Recognition: 2 theorem links
· Lean TheoremLearning POMDP World Models from Observations with Language-Model Priors
Pith reviewed 2026-05-14 19:51 UTC · model grok-4.3
The pith
An LLM proposes and refines POMDP models from observation-action trajectories alone to match methods with hidden-state access.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
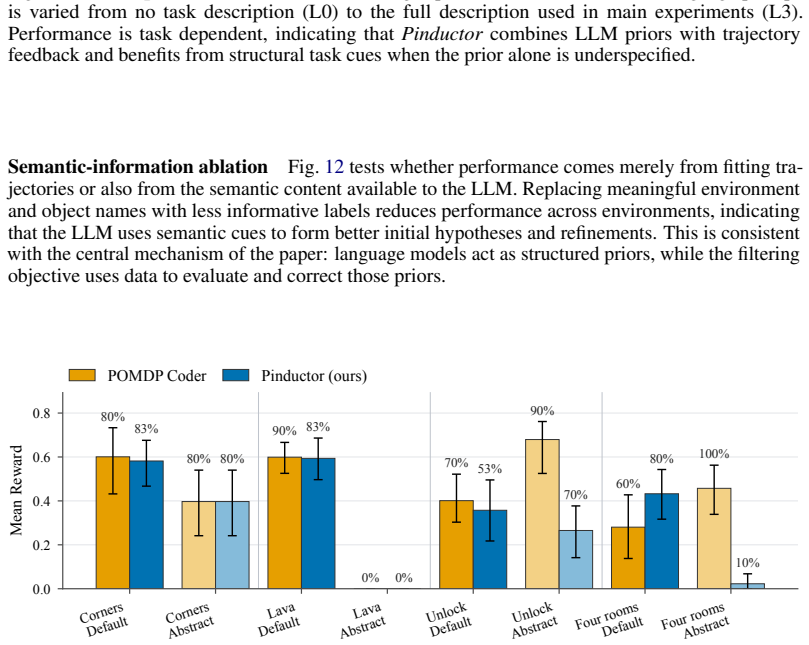
Pinductor lets an LLM first propose candidate POMDP models from a few observation-action trajectories and then iteratively refines those models by maximizing a belief-based likelihood objective. Despite using strictly less information than competing LLM methods that assume access to hidden states, Pinductor matches their performance and sample efficiency while substantially outperforming tabular POMDP baselines in sample efficiency. Performance improves with stronger language models and degrades only gradually when environment semantics are withheld.
What carries the argument
Pinductor, an iterative loop in which an LLM generates POMDP transition and observation functions and refines them against a belief-state likelihood computed on the observed trajectories.
If this is right
- Performance scales directly with the capability of the base language model.
- Degradation remains graceful when semantic cues about the environment are removed from the LLM prompt.
- Language-model priors become a practical substitute for privileged state information in sample-efficient POMDP learning.
- The method offers a concrete route toward generalist agents that build world models with limited real-world interaction.
Where Pith is reading between the lines
- The same proposal-and-refine loop could be applied to other partially observable control domains where only raw sensor streams are available.
- If future language models become more reliable at long-horizon dynamics, the number of required trajectories could drop further without changing the algorithm.
- Combining the LLM prior with lightweight tabular updates after the initial refinement might produce hybrid models that retain both speed and precision.
Load-bearing premise
An LLM can reliably generate and refine POMDP transition and observation models so that their belief-based likelihood on a small set of trajectories matches the true underlying dynamics.
What would settle it
A controlled experiment in which Pinductor is run on the same short trajectories but with an LLM whose proposals are replaced by random or fixed models, checking whether the likelihood optimization still recovers accurate dynamics and policy performance.
Figures






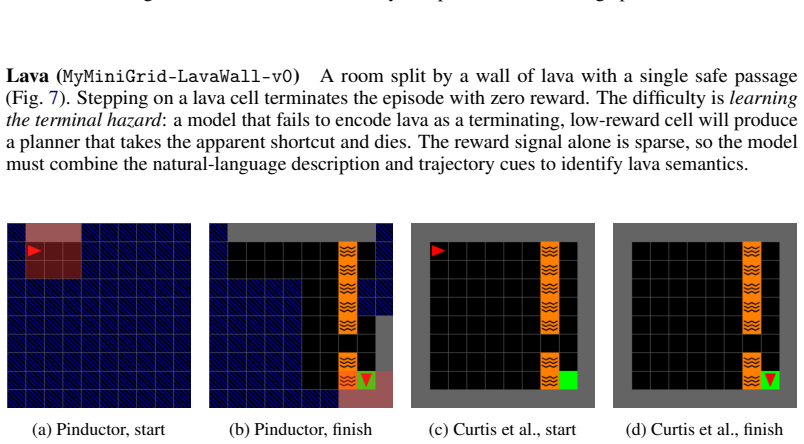


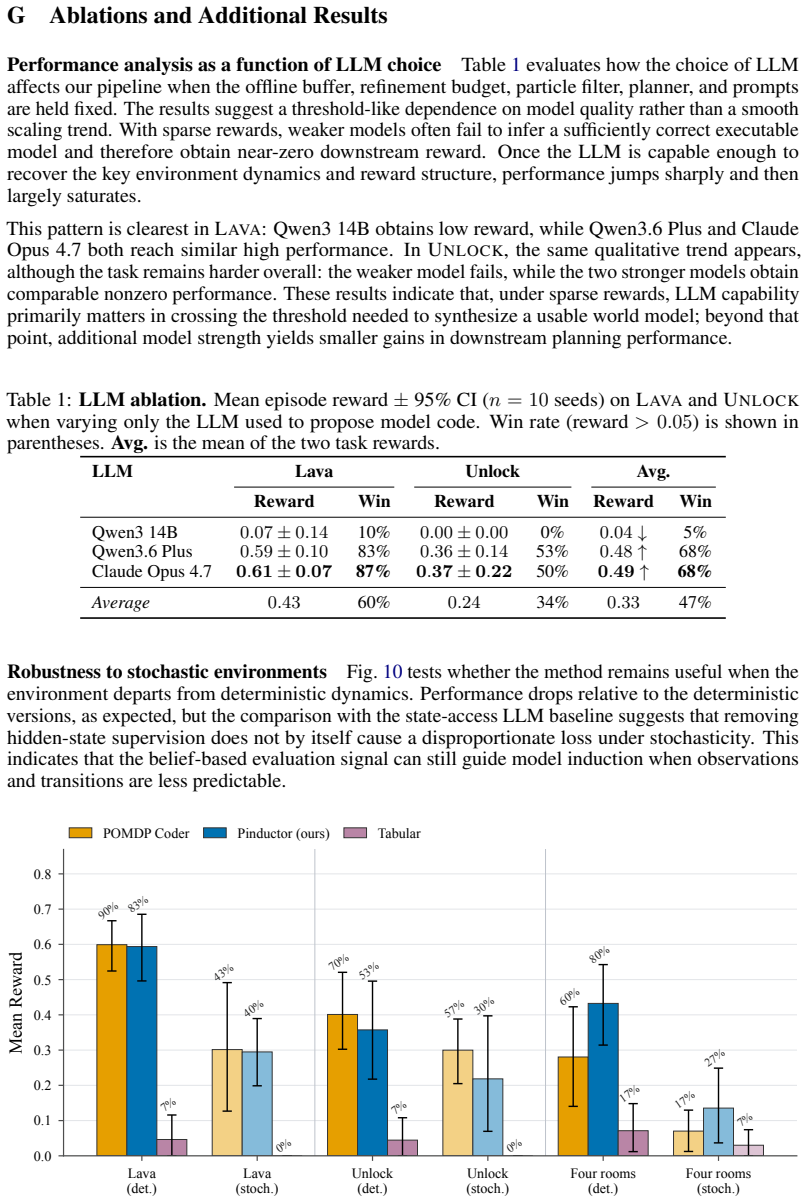
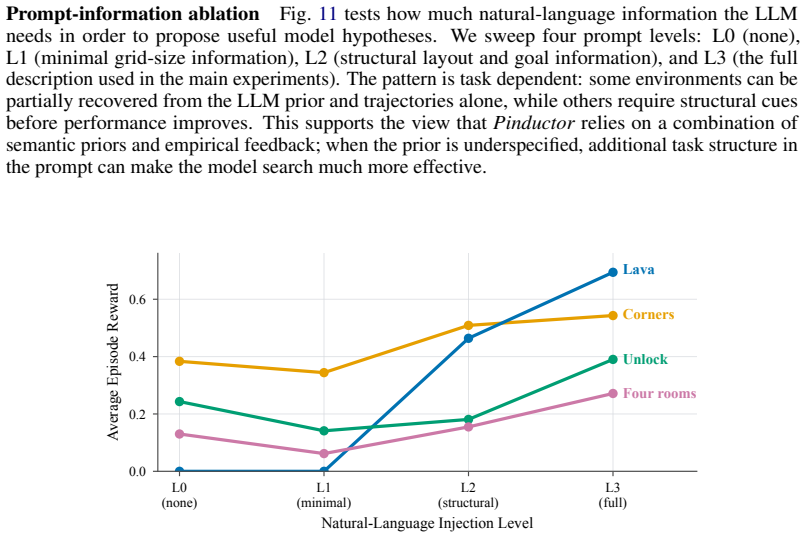
read the original abstract
Whether navigating a building, operating a robot, or playing a game, an agent that acts effectively in an environment must first learn an internal model of how that environment works. Partially-observable Markov decision processes (POMDPs) provide a flexible modeling class for such internal world models, but learning them from observation-action trajectories alone is challenging and typically requires extensive environment interaction. We ask whether language-model priors can reduce costly interaction by leveraging prior knowledge, and introduce \emph{Pinductor} (POMDP-inductor): an LLM proposes candidate POMDP models from a few observation-action trajectories and iteratively refines them to optimize a belief-based likelihood score. Despite using strictly less information, \emph{Pinductor} matches the performance and sample efficiency of LLM-based POMDP learning methods that assume privileged access to the hidden state, while significantly surpassing the sample efficiency of tabular POMDP baselines. Further results show that performance scales with LLM capability and degrades gracefully as semantic information about the environment is withheld. Together, these results position language-model priors as a practical tool for sample-efficient world-model learning under partial observability, and a step toward generalist agents in real-world environments. Code is available at https://github.com/atomresearch/pinductor.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Pinductor, an approach that uses an LLM to propose candidate POMDP transition and observation models from a small number of observation-action trajectories and then iteratively refines the models by maximizing a belief-based likelihood score. The central claim is that this method, which has access only to trajectories, matches the performance and sample efficiency of prior LLM-based POMDP learners that assume privileged access to hidden states while substantially outperforming tabular POMDP baselines; performance is shown to scale with LLM capability and to degrade gracefully when semantic environment information is withheld.
Significance. If the empirical results hold under rigorous controls, the work would demonstrate that language-model priors can enable sample-efficient world-model learning in partially observable settings without requiring state supervision, providing a concrete step toward generalist agents that build internal models from limited interaction. The public code release supports reproducibility.
major comments (2)
- [Method / Optimization] The optimization procedure maximizes belief likelihood on finite-length trajectories, yet the manuscript provides no identifiability argument or regularization that would guarantee recovery of the true transition and observation functions rather than an observationally equivalent alternative (see skeptic note on marginal observation distributions). This is load-bearing for the claim that Pinductor recovers accurate world models despite never observing hidden states.
- [Experiments] The abstract and results sections report performance matching and efficiency gains, but the provided description indicates absence of full experimental details, error bars, or ablation controls on the belief-likelihood objective; without these, the support for the central claim that the scalar likelihood suffices remains provisional.
minor comments (2)
- [Method] Clarify the exact form of the belief-based likelihood (e.g., whether it is the marginal likelihood over observations or includes an explicit entropy term) and how the LLM proposal distribution is updated across iterations.
- [Results] Add explicit comparison tables that include standard deviations across random seeds and environment instances to substantiate the sample-efficiency claims against tabular baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [Method / Optimization] The optimization procedure maximizes belief likelihood on finite-length trajectories, yet the manuscript provides no identifiability argument or regularization that would guarantee recovery of the true transition and observation functions rather than an observationally equivalent alternative (see skeptic note on marginal observation distributions). This is load-bearing for the claim that Pinductor recovers accurate world models despite never observing hidden states.
Authors: We agree that the manuscript lacks a formal identifiability argument. The belief-based likelihood is optimized to produce models that explain the observed trajectories for downstream planning and control, but we recognize that observationally equivalent alternatives may exist. In the revision we will add a dedicated discussion section on identifiability challenges in observation-only POMDP learning, clarify that the central claim concerns recovery of models sufficient for effective control rather than exact ground-truth parameters, and introduce a regularization term in the objective that penalizes overly complex models. We will also cite relevant literature on POMDP identifiability. revision: partial
-
Referee: [Experiments] The abstract and results sections report performance matching and efficiency gains, but the provided description indicates absence of full experimental details, error bars, or ablation controls on the belief-likelihood objective; without these, the support for the central claim that the scalar likelihood suffices remains provisional.
Authors: We acknowledge the need for stronger empirical documentation. The revised manuscript will expand the experimental section with complete implementation details, report performance means accompanied by standard-error bars computed over multiple random seeds, and include ablation studies that isolate the contribution of the belief-likelihood objective. These additions will provide clearer evidence that the scalar likelihood drives the observed performance gains. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's central procedure proposes candidate POMDP models via LLM and refines them by maximizing an external belief-based likelihood on finite observation-action trajectories. This likelihood is computed from the data and is not defined in terms of the reported performance metrics (e.g., downstream control or sample efficiency comparisons). No equation reduces the claimed performance to a fitted parameter or self-citation by construction; the optimization target remains independent of the evaluation benchmarks. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Pinductor uses an LLM to propose candidate programs for the transition, observation, reward, and initial-state distributions, and then iteratively refines them using a belief-based likelihood score... L(P^m;D) = sum ... E[log O^m(o_{t+1}|s_{t+1},a_t)]
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Richard S. Sutton and Andrew G. Barto.Reinforcement Learning: An Introduction. MIT Press, Cambridge, MA, second edition, 2018. 1, 3
work page 2018
-
[2]
David Ha and Jürgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
Training Agents Inside of Scalable World Models
Danijar Hafner, Wilson Yan, and Timothy Lillicrap. Training agents inside of scalable world models.arXiv preprint arXiv:2509.24527, 2025. 1
work page internal anchor Pith review arXiv 2025
-
[4]
Aggregate: count rows whereCOUNTRY= Algeria. [target: Country]
K. J Åström. Optimal control of Markov processes with incomplete state information.Journal of Mathematical Analysis and Applications, 10(1):174–205, February 1965. ISSN 0022-247X. doi: 10.1016/0022-247X(65)90154-X. 1
-
[5]
Leslie Pack Kaelbling, Michael L. Littman, and Anthony R. Cassandra. Planning and acting in partially observable stochastic domains.Artificial Intelligence, 101(1-2):99–134, 1998. doi: 10.1016/S0004-3702(98)00023-X. 1
-
[6]
Learning nonsingular phylogenies and hidden Markov models
Elchanan Mossel and Sébastien Roch. Learning nonsingular phylogenies and hidden Markov models. InProceedings of the Thirty-Seventh Annual ACM Symposium on Theory of Computing, STOC ’05, pages 366–375. ACM, 2005. doi: 10.1145/1060590.1060645. 1
-
[7]
Satinder Singh, Michael R. James, and Matthew R. Rudary. Predictive state representations: A new theory for modeling dynamical systems. InProceedings of the Twentieth Conference on Uncertainty in Artificial Intelligence (UAI), pages 512–519. AUAI Press, 2004. 1
work page 2004
-
[8]
A survey of point-based POMDP solvers.Au- tonomous Agents and Multi-Agent Systems, 27(1):1–51, 2013
Guy Shani, Joelle Pineau, and Robert Kaplow. A survey of point-based POMDP solvers.Au- tonomous Agents and Multi-Agent Systems, 27(1):1–51, 2013. doi: 10.1007/s10458-012-9200-2. 1
-
[9]
Reasoning with language model is planning with world model
Shibo Hao, Yi Gu, Haodi Ma, Joshua Jiahua Hong, Zhen Wang, Daisy Zhe Wang, and Zhiting Hu. Reasoning with language model is planning with world model. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 8154–8173, Singa- pore, 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-main.507. 2
-
[10]
Generating code world models with large language models guided by monte carlo tree search
Nicola Dainese, Matteo Merler, Minttu Alakuijala, and Pekka Marttinen. Generating code world models with large language models guided by monte carlo tree search. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems, volume 37, pages 60429–60474. Curran Associates, I...
-
[11]
Hao Tang, Darren Key, and Kevin Ellis. WorldCoder, a model-based LLM agent: Building world models by writing code and interacting with the environment. InAdvances in Neural Information Processing Systems, volume 37, 2024. 2, 3, 9
work page 2024
-
[12]
PoE-World: Compositional world modeling with products of programmatic experts
Wasu Top Piriyakulkij, Yichao Liang, Hao Tang, Adrian Weller, Marta Kryven, and Kevin Ellis. PoE-World: Compositional world modeling with products of programmatic experts. In Advances in Neural Information Processing Systems, 2025
work page 2025
-
[13]
Tenenbaum, Tom Sil- ver, João F
Yichao Liang, Nishanth Kumar, Hao Tang, Adrian Weller, Joshua B. Tenenbaum, Tom Sil- ver, João F. Henriques, and Kevin Ellis. VisualPredicator: Learning abstract world models with neuro-symbolic predicates for robot planning. InInternational Conference on Learning Representations (ICLR), 2025. Spotlight. 2
work page 2025
-
[14]
Tenenbaum, Tomás Lozano- Pérez, and Leslie Pack Kaelbling
Aidan Curtis, Hao Tang, Thiago Veloso, Kevin Ellis, Joshua B. Tenenbaum, Tomás Lozano- Pérez, and Leslie Pack Kaelbling. LLM-guided probabilistic program induction for POMDP model estimation. In9th Annual Conference on Robot Learning, 2025. 2, 3, 7, 8, 10, 17, 19, 24 10
work page 2025
-
[15]
Minimalistic gridworld envi- ronment for OpenAI Gym
Maxime Chevalier-Boisvert, Lucas Willems, and Suman Pal. Minimalistic gridworld envi- ronment for OpenAI Gym. https://github.com/maximecb/gym-minigrid, 2018. 2, 7, 24
work page 2018
-
[16]
Jonathan Light, Sixue Xing, Yuanzhe Liu, Weiqin Chen, Min Cai, Xiusi Chen, Guanzhi Wang, Wei Cheng, Yisong Yue, and Ziniu Hu. Pianist: Learning partially observable world models with LLMs for multi-agent decision making.arXiv preprint arXiv:2411.15998, 2024. 3
-
[17]
Tru- POMDP: Task planning under uncertainty via tree of hypotheses and open-ended POMDPs
Wenjing Tang, Xinyu He, Yongxi Huang, Yunxiao Xiao, Cewu Lu, and Panpan Cai. Tru- POMDP: Task planning under uncertainty via tree of hypotheses and open-ended POMDPs. arXiv preprint arXiv:2506.02860, 2025. 3
-
[18]
Xiao, Robert Bamler, Bernhard Schölkopf, and Weiyang Liu
Tim Z. Xiao, Robert Bamler, Bernhard Schölkopf, and Weiyang Liu. Verbalized machine learning: Revisiting machine learning with language models.Transactions on Machine Learning Research, 2025. 3
work page 2025
-
[19]
Code as policies: Language model programs for embodied control
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, and Andy Zeng. Code as policies: Language model programs for embodied control. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 9493–9500. IEEE,
-
[20]
doi: 10.1109/ICRA48891.2023.10160591. 3
-
[21]
Zergham Ahmed, Joshua B. Tenenbaum, Christopher J. Bates, and Samuel J. Gershman. Synthesizing world models for bilevel planning.Transactions on Machine Learning Research,
-
[22]
Panagiotis Lymperopoulos, Abhiramon Rajasekharan, Ian Berlot-Attwell, Stéphane Aroca- Ouellette, and Kaheer Suleman. CASSANDRA: Programmatic and probabilistic learning and inference for stochastic world modeling.arXiv preprint arXiv:2601.18620, 2026. 3
-
[23]
Alexander Novikov, Ngân V˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco J. R. Ruiz, Abbas Mehrabian, M. Pawan Kumar, Abigail See, Swarat Chaudhuri, George Holland, Alex Davies, Sebastian Nowozin, Pushmeet Kohli, and Matej Balog. Alphaevolve: A coding agent for scientific and algor...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Stéphane Ross, Brahim Chaib-draa, and Joelle Pineau. Bayes-adaptive POMDPs. InAdvances in Neural Information Processing Systems, volume 20, pages 1225–1232, 2007. 3
work page 2007
-
[25]
Oliehoek, and Christopher Amato
Sammie Katt, Frans A. Oliehoek, and Christopher Amato. Bayesian reinforcement learning in factored POMDPs. InProceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems (AAMAS), pages 7–15. IFAAMAS, 2019. 3
work page 2019
-
[26]
Reinforcement learning of POMDPs using spectral methods
Kamyar Azizzadenesheli, Alessandro Lazaric, and Animashree Anandkumar. Reinforcement learning of POMDPs using spectral methods. In Vitaly Feldman, Alexander Rakhlin, and Ohad Shamir, editors,29th Annual Conference on Learning Theory, volume 49 ofProceedings of Machine Learning Research, pages 193–256. PMLR, 2016. 3
work page 2016
-
[27]
Variational Inference for Data-Efficient Model Learning in POMDPs
Sebastian Tschiatschek, Kai Arulkumaran, Jan Stühmer, and Katja Hofmann. Variational inference for data-efficient model learning in POMDPs.arXiv preprint arXiv:1805.09281, 2018. 3
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[28]
Active learning of Markov decision processes using baum-welch algorithm
Giovanni Bacci, Anna Ingólfsdóttir, Kim G Larsen, and Raphaël Reynouard. Active learning of Markov decision processes using baum-welch algorithm. In2021 20th IEEE International Conference on Machine Learning and Applications (ICMLA), pages 1203–1208. IEEE, 2021. 3
work page 2021
-
[29]
Mastering diverse control tasks through world models.Nature, 640(8059):647–653, 2025
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse control tasks through world models.Nature, 640(8059):647–653, 2025. 3, 9
work page 2025
-
[30]
Tsividis, Joao Loula, Jake Burga, Nathan Foss, Andres Campero, Thomas Pouncy, Samuel J
Pedro A. Tsividis, Joao Loula, Jake Burga, Nathan Foss, Andres Campero, Thomas Pouncy, Samuel J. Gershman, and Joshua B. Tenenbaum. Human-level reinforcement learning through theory-based modeling, exploration, and planning.arXiv preprint arXiv:2107.12544, 2021. 3
-
[31]
Inductive biases in theory-based reinforcement learning.Cognitive Psychology, 138:101509, 2022
Thomas Pouncy and Samuel J Gershman. Inductive biases in theory-based reinforcement learning.Cognitive Psychology, 138:101509, 2022. 3 11
work page 2022
-
[32]
Qwen3.6-Plus: Towards real world agents, April 2026
Qwen Team. Qwen3.6-Plus: Towards real world agents, April 2026. URL https://qwen.ai/ blog?id=qwen3.6. 7
work page 2026
- [33]
-
[34]
Anthropic. Claude opus 4.7. https://www.anthropic.com/claude/opus, 2026. Accessed: 2026-05-06. 7
work page 2026
-
[35]
Tianwei Ni, Benjamin Eysenbach, and Ruslan Salakhutdinov. Recurrent model-free RL is a strong baseline for many pomdps.CoRR, abs/2110.05038, 2021. URL https://arxiv.org/ abs/2110.05038. 9 A Methodological Details This appendix provides implementation details omitted from the main methodology section for space. Appendix A.1 gives the full distance-kernel l...
-
[36]
First, explain in plain English what you believe the dynamics are: - Which hidden variables are randomized at the start of each episode? - How does the agent’s view change when it moves or turns? - What objects exist and how does the agent interact with them? - What actions succeed or fail, and why?
-
[37]
Then, implement the initial_func, observation_func, transition_func, reward_func, and initial_func functions. Rules: - You must implement the initial_func, observation_func, transition_func, reward_func, and initial_func functions. 28 - Create helper functions only INSIDE the scope of the initial_func, observation_func, transition_func, reward_func, and i...
-
[38]
A rule that hard-codes a specific layout fragment will break on the next draw
**Rules over memorization.** Express conditions on the semantic content of states, not on the literal arrays present in the samples. A rule that hard-codes a specific layout fragment will break on the next draw
-
[39]
Missing a rare case is usually worse than being slightly inexact on a common one
**Cover the space, not the sample.** Enumerate every plausible case the environment can produce and decide what should happen in each, even when the sample does not exercise it. Missing a rare case is usually worse than being slightly inexact on a common one
-
[41]
**No episode or step references.** "Episode N ended at step T" is not a rule you can use at deployment. Conditions must depend only on the arguments your function receives
-
[42]
**One coherent hypothesis.** When several samples disagree, choose the single most general rule consistent with all of them – do not stack special cases for each one. Pinductor — OUTPUT Based on the environment description and analyzed observations, here is the inferred model of the dynamics: **1. Dynamics & Hidden Variables** - **Grid & Layout:** A fixed...
-
[43]
First, analyze: for each reported error or disagreement above, explain in plain English what you think went wrong and why
-
[44]
Focus on the specific cases where the evaluation found errors
Then, fix: implement an improved version of the initial_func, observation_func, transition_func, reward_func, and initial_func functions. Focus on the specific cases where the evaluation found errors. Rules: - You must implement the initial_func, observation_func, transition_func, reward_func, and initial_func functions. - Do not create new classes or imp...
-
[45]
**Rules over memorization.** Express conditions on semantic content, not on the literal arrays present in the samples
-
[46]
**Cover the space, not the sample.** Enumerate every plausible case the environment can produce and decide what should happen in each, even when the sample does not exercise it
-
[47]
Long nested branches enumerating specific coordinates almost always overfit
**Parsimony.** Prefer the shortest rule consistent with the data. Long nested branches enumerating specific coordinates almost always overfit
-
[48]
**No episode or step references.** Conditions must depend only on the arguments your function receives, not on which sample they came from
-
[49]
**One coherent hypothesis.** When several samples disagree, choose the single most general rule consistent with all of them – do not stack special cases for each one
-
[50]
**Keep what was already right.** When extending your previous code, do not drop a case that already worked. Add the new case alongside. Pinductor — OUTPUT Looking at the evaluation results, I can identify several critical issues:
-
[51]
**Initial state not properly cleaning old objects**: The ’initial_func’ copies ’empty_state.grid’ but never clears previous episode’s key/goal/door positions before placing new ones, causing contamination
-
[52]
**Wall structure at column 5 not enforced**: The locked door is placed at a random row in column 5, but the rest of column 5 must be filled with walls to form the partition
-
[53]
**Agent position type inconsistency**: ’initial_func’ uses tuples while ’transition_func’ uses lists, which can cause subtle numpy indexing issues
-
[54]
**Forward movement blocking logic incomplete**: The agent should not move into walls, closed doors, or locked doors, but the current allowed set doesn’t explicitly account for all cases
-
[55]
""Samples a plausible initial state
**The ’empty’/wall boundary assumption**: The code assumes boundary walls exist, but they need to be explicitly set in every initialization. Here’s the corrected implementation: ’’’python def initial_func(empty_state: MinigridState) -> MinigridState: """Samples a plausible initial state.""" h = empty_state.grid.shape[1] w = empty_state.grid.shape[0] state...
-
[56]
This eliminates contamination from previous episodes
**Proper grid initialization**: Uses ’np.full’ with walls, then explicitly clears the interior and places the partition wall at column 5. This eliminates contamination from previous episodes
-
[57]
**Explicit wall placement**: Column 5 is filled with walls at all interior rows, then one cell is replaced with the locked door
-
[58]
**Consistent position types**: Uses ’list(state.agent_pos)’ in transition to match tuple-to-list conversion, preventing numpy broadcasting issues
-
[59]
**Bounds checking in reward**: Added explicit bounds validation before accessing the goal position in ’reward_func’
-
[60]
**Clean object placement**: Used ’while True’ loops with position checks to avoid placing objects on the agent. Curtis et al. — INPUT (transition_funcREx iter 1, identical template to online hook) #define system You are a robot exploring its environment. 10x10 grid with boundary walls. A vertical wall of lava spans most of one column with exactly one gap ...
-
[61]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.