Recognition: no theorem link
Multi-Scale Dequant: Eliminating Dequantization Bottleneck via Activation Decomposition for Efficient LLM Inference
Pith reviewed 2026-05-15 02:53 UTC · model grok-4.3
The pith
Decomposing BF16 activations into low-precision scales lets quantized weights multiply directly via native GEMM.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
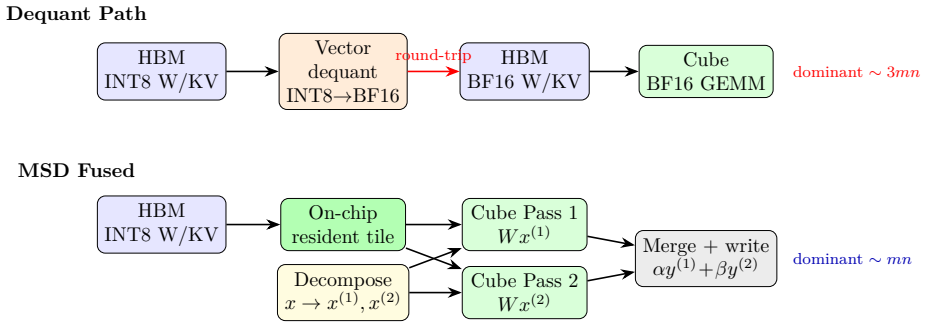
Multi-Scale Dequant removes weight and KV dequantization from the GEMM critical path by decomposing high-precision BF16 activations into multiple low-precision components. Each component is multiplied directly with the quantized weights using native hardware-accelerated GEMM. For INT8 weights (W4A16) the two-pass INT8 decomposition achieves near 16 effective bits. For MXFP4 weights (W4A16) the two-pass MXFP4 decomposition achieves near 6.6 effective bits with an error bound of 1/64 per block, surpassing single-pass MXFP8 (5.24 bits) at identical effective GEMM compute time. The approach also yields closed-form latency and HBM traffic models that predict avoidance of Vector-Cube stalls and up
What carries the argument
Multi-scale activation decomposition that splits BF16 activations into low-precision components for direct native GEMM with quantized weights
If this is right
- Two-pass INT8 decomposition reaches near 16 effective bits for W4A16 weights.
- Two-pass MXFP4 decomposition reaches near 6.6 effective bits with 1/64 per-block error bound, beating single-pass MXFP8 at the same GEMM time.
- Dequantization is removed from the critical path, eliminating Vector-Cube pipeline stalls.
- KV-cache HBM traffic drops by up to 2.5 times in attention layers.
- Numerical simulations confirm L2 error stays at or below dequantization baselines.
Where Pith is reading between the lines
- The same decomposition pattern could apply to additional low-precision formats and other accelerators that separate vector and matrix units.
- Hardware designers might add native support for multi-scale activation splits to further reduce data movement.
- Lower HBM traffic suggests measurable energy savings at scale when serving large models.
- Because simulations show accuracy preservation, full end-to-end model runs could be tested without retraining.
Load-bearing premise
The multi-scale activation decomposition can be implemented on native hardware-accelerated GEMM units without introducing pipeline stalls or accuracy loss beyond the derived error bounds.
What would settle it
Run the MSD kernels versus standard dequantized kernels on actual Ascend NPU hardware for large matrix multiplications and Flash Attention, then compare measured cycle counts, L2 error, and KV-cache traffic against the closed-form predictions.
Figures



read the original abstract
Quantization is essential for efficient large language model (LLM) inference, yet the dequantization step-converting low-bit weights back to high-precision for matrix multiplication has become a critical bottleneck on modern AI accelerators. On architectures with decoupled compute units (e.g., Ascend NPUs), dequantization operations can consume more cycles than the matrix multiplication itself, leaving the high-throughput tensor cores underutilized. This paper presents Multi-Scale Dequant (MSD), a quantization framework that removes weight/KV dequantization from the GEMM critical path. Instead of lifting low-bit weights to BF16 precision, MSD decomposes high-precision BF16 activations into multiple low-precision components, each of which can be multiplied directly with quantized weights via native hardware-accelerated GEMM. This approach shifts the computational paradigm from precision conversion to multi-scale approximation, avoiding INT8-to-BF16 weight conversion before GEMM. We instantiate MSD for two weight formats and derive tight error bounds for each. For INT8 weights (W4A16), two-pass INT8 decomposition achieves near 16 effective bits. For MXFP4 weights (W4A16), two-pass MXFP4 decomposition yields near 6.6 effective bits with error bound 1/64 per block surpassing single-pass MXFP8(5.24 bits) while maintaining the same effective GEMM compute time. We further derive closed-form latency and HBM traffic models showing that MSD avoids the Vector-Cube pipeline stall caused by dequantization and reduces KV cache HBM traffic by up to 2.5 times in attention. Numerical simulations on matrix multiplication and Flash Attention kernels confirm that MSD does not degrade accuracy compared to dequantization baselines, and in many settings achieves lower L2 error.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Multi-Scale Dequant (MSD), which decomposes BF16 activations into multiple low-precision components (INT8 or MXFP4) to perform direct GEMM with quantized weights, bypassing dequantization. For W4A16 INT8 weights, two-pass INT8 decomposition is claimed to achieve near 16 effective bits; for MXFP4 weights, near 6.6 effective bits with per-block error bound 1/64, outperforming single-pass MXFP8 while keeping the same effective GEMM time. Closed-form models for latency and HBM traffic are derived, and numerical simulations on matmul and FlashAttention confirm no accuracy degradation.
Significance. If the hardware implementation assumptions hold, MSD could substantially improve inference efficiency on decoupled accelerators by eliminating vector-cube pipeline stalls and reducing KV cache traffic by up to 2.5x, while maintaining or improving effective precision. The provision of closed-form models and error bounds is a strength, though empirical hardware validation is needed to confirm the claims.
major comments (2)
- [Abstract] The tight error bounds and closed-form latency models are asserted to be derived from first principles, but the manuscript must provide the full derivations (including any intermediate steps for the effective-bit calculations) to substantiate the 'near 16 effective bits' and '1/64 per block' claims, as these are central to the accuracy preservation argument.
- [Abstract] The assertion that MSD 'maintains the same effective GEMM compute time' and avoids pipeline stalls relies on the unverified assumption that hardware schedulers on architectures like Ascend treat the two-pass multi-scale schedule identically to single-pass dequantized GEMM; this requires hardware-level measurements or cycle-accurate simulation, as kernel-level numerical simulations alone do not address potential vector-unit contention or reordering overhead.
minor comments (2)
- [Abstract] Clarify the exact decomposition choices and constants used in the MXFP4 case to achieve the 6.6 effective bits, as the circularity note suggests these may be tuned.
- Include more details on the numerical simulation setup, such as matrix dimensions, number of trials, and specific error metrics beyond L2 error.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below, agreeing where revisions are warranted and qualifying claims where hardware assumptions are involved.
read point-by-point responses
-
Referee: [Abstract] The tight error bounds and closed-form latency models are asserted to be derived from first principles, but the manuscript must provide the full derivations (including any intermediate steps for the effective-bit calculations) to substantiate the 'near 16 effective bits' and '1/64 per block' claims, as these are central to the accuracy preservation argument.
Authors: We agree that the full derivations are essential for substantiating the central claims. In the revised manuscript we will add a new appendix that presents the complete step-by-step derivations from first principles, beginning with the multi-scale decomposition formulas, proceeding through the per-component error analysis, and arriving at the effective-bit figures (near-16 for INT8 and 6.6 for MXFP4) together with the 1/64 per-block bound. revision: yes
-
Referee: [Abstract] The assertion that MSD 'maintains the same effective GEMM compute time' and avoids pipeline stalls relies on the unverified assumption that hardware schedulers on architectures like Ascend treat the two-pass multi-scale schedule identically to single-pass dequantized GEMM; this requires hardware-level measurements or cycle-accurate simulation, as kernel-level numerical simulations alone do not address potential vector-unit contention or reordering overhead.
Authors: We acknowledge that the latency-model claim rests on an architectural assumption about scheduler behavior. Our closed-form models and numerical simulations treat the two GEMM passes as equivalent in compute time to a single dequantized GEMM, but they do not capture possible vector-unit contention or reordering costs. In the revision we will (i) add explicit caveats in the abstract and Section 3 stating that the stall-elimination claim is a theoretical prediction under the decoupled-unit model, (ii) discuss potential overhead sources, and (iii) note that hardware validation remains future work. revision: partial
- Empirical hardware measurements or cycle-accurate simulation results confirming the absence of additional pipeline stalls on Ascend NPUs, as the authors currently lack access to such hardware or simulators.
Circularity Check
No significant circularity; error bounds and latency models derived from first principles
full rationale
The paper's central derivations—tight error bounds for INT8 and MXFP4 multi-scale decompositions, closed-form latency/HBM models, and effective-bit calculations—proceed from explicit mathematical approximations and per-block analysis without reducing to fitted parameters renamed as predictions or self-citation chains. Numerical simulations on kernels serve as external verification rather than tautological confirmation. The effective-bit figures (near-16 for INT8, 6.6 for MXFP4) follow directly from the stated decomposition scales and error bounds (e.g., 1/64 per block) rather than being presupposed by construction. No load-bearing step collapses to its own inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Native hardware supports direct low-precision GEMM between decomposed activation components and quantized weights without additional conversion overhead.
- standard math Error bounds derived from two-pass decomposition are tight and hold under the block-wise quantization scheme used.
Reference graph
Works this paper leans on
-
[1]
DeepSeek.FlashMLA: Efficient MLA for Large Language Models. Technical Report, 2024. https://github.com/deepseek-ai/FlashMLA
work page 2024
-
[2]
DeepSeek.A Deep Dive Into The Flash MLA FP8 Decoding Kernel on Hopper. Technical Blog, 2025.https://github.com/deepseek-ai/FlashMLA/blob/main/docs/ 20250929-hopper-fp8-sparse-deep-dive.md
work page 2025
-
[3]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
E. Frantar, S. Ashkboos, T. Hoefler, and D. Alistarh.GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers. arXiv:2210.17323, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
J. Lin, J. Tang, H. Tang, S. Yang, X. Dang, and S. Han.AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration. arXiv:2306.00978, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
E. Frantar, R. Castro, J. Zhao, C. Hooper, M. Mahoney, and D. Alistarh.MARLIN: Mixed- Precision Auto-Regressive Parallel Inference on Large Language Models. arXiv:2408.11743, 2024
-
[6]
G. Xiao, J. Lin, M. Seznec, H. Wu, J. Demouth, and S. Han.SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models. ICML, 2023. 34
work page 2023
-
[7]
T. Dettmers, M. Lewis, Y. Belkada, and L. Zettlemoyer.LLM.int8(): 8-bit Matrix Multi- plication for Transformers at Scale. NeurIPS, 2022
work page 2022
-
[8]
Liao et al.MUL by ADD in FlashAttention Rescaling
Q. Liao et al.MUL by ADD in FlashAttention Rescaling. arXiv:2509.25224, 2025
-
[9]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
T. Dao.FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning. arXiv:2307.08691, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
T. Dao, D. Y. Fu, S. Ermon, A. Rudra, and C. Ré.FlashAttention: Fast and Memory- Efficient Exact Attention with IO-Awareness. NeurIPS, 2022
work page 2022
-
[11]
Huawei.Ascend 910 AI Processor Architecture White Paper. 2023
work page 2023
-
[12]
Huawei.CANN Toolkit Documentation, Version 8.0. 2024
work page 2024
-
[13]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvron et al.Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
DeepSeek.DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model. arXiv:2405.04434, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Wu et al.Understanding INT4 Quantization for Transformer Models
Y. Wu et al.Understanding INT4 Quantization for Transformer Models. arXiv:2306.04952, 2023
-
[16]
Park et al.LUT-GEMM: Quantized Matrix Multiplication Based on LUTs for Resource- Limited Hardware
S. Park et al.LUT-GEMM: Quantized Matrix Multiplication Based on LUTs for Resource- Limited Hardware. EMNLP Findings, 2024
work page 2024
-
[17]
J. Ainslie, J. Lee-Thorp, M. de Jong, Y. Zemlyanskiy, F. Lebrón, and S. Sanghai. GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Check- points. EMNLP, 2023
work page 2023
-
[18]
Y. Leviathan, M. Kalman, and Y. Matias.Fast Inference from Transformers via Speculative Decoding. ICML, 2023
work page 2023
-
[19]
DeepSeek.DeepSeek-V3 Technical Report. arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Y. He et al.W4A16 Mixed-Precision Matrix Multiplication on Decoupled Architecture: Ker- nel Design and Memory Bottleneck Analysis for Ascend NPUs. arXiv:2601.16536, 2026
- [21]
-
[22]
Guo et al.LiquidGEMM: Hardware-Efficient W4A8 GEMM Kernel for High- Performance LLM Serving
J. Guo et al.LiquidGEMM: Hardware-Efficient W4A8 GEMM Kernel for High- Performance LLM Serving. arXiv:2509.01229, 2025
-
[23]
Zhang et al.Efficient Mixed-Precision Large Language Model Inference with TurboMind
Y. Zhang et al.Efficient Mixed-Precision Large Language Model Inference with TurboMind. arXiv:2508.15601, 2025
-
[24]
Zeng et al.ABQ-LLM: Arbitrary-Bit Quantized Inference Acceleration for Large Lan- guage Models
C. Zeng et al.ABQ-LLM: Arbitrary-Bit Quantized Inference Acceleration for Large Lan- guage Models. AAAI, 2025. 35
work page 2025
-
[25]
Xu et al.MixPE: Quantization and Hardware Co-design for Efficient LLM Inference
Y. Xu et al.MixPE: Quantization and Hardware Co-design for Efficient LLM Inference. arXiv:2411.16158, 2024
-
[26]
Mo et al.LUT Tensor Core: Lookup Table Enables Efficient Low-Bit LLM Inference Acceleration
Z. Mo et al.LUT Tensor Core: Lookup Table Enables Efficient Low-Bit LLM Inference Acceleration. ISCA, 2025
work page 2025
-
[27]
Li et al.T-MAN: Enabling End-to-End Low-Bit LLM Inference on NPUs via Unified Table Lookup
Q. Li et al.T-MAN: Enabling End-to-End Low-Bit LLM Inference on NPUs via Unified Table Lookup. arXiv:2511.11248, 2025
-
[28]
J. Jang, Y. Kim, J. Lee, and J.-J. Kim.FIGNA: Integer Unit-Based Accelerator Design for FP-INT GEMM Preserving Numerical Accuracy. HPCA, 2024
work page 2024
-
[29]
Shalby et al.DQT: Dynamic Quantization Training via Dequantization-Free Nested Integer Arithmetic
H. Shalby et al.DQT: Dynamic Quantization Training via Dequantization-Free Nested Integer Arithmetic. arXiv:2508.09176, 2025
-
[30]
arXiv preprint arXiv:2310.10537 , year=
R. Rouhani et al.Microscaling Data Formats for Deep Learning. arXiv:2310.10537, 2023. 36
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.