Recognition: no theorem link
Evolving Layer-Specific Scalar Functions for Hardware-Aware Transformer Adaptation
Pith reviewed 2026-05-15 05:36 UTC · model grok-4.3
The pith
Genetic programming evolves layer-specific scalar functions to replace layer normalization in Vision Transformers, recovering 84.25 percent Top-1 accuracy after only 20 epochs of re-alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
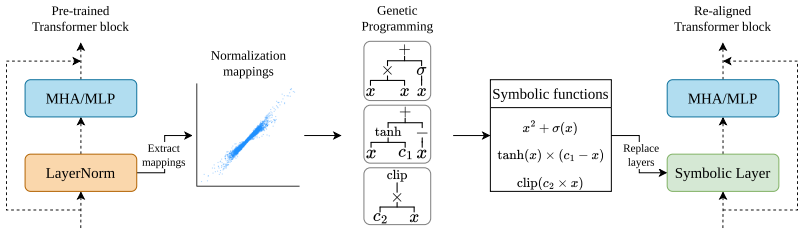
By evolving heterogeneous, layer-specific scalar functions directly from pre-trained weights using genetic programming and applying a post-training re-alignment strategy, the modified Vision Transformer architecture approximates the target normalization behaviors with an R² of 91.6 percent, compared to 70.2 percent for homogeneous baselines, and recovers 84.25 percent Top-1 accuracy on ImageNet-1K in only 20 epochs while eliminating the global reduction bottleneck.
What carries the argument
Genetic programming that evolves layer-specific scalar functions from pre-trained weights, paired with a post-training re-alignment strategy that restores accuracy without full retraining.
If this is right
- The modified architecture eliminates the global reduction bottleneck of layer normalization.
- It achieves a favorable trade-off between arithmetic complexity and off-chip memory traffic.
- The models become suitable for efficient deployment on edge accelerators.
- High accuracy is recovered with far less training effort than full retraining.
Where Pith is reading between the lines
- The same evolution process could be applied to other normalization layers or transformer blocks beyond vision models.
- Hardware-specific cost functions inside the genetic programming loop might further tailor the scalars to particular accelerators.
- The approach opens a path to fully static, reduction-free transformer inference pipelines on memory-constrained devices.
Load-bearing premise
Functions evolved from pre-trained weights will generalize to unseen inputs and the brief re-alignment step will restore performance without requiring full retraining from scratch.
What would settle it
Apply the evolved per-layer scalars to a Vision Transformer on ImageNet-1K and run the 20-epoch re-alignment; if Top-1 accuracy stays below 80 percent while the R² on held-out activation statistics falls below 80 percent, the central claim is falsified.
Figures






read the original abstract
Vision Transformers (ViTs) achieve state-of-the-art performance on challenging vision tasks, but their deployment on edge devices is severely hindered by the computational complexity and global reduction bottleneck imposed by layer normalization. Recent methods attempt to bypass this by replacing normalization layers with hardware-friendly scalar approximations. However, these homogeneous replacements do not optimally fit to all layers' behaviour and rely on expensive model retraining. In this work, we propose a highly efficient, hardware-aware framework that utilizes genetic programming (GP) to evolve heterogeneous, layer-specific scalar functions directly from pre-trained weights. Coupled with a novel post-training re-alignment strategy, our approach eliminates the need to retrain models from scratch entirely. Our evolved expressions accurately approximate the target normalization behaviours, capturing $91.6\%$ of the variance ($R^2$) compared to only $70.2\%$ for homogeneous baselines, allowing our modified architecture to recover $84.25\%$ Top-1 ImageNet-1K accuracy in only 20 epochs. By preserving this performance while eliminating the global reduction bottleneck, our approach establishes a highly favourable trade-off between arithmetic complexity and off-chip memory traffic, removing a primary barrier to the efficient deployment of ViTs on edge accelerators.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes evolving heterogeneous, layer-specific scalar functions via genetic programming (GP) to replace layer normalization in Vision Transformers. These functions are derived directly from pre-trained weights and paired with a post-training re-alignment procedure that avoids full retraining from scratch. The central empirical claims are that the evolved expressions achieve R² = 91.6 % (versus 70.2 % for homogeneous baselines) and enable recovery of 84.25 % Top-1 accuracy on ImageNet-1K after only 20 epochs while removing the global reduction bottleneck.
Significance. If the reported approximation quality and accuracy recovery hold under proper generalization tests, the work would provide a practical route to hardware-efficient ViT inference on edge accelerators by trading a modest amount of arithmetic for reduced off-chip memory traffic. The combination of GP-driven heterogeneity and lightweight re-alignment is a concrete contribution to hardware-aware model adaptation.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experimental Results): the headline R² = 91.6 % and 84.25 % Top-1 figures are reported without any explicit measurement of the evolved scalar functions on held-out validation activations before re-alignment. Because GP fitness is computed on training-split activations of the pre-trained model, any distributional shift on unseen inputs could degrade the approximation; the 20-epoch re-alignment may therefore be compensating for poor generalization rather than polishing an already faithful replacement.
- [§3.2] §3.2 (Re-alignment Strategy): the claim that post-training re-alignment is sufficient to restore performance rests on an untested assumption that the evolved scalars remain close to the original normalization statistics under the small distributional change induced by the modified layers. No ablation isolating the contribution of the GP functions versus the re-alignment alone is provided.
minor comments (1)
- [Abstract] Abstract: the phrase 'hardware-friendly scalar approximations' is used without enumerating the exact arithmetic operations (add, mul, etc.) present in the final evolved expressions; this information is needed to quantify the claimed reduction in arithmetic complexity and memory traffic.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our work. We provide point-by-point responses to the major comments below and have made revisions to the manuscript to address the concerns raised.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experimental Results): the headline R² = 91.6 % and 84.25 % Top-1 figures are reported without any explicit measurement of the evolved scalar functions on held-out validation activations before re-alignment. Because GP fitness is computed on training-split activations of the pre-trained model, any distributional shift on unseen inputs could degrade the approximation; the 20-epoch re-alignment may therefore be compensating for poor generalization rather than polishing an already faithful replacement.
Authors: We thank the referee for pointing this out. While the fitness evaluation during GP evolution was based on training activations, we have added an evaluation of the evolved scalar functions' approximation quality on held-out validation activations in the revised manuscript. The results indicate that the R² remains high on unseen data, suggesting good generalization of the layer-specific functions. Consequently, the 20-epoch re-alignment serves to adapt the model to the modified normalization layers for optimal task performance rather than merely correcting for generalization issues. We have incorporated these findings into §4 and updated the abstract. revision: yes
-
Referee: [§3.2] §3.2 (Re-alignment Strategy): the claim that post-training re-alignment is sufficient to restore performance rests on an untested assumption that the evolved scalars remain close to the original normalization statistics under the small distributional change induced by the modified layers. No ablation isolating the contribution of the GP functions versus the re-alignment alone is provided.
Authors: We concur that providing an ablation to separate the effects of the GP-evolved functions from the re-alignment procedure would strengthen the claims. In the revised manuscript, we include such an ablation study in which we perform the re-alignment using homogeneous scalar replacements instead of the heterogeneous GP functions. This demonstrates the superior performance enabled by the layer-specific evolved expressions. The updated §3.2 now discusses this assumption with supporting evidence from the ablation. revision: yes
Circularity Check
No significant circularity; central claims are empirical measurements
full rationale
The paper's derivation chain consists of applying genetic programming to evolve layer-specific scalar functions from pre-trained activations, followed by a post-training re-alignment procedure whose outcomes are measured directly on ImageNet-1K (91.6% R² approximation quality and 84.25% Top-1 accuracy after 20 epochs). These quantities are reported as experimental results rather than derived from equations that reduce to the fitted inputs by construction. No self-citation is load-bearing for the core performance claims, no uniqueness theorem or ansatz is smuggled in to force the result, and the reported metrics do not rename a known result or equate a prediction to its own training fitness by definition. The approach is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[2]
Jinfeng Cao, Bo Peng, Mingzhong Gao, Haichun Hao, Xinfang Li, and Hongwei Mou. Object detection based on cnn and vision-transformer: A survey.IET Computer Vision, 19(1):e70028, 2025
work page 2025
-
[3]
End-to-end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. InEuropean Conference on Computer Vision, pages 213–229. Springer, 2020
work page 2020
-
[4]
Hans Thisanke, Chamli Deshan, Kavindu Chamith, Sachith Seneviratne, Rajith Vidanaarachchi, and Damayanthi Herath. Semantic segmentation using vision transformers: A survey.Engineering Applications of Artificial Intelligence, 126:106669, 2023
work page 2023
-
[5]
Maithra Raghu, Thomas Unterthiner, Simon Kornblith, Chiyuan Zhang, and Alexey Dosovitskiy. Do vision transformers see like convolutional neural networks?Advances in Neural Information Processing Systems, 34:12116–12128, 2021
work page 2021
-
[6]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10012–10022, 2021
work page 2021
-
[7]
Refining datapath for microscaling vits
Can Xiao, Jianyi Cheng, and Yiren Zhao. Refining datapath for microscaling vits. In2025 35th International Conference on Field-Programmable Logic and Applications (FPL), pages 263–272. IEEE, 2025
work page 2025
-
[8]
Peano-vit: Power- efficient approximations of non-linearities in vision transformers
Mohammad Erfan Sadeghi, Arash Fayyazi, Seyedarmin Azizi, and Massoud Pedram. Peano-vit: Power- efficient approximations of non-linearities in vision transformers. InProceedings of the 29th ACM/IEEE International Symposium on Low Power Electronics and Design, pages 1–6, 2024
work page 2024
-
[9]
Zhixiong Zhao, Haomin Li, Fangxin Liu, Yuncheng Lu, Zongwu Wang, Tao Yang, Li Jiang, and Haibing Guan. Quark: Quantization-enabled circuit sharing for transformer acceleration by exploiting common patterns in nonlinear operations. In2025 IEEE/ACM International Conference On Computer Aided Design (ICCAD), pages 1–9. IEEE, 2025
work page 2025
-
[10]
Me-vit: A single-load memory-efficient fpga accelerator for vision transformers
Kyle Marino, Pengmiao Zhang, and Viktor K Prasanna. Me-vit: A single-load memory-efficient fpga accelerator for vision transformers. In2023 IEEE 30th International Conference on High Performance Computing, Data, and Analytics (HiPC), pages 213–223. IEEE, 2023
work page 2023
-
[11]
Integer quantization of nonlinear operations towards hardware-friendly vits
Tianyi Sun, Tuo Ma, Jiali Liu, Zhiwei Li, Qingjiang Li, Yinan Wang, Haijun Liu, and Sen Liu. Integer quantization of nonlinear operations towards hardware-friendly vits. In2025 32nd IEEE International Conference on Electronics, Circuits and Systems (ICECS), pages 1–4. IEEE, 2025
work page 2025
-
[12]
Bin Xu, Ayan Banerjee, and Sandeep Gupta. Hardware acceleration for neural networks: A comprehensive survey.arXiv preprint arXiv:2512.23914, 2025
-
[13]
Vita: A highly efficient dataflow and architecture for vision transformers
Chunyun Chen, Lantian Li, and Mohamed M Sabry Aly. Vita: A highly efficient dataflow and architecture for vision transformers. In2024 Design, Automation & Test in Europe Conference & Exhibition (DATE), pages 1–6. IEEE, 2024. 10
work page 2024
-
[14]
Improving the efficiency of transformers for resource-constrained devices
Hamid Tabani, Ajay Balasubramaniam, Shabbir Marzban, Elahe Arani, and Bahram Zonooz. Improving the efficiency of transformers for resource-constrained devices. In2021 24th Euromicro Conference on Digital System Design (DSD), pages 449–456. IEEE, 2021
work page 2021
-
[15]
Ziyang Chen, Ming Hao, Xinye Cao, Jingwei Zhang, Chaoyao Shen, Guoqing Li, and Meng Zhang. Hardware-friendly and efficient vision transformer for deployment on low-power embedded device.Journal of Low Power Electronics and Applications, 16(1):1, 2025
work page 2025
-
[16]
Raehyeong Kim, Dayoung Lee, Jinyeol Kim, Joungmin Park, and Seung Eun Lee. Hardware accelerator for approximation-based softmax and layer normalization in transformers.Electronics, 14(12):2337, 2025
work page 2025
-
[17]
Jemin Lee, Yongin Kwon, Sihyeong Park, Misun Yu, Jeman Park, and Hwanjun Song. Q-hyvit: Post- training quantization of hybrid vision transformers with bridge block reconstruction for iot systems.IEEE Internet of Things Journal, 11(22):36384–36396, 2024
work page 2024
-
[18]
Nn-lut: Neural approximation of non-linear operations for efficient transformer inference
Joonsang Yu, Junki Park, Seongmin Park, Minsoo Kim, Sihwa Lee, Dong Hyun Lee, and Jungwook Choi. Nn-lut: Neural approximation of non-linear operations for efficient transformer inference. InProceedings of the 59th ACM/IEEE Design Automation Conference, pages 577–582, 2022
work page 2022
-
[19]
Jung, Arpan Suravi Prasad, Francesco Conti, and Luca Benini
Severin Bochem, Victor J.B. Jung, Arpan Suravi Prasad, Francesco Conti, and Luca Benini. Distributed inference with minimal off-chip traffic for transformers on low-power MCUs. In2025 Design, Automation & Test in Europe Conference (DATE), pages 1–7, 2025. doi: 10.23919/DATE64628.2025.10992712
-
[20]
Yikan Qiu, Guoxiang Li, Meng Wu, Yifan Jia, Le Ye, and Yufei Ma. Quartet: A digital compute-in-memory versatile AI accelerator with heterogeneous tensor engines and off-chip-less dataflow.IEEE Transactions on Circuits and Systems I: Regular Papers, 73(1):370–383, 2026. doi: 10.1109/TCSI.2025.3598287
-
[21]
Transformers without normalization
Jiachen Zhu, Xinlei Chen, Kaiming He, Yann LeCun, and Zhuang Liu. Transformers without normalization. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14901–14911, 2025
work page 2025
-
[22]
John R Koza. Genetic programming as a means for programming computers by natural selection.Statistics and Computing, 4(2):87–112, 1994
work page 1994
-
[23]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255. Ieee, 2009
work page 2009
-
[24]
Ross Wightman. Pytorch image models. https://github.com/rwightman/pytorch-image-models, 2019
work page 2019
-
[25]
Kozax: flexible and scalable genetic programming in jax
Sigur De Vries, Sander Wessel Keemink, and Marcel Antonius Johannes van Gerven. Kozax: flexible and scalable genetic programming in jax. InProceedings of the Genetic and Evolutionary Computation Conference Companion, pages 603–606, 2025
work page 2025
-
[26]
Kalyanmoy Deb, Amrit Pratap, Sameer Agarwal, and TAMT Meyarivan. A fast and elitist multiobjective genetic algorithm: Nsga-ii.IEEE Transactions on Evolutionary Computation, 6(2):182–197, 2002
work page 2002
-
[27]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[28]
Yu-Hsin Chen, Tushar Krishna, Joel S. Emer, and Vivienne Sze. Eyeriss: An energy-efficient reconfigurable accelerator for deep convolutional neural networks.IEEE Journal of Solid-State Circuits, 52(1):127–138,
-
[29]
doi: 10.1109/JSSC.2016.2616357
-
[30]
Kyungmi Lee, Gaurab Das, Donghyeon Han, and Anantha P. Chandrakasan. Securing DNN acceleration from off-chip memory vulnerabilities with low-overhead authenticated encryption.IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 34(3):953–966, 2026. doi: 10.1109/TVLSI.2025.3650411
-
[31]
Higham.Accuracy and Stability of Numerical Algorithms
Nicholas J. Higham.Accuracy and Stability of Numerical Algorithms. Society for Industrial and Applied Mathematics, 2nd edition, 2002. ISBN 0898715210
work page 2002
-
[32]
Methods of computing values of polynomials.Russian Mathematical Surveys, 21(1):105–136, 1966
V Ya Pan. Methods of computing values of polynomials.Russian Mathematical Surveys, 21(1):105–136, 1966
work page 1966
-
[33]
Sangyeob Kim, Sangjin Kim, Wooyoung Jo, Soyeon Kim, Seongyon Hong, and Hoi-Jun Yoo. C- transformer: A 2.6-18.1 µJ/Token homogeneous DNN-transformer/spiking-transformer processor with big-little network and implicit weight generation for large language models. In2024 IEEE International Solid-State Circuits Conference (ISSCC), volume 67, pages 368–370, 2024...
-
[34]
Seunghyun Moon, Mao Li, Gregory K. Chen, Phil C. Knag, Ram Kumar Krishnamurthy, and Mingoo Seok. T-REX: A 68-to-567µs/Token 0.41-to-3.95µJ/Token transformer accelerator with reduced external memory access and enhanced hardware utilization in 16nm FinFET. In2025 IEEE International Solid-State Circuits Conference (ISSCC), volume 68, pages 406–408, 2025. doi...
-
[35]
Miles Cranmer, Alvaro Sanchez Gonzalez, Peter Battaglia, Rui Xu, Kyle Cranmer, David Spergel, and Shirley Ho. Discovering symbolic models from deep learning with inductive biases.Advances in Neural Information Processing Systems, 33:17429–17442, 2020
work page 2020
-
[36]
Training data-efficient image transformers & distillation through attention
Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Hervé Jégou. Training data-efficient image transformers & distillation through attention. InInternational Conference on Machine Learning, pages 10347–10357. PMLR, 2021
work page 2021
-
[37]
Jean-Michel Muller, Nicolas Brunie, Florent De Dinechin, Claude-Pierre Jeannerod, Mioara Joldes, Vincent Lefèvre, Guillaume Melquiond, Nathalie Revol, and Serge Torres.Handbook of Floating-Point Arithmetic, volume 1. Springer, 2018
work page 2018
-
[38]
Table-driven implementation of the exponential function in IEEE floating-point arithmetic.ACM Trans
Ping-Tak Peter Tang. Table-driven implementation of the exponential function in IEEE floating-point arithmetic.ACM Trans. Math. Softw., 15(2):144–157, June 1989. ISSN 0098-3500. doi: 10.1145/63522. 214389. URLhttps://doi.org/10.1145/63522.214389. A Normalization mappings Figure 5 visualizes the underlying distribution of the pre-affine normalization mappi...
-
[39]
Evaluating (7) at the boundary |r|= ln 2/2 gives: N degree √ 2 (ln 2/2)N+1 /(N+ 1)! 6 6 1.69×10 −7 > u 7 7 7.30×10 −9 < u Therefore N= 7 is the minimum polynomial order satisfying FP32 unit-roundoff accuracy, and Horner evaluation (5) of degree7costs2·7 = 14FLOPs. Reconstruction.The factor 2k is applied by adding k to the FP32 exponent field, a single int...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.