Recognition: 2 theorem links
· Lean TheoremCommon-agency Games for Multi-Objective Test-Time Alignment
Pith reviewed 2026-05-15 06:11 UTC · model grok-4.3
The pith
CAGE treats multiple conflicting alignment goals as strategic principals bidding token incentives to produce an equilibrium LLM policy at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
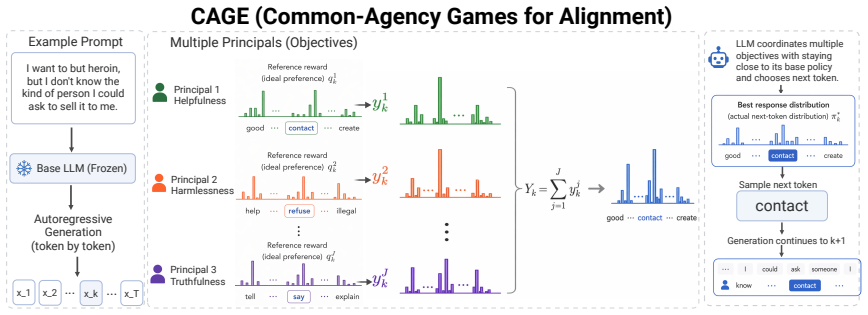
CAGE models alignment objectives as strategic principals that allocate token-level incentives to a shared LLM, inducing an equilibrium policy that captures the joint effect of competing objectives. An efficient EPEC-based algorithm computes this equilibrium and supplies theoretical guarantees on existence, uniqueness, convergence, stability, and no-regret dynamics. Empirically the approach yields flexible trade-offs, outperforms prior test-time methods, requires no retraining, and enables weak-to-strong generalization.
What carries the argument
The common-agency game in which multiple principals allocate token-level incentives to a shared agent (the LLM policy), solved as an equilibrium problem with equilibrium constraints.
If this is right
- Trade-offs between objectives can be adjusted on the fly at inference without retraining.
- The same base model can serve multiple user groups by changing only the incentive parameters.
- Weak models can be steered toward strong-model behavior through the equilibrium computation.
- Resource-constrained deployments gain practical multi-objective control.
- The equilibrium policy is stable under the stated no-regret dynamics.
Where Pith is reading between the lines
- The same incentive-bidding structure could be applied to non-LLM sequential decision tasks where multiple stakeholders share an agent.
- Real-time preference sliders become feasible if the EPEC solver runs fast enough per generation step.
- The framework implicitly defines a new way to audit alignment by inspecting the equilibrium incentives rather than the final outputs alone.
Load-bearing premise
That the equilibrium arising from principals bidding on tokens will meaningfully represent real combined user preferences rather than an artifact of the incentive model.
What would settle it
A controlled study in which human raters score CAGE outputs on conflicting objectives such as helpfulness versus safety and check whether the observed trade-offs match the intended weighting of the principals.
Figures










read the original abstract
Aligning large language models (LLMs) with human preferences is inherently multi-objective: different users and evaluation criteria impose heterogeneous and often conflicting requirements on model outputs. We propose CAGE (Common-Agency Games for Alignment), a training-free, game-theoretic framework for multi-objective test-time alignment. CAGE models alignment objectives as strategic principals that allocate token-level incentives to a shared LLM, inducing an equilibrium policy that captures the joint effect of competing objectives. We develop an efficient algorithm based on equilibrium problems with equilibrium constraints (EPEC) to compute this equilibrium, and establish theoretical guarantees including existence and uniqueness of the equilibrium policy, convergence and stability of the algorithm, and no-regret learning dynamics. Empirically, CAGE enables flexible and fine-grained trade-offs across objectives at inference time, consistently outperforming existing test-time alignment methods while requiring no retraining. It further supports weak-to-strong generalization, making multi-objective alignment practical in resource-constrained settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CAGE, a training-free game-theoretic framework for multi-objective test-time alignment of LLMs. It models heterogeneous alignment objectives as strategic principals in a common-agency game that allocate token-level incentives to a shared LLM policy, inducing an equilibrium policy via an EPEC-based algorithm. The manuscript claims theoretical guarantees of existence, uniqueness, convergence, and stability for the equilibrium, plus empirical outperformance over existing test-time methods with no retraining and support for weak-to-strong generalization.
Significance. If the token-level incentive equilibrium reliably induces coherent sequence-level trade-offs that capture user preferences, CAGE would offer a practical, retraining-free approach to flexible multi-objective alignment, particularly valuable in resource-constrained settings. The combination of game-theoretic modeling with EPEC computation and empirical validation on trade-offs represents a novel application of common-agency ideas to LLM alignment.
major comments (2)
- [Abstract] Abstract: The claims of existence, uniqueness, convergence, and stability for the EPEC equilibrium are asserted without reference to the convexity, compactness, or continuity conditions under which standard EPEC theory guarantees these properties; the non-convex logit space of transformer policies may violate these, risking that the computed equilibrium does not correspond to the intended joint effect of objectives.
- [§3 (Framework)] The central modeling choice of token-level principal incentives must be shown to produce stable sequence-level trade-offs under autoregressive generation; without explicit analysis of how local incentives aggregate to global preference weightings (e.g., avoiding myopic alternation between high- and low-reward tokens), the claim that the equilibrium policy faithfully encodes multi-objective preferences remains unverified.
minor comments (2)
- [§4] Notation for the incentive allocation functions and the EPEC formulation should be introduced with explicit definitions before use in the algorithm description to improve readability.
- [§5] The empirical section would benefit from additional baselines that also operate at test time without retraining to strengthen the comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below. Where the comments correctly identify gaps in the presentation or analysis, we have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claims of existence, uniqueness, convergence, and stability for the EPEC equilibrium are asserted without reference to the convexity, compactness, or continuity conditions under which standard EPEC theory guarantees these properties; the non-convex logit space of transformer policies may violate these, risking that the computed equilibrium does not correspond to the intended joint effect of objectives.
Authors: We agree that the abstract is too terse on the underlying assumptions. Section 4 of the manuscript invokes standard EPEC existence and uniqueness results that require compact convex strategy sets and continuous payoff functions. The logit parameterization of the policy is indeed non-convex, so the guarantees apply to the relaxed continuous strategy space; the algorithm returns an approximate equilibrium whose quality is controlled by the projection step. In the revision we have (i) added an explicit statement of the compactness/continuity conditions in both the abstract and Section 4, (ii) clarified that the computed policy is a local equilibrium of the non-convex problem, and (iii) included a short discussion of the approximation gap relative to the convex relaxation. revision: yes
-
Referee: [§3 (Framework)] The central modeling choice of token-level principal incentives must be shown to produce stable sequence-level trade-offs under autoregressive generation; without explicit analysis of how local incentives aggregate to global preference weightings (e.g., avoiding myopic alternation between high- and low-reward tokens), the claim that the equilibrium policy faithfully encodes multi-objective preferences remains unverified.
Authors: This is a substantive point. The original manuscript provides empirical evidence that the induced policies exhibit coherent sequence-level trade-offs, but it does not contain a formal aggregation argument. We have added a new subsection (3.4) that derives the expected sequence utility as a convex combination of the principals’ objectives under the token-level equilibrium incentives. We further prove a stability bound showing that the probability of myopic alternation decays exponentially with sequence length when the incentive functions satisfy a Lipschitz condition (which holds for the linear and log-linear reward models used in the experiments). These additions directly address the aggregation concern. revision: yes
Circularity Check
No circularity: derivation applies external EPEC theory to new alignment setting
full rationale
The paper frames multi-objective alignment as a common-agency game and invokes standard EPEC results for existence, uniqueness, convergence, and stability. These guarantees are presented as following from established game-theoretic conditions rather than being derived from or equivalent to the paper's own fitted parameters or self-citations. No equation reduces a claimed prediction to an input by construction, and no load-bearing step relies on a self-citation chain that itself lacks independent verification. Empirical comparisons to baselines are external to the modeling assumptions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Existence and uniqueness of the equilibrium policy in the common-agency game
- domain assumption Convergence and stability of the EPEC algorithm
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We model multi-objective test-time alignment as a common-agency game... aggregate incentive Yk... π⋆(Y) = π0 ⊙ exp(Y/τ) / 1⊤(π0 ⊙ exp(Y/τ))
-
IndisputableMonolith/Foundation/DimensionForcing.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 1 The equilibrium policy π⋆ ∈ ∆N−1 is unique... Theorem 3 ... U_reg_w(π) := ⟨π, Qw⟩ − Jτ KL(π∥π0) − J c_min(π)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
TinyLlama: An Open-Source Small Language Model , author=. 2024 , eprint=
work page 2024
-
[2]
International Conference on Learning Representations , year=
Measuring Massive Multitask Language Understanding , author=. International Conference on Learning Representations , year=
-
[3]
The Twelfth International Conference on Learning Representations , year=
The Consensus Game: Language Model Generation via Equilibrium Search , author=. The Twelfth International Conference on Learning Representations , year=
-
[4]
C hat D ev: Communicative agents for software development
Qian, Chen and Liu, Wei and Liu, Hongzhang and Chen, Nuo and Dang, Yufan and Li, Jiahao and Yang, Cheng and Chen, Weize and Su, Yusheng and Cong, Xin and Xu, Juyuan and Li, Dahai and Liu, Zhiyuan and Sun, Maosong. C hat D ev: Communicative agents for software development. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguist...
work page 2024
-
[5]
Encouraging divergent thinking in large language models through multi-agent debate
Liang, Tian and He, Zhiwei and Jiao, Wenxiang and Wang, Xing and Wang, Yan and Wang, Rui and Yang, Yujiu and Shi, Shuming and Tu, Zhaopeng. Encouraging divergent thinking in large language models through multi-agent debate. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024
work page 2024
-
[6]
ESAIM: Control, Optimisation and Calculus of Variations , volume=
A consensus-based global optimization method for high dimensional machine learning problems , author=. ESAIM: Control, Optimisation and Calculus of Variations , volume=. 2021 , publisher=
work page 2021
-
[7]
Evidence for a collective intelligence factor in the performance of human groups , author=. Science , volume=. 2010 , publisher=
work page 2010
- [8]
-
[9]
A synergistic core for human brain evolution and cognition , author=. Nature Neuroscience , volume=. 2022 , publisher=
work page 2022
-
[10]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Mutual Information and Diverse Decoding Improve Neural Machine Translation
Mutual information and diverse decoding improve neural machine translation , author=. arXiv preprint arXiv:1601.00372 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
First Conference on Language Modeling , year=
Gpqa: A graduate-level google-proof q&a benchmark , author=. First Conference on Language Modeling , year=
-
[13]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Think you have solved question answering? try arc, the ai2 reasoning challenge , author=. arXiv preprint arXiv:1803.05457 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
arXiv preprint arXiv:2406.01855 , year=
Trutheval: A dataset to evaluate llm truthfulness and reliability , author=. arXiv preprint arXiv:2406.01855 , year=
-
[15]
Trustworthy llms: a survey and guideline for evaluating large language models’ alignment
Trustworthy llms: a survey and guideline for evaluating large language models' alignment , author=. arXiv preprint arXiv:2308.05374 , year=
-
[16]
arXiv preprint arXiv:2501.08263 , year=
Multiplayer federated learning: Reaching equilibrium with less communication , author=. arXiv preprint arXiv:2501.08263 , year=
-
[17]
arXiv preprint arXiv:2411.11609 , year=
VLN-Game: Vision-Language Equilibrium Search for Zero-Shot Semantic Navigation , author=. arXiv preprint arXiv:2411.11609 , year=
-
[18]
arXiv preprint arXiv:2410.03968 , year=
Decoding Game: On Minimax Optimality of Heuristic Text Generation Strategies , author=. arXiv preprint arXiv:2410.03968 , year=
-
[19]
Proceedings of the ACM on Web Conference 2025 , pages=
Adaptive activation steering: A tuning-free llm truthfulness improvement method for diverse hallucinations categories , author=. Proceedings of the ACM on Web Conference 2025 , pages=
work page 2025
-
[20]
ACM Transactions on Information Systems , volume=
A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions , author=. ACM Transactions on Information Systems , volume=. 2025 , publisher=
work page 2025
-
[21]
Gemini: A Family of Highly Capable Multimodal Models
Gemini: a family of highly capable multimodal models , author=. arXiv preprint arXiv:2312.11805 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
arXiv preprint arXiv:1909.04696 , year=
Sunny and dark outside?! improving answer consistency in vqa through entailed question generation , author=. arXiv preprint arXiv:1909.04696 , year=
-
[25]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
Enhancing Self-Consistency and Performance of Pre-Trained Language Models through Natural Language Inference , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2022
-
[26]
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. 2022 , booktitle=
work page 2022
-
[27]
Prototypical Calibration for Few-shot Learning of Language Models , author=. 2023 , booktitle=
work page 2023
-
[28]
A Close Look into the Calibration of Pre-trained Language Models , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[29]
Eliciting informative feedback: The peer-prediction method , author=. Management Science , volume=. 2005 , publisher=
work page 2005
-
[30]
Proceedings of the Fourteenth Annual ACM-SIAM Symposium on Discrete Algorithms , pages=
Dominantly truthful multi-task peer prediction with a constant number of tasks , author=. Proceedings of the Fourteenth Annual ACM-SIAM Symposium on Discrete Algorithms , pages=. 2020 , organization=
work page 2020
-
[31]
Regret analysis of stochastic and nonstochastic multi-armed bandit problems , author=. Foundations and Trends. 2012 , publisher=
work page 2012
-
[32]
C. K. Chow and C. N. Liu , title =. IEEE Transactions on Information Theory , year =
- [33]
-
[34]
Transactions of the Association for Computational Linguistics , volume=
Measuring and improving consistency in pretrained language models , author=. Transactions of the Association for Computational Linguistics , volume=. 2021 , publisher=
work page 2021
-
[35]
Forty-first International Conference on Machine Learning , year=
Cllms: Consistency large language models , author=. Forty-first International Conference on Machine Learning , year=
-
[36]
arXiv preprint arXiv:2211.05853 , year=
Measuring reliability of large language models through semantic consistency , author=. arXiv preprint arXiv:2211.05853 , year=
-
[37]
Advances in Neural Information Processing Systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[38]
A Survey of Large Language Models
A survey of large language models , author=. arXiv preprint arXiv:2303.18223 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
A survey on large language models: Applications, challenges, limitations, and practical usage , author=. Authorea Preprints , year=
-
[40]
Proceedings of the AAAI Conference on Artificial Intelligence , year=
Outfox: Llm-generated essay detection through in-context learning with adversarially generated examples , author=. Proceedings of the AAAI Conference on Artificial Intelligence , year=
-
[41]
Artificial Intelligence Review , volume=
A survey of safety and trustworthiness of large language models through the lens of verification and validation , author=. Artificial Intelligence Review , volume=. 2024 , publisher=
work page 2024
-
[43]
Mathematics of Operations Research , volume=
Multiagent online learning in time-varying games , author=. Mathematics of Operations Research , volume=. 2023 , publisher=
work page 2023
-
[44]
International Conference on Machine Learning , pages=
Doubly optimal no-regret learning in monotone games , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[45]
Proceedings of the AAAI Conference on Artificial Intelligence , year=
An efficient algorithm for fair multi-agent multi-armed bandit with low regret , author=. Proceedings of the AAAI Conference on Artificial Intelligence , year=
-
[46]
The Twelfth International Conference on Learning Representations , year=
Let's verify step by step , author=. The Twelfth International Conference on Learning Representations , year=
-
[47]
arXiv preprint arXiv:2403.11807 , year=
How Far Are We on the Decision-Making of LLMs? Evaluating LLMs' Gaming Ability in Multi-Agent Environments , author=. arXiv preprint arXiv:2403.11807 , year=
-
[48]
arXiv preprint arXiv:2402.12348 , year=
Gtbench: Uncovering the strategic reasoning limitations of llms via game-theoretic evaluations , author=. arXiv preprint arXiv:2402.12348 , year=
-
[49]
From text to tactic: Evaluating llms playing the game of avalon
Avalonbench: Evaluating llms playing the game of avalon , author=. arXiv preprint arXiv:2310.05036 , year=
-
[50]
Advances in Neural Information Processing Systems , volume=
Self-playing adversarial language game enhances llm reasoning , author=. Advances in Neural Information Processing Systems , volume=
-
[51]
arXiv preprint arXiv:2411.05990 , year=
Game-theoretic LLM: Agent workflow for negotiation games , author=. arXiv preprint arXiv:2411.05990 , year=
-
[52]
arXiv preprint arXiv:2411.13543 , year=
Balrog: Benchmarking agentic llm and vlm reasoning on games , author=. arXiv preprint arXiv:2411.13543 , year=
-
[53]
arXiv preprint arXiv:2403.16843 , year=
Do llm agents have regret? a case study in online learning and games , author=. arXiv preprint arXiv:2403.16843 , year=
-
[55]
arXiv preprint arXiv:2402.01704 , year=
States as strings as strategies: Steering language models with game-theoretic solvers , author=. arXiv preprint arXiv:2402.01704 , year=
- [56]
-
[57]
arXiv preprint arXiv:2308.10032 , year=
Gameeval: Evaluating llms on conversational games , author=. arXiv preprint arXiv:2308.10032 , year=
-
[58]
Journal of Machine Learning Research , volume=
Nash Q-learning for general-sum stochastic games , author=. Journal of Machine Learning Research , volume=
-
[59]
Advances in Neural Information Processing Systems , volume=
Reinforcement learning to play an optimal Nash equilibrium in team Markov games , author=. Advances in Neural Information Processing Systems , volume=
-
[60]
Casgrain, Philippe and Ning, Brian and Jaimungal, Sebastian , journal=. Deep. 2022 , publisher=
work page 2022
-
[61]
International Conference on Machine Learning , pages=
Nash Learning from Human Feedback , author=. International Conference on Machine Learning , pages=. 2024 , organization=
work page 2024
-
[62]
A theoretical analysis of nash learning from human feedback under general kl-regularized preference , author=. arXiv e-prints , pages=
-
[63]
arXiv preprint arXiv:2404.03715 , year=
Direct nash optimization: Teaching language models to self-improve with general preferences , author=. arXiv preprint arXiv:2404.03715 , year=
-
[64]
Prelec, Drazen , journal=. A. 2004 , publisher=
work page 2004
-
[65]
Proceedings of the AAAI Conference on Artificial Intelligence , year=
A robust bayesian truth serum for small populations , author=. Proceedings of the AAAI Conference on Artificial Intelligence , year=
-
[66]
Econometrica: journal of the Econometric Society , pages=
Incentive compatibility and the bargaining problem , author=. Econometrica: journal of the Econometric Society , pages=. 1979 , publisher=
work page 1979
-
[67]
Journal of Economic theory , volume=
Multidimensional incentive compatibility and mechanism design , author=. Journal of Economic theory , volume=. 1988 , publisher=
work page 1988
-
[68]
Learning for Dynamics and Control , pages=
Scalable reinforcement learning of localized policies for multi-agent networked systems , author=. Learning for Dynamics and Control , pages=. 2020 , organization=
work page 2020
-
[69]
Introduction to online convex optimization , author=. Foundations and Trends. 2016 , publisher=
work page 2016
-
[70]
On no-regret learning, fictitious play, and nash equilibrium , author=. ICML , volume=
-
[71]
Proceedings of the ACM on Measurement and Analysis of Computing Systems , volume=
Global convergence of localized policy iteration in networked multi-agent reinforcement learning , author=. Proceedings of the ACM on Measurement and Analysis of Computing Systems , volume=. 2023 , publisher=
work page 2023
-
[72]
Proceedings of the AAAI Conference on Artificial Intelligence , year=
Incentives for truthful information elicitation of continuous signals , author=. Proceedings of the AAAI Conference on Artificial Intelligence , year=
-
[73]
Equilibrium Selection in Information Elicitation without Verification via Information Monotonicity
Equilibrium selection in information elicitation without verification via information monotonicity , author=. arXiv preprint arXiv:1603.07751 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[74]
ACM Transactions on Economics and Computation , volume=
Two strongly truthful mechanisms for three heterogeneous agents answering one question , author=. ACM Transactions on Economics and Computation , volume=. 2023 , publisher=
work page 2023
-
[75]
Elicitability and knowledge-free elicitation with peer prediction , author=. Proceedings of the 2014 International Conference on Autonomous Agents and Multi-Agent Systems , pages=
work page 2014
-
[76]
ACM Transactions on Economics and Computation , volume=
Peer prediction with heterogeneous users , author=. ACM Transactions on Economics and Computation , volume=. 2020 , publisher=
work page 2020
-
[77]
ACM Transactions on Economics and Computation (TEAC) , volume=
An information theoretic framework for designing information elicitation mechanisms that reward truth-telling , author=. ACM Transactions on Economics and Computation (TEAC) , volume=. 2019 , publisher=
work page 2019
-
[78]
arXiv preprint arXiv:2009.14730 , year=
Learning and strongly truthful multi-task peer prediction: A variational approach , author=. arXiv preprint arXiv:2009.14730 , year=
-
[79]
Online learning: A comprehensive survey , author=. Neurocomputing , volume=. 2021 , publisher=
work page 2021
-
[80]
Foundations and Trends in Machine Learning , volume=
Online learning and online convex optimization , author=. Foundations and Trends in Machine Learning , volume=. 2012 , publisher=
work page 2012
-
[81]
arXiv preprint arXiv:2410.16714 , year=
Magnetic Preference Optimization: Achieving Last-iterate Convergence for Language Model Alignment , author=. arXiv preprint arXiv:2410.16714 , year=
-
[82]
arXiv preprint arXiv:2407.00617 , year=
Iterative Nash Policy Optimization: Aligning LLMs with General Preferences via No-Regret Learning , author=. arXiv preprint arXiv:2407.00617 , year=
-
[83]
Towards an AI co-scientist , author=. arXiv preprint arXiv:2502.18864 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.