Recognition: 2 theorem links
· Lean TheoremBreaking Global Self-Attention Bottlenecks in Transformer-based Spiking Neural Networks with Local Structure-Aware Self-Attention
Pith reviewed 2026-05-15 06:13 UTC · model grok-4.3
The pith
Local dilated-window self-attention and spiking response pooling let transformer-based spiking networks preserve regional features while cutting quadratic redundancy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
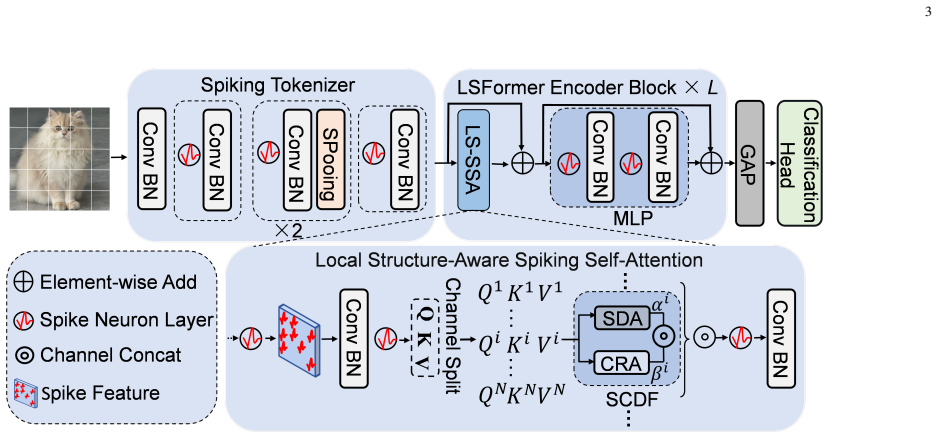
LSFormer replaces global self-attention with Local Structure-Aware Spiking Self-Attention (LS-SSA) that operates inside dilated local windows and introduces Spiking Response Pooling (SPooling) that aggregates representative regional activations rather than only the strongest one. These two changes together reduce computational waste and retain more informative features, yielding 4.3 percent higher top-1 accuracy on Tiny-ImageNet and 8.6 percent higher on N-CALTECH101 than prior transformer-based spiking models.
What carries the argument
Local Structure-Aware Spiking Self-Attention (LS-SSA) that restricts attention to dilated local windows so that each spiking neuron interacts only with a controlled neighborhood while still reaching long-range context through dilation.
If this is right
- Quadratic attention cost is replaced by cost linear in the number of local windows.
- Feature maps keep more spatially distributed information instead of discarding all but the peak response.
- The same architecture can be applied to both static images and event-based neuromorphic data without separate redesigns.
- Energy per inference stays low because the sparse spiking activity is preserved inside the restricted attention windows.
Where Pith is reading between the lines
- Similar local-window restrictions could be tested in non-spiking vision transformers to see if they reduce memory traffic without accuracy loss.
- The dilated-window pattern may extend naturally to video or temporal spiking sequences where long-range timing relations matter.
- A controlled ablation that isolates SPooling from LS-SSA would clarify which component drives most of the gain on event-based datasets.
Load-bearing premise
The reported accuracy gains come from the local attention window and spiking pooling rather than from unmentioned differences in training length, optimizer settings, or data augmentation.
What would settle it
Train the strongest baseline models with the exact same schedule, batch size, learning-rate schedule, and data augmentations used for LSFormer and check whether the accuracy gap shrinks or disappears.
Figures





read the original abstract
Transformer-based Spiking Neural Networks (SNNs) integrate SNNs with global self-attention and have demonstrated impressive performance. However, existing Transformer-based SNNs suffer from two fundamental limitations. First, they typically employ max pooling layers to reduce the size of feature maps, but the max pooling captures only the strongest response and fails to comprehensively preserve representative regional features. Second, the global self-attention involves all global feature interactions, resulting in computational redundancy and quadratic computational complexity, thus conflicting with the sparse and energy-efficient characteristics of SNNs. To address these challenges, we develop Local Structure-Aware Spiking Transformer (LSFormer), a novel Transformer-based Spiking Neural Network that incorporates Spiking Response Pooling (SPooling) and Local Structure-Aware Spiking Self-Attention (LS-SSA). For the first time, our LSFormer leverages a local dilated window mechanism to capture both local details and long-range dependencies. Experimental results demonstrate that our LSFormer achieves state-of-the-art performance compared to existing advanced Transformer-based SNNs. Notably, on the more challenging static dataset Tiny-ImageNet and neuromorphic dataset N-CALTECH101, LSFormer substantially outperforms state-of-the-art baselines by 4.3\% and 8.6\% in top-1 classification accuracy, respectively. These results highlight the potential of LSFormer to advance energy-efficient spiking models toward practical deployment in large-scale vision applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LSFormer, a Transformer-based Spiking Neural Network that replaces max pooling with Spiking Response Pooling (SPooling) to preserve representative regional features and introduces Local Structure-Aware Spiking Self-Attention (LS-SSA) via a local dilated-window mechanism to capture both local details and long-range dependencies while mitigating quadratic complexity. It claims state-of-the-art results on static and neuromorphic vision tasks, with specific top-1 accuracy gains of 4.3% on Tiny-ImageNet and 8.6% on N-CALTECH101 over prior Transformer-based SNNs.
Significance. If the gains are shown to stem from SPooling and LS-SSA under matched training conditions, the work would meaningfully advance energy-efficient hybrid SNN-Transformer models for large-scale vision by aligning attention mechanisms with SNN sparsity and reducing computational redundancy.
major comments (2)
- [Experimental Results] Experimental section: the reported 4.3% and 8.6% gains lack error bars, ablation studies isolating SPooling versus LS-SSA, and any description of training protocol or baseline re-implementation details (epochs, LR schedules, augmentations, surrogate gradients). This directly undermines attribution of the deltas to the architectural changes, as SNN performance is known to vary 3-5% with such factors.
- [Experiments] Method and Experiments: no evidence is provided that baselines were trained under identical hyper-parameter regimes; without this control the central claim that LS-SSA and SPooling break the global-attention bottleneck cannot be verified.
minor comments (1)
- [Abstract] Abstract: the phrase 'existing advanced Transformer-based SNNs' should include explicit citations to the compared methods for immediate context.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify key areas where additional experimental rigor will strengthen the manuscript. We address each major comment below and will incorporate the requested details in the revised version.
read point-by-point responses
-
Referee: [Experimental Results] Experimental section: the reported 4.3% and 8.6% gains lack error bars, ablation studies isolating SPooling versus LS-SSA, and any description of training protocol or baseline re-implementation details (epochs, LR schedules, augmentations, surrogate gradients). This directly undermines attribution of the deltas to the architectural changes, as SNN performance is known to vary 3-5% with such factors.
Authors: We agree that these elements are necessary to support attribution of the gains. In the revision we will add error bars from at least three independent runs, a full ablation table isolating SPooling, LS-SSA, and their combination, and an expanded experimental protocol section that specifies epochs, learning-rate schedules, augmentations, and surrogate-gradient implementations. We will also document that all baselines were re-implemented and trained under the identical hyper-parameter regime used for LSFormer. revision: yes
-
Referee: [Experiments] Method and Experiments: no evidence is provided that baselines were trained under identical hyper-parameter regimes; without this control the central claim that LS-SSA and SPooling break the global-attention bottleneck cannot be verified.
Authors: We accept the point. The revised manuscript will include a new subsection that tabulates all hyper-parameters (optimizer, learning-rate schedule, batch size, epochs, data augmentations, and surrogate gradient) applied uniformly to LSFormer and every baseline. This documentation will make explicit that the reported improvements result from the architectural changes rather than training discrepancies. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces LSFormer as an architectural proposal combining Spiking Response Pooling and Local Structure-Aware Spiking Self-Attention to mitigate global attention and pooling limitations in Transformer-based SNNs. The provided abstract and description contain no equations, no parameter-fitting steps presented as predictions, and no self-citation chains that bear the central claim. Performance improvements are asserted via direct experimental comparisons on Tiny-ImageNet and N-CALTECH101; these are empirical outcomes rather than quantities that reduce by construction to the method's own inputs or prior self-referential definitions. The derivation chain is therefore self-contained and does not match any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LS-SSA ... local dilated window mechanism to capture both local details and long-range dependencies ... dilation rates of 1, 2, and 3
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Spiking Response Pooling ... x(i,j) = xmax + σ(θ)·x′avg ... threshold λ
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
S. B. Furber, F. Galluppi, S. Temple, and L. A. Plana, “The spinnaker project,”Proceedings of the IEEE, vol. 102, no. 5, pp. 652–665, 2014
work page 2014
-
[2]
Trainable spiking-yolo for low-latency and high-performance object detection,
M. Yuan, C. Zhang, Z. Wang, H. Liu, G. Pan, and H. Tang, “Trainable spiking-yolo for low-latency and high-performance object detection,” Neural Networks, vol. 172, p. 106092, 2024
work page 2024
-
[3]
Event stream learning using spatio-temporal event surface,
J. Dong, R. Jiang, R. Xiao, R. Yan, and H. Tang, “Event stream learning using spatio-temporal event surface,”Neural Networks, vol. 154, pp. 543–559, 2022
work page 2022
-
[4]
L.-Y . Niu, Y . Wei, and Y . Liu, “Event-driven spiking neural network based on membrane potential modulation for remote sensing image classification,”Engineering Applications of Artificial Intelligence, vol. 123, p. 106322, 2023
work page 2023
-
[5]
Spiking neural network-based multi- task autonomous learning for mobile robots,
J. Liu, H. Lu, Y . Luo, and S. Yang, “Spiking neural network-based multi- task autonomous learning for mobile robots,”Engineering Applications of Artificial Intelligence, vol. 104, p. 104362, 2021
work page 2021
-
[6]
A spiking neural network system for robust sequence recognition,
Q. Yu, R. Yan, H. Tang, K. C. Tan, and H. Li, “A spiking neural network system for robust sequence recognition,”IEEE Transactions on Neural Networks and Learning Systems, vol. 27, no. 3, pp. 621–635, 2015
work page 2015
-
[7]
W. Gerstner, W. M. Kistler, R. Naud, and L. Paninski,Neuronal dynamics: From single neurons to networks and models of cognition. Cambridge University Press, 2014
work page 2014
-
[8]
Reliable object tracking by multimodal hybrid feature extraction and transformer-based fusion,
H. Sun, R. Liu, W. Cai, J. Wang, Y . Wang, H. Tang, Y . Cui, D. Yao, and D. Guo, “Reliable object tracking by multimodal hybrid feature extraction and transformer-based fusion,”Neural Networks, vol. 178, p. 106493, 2024
work page 2024
-
[9]
X. Tang, T. Chen, Q. Cheng, H. Shen, S. Duan, and L. Wang, “Spatio- temporal channel attention and membrane potential modulation for efficient spiking neural network,”Engineering Applications of Artificial Intelligence, vol. 148, p. 110131, 2025
work page 2025
-
[10]
Lisnn: Improving spiking neural networks with lateral interactions for robust object recognition
X. Cheng, Y . Hao, J. Xu, and B. Xu, “Lisnn: Improving spiking neural networks with lateral interactions for robust object recognition.” in IJCAI, 2020, pp. 1519–1525
work page 2020
-
[11]
Spiking-yolo: spiking neural network for energy-efficient object detection,
S. Kim, S. Park, B. Na, and S. Yoon, “Spiking-yolo: spiking neural network for energy-efficient object detection,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 07, 2020, pp. 11 270–11 277. 13
work page 2020
-
[12]
Towards spike-based machine intelligence with neuromorphic computing,
K. Roy, A. Jaiswal, and P. Panda, “Towards spike-based machine intelligence with neuromorphic computing,”Nature, vol. 575, no. 7784, pp. 607–617, 2019
work page 2019
-
[13]
Towards artificial general intelligence with hybrid tianjic chip architecture,
J. Pei, L. Deng, S. Song, M. Zhao, Y . Zhang, S. Wu, G. Wang, Z. Zou, Z. Wu, W. Heet al., “Towards artificial general intelligence with hybrid tianjic chip architecture,”Nature, vol. 572, no. 7767, pp. 106–111, 2019
work page 2019
-
[14]
S. Zhou, B. Yang, M. Yuan, R. Jiang, R. Yan, G. Pan, and H. Tang, “Enhancing snn-based spatio-temporal learning: A benchmark dataset and cross-modality attention model,”Neural Networks, vol. 180, p. 106677, 2024
work page 2024
-
[15]
Efficient learning with augmented spikes: A case study with image classification,
S. Song, C. Ma, W. Sun, J. Xu, J. Dang, and Q. Yu, “Efficient learning with augmented spikes: A case study with image classification,”Neural Networks, vol. 142, pp. 205–212, 2021
work page 2021
-
[16]
Q. Yu, M. Tsodyks, H. Sompolinsky, D. Schmitz, and R. G ¨utig, “Interactions between long- and short-term synaptic plasticity transform temporal neural representations into spatial,”Proceedings of the National Academy of Sciences, vol. 122, no. 47, p. e2426290122, 2025
work page 2025
-
[17]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in Neural Information Processing Systems, vol. 30, pp. 5998–6008, 2017
work page 2017
-
[18]
Bert: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” inPro- ceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics, 2019, pp. 4171–4186
work page 2019
-
[19]
L. Gorenstein, E. Konen, M. Green, and E. Klang, “Bidirectional encoder representations from transformers in radiology: a systematic review of natural language processing applications,”Journal of the American College of Radiology, vol. 21, no. 6, pp. 914–941, 2024
work page 2024
-
[20]
H. Zhang and M. O. Shafiq, “Survey of transformers and towards ensemble learning using transformers for natural language processing,” Journal of Big Data, vol. 11, no. 1, p. 25, 2024
work page 2024
-
[21]
Citation prediction by leveraging transformers and natural language processing heuristics,
D. Buscaldi, D. Dess ´ı, E. Motta, M. Murgia, F. Osborne, and D. R. Recupero, “Citation prediction by leveraging transformers and natural language processing heuristics,”Information Processing Management, vol. 61, no. 1, p. 103583, 2024
work page 2024
-
[22]
Hybrid multiscale spectral-spatial swin transformer for hyperspectral image classification,
M. Haidarh, C. Mu, and Y . Liu, “Hybrid multiscale spectral-spatial swin transformer for hyperspectral image classification,”Optics Laser Technology, vol. 192, p. 113923, 2025
work page 2025
-
[23]
Style mamba-transformer: A hybrid mamba-transformer unsupervised framework for text style transfer,
D. Meng, Z. Wang, W. Yan, T. Phuntsho, and T. Gonsalves, “Style mamba-transformer: A hybrid mamba-transformer unsupervised framework for text style transfer,”Knowledge-Based Systems, vol. 329, p. 114270, 2025. [Online]. Available: https://www.sciencedirect.com/ science/article/pii/S0950705125013115
work page 2025
-
[24]
Not all images are worth 16x16 words: Dynamic transformers for efficient image recognition,
Y . Wang, R. Huang, S. Song, Z. Huang, and G. Huang, “Not all images are worth 16x16 words: Dynamic transformers for efficient image recognition,”Advances in Neural Information Processing Systems, vol. 34, pp. 11 960–11 973, 2021
work page 2021
-
[25]
An image is worth 16x16 words: Trans- formers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Trans- formers for image recognition at scale,” inInternational Conference on Learning Representations, 2021
work page 2021
-
[26]
Dilateformer: Multi-scale dilated transformer for visual recognition,
J. Jiao, Y .-M. Tang, K.-Y . Lin, Y . Gao, A. J. Ma, Y . Wang, and W.-S. Zheng, “Dilateformer: Multi-scale dilated transformer for visual recognition,”IEEE Transactions on Multimedia, vol. 25, pp. 8906–8919, 2023
work page 2023
-
[27]
Tokens-to-token vit: Training vision transformers from scratch on imagenet,
L. Yuan, Y . Chen, T. Wang, W. Yu, Y . Shi, Z.-H. Jiang, F. E. Tay, J. Feng, and S. Yan, “Tokens-to-token vit: Training vision transformers from scratch on imagenet,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 558–567
work page 2021
-
[28]
Y . Fang, Z. Wang, L. Zhang, J. Cao, H. Chen, and R. Xu, “Spiking wavelet transformer,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 19–37
work page 2024
-
[29]
Spikformer: When spiking neural network meets transformer,
Z. Zhou, Y . Zhu, C. He, Y . Wang, S. Y AN, Y . Tian, and L. Yuan, “Spikformer: When spiking neural network meets transformer,” inThe Eleventh International Conference on Learning Representations, 2023. [Online]. Available: https://openreview.net/forum?id=frE4fUwz h
work page 2023
-
[30]
C. Zhou, H. Zhang, Z. Zhou, L. Yu, Z. Ma, H. Zhou, X. Fan, and Y . Tian, “Enhancing the performance of transformer-based spiking neural networks by snn-optimized downsampling with precise gradient backpropagation,”arXiv preprint arXiv:2305.05954, 2023
-
[31]
C. Zhou, L. Yu, Z. Zhou, Z. Ma, H. Zhang, H. Zhou, and Y . Tian, “Spikingformer: Spike-driven residual learning for transformer-based spiking neural network,”arXiv preprint arXiv:2304.11954, 2023
-
[32]
Tim: an efficient tem- poral interaction module for spiking transformer,
S. Shen, D. Zhao, G. Shen, and Y . Zeng, “Tim: an efficient tem- poral interaction module for spiking transformer,”arXiv preprint arXiv:2401.11687, 2024
-
[33]
M. Yao, J. Hu, Z. Zhou, L. Yuan, Y . Tian, B. Xu, and G. Li, “Spike-driven transformer,”Advances in Neural Information Processing Systems, vol. 36, pp. 64 043–64 058, 2023
work page 2023
-
[34]
Going deeper in spiking neural networks: Vgg and residual architectures,
A. Sengupta, Y . Ye, R. Wang, C. Liu, and K. Roy, “Going deeper in spiking neural networks: Vgg and residual architectures,”Frontiers in Neuroscience, vol. 13, p. 95, 2019
work page 2019
-
[35]
N. Rathi, G. Srinivasan, P. Panda, and K. Roy, “Enabling deep spiking neural networks with hybrid conversion and spike timing dependent backpropagation,”arXiv preprint arXiv:2005.01807, 2020
-
[36]
Mixed pooling for convolutional neural networks,
D. Yu, H. Wang, P. Chen, and Z. Wei, “Mixed pooling for convolutional neural networks,” inInternational Conference on Rough Sets and Knowledge Technology. Springer, 2014, pp. 364–375
work page 2014
-
[37]
M. Lin, Q. Chen, and S. Yan, “Network in network,”arXiv preprint arXiv:1312.4400, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[38]
Neighborhood attention transformer,
A. Hassani, S. Walton, J. Li, S. Li, and H. Shi, “Neighborhood attention transformer,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 6185–6194
work page 2023
-
[39]
Swin transformer: Hierarchical vision transformer using shifted windows,
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 10 012–10 022
work page 2021
-
[40]
Swin transformer v2: Scaling up capacity and resolution,
Z. Liu, H. Hu, Y . Lin, Z. Yao, Z. Xie, Y . Wei, J. Ning, Y . Cao, Z. Zhang, L. Donget al., “Swin transformer v2: Scaling up capacity and resolution,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 12 009–12 019
work page 2022
-
[41]
Dynamic texture classification using directional binarized random fea- tures,
X. Zhao, F. Xu, Y . Ma, Z. Liu, M. Deng, U. S. Khan, and Z. Xiong, “Dynamic texture classification using directional binarized random fea- tures,”IEEE Access, vol. 11, pp. 55 895–55 910, 2023
work page 2023
-
[42]
QKformer: Hierarchical spiking transformer using q-k attention,
C. Zhou, H. Zhang, Z. Zhou, L. Yu, L. Huang, X. Fan, L. Yuan, Z. Ma, H. Zhou, and Y . Tian, “QKformer: Hierarchical spiking transformer using q-k attention,” inThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
work page 2024
-
[43]
Spikingresformer: bridging resnet and vision transformer in spiking neural networks,
X. Shi, Z. Hao, and Z. Yu, “Spikingresformer: bridging resnet and vision transformer in spiking neural networks,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 5610–5619
work page 2024
-
[44]
H. Zhang, A. Sboev, R. Rybka, and Q. Yu, “Combining aggregated atten- tion and transformer architecture for accurate and efficient performance of spiking neural networks,”Neural Networks, p. 107789, 2025
work page 2025
-
[45]
Spikformer v2: Join the high accuracy club on imagenet with an snn ticket,
Z. Zhou, K. Che, W. Fang, K. Tian, Y . Zhu, S. Yan, Y . Tian, and L. Yuan, “Spikformer v2: Join the high accuracy club on imagenet with an snn ticket,”arXiv preprint arXiv:2401.02020, 2024
-
[46]
Spikingjelly: An open-source machine learning infrastructure platform for spike-based intelligence,
W. Fang, Y . Chen, J. Ding, Z. Yu, T. Masquelier, D. Chen, L. Huang, H. Zhou, G. Li, and Y . Tian, “Spikingjelly: An open-source machine learning infrastructure platform for spike-based intelligence,”Science Advances, vol. 9, no. 40, p. 1480, 2023
work page 2023
-
[47]
Impact of the sub-resting membrane potential on accurate inference in spiking neural networks,
S. Hwang, J. Chang, M.-H. Oh, J.-H. Lee, and B.-G. Park, “Impact of the sub-resting membrane potential on accurate inference in spiking neural networks,”Scientific reports, vol. 10, no. 1, p. 3515, 2020
work page 2020
-
[48]
Advancing spiking neural networks toward deep residual learning,
Y . Hu, L. Deng, Y . Wu, M. Yao, and G. Li, “Advancing spiking neural networks toward deep residual learning,”IEEE Transactions on Neural Networks and Learning Systems, vol. 36, no. 2, pp. 2353–2367, 2024
work page 2024
-
[49]
Z. Hao, X. Shi, Z. Huang, T. Bu, Z. Yu, and T. Huang, “A progressive training framework for spiking neural networks with learnable multi- hierarchical model,” inThe Twelfth International Conference on Learn- ing Representations, 2023
work page 2023
-
[50]
Learning multiple layers of features from tiny images,
A. Krizhevsky, G. Hintonet al., “Learning multiple layers of features from tiny images,” 2009
work page 2009
-
[51]
Cifar10-dvs: an event-stream dataset for object classification,
H. Li, H. Liu, X. Ji, G. Li, and L. Shi, “Cifar10-dvs: an event-stream dataset for object classification,”Frontiers in Neuroscience, vol. 11, p. 309, 2017
work page 2017
-
[52]
A low power, fully event-based gesture recognition system,
A. Amir, B. Taba, D. Berg, T. Melano, J. McKinstry, C. Di Nolfo, T. Nayak, A. Andreopoulos, G. Garreau, M. Mendozaet al., “A low power, fully event-based gesture recognition system,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 7243–7252
work page 2017
-
[53]
Converting static image datasets to spiking neuromorphic datasets using saccades,
G. Orchard, A. Jayawant, G. K. Cohen, and N. Thakor, “Converting static image datasets to spiking neuromorphic datasets using saccades,” Frontiers in Neuroscience, vol. 9, p. 437, 2015
work page 2015
-
[54]
Optimizing deeper spiking neural networks for dynamic vision sensing,
Y . Kim and P. Panda, “Optimizing deeper spiking neural networks for dynamic vision sensing,”Neural Networks, vol. 144, pp. 686–698, 2021
work page 2021
-
[55]
Spatio-temporal backpropa- gation for training high-performance spiking neural networks,
Y . Wu, L. Deng, G. Li, J. Zhu, and L. Shi, “Spatio-temporal backpropa- gation for training high-performance spiking neural networks,”Frontiers in Neuroscience, vol. 12, p. 331, 2018
work page 2018
-
[56]
Going deeper with directly-trained larger spiking neural networks,
H. Zheng, Y . Wu, L. Deng, Y . Hu, and G. Li, “Going deeper with directly-trained larger spiking neural networks,” inProceedings of the 14 AAAI Conference on Artificial Intelligence, no. 12, 2021, pp. 11 062– 11 070
work page 2021
-
[57]
Eventmix: An efficient data augmentation strategy for event-based learning,
G. Shen, D. Zhao, and Y . Zeng, “Eventmix: An efficient data augmentation strategy for event-based learning,”Information Sciences, vol. 644, p. 119170, 2023. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0020025523007557
work page 2023
-
[58]
Deep residual learning in spiking neural networks,
W. Fang, Z. Yu, Y . Chen, T. Huang, and Y . Tian, “Deep residual learning in spiking neural networks,”Advances in Neural Information Processing Systems, vol. 34, pp. 21 056–21 069, 2021
work page 2021
-
[59]
Q. Meng, M. Xiao, S. Yan, Y . Wang, Z. Lin, and Z.-Q. Luo, “Training high-performance low-latency spiking neural networks by differentiation on spike representation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 12 444–12 453
work page 2022
-
[60]
Temporal efficient training of spiking neural network via gradient re-weighting,
S. Deng, Y . Li, S. Zhang, and S. Gu, “Temporal efficient training of spiking neural network via gradient re-weighting,”arXiv preprint arXiv:2202.11946, 2022
-
[61]
Spiking deep residual networks,
Y . Hu, H. Tang, and G. Pan, “Spiking deep residual networks,”IEEE Transactions on Neural Networks and Learning Systems, vol. 34, no. 8, pp. 5200–5205, 2021
work page 2021
-
[62]
Adaptive smoothing gradient learning for spiking neural networks,
Z. Wang, R. Jiang, S. Lian, R. Yan, and H. Tang, “Adaptive smoothing gradient learning for spiking neural networks,” inInternational Confer- ence on Machine Learning. PMLR, 2023, pp. 35 798–35 816
work page 2023
-
[63]
I. Garg, S. S. Chowdhury, and K. Roy, “Dct-snn: Using dct to distribute spatial information over time for low-latency spiking neural networks,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 4671–4680
work page 2021
-
[64]
Training spiking neural networks with local tandem learning,
Q. Yang, J. Wu, M. Zhang, Y . Chua, X. Wang, and H. Li, “Training spiking neural networks with local tandem learning,”Advances in Neural Information Processing Systems, vol. 35, pp. 12 662–12 676, 2022
work page 2022
-
[65]
Z. Hao, X. Shi, Y . Liu, Z. Yu, and T. Huang, “Lm-ht snn: Enhancing the performance of snn to ann counterpart through learnable multi- hierarchical threshold model,”Advances in Neural Information Process- ing Systems, vol. 37, pp. 101 905–101 927, 2024
work page 2024
-
[66]
Z. Wu, H. Zhang, Y . Lin, G. Li, M. Wang, and Y . Tang, “Liaf-net: Leaky integrate and analog fire network for lightweight and efficient spatiotemporal information processing,”IEEE Transactions on Neural Networks and Learning Systems, vol. 33, no. 11, pp. 6249–6262, 2021
work page 2021
-
[67]
Incorporating learnable membrane time constant to enhance learning of spiking neural networks,
W. Fang, Z. Yu, Y . Chen, T. Masquelier, T. Huang, and Y . Tian, “Incorporating learnable membrane time constant to enhance learning of spiking neural networks,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 2661–2671
work page 2021
-
[68]
Event transformer +. a multi-purpose solution for efficient event data processing,
A. Sabater, L. Montesano, and A. C. Murillo, “Event transformer +. a multi-purpose solution for efficient event data processing,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 12, pp. 16 013–16 020, 2023
work page 2023
-
[69]
W. Shuihua, C. Mengmeng, L. Yang, Z. Yudong, H. Liangxiu, W. Jane, and D. Sidan, “Detection of dendritic spines using wavelet-based conditional symmetric analysis and regularized morphological shared- weight neural networks,”Computational and Mathematical Methods in Medicine, vol. 2015, pp. 1–12, 2015
work page 2015
-
[70]
Kornia: an open source differentiable computer vision library for pytorch,
E. Riba, D. Mishkin, D. Ponsa, E. Rublee, and G. Bradski, “Kornia: an open source differentiable computer vision library for pytorch,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2020, pp. 3674–3683
work page 2020
-
[71]
F.-F. Li, R. Fergus, and P. Perona, “Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories,” inConference on Computer Vision and Pattern Recognition Workshop. IEEE, 2004, pp. 178–178
work page 2004
-
[72]
Pytorch: An imperative style, high-performance deep learning library,
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antigaet al., “Pytorch: An imperative style, high-performance deep learning library,”Advances in Neural Information Processing Systems, vol. 32, 2019
work page 2019
-
[73]
R. Wightman, “Pytorch image models,” https://github.com/rwightman/ pytorch-image-models, 2019
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.