Recognition: 2 theorem links
· Lean TheoremLiWi: Layering in the Wild
Pith reviewed 2026-05-15 01:58 UTC · model grok-4.3
The pith
Agent-driven synthesis creates over 100,000 layered natural images and trains models to decompose them with state-of-the-art accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
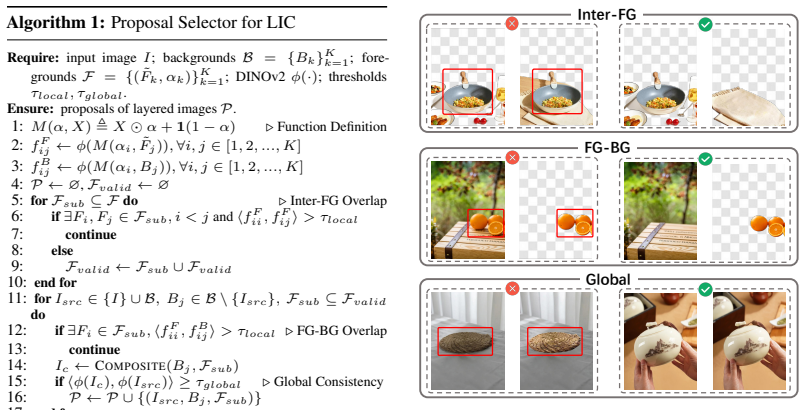
We present an Agent-driven Data Decomposition pipeline that orchestrates agents and tools to generate a large-scale dataset of more than 100,000 high-quality layered natural images without manual labeling. We then train a decomposition network with shadow-guided objectives that explicitly model illumination effects and a degradation-restoration loss that supplies boundary supervision by reconstructing the clean foreground from a degraded version, yielding state-of-the-art results on RGB L1 and Alpha IoU metrics for natural image decomposition.
What carries the argument
The ADD pipeline for automatic layered-data synthesis combined with shadow-guided learning for illumination effects and degradation-restoration supervision for alpha boundary accuracy.
If this is right
- Scalable creation of layered training data becomes possible without human annotation effort.
- Models gain explicit handling of real-world shadow and lighting interactions during decomposition.
- Alpha mattes achieve higher boundary precision on natural images with complex edges.
- Fine-grained editing applications extend from graphic design to ordinary photographs.
- Quantitative metrics for decomposition quality improve consistently across standard benchmarks.
Where Pith is reading between the lines
- Extending the ADD pipeline with temporal constraints could support layered video decomposition.
- The generated dataset may expose systematic lighting biases that current models inherit from graphic-design data.
- Integration with text-to-image generators could enable direct synthesis of layered natural scenes from prompts.
Load-bearing premise
The automated ADD pipeline produces accurate layered ground truth for complex natural scenes that correctly reflects real illumination and object boundaries.
What would settle it
A side-by-side test on a fresh set of real photographs with independent hand-annotated layers showing that the model fails to improve on the best prior RGB L1 or Alpha IoU scores.
Figures










read the original abstract
Recent advances in generative models have empowered impressive layered image generation, yet their success is largely confined to graphic design domains. The layering of in-the-wild images remains an underexplored problem, limiting fine-grained editing and applications of images in real-world scenarios. Specifically, challenges remain in scalable layered data and the modeling of object interaction in natural images, such as illumination effects and structural boundary. To address these bottlenecks, we propose a novel framework for high-fidelity natural image decomposition. First, we introduce an Agent-driven Data Decomposition (ADD) pipeline that orchestrates agents and tools to synthesize layered data without manual intervention. Utilizing this pipeline, we construct a large-scale dataset, named LiWi-100k, with over 100,000 high-quality layered in-the-wild images. Second, we present a novel framework that jointly improves photometric fidelity and alpha boundary accuracy. Specifically, shadow-guided learning explicitly models the illumination effects, and degradation-restoration objective provides boundary-correction supervision by recovering clean foreground image from degraded one. Extensive experiments demonstrate that our framework achieves state-of-the-art (SoTA) performance in natural image decomposition, outperforming existing models in RGB L1 and Alpha IoU metrics. We will soon release our code and dataset.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the LiWi framework for high-fidelity decomposition of natural images into layers. It proposes an Agent-driven Data Decomposition (ADD) pipeline that orchestrates agents and tools to synthesize layered ground truth without manual intervention, yielding the LiWi-100k dataset of over 100,000 in-the-wild images. The model incorporates shadow-guided learning to explicitly model illumination effects and a degradation-restoration objective to supervise boundary accuracy by recovering clean foregrounds from degraded inputs. Experiments are reported to demonstrate state-of-the-art performance on RGB L1 and Alpha IoU metrics, outperforming prior models.
Significance. If the synthetic ground truth faithfully reproduces real-world illumination, shadow interactions, and boundaries, and if the performance gains generalize beyond the authors' dataset, the work could meaningfully advance layered image decomposition for natural scenes. This addresses a clear gap relative to generative models that succeed mainly in graphic-design domains and could enable more precise fine-grained editing applications.
major comments (3)
- [ADD Pipeline and Dataset Construction] The headline SoTA claims on RGB L1 and Alpha IoU are measured exclusively on the LiWi-100k dataset produced by the ADD pipeline. No quantitative fidelity evaluation (e.g., agreement with human annotations on the same source photographs) or error-propagation analysis from agent mistakes is reported, which is load-bearing for any claim of superior performance on natural images.
- [Experiments] The abstract asserts SoTA results yet supplies no quantitative tables, baseline comparisons, error bars, or cross-dataset generalization tests. Without these, it is impossible to verify the magnitude or robustness of the reported improvements.
- [Proposed Framework] The shadow-guided learning and degradation-restoration objectives are described at a high level but lack explicit loss formulations, network details, or ablation studies isolating their contribution to photometric fidelity and boundary accuracy.
minor comments (1)
- [Abstract] The promise to release code and dataset is stated without a timeline, repository link, or licensing information.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and describe the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [ADD Pipeline and Dataset Construction] The headline SoTA claims on RGB L1 and Alpha IoU are measured exclusively on the LiWi-100k dataset produced by the ADD pipeline. No quantitative fidelity evaluation (e.g., agreement with human annotations on the same source photographs) or error-propagation analysis from agent mistakes is reported, which is load-bearing for any claim of superior performance on natural images.
Authors: We agree that direct validation of the synthetic ground truth against human annotations is important for supporting claims on natural images. The current version does not include such a quantitative fidelity study or explicit error-propagation analysis. In the revised manuscript we will add a human evaluation on a random subset of 500 source photographs, reporting agreement metrics for layer boundaries, shadows, and overall decomposition quality. We will also include an error-propagation study that injects controlled agent mistakes and measures downstream impact on RGB L1 and Alpha IoU. These additions will appear in a new subsection of the Experiments section. revision: yes
-
Referee: [Experiments] The abstract asserts SoTA results yet supplies no quantitative tables, baseline comparisons, error bars, or cross-dataset generalization tests. Without these, it is impossible to verify the magnitude or robustness of the reported improvements.
Authors: The full manuscript contains tables with baseline comparisons, multiple-run error bars, and statistical significance tests on the LiWi-100k test split. These details were omitted from the abstract for brevity. We will revise the abstract to report the key quantitative gains (e.g., RGB L1 and Alpha IoU deltas versus the strongest baseline). In addition, we will add a cross-dataset generalization experiment on an external natural-image set (e.g., a held-out portion of COCO or Adobe FiveK with manually verified layers) and report the corresponding metrics with error bars. revision: yes
-
Referee: [Proposed Framework] The shadow-guided learning and degradation-restoration objectives are described at a high level but lack explicit loss formulations, network details, or ablation studies isolating their contribution to photometric fidelity and boundary accuracy.
Authors: We will expand the Method section with the precise loss equations for both the shadow-guided term (including the illumination modeling loss) and the degradation-restoration objective. A new subsection will detail the network architecture, layer dimensions, and training hyperparameters. We will also add ablation tables that isolate each objective’s contribution to photometric fidelity (RGB L1) and boundary accuracy (Alpha IoU), together with qualitative examples showing the effect of removing each component. revision: yes
Circularity Check
No circularity: dataset synthesis and objectives are independent contributions
full rationale
The paper's core claims rest on an Agent-driven Data Decomposition pipeline that generates the LiWi-100k dataset and a framework using shadow-guided learning plus degradation-restoration objectives. No equations, derivations, or fitted parameters are shown to reduce by construction to the inputs; the SoTA results on RGB L1 and Alpha IoU are empirical measurements on the newly synthesized data rather than tautological predictions. No self-citation chains, uniqueness theorems, or ansatz smuggling appear in the derivation. The pipeline and objectives constitute genuine new engineering steps whose validity can be assessed externally via fidelity checks or human annotations, keeping the argument self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Natural images admit accurate layered decompositions with alpha mattes that capture object interactions including illumination and boundaries.
invented entities (2)
-
Agent-driven Data Decomposition (ADD) pipeline
no independent evidence
-
LiWi-100k dataset
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a novel framework for high-fidelity natural image decomposition... shadow-guided learning explicitly models the illumination effects, and degradation-restoration objective provides boundary-correction supervision
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The shadow layer S is defined as the residual between the source image Isrc and the recomposed image Ic
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Layered neural atlases for consistent video editing.ACM Transactions on Graphics, 40(6):1–12, 2021
Yoni Kasten, Dolev Ofri, Oliver Wang, and Tali Dekel. Layered neural atlases for consistent video editing.ACM Transactions on Graphics, 40(6):1–12, 2021
work page 2021
-
[2]
Text2live: Text-driven layered image and video editing
Omer Bar-Tal, Dolev Ofri-Amar, Rafail Fridman, Yoni Kasten, and Tali Dekel. Text2live: Text-driven layered image and video editing. InEuropean Conference on Computer Vision, pages 707–723, 2022
work page 2022
-
[3]
Shape- aware text-driven layered video editing
Yao-Chih Lee, Ji-Ze Genevieve Jang, Yi-Ting Chen, Elizabeth Qiu, and Jia-Bin Huang. Shape- aware text-driven layered video editing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14317–14326, 2023
work page 2023
-
[4]
Resolution-robust large mask inpainting with fourier convolutions
Roman Suvorov, Elizaveta Logacheva, Anton Mashikhin, Anastasia Remizova, Arsenii Ashukha, Aleksei Silvestrov, Naejin Kong, Harshith Goka, Kiwoong Park, and Victor Lempitsky. Resolution-robust large mask inpainting with fourier convolutions. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 2149–2159, 2022
work page 2022
-
[5]
Layerd: Decomposing raster graphic designs into layers
Tomoyuki Suzuki, Kang-Jun Liu, Naoto Inoue, and Kota Yamaguchi. Layerd: Decomposing raster graphic designs into layers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 17783–17792, 2025
work page 2025
-
[6]
Shengming Yin, Zekai Zhang, Zecheng Tang, Kaiyuan Gao, Xiao Xu, Kun Yan, Jiahao Li, Yilei Chen, Yuxiang Chen, Heung-Yeung Shum, et al. Qwen-image-layered: Towards inherent editability via layer decomposition.arXiv preprint arXiv:2512.15603, 2025
-
[7]
Omnipsd: Layered psd generation with diffusion transformer.arXiv preprint arXiv:2512.09247, 2025
Cheng Liu, Yiren Song, Haofan Wang, and Mike Zheng Shou. Omnipsd: Layered psd generation with diffusion transformer.arXiv preprint arXiv:2512.09247, 2025
-
[8]
Elena Garces, Carlos Rodriguez-Pardo, Dan Casas, and Jorge Lopez-Moreno. A survey on intrinsic images: Delving deep into lambert and beyond.International Journal of Computer Vision, 130:836–868, 2022
work page 2022
-
[9]
Canvasvae: Learning to generate vector graphic documents
Kota Yamaguchi. Canvasvae: Learning to generate vector graphic documents. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5481–5489, 2021
work page 2021
-
[10]
Deepprimitive: Image decomposition by layered primitive detection
Jiahui Huang, Jun Gao, Vignesh Ganapathi-Subramanian, Hao Su, Yin Liu, Chengcheng Tang, and Leonidas J Guibas. Deepprimitive: Image decomposition by layered primitive detection. Computational Visual Media, 4(4):385–397, 2018
work page 2018
-
[11]
Generative image layer decomposition with visual effects
Jinrui Yang, Qing Liu, Yijun Li, Soo Ye Kim, Daniil Pakhomov, Mengwei Ren, Jianming Zhang, Zhe Lin, Cihang Xie, and Yuyin Zhou. Generative image layer decomposition with visual effects. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7643–7653, 2025
work page 2025
-
[12]
Xinyang Zhang, Wentian Zhao, Xin Lu, and Jeff Chien. Text2layer: Layered image generation using latent diffusion model.arXiv preprint arXiv:2307.09781, 2023
-
[13]
Runhui Huang, Kaixin Cai, Jianhua Han, Xiaodan Liang, Renjing Pei, Guansong Lu, Songcen Xu, Wei Zhang, and Hang Xu. Layerdiff: Exploring text-guided multi-layered composable image synthesis via layer-collaborative diffusion model. InEuropean Conference on Computer Vision, pages 144–160. Springer, 2024
work page 2024
-
[14]
Art: Anonymous region transformer for variable multi-layer transparent image generation
Yifan Pu, Yiming Zhao, Zhicong Tang, Ruihong Yin, Haoxing Ye, Yuhui Yuan, Dong Chen, Jianmin Bao, Sirui Zhang, Yanbin Wang, et al. Art: Anonymous region transformer for variable multi-layer transparent image generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 7952–7962, 2025. 10
work page 2025
-
[15]
Mulan: A multi layer annotated dataset for controllable text-to-image generation
Petru-Daniel Tudosiu, Yongxin Yang, Shifeng Zhang, Fei Chen, Steven McDonagh, Gerasimos Lampouras, Ignacio Iacobacci, and Sarah Parisot. Mulan: A multi layer annotated dataset for controllable text-to-image generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22413–22422, 2024
work page 2024
-
[16]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Rethinking layered graphic design generation with a top-down approach
Jingye Chen, Zhaowen Wang, Nanxuan Zhao, Li Zhang, Difan Liu, Jimei Yang, and Qifeng Chen. Rethinking layered graphic design generation with a top-down approach. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 16861–16870, 2025
work page 2025
-
[18]
A Unified and Controllable Framework for Layered Image Generation with Visual Effects
Jinrui Yang, Qing Liu, Yijun Li, Mengwei Ren, Letian Zhang, Zhe Lin, Cihang Xie, and Yuyin Zhou. Controllable layered image generation for real-world editing.arXiv preprint arXiv:2601.15507, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Referring layer decomposition.arXiv preprint arXiv:2602.19358, 2026
Fangyi Chen, Yaojie Shen, Lu Xu, Ye Yuan, Shu Zhang, Yulei Niu, and Longyin Wen. Referring layer decomposition.arXiv preprint arXiv:2602.19358, 2026
-
[20]
Transparent image layer diffusion using latent trans- parency.arXiv preprint arXiv:2402.17113, 2024
Lvmin Zhang and Maneesh Agrawala. Transparent image layer diffusion using latent trans- parency.arXiv preprint arXiv:2402.17113, 2024
-
[21]
Dreamlayer: Simultaneous multi-layer generation via diffusion model
Junjia Huang, Pengxiang Yan, Jinhang Cai, Jiyang Liu, Zhao Wang, Yitong Wang, Xinglong Wu, and Guanbin Li. Dreamlayer: Simultaneous multi-layer generation via diffusion model. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3357–3366, 2025
work page 2025
-
[22]
Psdiffusion: Harmonized multi-layer image generation via layout and appearance alignment
Dingbang Huang, Wenbo Li, Yifei Zhao, Xinyu Pan, Yanhong Zeng, and Bo Dai. Psdiffusion: Harmonized multi-layer image generation via layout and appearance alignment. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 3233–3242, 2026
work page 2026
-
[23]
Kyoungkook Kang, Gyujin Sim, Geonung Kim, Donguk Kim, Seungho Nam, and Sunghyun Cho. Layeringdiff: Layered image synthesis via generation, then disassembly with generative knowledge.arXiv preprint arXiv:2501.01197, 2025
-
[24]
Layerfusion: Harmonized multi-layer text-to-image generation with generative priors
Yusuf Dalva, Yijun Li, Qing Liu, Nanxuan Zhao, Jianming Zhang, Zhe Lin, and Pinar Yanardag. Layerfusion: Harmonized multi-layer text-to-image generation with generative priors. In NeurIPS 2025 Workshop on Space in Vision, Language, and Embodied AI, 2024
work page 2025
-
[25]
Jingxi Chen, Yixiao Zhang, Xiaoye Qian, Zongxia Li, Cornelia Fermuller, Caren Chen, and Yiannis Aloimonos. From inpainting to layer decomposition: Repurposing generative inpainting models for image layer decomposition.arXiv preprint arXiv:2511.20996, 2025
-
[26]
Datasetagent: A novel multi-agent system for auto-constructing datasets from real-world images
Haoran Sun, Haoyu Bian, Shaoning Zeng, Yunbo Rao, Xu Xu, Lin Mei, and Jianping Gou. Datasetagent: A novel multi-agent system for auto-constructing datasets from real-world images. arXiv preprint arXiv:2507.08648, 2025
-
[27]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Black Forest Labs. Flux.2-klein-9b, 2026. URL https://bfl.ai/models/flux-2-klein. Accessed: 2026-04-27
work page 2026
-
[29]
Rmbg-1.4: Background removal model, 2024
BRIA AI. Rmbg-1.4: Background removal model, 2024. URL https://huggingface.co/ briaai/RMBG-1.4. Accessed: 2026-04-27
work page 2024
-
[30]
Peng Zheng, Dehong Gao, Deng-Ping Fan, Li Liu, Jorma Laaksonen, Wanli Ouyang, and Nicu Sebe. Bilateral reference for high-resolution dichotomous image segmentation.CAAI Artificial Intelligence Research, 2024. 11
work page 2024
-
[31]
Rmbg-2.0: Background removal model, 2024
BRIA AI. Rmbg-2.0: Background removal model, 2024. URL https://huggingface.co/ briaai/RMBG-2.0. Accessed: 2026-04-27
work page 2024
-
[32]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[34]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[35]
Highly accurate dichotomous image segmentation
Xuebin Qin, Hang Dai, Xiaobin Hu, Deng-Ping Fan, Ling Shao, et al. Highly accurate dichotomous image segmentation. 2022
work page 2022
-
[36]
Deng-Ping Fan, Ge-Peng Ji, Guolei Sun, Ming-Ming Cheng, Jianbing Shen, and Ling Shao. Camouflaged object detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2777–2787, 2020
work page 2020
-
[37]
U2-net: Going deeper with nested u-structure for salient object detection
Xuebin Qin, Zichen Zhang, Chenyang Huang, Masood Dehghan, Osmar R Zaiane, and Martin Jagersand. U2-net: Going deeper with nested u-structure for salient object detection. 106: 107404, 2020
work page 2020
-
[38]
Deep high-resolution representation learning for visual recognition
Jingdong Wang, Ke Sun, Tianheng Cheng, Borui Jiang, Chaorui Deng, Yang Zhao, Dong Liu, Yadong Mu, Mingkui Tan, Xinggang Wang, et al. Deep high-resolution representation learning for visual recognition. 43(10):3349–3364, 2020
work page 2020
-
[39]
Pyramid grafting network for one-stage high resolution saliency detection
Chenxi Xie, Changqun Xia, Mingcan Ma, Zhirui Zhao, Xiaowu Chen, and Jia Li. Pyramid grafting network for one-stage high resolution saliency detection. 2022
work page 2022
-
[40]
Dichotomous image segmentation with frequency priors
Yan Zhou, Bo Dong, Yuanfeng Wu, Wentao Zhu, Geng Chen, and Yanning Zhang. Dichotomous image segmentation with frequency priors. 2023
work page 2023
-
[41]
Peng Zheng, Dehong Gao, Deng-Ping Fan, Li Liu, Jorma Laaksonen, Wanli Ouyang, and Nicu Sebe. Bilateral reference for high-resolution dichotomous image segmentation.arXiv preprint arXiv:2401.03407, 2024. 12 A Complete Zero-Shot Foreground Segmentation Results on Real-World Data We compare our method with various foreground segmentation approaches on the fo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.