Parallelizing Counterfactual Regret Minimization
Pith reviewed 2026-05-15 02:35 UTC · model grok-4.3
The pith
Counterfactual regret minimization can be reframed as linear algebra operations to run up to four orders of magnitude faster on GPUs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By expressing the regret and strategy updates of CFR as linear algebra operations, existing parallel linear-algebra routines can be used to accelerate the algorithm on GPUs without changing its convergence behavior, and the same transformation extends to other members of the CFR family including CFR+, discounted CFR, and predictive variants.
What carries the argument
A generalized parallelization framework that reformulates CFR regret and strategy updates as linear algebra operations so that GPU-accelerated matrix routines can be substituted for the original sequential loops.
If this is right
- The same linear-algebra reformulation applies directly to CFR+, discounted CFR, and predictive CFR variants.
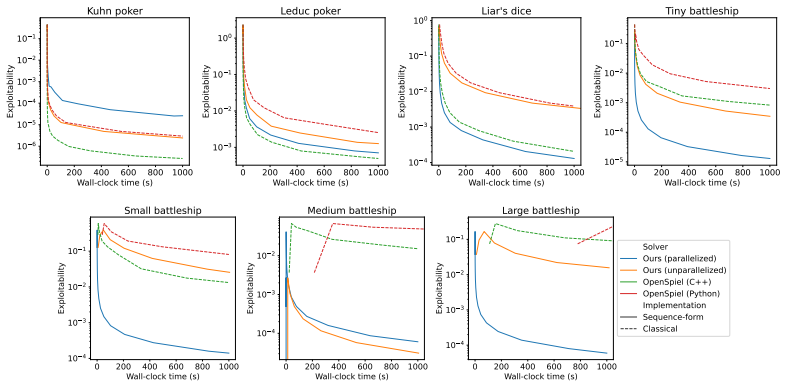
- A GPU implementation achieves up to four orders of magnitude speedup over existing CPU baselines such as OpenSpiel.
- Larger imperfect-information games become solvable in the same wall-clock time as smaller ones were before.
- The framework is general enough to be reused for any tabular CFR-family algorithm.
- Training time for game-solving agents drops dramatically, enabling more iterations or bigger game trees.
- pith_inferences:[
Load-bearing premise
The linear-algebra reformulation must preserve the exact regret bounds and convergence properties of the original CFR without introducing floating-point or parallelism errors.
What would settle it
Execute both the original serial CFR and the new GPU version on Kuhn poker until convergence and verify whether the final strategies and exploitability values match within floating-point tolerance.
Figures

read the original abstract
Parallelization has played an instrumental role in the field of artificial intelligence (AI), drastically reducing the time taken to train and evaluate large AI models. In contrast to its impact in the broader field of AI, applying parallelization to computational game solving is relatively unexplored, despite its great potential. In this paper, we parallelize the family of counterfactual regret minimization (CFR) algorithms, which were central to important breakthroughs for solving large imperfect-information games. We present a generalized parallelization framework, reframing CFR as a series of linear algebra operations. Then, existing techniques for parallelizing linear algebra operations can be applied to accelerate CFR. We also describe how our technique can be applied to other tabular members of the CFR family of algorithms, including the state-of-the-art, such as CFR+, discounted CFR, and predictive variants of CFR. Experimentally, we show that our CFR implementation on a GPU is up to four orders of magnitude faster than Google DeepMind OpenSpiel's CFR implementations on a CPU.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce a generalized parallelization framework for counterfactual regret minimization (CFR) by reframing the algorithm family as sequences of linear algebra operations, enabling the application of existing parallel linear-algebra techniques. It states that this applies to CFR, CFR+, discounted CFR, and predictive CFR variants, and reports that a GPU implementation achieves speedups of up to four orders of magnitude over OpenSpiel's CPU CFR implementations.
Significance. If the reformulation is shown to be mathematically equivalent to standard CFR and to preserve its regret bounds and convergence properties, the work would provide a practical route to scaling CFR to substantially larger games, potentially expanding the range of imperfect-information problems that can be solved exactly or approximately within reasonable compute budgets.
major comments (2)
- [Framework section (reformulation)] The central claim that the linear-algebra reformulation is exact (and therefore inherits the O(1/√T) regret bound) requires an explicit derivation or proof of equivalence. No such derivation, error analysis, or verification that parallel reductions, matrix multiplications for reach probabilities, and the max(0,·) operation in regret matching preserve semantics appears in the manuscript; without it the reported speedups cannot be claimed to solve the same problem.
- [Experiments] Experimental results must include a direct comparison of the strategies and cumulative regrets produced by the parallel GPU version versus the sequential CPU version on the same games; floating-point associativity or execution-order differences could silently violate the regret-matching guarantee even if wall-clock time improves.
minor comments (2)
- [Abstract] The abstract should state the specific game sizes, number of information sets, and iteration counts used to obtain the four-order-of-magnitude speedup so readers can assess the practical scope of the result.
- [Framework section] Notation for the matrix forms of counterfactual values and regret vectors should be introduced with explicit mappings back to the standard CFR recurrence to aid readability.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below and will revise the manuscript accordingly to strengthen the presentation of the linear-algebra reformulation and the experimental validation.
read point-by-point responses
-
Referee: [Framework section (reformulation)] The central claim that the linear-algebra reformulation is exact (and therefore inherits the O(1/√T) regret bound) requires an explicit derivation or proof of equivalence. No such derivation, error analysis, or verification that parallel reductions, matrix multiplications for reach probabilities, and the max(0,·) operation in regret matching preserve semantics appears in the manuscript; without it the reported speedups cannot be claimed to solve the same problem.
Authors: We agree that an explicit derivation is necessary to rigorously confirm equivalence and inheritance of the regret bound. In the revised manuscript we will insert a new subsection (tentatively 3.3) that derives the equivalence step by step: (i) showing that the reach-probability computation is identical to the standard product of strategy and transition matrices, (ii) demonstrating that the regret update is a direct matrix subtraction and accumulation, and (iii) proving that the regret-matching operator (including the element-wise max(0,·) and normalization) produces the identical strategy vector as the sequential formulation. We will also add a short floating-point error discussion noting that all operations remain within the same associative order as the original algorithm when reductions are performed with the same precision. revision: yes
-
Referee: [Experiments] Experimental results must include a direct comparison of the strategies and cumulative regrets produced by the parallel GPU version versus the sequential CPU version on the same games; floating-point associativity or execution-order differences could silently violate the regret-matching guarantee even if wall-clock time improves.
Authors: We accept this requirement. The revised Experiments section will contain a new table (and accompanying text) that reports, for each benchmark game, the L1 distance between the final strategy profiles produced by the GPU and CPU implementations, as well as the absolute difference in cumulative regret after a fixed number of iterations. We will also include a short convergence plot overlaying the two curves to confirm that any numerical discrepancy remains negligible and does not alter the observed convergence rate. revision: yes
Circularity Check
No circularity: CFR reframed as linear-algebra operations using standard parallelization techniques
full rationale
The paper reframes CFR (regret matching, counterfactual values, strategy updates) as a sequence of matrix and vector operations so that existing GPU linear-algebra libraries can be applied directly. No equation is defined in terms of its own output, no parameter is fitted to a subset of data and then relabeled a prediction, and no uniqueness theorem or ansatz is imported via self-citation. The derivation chain consists of explicit algebraic rewrites whose equivalence to the original CFR recurrence is asserted by construction of the reformulation itself; this is an independent translation step rather than a reduction to fitted inputs or prior self-referential results. The reported speedups are therefore empirical consequences of the parallel execution of the rewritten operations, not circularly forced by the paper's own definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption CFR regret updates can be expressed exactly as matrix-vector operations
Reference graph
Works this paper leans on
-
[1]
G. E. Blelloch. Programming parallel algorithms.Commun. ACM, 39(3):85–97, 1996
work page 1996
-
[2]
N. Brown and T. Sandholm. Regret-based pruning in extensive-form games. InProceedings of the Annual Conference on Neural Information Processing Systems (NeurIPS), 2015
work page 2015
-
[3]
N. Brown and T. Sandholm. Reduced space and faster convergence in imperfect-information games via pruning. InProceedings of the International Conference on Machine Learning (ICML), 2017
work page 2017
-
[4]
N. Brown and T. Sandholm. Superhuman AI for heads-up no-limit poker: Libratus beats top professionals.Science, 359(6374):418–424, 2018
work page 2018
-
[5]
N. Brown and T. Sandholm. Superhuman AI for multiplayer poker.Science, 365(6456):885–890, 2019
work page 2019
-
[6]
N. Brown and T. Sandholm. Solving imperfect-information games via discounted regret minimization. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2019
work page 2019
- [7]
- [8]
-
[9]
J. Dean, G. Corrado, R. Monga, K. Chen, M. Devin, M. Mao, M. a. Ranzato, A. Senior, P. Tucker, K. Yang, Q. Le, and A. Ng. Large scale distributed deep networks. InProceedings of the Annual Conference on Neural Information Processing Systems (NeurIPS), 2012
work page 2012
- [10]
- [11]
- [12]
- [13]
-
[14]
A. Gilpin and T. Sandholm. Speeding up gradient-based algorithms for sequential games. In Proceedings of the International Conference on Autonomous Agents and Multiagent Systems (AAMAS), 2010
work page 2010
- [15]
- [16]
-
[17]
S. Hart and A. Mas-Colell. A simple adaptive procedure leading to correlated equilibrium. Econometrica, 68(5):1127–1150, 2000. 10
work page 2000
-
[18]
S. Hoda, A. Gilpin, J. Pe `na, and T. Sandholm. Smoothing techniques for computing Nash equilibria of sequential games.Math. Oper. Res., 35(2):494–512, 2010
work page 2010
-
[19]
J. Kepner, P. Aaltonen, D. Bader, A. Buluç, F. Franchetti, J. Gilbert, D. Hutchison, M. Kumar, A. Lumsdaine, H. Meyerhenke, S. McMillan, C. Yang, J. D. Owens, M. Zalewski, T. Mattson, and J. Moreira. Mathematical foundations of the GraphBLAS. InProceedings of the IEEE High Performance Extreme Computing Conference (HPEC), 2016
work page 2016
- [20]
- [21]
-
[22]
M. Lanctot, K. Waugh, M. Zinkevich, and M. Bowling. Monte Carlo sampling for regret mini- mization in extensive games. InProceedings of the Annual Conference on Neural Information Processing Systems (NeurIPS), 2009
work page 2009
-
[23]
M. Lanctot, E. Lockhart, J.-B. Lespiau, V . Zambaldi, S. Upadhyay, J. Pérolat, S. Srinivasan, F. Timbers, K. Tuyls, S. Omidshafiei, D. Hennes, D. Morrill, P. Muller, T. Ewalds, R. Faulkner, J. Kramár, B. D. Vylder, B. Saeta, J. Bradbury, D. Ding, S. Borgeaud, M. Lai, J. Schrit- twieser, T. Anthony, E. Hughes, I. Danihelka, and J. Ryan-Davis. OpenSpiel: A ...
work page 2019
-
[24]
S. M. McAleer, G. Farina, M. Lanctot, and T. Sandholm. ESCHER: Eschewing importance sampling in games by computing a history value function to estimate regret. InProceedings of the International Conference on Learning Representations (ICLR), 2023
work page 2023
-
[25]
M. Morav ˇcík, M. Schmid, N. Burch, V . Lisý, D. Morrill, N. Bard, T. Davis, K. Waugh, M. Johanson, and M. Bowling. DeepStack: Expert-level artificial intelligence in heads-up no-limit poker.Science, 356(6337):508–513, 2017
work page 2017
- [26]
- [27]
-
[28]
J. Reis. A GPU implementation of counterfactual regret minimization. Master’s thesis, Univer- sity of Porto, 2015
work page 2015
-
[29]
J. Rudolf. Counterfactual regret minimization on GPU, 2021
work page 2021
-
[30]
A. Sergeev and M. D. Balso. Horovod: fast and easy distributed deep learning in TensorFlow, 2018
work page 2018
- [31]
-
[32]
O. Tammelin, N. Burch, M. Johanson, and M. Bowling. Solving heads-up limit Texas Hold’em. InProceedings of the International Joint Conference on Artificial Intelligence (IJCAI), 2015
work page 2015
-
[33]
B. von Stengel. Efficient computation of behavior strategies.Games and Economic Behavior, 14(2):220–246, 1996
work page 1996
-
[34]
H. Xu, K. Li, H. Fu, Q. Fu, J. Xing, and J. Cheng. Dynamic discounted counterfactual regret minimization. InProceedings of the International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[35]
B. H. Zhang, I. Anagnostides, and T. Sandholm. Scale-invariant regret matching and online learning with optimal convergence: Bridging theory and practice in zero-sum games, 2026. 11
work page 2026
- [36]
-
[37]
M. Zinkevich, M. Johanson, M. Bowling, and C. Piccione. Regret minimization in games with incomplete information. InProceedings of the Annual Conference on Neural Information Processing Systems (NeurIPS), 2007. 12 A Omitted proofs in Section 3.4 This appendix section contains proofs excluded from the main paper content due to space constraints. A.1 Proof ...
work page 2007
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.