Recognition: 3 theorem links
· Lean TheoremPolar probe linearly decodes semantic structures from LLMs
Pith reviewed 2026-05-15 04:56 UTC · model grok-4.3
The pith
Large language models encode the existence and type of semantic relations as distance and direction between embeddings in a linear subspace of their activations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The true semantic structures can be linearly recovered with a Polar Probe targeting a subspace of LLMs' layer activations, where distance between embeddings represents the existence of relations and direction represents their type. This polar code emerges mostly in middle layers, improves with model performance, generalizes to novel entities and relations, but degrades with larger structures, and its quality correlates with the LLM's question-answering accuracy on the structures.
What carries the argument
The Polar Probe, a linear decoder applied to a subspace of layer activations that extracts distance-direction geometry to represent relation existence and type.
If this is right
- The polar representation emerges primarily in middle layers of the network.
- Decoding quality improves as overall LLM performance on the tasks increases.
- The code generalizes to previously unseen entities and relation types.
- Representation quality declines as the size of the semantic structure grows.
- Better polar decoding predicts better ability to answer questions about the structure.
Where Pith is reading between the lines
- If the geometry is causal, targeted interventions on embedding distances and directions could be used to edit or control the model's internal knowledge of relations.
- Similar distance-direction codes might appear in other modalities or architectures, suggesting a general principle for binding representations.
- The degradation with structure size points to a potential limit on how complex relational knowledge LLMs can maintain in this format.
Load-bearing premise
That the distance-direction geometry in embedding space is the actual causal mechanism the model uses rather than a convenient post-hoc linear fit that happens to correlate with task performance.
What would settle it
Observing that perturbing the distances and directions between embeddings in the identified subspace leaves the model's answers to questions about the semantic structures unchanged.
Figures


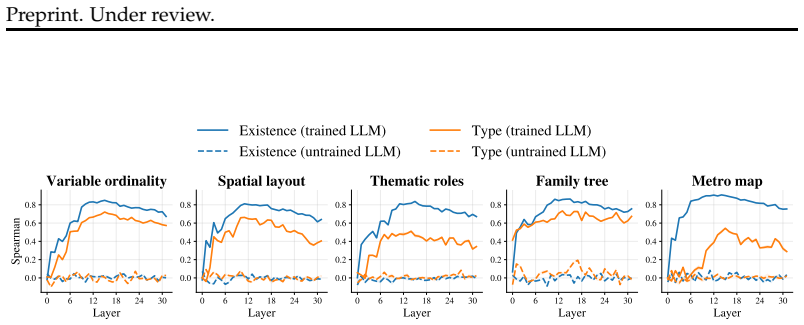




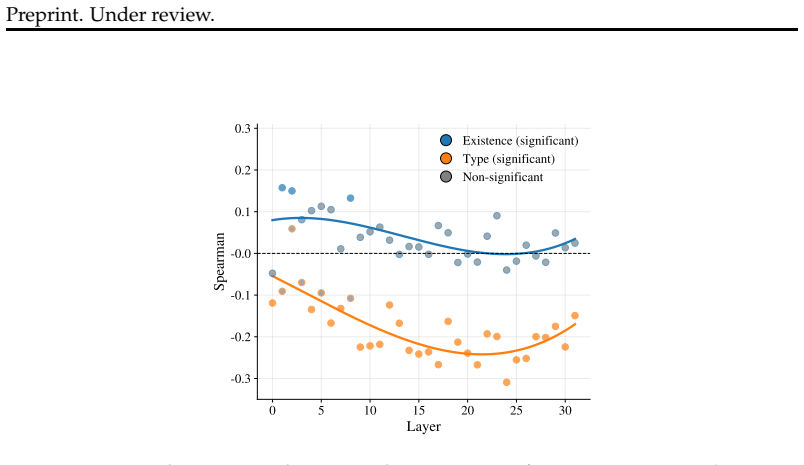






read the original abstract
How do artificial neural networks bind concepts to form complex semantic structures? Here, we propose a simple neural code, whereby the existence and the type of relations between entities are represented by the distance and the direction between their embeddings, respectively. We test this hypothesis in a variety of Large Language Models (LLMs), each input with natural-language descriptions of minimalist tasks from five different domains: arithmetic, visual scenes, family trees, metro maps and social interactions. Results show that the true semantic structures can be linearly recovered with a Polar Probe targeting a subspace of LLMs' layer activations. Second, this code emerges mostly in middle layers and improves with LLM performance. Third, these Polar Probes successfully generalize to new entities and relation types, but degrades with the size of the semantic structure. Finally, the quality of the polar representation correlates with the LLM's ability to answer questions about the semantic structure. Together, these findings suggest that LLMs learn to build complex semantic structures by binding representations with a simple geometrical principle.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs bind concepts into semantic structures via a polar geometry in embedding space, with distance encoding relation existence and direction encoding relation type. A Polar Probe linearly decodes these structures from a subspace of middle-layer activations across five domains (arithmetic, visual scenes, family trees, metro maps, social interactions). The representation emerges in middle layers, scales with model performance, generalizes to novel entities and relations (but degrades with structure size), and correlates with the model's question-answering accuracy on the structures.
Significance. If the geometric code is shown to be more than a post-hoc fit, the work supplies a simple, falsifiable account of compositional representation in LLMs that links representational geometry directly to task behavior. The reported generalization and performance correlation are concrete strengths that could inform interpretability methods and model analysis.
major comments (3)
- [Methods] Methods section: the abstract states successful linear recovery and generalization, yet provides no detail on whether probe training used held-out structures or whether accuracy metrics were compared against chance-level or random linear baselines; this leaves open whether the polar geometry is required or any linear decoder would suffice.
- [Results] Results: no ablation is reported that compares Polar Probes against arbitrary linear decoders trained on the identical activation subspace. Without this comparison, the distance-direction geometry cannot be distinguished from a convenient post-hoc mapping that happens to correlate with the annotated structures.
- [Discussion] Discussion: the claim that the geometry constitutes the model's internal binding mechanism requires interventional evidence (e.g., editing activations along polar axes and measuring downstream task degradation), which is absent; correlational decoding alone does not establish causality.
minor comments (2)
- [Abstract] Abstract: define the Polar Probe and the precise subspace selection criterion more explicitly.
- [Figures] Figures: ensure all panels include chance-level baselines and error bars for the reported generalization and correlation results.
Simulated Author's Rebuttal
We thank the referee for their detailed and insightful comments. We have carefully considered each point and provide point-by-point responses below, along with planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Methods] Methods section: the abstract states successful linear recovery and generalization, yet provides no detail on whether probe training used held-out structures or whether accuracy metrics were compared against chance-level or random linear baselines; this leaves open whether the polar geometry is required or any linear decoder would suffice.
Authors: We appreciate this observation. The Methods section describes the use of held-out structures for training the Polar Probes to test generalization to new entities and relations. Accuracy is evaluated against chance-level baselines appropriate for each task. To make this clearer, we will expand the Methods section with explicit details on the data splits, training procedure, and baseline comparisons including random linear probes. revision: yes
-
Referee: [Results] Results: no ablation is reported that compares Polar Probes against arbitrary linear decoders trained on the identical activation subspace. Without this comparison, the distance-direction geometry cannot be distinguished from a convenient post-hoc mapping that happens to correlate with the annotated structures.
Authors: We acknowledge the value of such an ablation. While the Polar Probe is tailored to the polar geometry hypothesis, we did not directly compare it to generic linear decoders in the original submission. In the revision, we will include an ablation where we train standard linear probes (e.g., MLPs or linear classifiers) on the same middle-layer activations and report their performance in recovering the semantic structures. This will help demonstrate whether the specific distance-direction encoding provides additional benefit. revision: yes
-
Referee: [Discussion] Discussion: the claim that the geometry constitutes the model's internal binding mechanism requires interventional evidence (e.g., editing activations along polar axes and measuring downstream task degradation), which is absent; correlational decoding alone does not establish causality.
Authors: We concur that interventional evidence would be necessary to claim causality. Our manuscript presents correlational findings: the polar geometry is decodable and correlates with model performance. We will revise the Discussion to emphasize that these results are consistent with the geometry serving as a binding mechanism but do not prove it is the causal internal representation. We will add a section on limitations and future work including potential activation editing experiments. revision: partial
Circularity Check
No circularity: empirical probe validation independent of fitted inputs
full rationale
The paper proposes a geometric hypothesis (distance for existence, direction for type of relations) and validates it via linear probing on LLM activations across multiple domains. Probe performance, generalization to new entities, layer-wise emergence, and correlation with task accuracy are reported as empirical measurements against ground-truth structures. No derivation reduces predictions to inputs by construction, no self-citations bear the central claim, and no uniqueness theorems or ansatzes are smuggled in. The analysis remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Relational semantics between entities are represented geometrically in embedding space
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
the existence and the type of relations between entities are represented by the distance and the direction between their embeddings, respectively... Polar Probe... (M̂ρ_G)ij = ||δ_ij||₂ ... (M̂ϕ_G)ijr = δij · p_r / (||δ_ij||₂ ||p_r||₂)
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Polar probe performance saturates at low ranks... semantic structures are represented in a compact subspace... interventions along polar probe directions causally modulate model predictions
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
this code emerges mostly in middle layers and improves with LLM performance... generalizes to new entities and relation types
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Understanding intermediate layers using linear classifier probes, 2017
Guillaume Alain and Yoshua Bengio. Understanding intermediate layers using linear classifier probes, 2017. URL https://openreview.net/forum?id=ryF7rTqgl
work page 2017
-
[2]
Pythia: a suite for analyzing large language models across training and scaling
Stella Biderman, Hailey Schoelkopf, Quentin Anthony, Herbie Bradley, Kyle O'Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, Aviya Skowron, Lintang Sutawika, and Oskar Van Der Wal. Pythia: a suite for analyzing large language models across training and scaling. In Proceedings of the 40th International Confere...
work page 2023
-
[3]
Fast differentiable sorting and ranking
Mathieu Blondel, Olivier Teboul, Quentin Berthet, and Josip Djolonga. Fast differentiable sorting and ranking. In Proceedings of the 37th International Conference on Machine Learning, ICML'20. JMLR.org, 2020
work page 2020
-
[4]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gr...
work page 1901
-
[8]
Diego-Simon, St \'e phane d'Ascoli, Emmanuel Chemla, Yair Lakretz, and Jean-Remi King
Pablo J. Diego-Simon, St \'e phane d'Ascoli, Emmanuel Chemla, Yair Lakretz, and Jean-Remi King. A polar coordinate system represents syntax in large language models. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum?id=x2780VcMOI
work page 2024
-
[10]
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, Roger Grosse, Sam McCandlish, Jared Kaplan, Dario Amodei, Martin Wattenberg, and Christopher Olah. Toy models of superposition. Transformer Circuits Thread, 2022
work page 2022
-
[11]
Jiahai Feng and Jacob Steinhardt. How do language models bind entities in context? In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=zb3b6oKO77
work page 2024
-
[15]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aurelien Rodriguez, Austen Gregerson, Ava S...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Dirk Groeneveld, Iz Beltagy, Pete Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Harsh Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, Shane Arora, David Atkinson, Russell Authur, Khyathi Chandu, Arman Cohan, Jennifer Dumas, Yanai Elazar, Yuling Gu, Jack Hessel, Tushar Khot, William Merrill, Jacob Morrison, Niklas Muennighoff, Aakanksha Nai...
work page 2024
-
[17]
Language models represent space and time
Wes Gurnee and Max Tegmark. Language models represent space and time. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=jE8xbmvFin
work page 2024
-
[21]
Linear representations of political perspective emerge in large language models
Junsol Kim, James Evans, and Aaron Schein. Linear representations of political perspective emerge in large language models. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=rwqShzb9li
work page 2025
-
[25]
The algebraic mind: Integrating connectionism and cognitive science
Gary F Marcus. The algebraic mind: Integrating connectionism and cognitive science. MIT press, 2003
work page 2003
-
[26]
Samuel Marks and Max Tegmark. The geometry of truth: Emergent linear structure in large language model representations of true/false datasets. In First Conference on Language Modeling, 2024. URL https://openreview.net/forum?id=aajyHYjjsk
work page 2024
-
[30]
ICLR : In-context learning of representations
Core Francisco Park, Andrew Lee, Ekdeep Singh Lubana, Yongyi Yang, Maya Okawa, Kento Nishi, Martin Wattenberg, and Hidenori Tanaka. ICLR : In-context learning of representations. In The Thirteenth International Conference on Learning Representations, 2025 a . URL https://openreview.net/forum?id=pXlmOmlHJZ
work page 2025
-
[31]
The geometry of categorical and hierarchical concepts in large language models
Kiho Park, Yo Joong Choe, Yibo Jiang, and Victor Veitch. The geometry of categorical and hierarchical concepts in large language models. In The Thirteenth International Conference on Learning Representations, 2025 b . URL https://openreview.net/forum?id=bVTM2QKYuA
work page 2025
-
[32]
Diego Simon, Emmanuel Chemla, Jean-Remi King, and Yair Lakretz
Pablo J. Diego Simon, Emmanuel Chemla, Jean-Remi King, and Yair Lakretz. Probing syntax in large language models: Successes and remaining challenges. In Second Conference on Language Modeling, 2025. URL https://openreview.net/forum?id=nrZysNmJ0n
work page 2025
-
[35]
Steering language models with activation engineering, 2025
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J Vazquez, Ulisse Mini, and Monte MacDiarmid. Steering language models with activation engineering, 2025. URL https://openreview.net/forum?id=2XBPdPIcFK
work page 2025
-
[36]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett (eds.), Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. URL https:...
work page 2017
- [37]
-
[38]
Tolman, Edward C. , year =. Cognitive maps in rats and men. , volume =. Psychological Review , publisher =. doi:10.1037/h0061626 , number =
-
[39]
Proceedings of the 37th International Conference on Machine Learning , articleno =
Blondel, Mathieu and Teboul, Olivier and Berthet, Quentin and Djolonga, Josip , title =. Proceedings of the 37th International Conference on Machine Learning , articleno =. 2020 , publisher =
work page 2020
-
[40]
The algebraic mind: Integrating connectionism and cognitive science , author=. 2003 , publisher=
work page 2003
-
[41]
arXiv preprint cs/0412059 , year=
Vector symbolic architectures answer Jackendoff's challenges for cognitive neuroscience , author=. arXiv preprint cs/0412059 , year=
- [42]
-
[43]
OLMo: Accelerating the Science of Language Models , author=. Preprint , year=
- [44]
-
[45]
Constantinescu, Alexandra O. and O’Reilly, Jill X. and Behrens, Timothy E. J. , year =. Organizing conceptual knowledge in humans with a gridlike code , volume =. Science , publisher =. doi:10.1126/science.aaf0941 , number =
-
[46]
Theves, Stephanie and Fernandez, Guillén and Doeller, Christian F. , year =. The Hippocampus Encodes Distances in Multidimensional Feature Space , volume =. Current Biology , publisher =. doi:10.1016/j.cub.2019.02.035 , number =
-
[47]
Aronov, Dmitriy and Nevers, Rhino and Tank, David W. , year =. Mapping of a non-spatial dimension by the hippocampal–entorhinal circuit , volume =. Nature , publisher =. doi:10.1038/nature21692 , number =
-
[48]
Theves, Stephanie and Fernández, Guillén and Doeller, Christian F. , year =. The Hippocampus Maps Concept Space, Not Feature Space , volume =. The Journal of Neuroscience , publisher =. doi:10.1523/jneurosci.0494-20.2020 , number =
-
[49]
A Map for Social Navigation in the Human Brain , volume =
Tavares, Rita Morais and Mendelsohn, Avi and Grossman, Yael and Williams, Christian Hamilton and Shapiro, Matthew and Trope, Yaacov and Schiller, Daniela , year =. A Map for Social Navigation in the Human Brain , volume =. Neuron , publisher =. doi:10.1016/j.neuron.2015.06.011 , number =
-
[50]
Place units in the hippocampus of the freely moving rat , volume =
O’Keefe, John , year =. Place units in the hippocampus of the freely moving rat , volume =. Experimental Neurology , publisher =. doi:10.1016/0014-4886(76)90055-8 , number =
-
[51]
Précis of O’Keefe &; Nadel’sThe hippocampus as a cognitive map , volume =
O’Keefe, John and Nadel, Lynn , year =. Précis of O’Keefe &; Nadel’sThe hippocampus as a cognitive map , volume =. Behavioral and Brain Sciences , publisher =. doi:10.1017/s0140525x00063949 , number =
-
[52]
and Clark, Kevin and Hewitt, John and Khandelwal, Urvashi and Levy, Omer , year =
Manning, Christopher D. and Clark, Kevin and Hewitt, John and Khandelwal, Urvashi and Levy, Omer , year =. Emergent linguistic structure in artificial neural networks trained by self-supervision , volume =. Proceedings of the National Academy of Sciences , publisher =. doi:10.1073/pnas.1907367117 , number =
-
[53]
A Structural Probe for Finding Syntax in Word Representations
Hewitt, John and Manning, Christopher D. A Structural Probe for Finding Syntax in Word Representations. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v1/N19-1419
-
[54]
arXiv preprint arXiv:2312.16257 , year=
More than correlation: Do large language models learn causal representations of space? , author=. arXiv preprint arXiv:2312.16257 , year=
-
[55]
Forty-second International Conference on Machine Learning , year=
How Do Transformers Learn Variable Binding in Symbolic Programs? , author=. Forty-second International Conference on Machine Learning , year=
-
[56]
First Conference on Language Modeling , year=
The Geometry of Truth: Emergent Linear Structure in Large Language Model Representations of True/False Datasets , author=. First Conference on Language Modeling , year=
-
[57]
Steering Language Models with Activation Engineering , author=. 2025 , url=
work page 2025
-
[58]
Language Models Encode Numbers Using Digit Representations in Base 10
Levy, Amit Arnold and Geva, Mor. Language Models Encode Numbers Using Digit Representations in Base 10. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers). 2025. doi:10.18653/v1/2025.naacl-short.33
-
[59]
Probing for Incremental Parse States in Autoregressive Language Models
Eisape, Tiwalayo and Gangireddy, Vineet and Levy, Roger and Kim, Yoon. Probing for Incremental Parse States in Autoregressive Language Models. Findings of the Association for Computational Linguistics: EMNLP 2022. 2022. doi:10.18653/v1/2022.findings-emnlp.203
-
[60]
Probing for Labeled Dependency Trees
M. Probing for Labeled Dependency Trees. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.532
-
[61]
Language Models are Few-Shot Learners , url =
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Winte...
-
[62]
and Bruna, Joan and LeCun, Yann and Szlam, Arthur and Vandergheynst, Pierre , journal=
Bronstein, Michael M. and Bruna, Joan and LeCun, Yann and Szlam, Arthur and Vandergheynst, Pierre , journal=. Geometric Deep Learning: Going beyond Euclidean data , year=
- [63]
-
[64]
Hyperbolic neural networks , year =
Ganea, Octavian-Eugen and B\'. Hyperbolic neural networks , year =. Proceedings of the 32nd International Conference on Neural Information Processing Systems , pages =
-
[65]
Boli Chen and Yao Fu and Guangwei Xu and Pengjun Xie and Chuanqi Tan and Mosha Chen and Liping Jing , booktitle=. Probing. 2021 , url=
work page 2021
-
[66]
Representational Analysis of Binding in Language Models
Dai, Qin and Heinzerling, Benjamin and Inui, Kentaro. Representational Analysis of Binding in Language Models. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.967
-
[67]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Transformers Represent Belief State Geometry in their Residual Stream , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[68]
The Twelfth International Conference on Learning Representations , year=
How do Language Models Bind Entities in Context? , author=. The Twelfth International Conference on Learning Representations , year=
-
[69]
and Gardner, Matt and Belinkov, Yonatan and Peters, Matthew E
Liu, Nelson F. and Gardner, Matt and Belinkov, Yonatan and Peters, Matthew E. and Smith, Noah A. Linguistic Knowledge and Transferability of Contextual Representations. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi...
-
[70]
What Does BERT Learn about the Structure of Language?
Jawahar, Ganesh and Sagot, Beno \^i t and Seddah, Djam \'e. What Does BERT Learn about the Structure of Language?. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1356
-
[71]
Language Models Encode the Value of Numbers Linearly
Zhu, Fangwei and Dai, Damai and Sui, Zhifang. Language Models Encode the Value of Numbers Linearly. Proceedings of the 31st International Conference on Computational Linguistics. 2025
work page 2025
-
[72]
The Thirteenth International Conference on Learning Representations , year=
Linear Representations of Political Perspective Emerge in Large Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[73]
The Thirteenth International Conference on Learning Representations , year=
The Geometry of Categorical and Hierarchical Concepts in Large Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[74]
What you can cram into a single \ &!\#* vector:
Conneau, Alexis and Kruszewski, German and Lample, Guillaume and Barrault, Lo. What you can cram into a single \ & ! \# * vector: Probing sentence embeddings for linguistic properties. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018. doi:10.18653/v1/P18-1198
-
[75]
Understanding intermediate layers using linear classifier probes , author=. 2017 , url=
work page 2017
-
[76]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
A Polar coordinate system represents syntax in large language models , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[77]
Composition in Distributional Models of Semantics , volume =
Mitchell, Jeff and Lapata, Mirella , year =. Composition in Distributional Models of Semantics , volume =. Cognitive Science , publisher =. doi:10.1111/j.1551-6709.2010.01106.x , number =
-
[78]
Collins, Allan M. and Quillian, M. Ross , year =. Retrieval time from semantic memory , volume =. Journal of Verbal Learning and Verbal Behavior , publisher =. doi:10.1016/s0022-5371(69)80069-1 , number =
-
[79]
Collins, Allan M. and Loftus, Elizabeth F. , year =. A spreading-activation theory of semantic processing. , volume =. Psychological Review , publisher =. doi:10.1037/0033-295x.82.6.407 , number =
-
[80]
Simmons, R. and Slocum, J. , year =. Generating English discourse from semantic networks , volume =. Communications of the ACM , publisher =. doi:10.1145/355604.361595 , number =
-
[81]
On generative semantics , isbn =
Lakoff, George , editor =. On generative semantics , isbn =. Semantics:. 1971 , keywords =
work page 1971
- [82]
- [83]
- [84]
-
[85]
The proper treatment of quantification in ordinary English , author=. Approaches to natural language: Proceedings of the 1970 Stanford workshop on grammar and semantics , pages=. 1973 , organization=
work page 1970
-
[86]
McRae, Ken and Ferretti and Liane Amyote, Todd R. , year =. Thematic Roles as Verb-specific Concepts , volume =. Language and Cognitive Processes , publisher =. doi:10.1080/016909697386835 , number =
-
[87]
Sowa, John F , year =. Semantic Networks , ISBN =. doi:10.1002/0470018860.s00065 , journal =
-
[88]
Compositionality in Formal Semantics: Selected Papers of Barbara H
Barbara Hall Partee , editor =. Compositionality in Formal Semantics: Selected Papers of Barbara H. Partee , year =
-
[89]
Situations and Attitudes , year =
Jon Barwise and John Perry , publisher =. Situations and Attitudes , year =
-
[90]
Hans Kamp and Uwe Reyle , editor =. From Discourse to Logic: Introduction to Modeltheoretic Semantics of Natural Language, Formal Logic and Discourse Representation Theory , year =
-
[91]
The neural basis of combinatory syntax and semantics , volume =
Pylkk\". The neural basis of combinatory syntax and semantics , volume =. Science , publisher =. 2019 , month = oct, pages =. doi:10.1126/science.aax0050 , number =
-
[92]
Frankland, Steven M and Greene, Joshua D , year =. Two Ways to Build a Thought: Distinct Forms of Compositional Semantic Representation across Brain Regions , volume =. Cerebral Cortex , publisher =. doi:10.1093/cercor/bhaa001 , number =
-
[93]
Minimal Recursion Semantics: An Introduction , volume =
Copestake, Ann and Flickinger, Dan and Pollard, Carl and Sag, Ivan , year =. Minimal Recursion Semantics: An Introduction , volume =. Reseach On Language And Computation , doi =
-
[94]
A bstract M eaning R epresentation for Sembanking
Banarescu, Laura and Bonial, Claire and Cai, Shu and Georgescu, Madalina and Griffitt, Kira and Hermjakob, Ulf and Knight, Kevin and Koehn, Philipp and Palmer, Martha and Schneider, Nathan. A bstract M eaning R epresentation for Sembanking. Proceedings of the 7th Linguistic Annotation Workshop and Interoperability with Discourse. 2013
work page 2013
-
[95]
Eye movements in reading and information processing: 20 years of research
Rayner, Keith , year =. Eye movements in reading and information processing: 20 years of research. , volume =. Psychological Bulletin , publisher =. doi:10.1037/0033-2909.124.3.372 , number =
-
[96]
and Spivey-Knowlton, Michael J
Tanenhaus, Michael K. and Spivey-Knowlton, Michael J. and Eberhard, Kathleen M. and Sedivy, Julie C. , year =. Integration of Visual and Linguistic Information in Spoken Language Comprehension , volume =. Science , publisher =. doi:10.1126/science.7777863 , number =
-
[97]
and Dehaene, Stanislas and King, Jean-Rémi , year =
Desbordes, Théo and Lakretz, Yair and Chanoine, Valérie and Oquab, Maxime and Badier, Jean-Michel and Trébuchon, Agnès and Carron, Romain and Bénar, Christian-G. and Dehaene, Stanislas and King, Jean-Rémi , year =. Dimensionality and Ramping: Signatures of Sentence Integration in the Dynamics of Brains and Deep Language Models , volume =. The Journal of N...
-
[98]
Disentangling Semantic Composition and Semantic Association in the Left Temporal Lobe , volume =
Li, Jixing and Pylkk\". Disentangling Semantic Composition and Semantic Association in the Left Temporal Lobe , volume =. The Journal of Neuroscience , publisher =. doi:10.1523/jneurosci.2317-20.2021 , number =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.