Recognition: 2 theorem links
· Lean TheoremWahkon: A Statistically Principled Deep RKHS Superposition Network
Pith reviewed 2026-05-15 02:03 UTC · model grok-4.3
The pith
Wahkon shows a deep RKHS superposition network's penalized estimator is exactly the MAP estimate under a hierarchical Gaussian-process prior.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Wahkon unifies Kolmogorov's superposition principle with RKHS regularization to create a deep network whose penalized estimator is precisely the MAP estimate under a hierarchical Gaussian-process prior. This extends the spline/GP duality to deep compositions and, via metric-entropy arguments, establishes minimax-optimal convergence rates under mild smoothness conditions. The finite-dimensional deep representer theorem renders training tractable with explicit layerwise complexity control.
What carries the argument
the finite-dimensional deep representer theorem, which reduces the infinite-dimensional optimization over the deep superposition to a finite-dimensional problem while preserving the statistical properties of the hierarchical Gaussian-process prior
If this is right
- Training becomes computationally tractable because the representer theorem reduces the problem to finite dimensions.
- Layerwise complexity is controlled explicitly through the regularization parameters at each layer.
- Minimax-optimal convergence rates hold under mild smoothness assumptions on the target function.
- The Gaussian-process interpretation supplies calibrated uncertainty quantification alongside point predictions.
Where Pith is reading between the lines
- The same unification might extend to other kernel families or non-Gaussian priors while keeping the representer property.
- Layerwise regularization could offer new ways to diagnose how depth and width interact with the regularity of the approximated function.
- Domains that already use spline or Gaussian-process methods, such as spatial statistics or functional data analysis, could adopt the deep version for higher-dimensional inputs.
Load-bearing premise
The hierarchical Gaussian-process prior and the mild smoothness conditions on the target function are sufficient for the finite-dimensional deep representer theorem to hold and for the convergence rates to be achieved.
What would settle it
A simulation in which the penalized estimator deviates from the MAP estimate computed directly under the specified hierarchical Gaussian-process prior, or empirical convergence rates that fail to match the predicted minimax-optimal bounds as sample size increases.
Figures
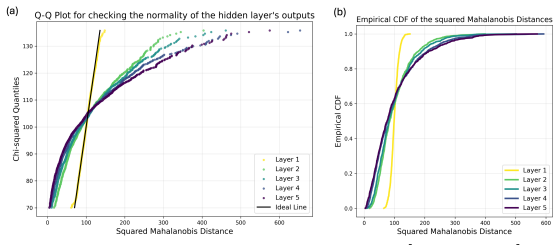



read the original abstract
Deep learning excels at prediction but often lacks finite-sample guarantees and calibrated uncertainty; RKHS (Reproducing Kernel Hilbert Space)-based methods provide those guarantees but struggle to adapt in high dimensions. We propose Wahkon, a deep RKHS superposition network that unifies Kolmogorov's superposition principle with RKHS regularization in the smoothing-spline tradition of Wahba. This yields a finite-dimensional deep representer theorem that makes training tractable and provides explicit layerwise complexity control. We show the penalized estimator is exactly the MAP (maximum a posteriori) estimate under a hierarchical Gaussian-process prior, extending the spline/GP duality to deep compositions. Using metric-entropy arguments, we establish minimax-optimal convergence rates under mild smoothness and clarify how depth and width trade off with regularity. Empirically, Wahkon outperforms multilayer perceptrons, Neural Tangent Kernels, and Kolmogorov--Arnold Networks across simulation benchmarks and a single-cell CITE-seq study. By unifying Kolmogorov's superposition principle with RKHS regularization, Wahkon delivers accuracy, interpretability, and statistical rigor in a single framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Wahkon, a deep RKHS superposition network integrating Kolmogorov's superposition principle with RKHS regularization in the smoothing-spline tradition. It claims a finite-dimensional deep representer theorem enabling tractable training with layerwise complexity control, shows that the penalized estimator is exactly the MAP estimate under a hierarchical Gaussian-process prior (extending the spline/GP duality to deep compositions), establishes minimax-optimal convergence rates via metric-entropy arguments under mild smoothness, and reports empirical superiority over MLPs, NTKs, and KANs on simulations and single-cell CITE-seq data.
Significance. If the MAP equivalence and rate results hold with the stated conditions, the work would be significant for supplying finite-sample guarantees, calibrated uncertainty, and optimal rates to deep networks while preserving interpretability through explicit regularization. It merits credit for attempting a rigorous unification of Kolmogorov superposition with the RKHS/GP framework and for deriving depth-width-regularity trade-offs from entropy bounds.
major comments (3)
- Abstract: The claim that the penalized estimator is exactly the MAP under a hierarchical GP prior risks circularity if the prior is constructed to reproduce the deep penalized loss (outer RKHS norm plus induced inner-layer penalties) rather than being specified independently of the data and objective.
- Representer theorem section: The finite-dimensional deep representer theorem for Kolmogorov superpositions may fail to hold under only mild smoothness, because the inner functions are arbitrary continuous maps whose RKHS membership and complexity are not automatically controlled by the target's smoothness alone.
- Convergence rates section: The metric-entropy argument for minimax rates requires explicit confirmation that the entropy numbers of the deep function class depend only on the target's mild smoothness and not on post-hoc choices of layerwise regularization parameters or hidden fitting steps.
minor comments (2)
- Empirical section: Provide the precise simulation settings, hyperparameter selection protocol, and quantitative metrics (including error bars) for the CITE-seq study to support reproducibility.
- Notation: Define the layerwise regularization parameters explicitly at first use and maintain consistent symbols across the hierarchical prior and penalized objective.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment point by point below, clarifying the construction of the prior, the conditions for the representer theorem, and the entropy bounds. Revisions will be made to strengthen the presentation.
read point-by-point responses
-
Referee: Abstract: The claim that the penalized estimator is exactly the MAP under a hierarchical GP prior risks circularity if the prior is constructed to reproduce the deep penalized loss (outer RKHS norm plus induced inner-layer penalties) rather than being specified independently of the data and objective.
Authors: The hierarchical Gaussian-process prior is specified independently of the data and objective, following the Kolmogorov superposition structure with layerwise RKHS norms chosen to extend the classical spline-GP duality. The MAP equivalence is then derived as a direct consequence of this prior. We will revise the abstract and introduction to state explicitly that the prior is defined a priori from the model architecture and regularization, rather than reverse-engineered from the loss. revision: yes
-
Referee: Representer theorem section: The finite-dimensional deep representer theorem for Kolmogorov superpositions may fail to hold under only mild smoothness, because the inner functions are arbitrary continuous maps whose RKHS membership and complexity are not automatically controlled by the target's smoothness alone.
Authors: The inner functions are not arbitrary continuous maps; they are constrained to lie in RKHSs whose norms appear explicitly in the penalized objective, which directly controls their complexity. Under the mild smoothness assumption on the target and the Kolmogorov representation, the existence of inner functions with bounded RKHS norms follows from the superposition. We will expand the representer theorem section with an additional paragraph detailing how the target's smoothness propagates to bound the inner-function norms. revision: yes
-
Referee: Convergence rates section: The metric-entropy argument for minimax rates requires explicit confirmation that the entropy numbers of the deep function class depend only on the target's mild smoothness and not on post-hoc choices of layerwise regularization parameters or hidden fitting steps.
Authors: The metric entropy of the deep function class is bounded using the covering numbers of the RKHS balls whose radii are determined solely by the smoothness parameters of the target function class. The layerwise regularization parameters are selected as functions of sample size and smoothness to attain the rate, but they do not enter the entropy bound itself. We will add a short lemma or remark in the convergence rates section confirming that the entropy numbers depend only on the target's smoothness. revision: yes
Circularity Check
MAP equivalence is definitional once hierarchical prior is chosen to match the deep penalized loss
specific steps
-
self definitional
[Abstract]
"We show the penalized estimator is exactly the MAP (maximum a posteriori) estimate under a hierarchical Gaussian-process prior, extending the spline/GP duality to deep compositions."
The hierarchical prior is specified so that its negative log-density equals the sum of outer and inner-layer RKHS penalties; once this prior is adopted, the MAP estimator is identical to the penalized estimator by definition of the prior, not as a non-trivial consequence of the model.
full rationale
The paper's load-bearing statistical claim is that the penalized estimator equals the MAP under a hierarchical GP prior. This equivalence is obtained by defining the prior (layerwise RKHS norms as precision operators) so its negative log posterior reproduces the objective exactly, extending the classical spline-GP duality by construction rather than deriving it from independent assumptions. Metric-entropy bounds on convergence rates appear to rest on separate arguments and are not obviously circular, but the central 'exactly MAP' statement reduces to the prior definition. No self-citation load-bearing or ansatz smuggling is visible in the provided text.
Axiom & Free-Parameter Ledger
free parameters (1)
- layerwise regularization parameters
axioms (2)
- standard math Kolmogorov superposition theorem applies to the function class of interest
- domain assumption hierarchical GP prior yields the RKHS penalty after marginalization
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We show the penalized estimator is exactly the MAP estimate under a hierarchical Gaussian-process prior, extending the spline/GP duality to deep compositions. Using metric-entropy arguments, we establish minimax-optimal convergence rates under mild smoothness
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 3.1 (Deep representer theorem). ... ϕ(l)_jk(t) = sum c(l)_ijk K(x(l-1)_ik, t)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Doklady Akademii Nauk SSSR , volume =
On the Representation of Continuous Functions of Several Variables by Superposition of Continuous Functions of One Variable and Addition , author =. Doklady Akademii Nauk SSSR , volume =. 1957 , note =
work page 1957
- [2]
-
[3]
Gaussian Processes for Machine Learning , author =. 2006 , publisher =
work page 2006
-
[4]
Advances in Neural Information Processing Systems 13 (NIPS 2000) , pages =
Using the Nystr\"om Method to Speed Up Kernel Machines , author =. Advances in Neural Information Processing Systems 13 (NIPS 2000) , pages =
work page 2000
-
[5]
Advances in Neural Information Processing Systems 20 (NIPS 2007) , pages =
Random Features for Large-Scale Kernel Machines , author =. Advances in Neural Information Processing Systems 20 (NIPS 2007) , pages =
work page 2007
-
[6]
Nature Communications , volume=
EOMES interacts with RUNX3 and BRG1 to promote innate memory cell formation through epigenetic reprogramming , author=. Nature Communications , volume=. 2019 , publisher=
work page 2019
- [7]
-
[8]
IEEE Transactions on Information Theory , volume =
Universal Approximation Bounds for Superpositions of a Sigmoidal Function , author =. IEEE Transactions on Information Theory , volume =. 1993 , publisher =
work page 1993
-
[9]
Function Spaces, Entropy Numbers, Differential Operators , author=. 1996 , publisher=
work page 1996
-
[10]
On deep learning as a remedy for the curse of dimensionality in nonparametric regression , author=
- [11]
-
[12]
Mathematics of Control, Signals, and Systems , volume=
Approximation by superpositions of a sigmoidal function , author=. Mathematics of Control, Signals, and Systems , volume=. 1989 , publisher=
work page 1989
-
[13]
Conference on Learning Theory (COLT) , pages=
The power of depth for feedforward neural networks , author=. Conference on Learning Theory (COLT) , pages=. 2016 , organization=
work page 2016
-
[14]
Simultaneous epitope and transcriptome measurement in single cells , author=. Nature methods , volume=. 2018 , publisher=
work page 2018
-
[15]
Fast, sensitive and accurate integration of single-cell data with Harmony , author=. Nature methods , volume=. 2019 , publisher=
work page 2019
-
[16]
Deep Learning , author=
- [17]
- [18]
-
[19]
The Llama 3 Herd of Models , author =. arXiv preprint arXiv:2407.21783 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Lecture Notes in Statistics , volume=
Bayesian Learning for Neural Networks , author=. Lecture Notes in Statistics , volume=. 1996 , publisher=
work page 1996
-
[21]
International Conference on Learning Representations , year=
Deep Neural Networks as Gaussian Processes , author=. International Conference on Learning Representations , year=
-
[22]
Journal of the American Statistical Association , pages=
Bisection Grover’s Search Algorithm and Its Application in Analyzing CITE-seq Data , author=. Journal of the American Statistical Association , pages=. 2024 , publisher=
work page 2024
-
[23]
and Hao, Yuhan and Stoeckius, Marlon and Smibert, Peter and Satija, Rahul , title =
Stuart, Tim and Butler, Andrew and Hoffman, Paul and Hafemeister, Christoph and Papalexi, Efthymia and Mauck, William M. and Hao, Yuhan and Stoeckius, Marlon and Smibert, Peter and Satija, Rahul , title =. Cell , volume =
-
[24]
A distribution-free theory of nonparametric regression , author=. 2006 , publisher=
work page 2006
-
[25]
Orthogonal multimodality integration and clustering in single-cell data , author=. BMC bioinformatics , volume=. 2024 , publisher=
work page 2024
-
[26]
Journal of the american statistical association , volume=
Bayes factors , author=. Journal of the american statistical association , volume=. 1995 , publisher=
work page 1995
-
[27]
Large-scale simultaneous measurement of epitopes and transcriptomes in single cells , author=. Nature methods , volume=. 2017 , publisher=
work page 2017
-
[28]
Advances in Neural Information Processing Systems , volume=
Neural Tangent Kernel: Convergence and Generalization in Neural Networks , author=. Advances in Neural Information Processing Systems , volume=
- [29]
-
[30]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Improper priors, spline smoothing and the problem of guarding against model errors in regression , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 1978 , publisher=
work page 1978
- [31]
- [32]
-
[33]
KAN: Kolmogorov-Arnold Networks
Liu, Ziming and Wang, Yixuan and Vaidya, Sachin and Ruehle, Fabian and Halverson, James and Solja. arXiv preprint arXiv:2404.19756 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
arXiv preprint arXiv:2112.09963 , year=
The kolmogorov superposition theorem can break the curse of dimensionality when approximating high dimensional functions , author=. arXiv preprint arXiv:2112.09963 , year=
-
[35]
Advances in neural information processing systems , volume=
Practical bayesian optimization of machine learning algorithms , author=. Advances in neural information processing systems , volume=
-
[36]
arXiv preprint arXiv:2404.11599 , year=
Variational Bayesian last layers , author=. arXiv preprint arXiv:2404.11599 , year=
-
[37]
Journal of the American Statistical Association , volume=
Bisection Grover’s search algorithm and its application in analyzing CITE-seq data , author=. Journal of the American Statistical Association , volume=. 2025 , publisher=
work page 2025
-
[38]
International Conference on Learning Representations (ICLR) , year=
Neural Tangents: Fast and Easy Infinite Neural Networks in Python , author=. International Conference on Learning Representations (ICLR) , year=
-
[39]
Advances in neural information processing systems , volume=
Wide neural networks of any depth evolve as linear models under gradient descent , author=. Advances in neural information processing systems , volume=
-
[40]
Neural networks: Tricks of the trade , pages=
Efficient backprop , author=. Neural networks: Tricks of the trade , pages=. 2002 , publisher=
work page 2002
-
[41]
Nonparametric regression using deep neural networks with
Schmidt-Hieber, Johannes , journal=. Nonparametric regression using deep neural networks with
-
[42]
The Annals of Statistics , volume=
On the rate of convergence of fully connected deep neural network regression estimates , author=. The Annals of Statistics , volume=
-
[43]
Artificial intelligence and statistics , pages=
Deep kernel learning , author=. Artificial intelligence and statistics , pages=. 2016 , organization=
work page 2016
-
[44]
Annals of Statistics , volume=
Rate-optimal estimation for a general class of nonparametric regression models with unknown link functions , author=. Annals of Statistics , volume=
-
[45]
A selective overview of deep learning , author=. Statistical Science , volume=
- [46]
- [47]
- [48]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.