Recognition: 2 theorem links
· Lean TheoremWoodelf++: A Fast and Unified Partial Dependence Plot Algorithm for Decision Tree Ensembles
Pith reviewed 2026-05-15 01:37 UTC · model grok-4.3
The pith
Woodelf++ computes partial dependence plots, joint plots, and all-order interaction values for decision tree ensembles with exponential complexity reductions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Woodelf++ derives metrics over pseudo-Boolean functions to compute PDPs (exact and approximate), Joint-PDPs, and Any-Order-PDIVs inside one framework. The same structure yields Full PDPs that capture model behavior across all possible feature values by using the tree split thresholds directly. The resulting complexity for Any-Order-PDIVs improves exponentially over the state of the art, while PDP and Joint-PDP calculations run up to six times faster than current leading implementations and five orders of magnitude faster than scikit-learn on a 400,000-row dataset.
What carries the argument
Metrics defined over pseudo-Boolean functions that encode the decision tree ensemble and enable a single pass to obtain dependence plots and all-order interaction values.
If this is right
- Any-Order-PDIVs become practical to compute for every feature subset on large datasets instead of remaining intractable.
- Joint-PDPs and single-feature PDPs can be generated together without separate code paths or repeated traversals of the ensemble.
- Full PDPs that respect exact split thresholds replace sampled approximations and give a more faithful view of model behavior.
- The same machinery that accelerates SHAP values can now accelerate a broader set of dependence and interaction diagnostics.
- Pure-Python implementation with optional GPU support allows these tools to run inside existing Python ML pipelines without external dependencies.
Where Pith is reading between the lines
- Routine higher-order interaction analysis could become part of standard model auditing workflows once the runtime barrier drops.
- The pseudo-Boolean representation might transfer to other tree-based or additive models if similar function encodings can be derived.
- Practitioners could subsample rows or features and still obtain reliable interaction rankings by reusing the same efficient metrics.
- The unified framework suggests a path toward computing dependence measures that condition on arbitrary subsets without exponential blow-up in the number of subsets examined.
Load-bearing premise
The pseudo-Boolean metrics extracted from the tree ensemble can be evaluated without additional per-row or per-subset costs that grow with dataset size or number of features.
What would settle it
Time the computation of Any-Order-PDIVs for every feature subset on the 400,000-row dataset using both Woodelf++ and the previous state-of-the-art method; if Woodelf++ finishes in under an hour while the baseline exceeds days, the claimed exponential improvement holds.
Figures








read the original abstract
Partial Dependence Plots (PDPs) visualize how changes in a single feature affect the average model prediction. They are widely used in practice to interpret decision tree ensembles and other machine learning models. Joint-PDPs extend this idea to pairs of features, revealing their combined effect. Partial Dependence Interaction Values (PDIVs) measure feature interactions. The Any-Order-PDIVs task computes these interactions for every feature subset across all rows of the dataset. We introduce Woodelf++, a unified and efficient approach for computing all these useful explainability tools on decision tree ensembles, building on Woodelf, an algorithm for efficient SHAP computation. By deriving suitable metrics over pseudo-Boolean functions, Woodelf++ can compute PDPs (exact and approximate), Joint-PDPs, and Any-Order-PDIVs in a unified framework. Our method delivers substantial complexity improvements over the state of the art, including an exponential gain for Any-Order-PDIVs. Additionally, we introduce and efficiently compute Full PDPs, which leverage the model's split thresholds to faithfully capture its behavior across all possible feature values. Woodelf++ is implemented in pure Python and supports GPU acceleration. On a dataset with 400,000 rows, Woodelf++ computes PDP and Joint-PDP up to 6x faster than the state of the art and up to five orders of magnitude faster than scikit-learn. For Any-Order-PDIVs, the gap is even larger: Woodelf++ computes all interaction values in 5 minutes, while the state of the art is estimated to require over 1,000,000 years.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Woodelf++, a unified algorithm for computing Partial Dependence Plots (PDPs), Joint-PDPs, Full PDPs, and Any-Order Partial Dependence Interaction Values (PDIVs) on decision tree ensembles. Building on the prior Woodelf SHAP method, it derives metrics over pseudo-Boolean functions to enable exact and approximate computations in a single framework, claiming exponential complexity gains for Any-Order-PDIVs along with practical speedups (e.g., 5 minutes on 400k rows vs. >1M years for SOTA). The implementation is in pure Python with GPU support and introduces Full PDPs that respect model split thresholds.
Significance. If the complexity claims and absence of hidden per-row/per-subset overheads are verified, this would represent a substantial practical advance for interpretability of tree ensembles, making high-order interaction analysis feasible on large datasets where it was previously intractable. The unified treatment of PDPs, Joint-PDPs, and Any-Order-PDIVs plus the threshold-aware Full PDPs are useful contributions; the pure-Python GPU implementation aids reproducibility.
major comments (2)
- [§4] §4 (Complexity Analysis): The exponential improvement for Any-Order-PDIVs and the 5-minute runtime on 400k rows rest on the claim that pseudo-Boolean metric evaluation incurs no per-row or per-subset costs linear in n after O(2^d) preprocessing. The manuscript must explicitly derive the end-to-end complexity including any aggregation over rows or trees to confirm independence from dataset size; without this, the 1,000,000-year SOTA estimate cannot be validated.
- [§5.3] §5.3 (Benchmark Experiments): The reported speedups (6x vs SOTA for PDP/Joint-PDP, five orders of magnitude vs scikit-learn) compare against baselines whose implementation details (GPU usage, optimization level) are not fully specified. Please add a table or paragraph clarifying whether baselines received equivalent hardware acceleration and whether the 400k-row timing includes all 2^d subsets or a sampled subset.
minor comments (3)
- [§3] Notation for pseudo-Boolean functions is introduced without an explicit definition table; adding one would aid readers unfamiliar with the Woodelf base paper.
- [Figure 2] Figure 2 (runtime scaling) lacks error bars or multiple runs; reporting variance across random seeds would strengthen the empirical claims.
- [Abstract] The abstract states 'exponential gain' but the main text should cross-reference the precise big-O expressions (e.g., O(2^d * poly(d)) vs prior O(n * 2^d)) to avoid ambiguity.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments, which have helped us identify areas where the manuscript can be strengthened for clarity and rigor. We address each major comment point by point below.
read point-by-point responses
-
Referee: [§4] §4 (Complexity Analysis): The exponential improvement for Any-Order-PDIVs and the 5-minute runtime on 400k rows rest on the claim that pseudo-Boolean metric evaluation incurs no per-row or per-subset costs linear in n after O(2^d) preprocessing. The manuscript must explicitly derive the end-to-end complexity including any aggregation over rows or trees to confirm independence from dataset size; without this, the 1,000,000-year SOTA estimate cannot be validated.
Authors: We agree that an explicit end-to-end complexity derivation is required to substantiate the independence from dataset size n. In the revised manuscript, we will expand Section 4 with a formal breakdown: the preprocessing computes pseudo-Boolean function metrics in O(2^d * T) time per tree (where T is the number of trees), after which metric evaluation and aggregation for all PDPs, Joint-PDPs, and Any-Order-PDIVs are performed in O(2^d) time independent of n, with row-wise aggregation folded into the precomputed expectations. This structure eliminates per-row linear costs post-preprocessing. We will include a theorem statement and proof sketch confirming the claimed exponential gains and validating the SOTA runtime comparison. revision: yes
-
Referee: [§5.3] §5.3 (Benchmark Experiments): The reported speedups (6x vs SOTA for PDP/Joint-PDP, five orders of magnitude vs scikit-learn) compare against baselines whose implementation details (GPU usage, optimization level) are not fully specified. Please add a table or paragraph clarifying whether baselines received equivalent hardware acceleration and whether the 400k-row timing includes all 2^d subsets or a sampled subset.
Authors: We agree that baseline implementation details require clarification for fair comparison. In the revised Section 5.3, we will add a paragraph and a new comparison table specifying: (1) SOTA baselines for PDP/Joint-PDP were run using their original CPU-based public implementations without GPU acceleration, while Woodelf++ uses GPU support for the core pseudo-Boolean operations; (2) scikit-learn comparisons used the standard CPU implementation; (3) all reported timings, including the 400k-row Any-Order-PDIVs result, were computed over the full set of 2^d subsets with no sampling. We will also list the exact hardware (CPU/GPU models) used in our experiments. revision: yes
Circularity Check
Minor self-citation to prior Woodelf work; central derivations remain independent
full rationale
The paper derives new metrics over pseudo-Boolean functions to unify computation of PDPs, Joint-PDPs, Any-Order-PDIVs, and Full PDPs, extending the Woodelf SHAP algorithm. The abstract states the approach 'building on Woodelf' but presents the new metrics and complexity improvements as derived in this work rather than fitted or self-referentially defined. No equations reduce outputs to parameters chosen from target data, no self-definitional loops appear, and the exponential gains are tied to the unified framework structure. The self-citation is present but not load-bearing for the novel claims, keeping overall circularity low.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Decision tree ensembles can be represented as pseudo-Boolean functions whose relevant metrics admit efficient evaluation.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By deriving suitable metrics over pseudo-Boolean functions, WOODELF++ can compute PDPs... PDIVV,F = sum (-1)^|F|-|S| · PDV...
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery theorem unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
WOODELF models this game as a PB function F... linearity property
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Springer Nature Switzerland. [Nadel and Wettenstein, 2026a] Alexander Nadel and Ron Wettenstein. From decision trees to boolean logic: A fast and unified shap algorithm.Proceedings of the AAAI Con- ference on Artificial Intelligence, 40(29):24476–24485, Mar. 2026. [Nadel and Wettenstein, 2026b] Alexander Nadel and Ron Wettenstein. From decision trees to b...
work page 2026
-
[2]
Setp[i] = 1ifx i ∈S + k
-
[3]
Setp[i] = 2if(x i ∈S − k )∧(x i ∈s)
-
[4]
Setp[i] = 3if(x i ∈S − k )∧(x i /∈s)
-
[5]
In par- ticular, there is noisuch thatx i ∈S + k andx i ∈S − k
Setp[i] = 4ifx i /∈Sk Note: Since we consider a path with no repeating features, each variablex i can appear only once in each cube. In par- ticular, there is noisuch thatx i ∈S + k andx i ∈S − k . Given a patternp, construct a single pair(c k, s)using the rules below:
-
[6]
Addx i toS + k ifp[i] = 1
-
[7]
Addx i toS − k ifp[i] = 2orp[i] = 3
-
[8]
Addx i tosifp[i] = 1orp[i] = 2 This proves the one-to-one correspondence, implying that {1,2,3,4} D and the set of(c k, s)pairs have the same size. As the size of{1,2,3,4} D is4 D, the size of all the(c k, s) pairs is also4 D andPDIVMetrictotal complexity isO(4 D). Thus, the average complexity on allO(3 D)cubes is: O(vavg c ) =O 4 3 D . A more refined ana...
-
[9]
Samplekvalues for each feature (line 2)
-
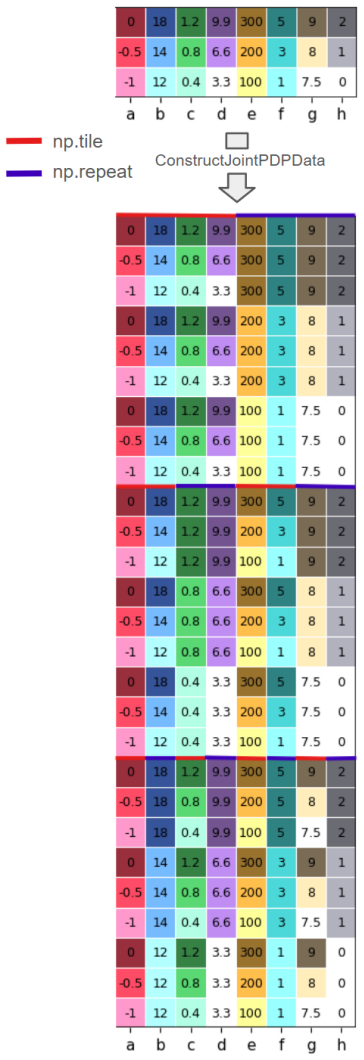
[10]
Build the Joint-PDP dataset usingConstructJointPDP- Data(line 3)
-
[11]
This is done by invoking WOODELF++ with thePDIVOrder1Or2metric, whose implementation appears in Fig
Compute all PDIVs of first and second order using WOODELF++ (lines 4-5). This is done by invoking WOODELF++ with thePDIVOrder1Or2metric, whose implementation appears in Fig. 8
-
[12]
ComputePDIV {},{}, which corresponds to the average prediction over the background data (line 6)
-
[13]
Apply Formula 12 to compute Joint-PDVs (lines 7-11)
-
[14]
Clip the resulting Joint-PDVs usingClipPDVsand re- turn the result (line 12). Algorithm 4Joint-PDPs 1:functionWJOINTPDPS(M, B, k) 2:Selectkpossible values for each feature inB, and store them ind f(see Formula 5). 3:C= CONSTRUCTJOINTPDPDATA(d f) 4:metric=PDIVOrder1Or2() 5:P DIV= WOODELF(M, C, B, metric) 6:P DIV[∅] =M(B).mean() 7:P DV={} 8:forf i inFdo 9:f...
-
[15]
Line 2 samplekpoints for each feature inB, requiring O(kf)time
-
[16]
Line 3 has complexityO(k 2log(f)), asConstructJoint- PDPDataproduces an output of sizek 2log(f)and its complexity is linear with respect to its output size (Lines 8 and 10 are the bottlenecks of Alg 2)
-
[17]
In practice, line 5 is the main bottleneck of the algorithm. To analyze the complexity of WOOD- ELF++, we boundO(v s)andO(v avg c )when apply- ingPDIVOrder1Or2to all cubes over the variables {x1, . . . , xD}(see Sect. 2.2 and Appendix A.2 for de- tails on these quantities). First, observe that any cube ck with more than two positive literals (|S + k |>2) ...
-
[18]
Line 6 performsnmodel predictions, takingO(nT D) time
-
[19]
Lines 7-11 iterate over all feature pairs and apply simple arithmetic on thePDIVdata of sizek 2log(f), resulting inO(k 2f 2log(f))complexity
-
[20]
In line 12 theClipPDVsalgorithm (Alg 3) clips the PDIVdata, creating a dataset withk 2 rows andf 2 columns inO(k 2f 2)time. Combining the above line-by-line complexities yields a fi- nal complexity of: O(k2f 2log(f) +nT L+k 2log(f)·T LD 2 +T L2 DD2) C Experimental Results This section provides technical details of our experiments, reports empirical correc...
work page 2017
-
[21]
We run the SOTA implementation on 10 feature pairs withk= 5
-
[22]
We divide the total runtime by 10 to obtain the average runtime per pair
-
[23]
We multiply this average by the total number of feature pairs, which is f(f−1) 2 . Equivalently, the total estimate is: running time on 10 pairs 10 · f(f−1) 2 In our runs, the measured time for 10 pairs was 382 seconds on the IEEE-CIS dataset and 1030 seconds on the KDD-Cup dataset. Any-Order-PDIVsIn both ‘Any-Order-PDIVs n=10,000’ and ‘Any-Order-PDIVs’, ...
work page 2036
-
[24]
‘Any-Order-PDIVs’ IEEE-CIS (n=472 432) is: c·2199096386519040·472432≈2854863years
-
[25]
‘Any-Order-PDIVs n=10,000’ IEEE-CIS is: c·2199096386519040·10000≈60429years
-
[26]
‘Any-Order-PDIVs’ KDD Cup (n=4 898 431) is: c·1490305024·4898431≈20years
-
[27]
This comparison was carried out on the first1000rows of the IEEE-CIS train dataset
‘Any-Order-PDIVs n=10,000’ KDD Cup is: c·1490305024·10000≈15days C.5 Empirical Correctness Verification To validate the correctness of our approaches, we compared the PDV k=5 computed by WOODELF++ (both with exact and approximate approaches) to those generated by scikit- learn. This comparison was carried out on the first1000rows of the IEEE-CIS train dat...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.