Recognition: 1 theorem link
· Lean TheoremViMU: Benchmarking Video Metaphorical Understanding
Pith reviewed 2026-05-15 04:48 UTC · model grok-4.3
The pith
ViMU is the first benchmark to test whether video models can interpret metaphorical, ironic and social subtext beyond literal visuals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish ViMU as a benchmark that evaluates video understanding models on their ability to move past literal perception and infer implicit ideas, intentions, emotions, attitudes and social meanings embedded in video context, style and viewer experience, using carefully designed hint-free questions in both open-ended and multiple-choice formats.
What carries the argument
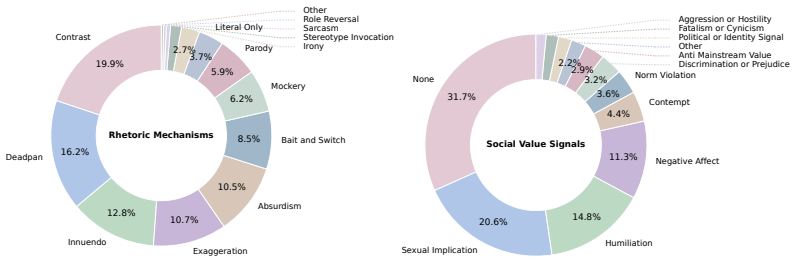
The ViMU benchmark itself, which assesses subtext understanding through curated, hint-free questions that force models to extract metaphorical, ironic and social meanings from videos.
If this is right
- Video models that succeed on ViMU would demonstrate improved capacity to interpret real-world communications that rely on unspoken layers.
- The benchmark supplies a standardized way to compare frontier models on their handling of context, style and social experience rather than surface visuals alone.
- Development of future video systems will need explicit mechanisms for cultural and social inference to perform well on ViMU-style evaluations.
- Passing ViMU would indicate models can ground interpretations in multimodal evidence instead of relying on disclosed hints.
Where Pith is reading between the lines
- The benchmark could be extended to test whether the same models handle subtext in static images or audio-only clips with comparable difficulty.
- Poor performance on ViMU would motivate new training approaches that emphasize implicit reasoning over explicit visual classification.
- If ViMU questions prove culturally biased, future versions might incorporate diverse viewer perspectives to strengthen the evaluation.
Load-bearing premise
That metaphorical and social subtext in videos can be reliably measured through a fixed set of curated hint-free questions that separate genuine understanding from pattern matching or guessing.
What would settle it
A finding that top models reach high accuracy on ViMU by exploiting dataset statistics or guessing without actually processing the video content or its implicit meanings would show the benchmark does not measure the intended capability.
Figures










read the original abstract
Any new medium, once it emerges, is used for more than the transmission of overt content alone. The information it carries typically operates on two levels: one is the content directly presented, while the other is the subtext beneath it-the implicit ideas and intentions the creator seeks to convey through the medium. Likewise, since video technologies became widely adopted, video has served not only as a powerful tool for recording and communicating visual information, but also as a vehicle for emotions, attitudes, and social meanings that are often difficult to articulate explicitly. Thus, the true meaning of many videos does not reside solely in what is shown on screen; it is often embedded in context, style of expression, and the viewer's social experience. Some forms of such video subtext are humorous, while others carry irony, mockery, or criticism. These implicit meanings can also be interpreted very differently across cultural backgrounds and social groups. However, most existing video understanding models still focus primarily on literal visual comprehension, such as recognizing objects, actions, or temporal relations, and lack a systematic ability to understand the metaphorical, ironic, and social meanings embedded in videos. To bridge this gap, we introduce ViMU, the first benchmark designed to systematically evaluate the subtext understanding capabilities of frontier models in videos. ViMU assesses whether video understanding models can go beyond literal perception to infer implicit meaning while grounding their interpretations in multimodal evidence and answering both open-ended and multiple-choice questions. Importantly, all questions are designed to be hint-free, ensuring that no key evidence is disclosed to models before answering.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
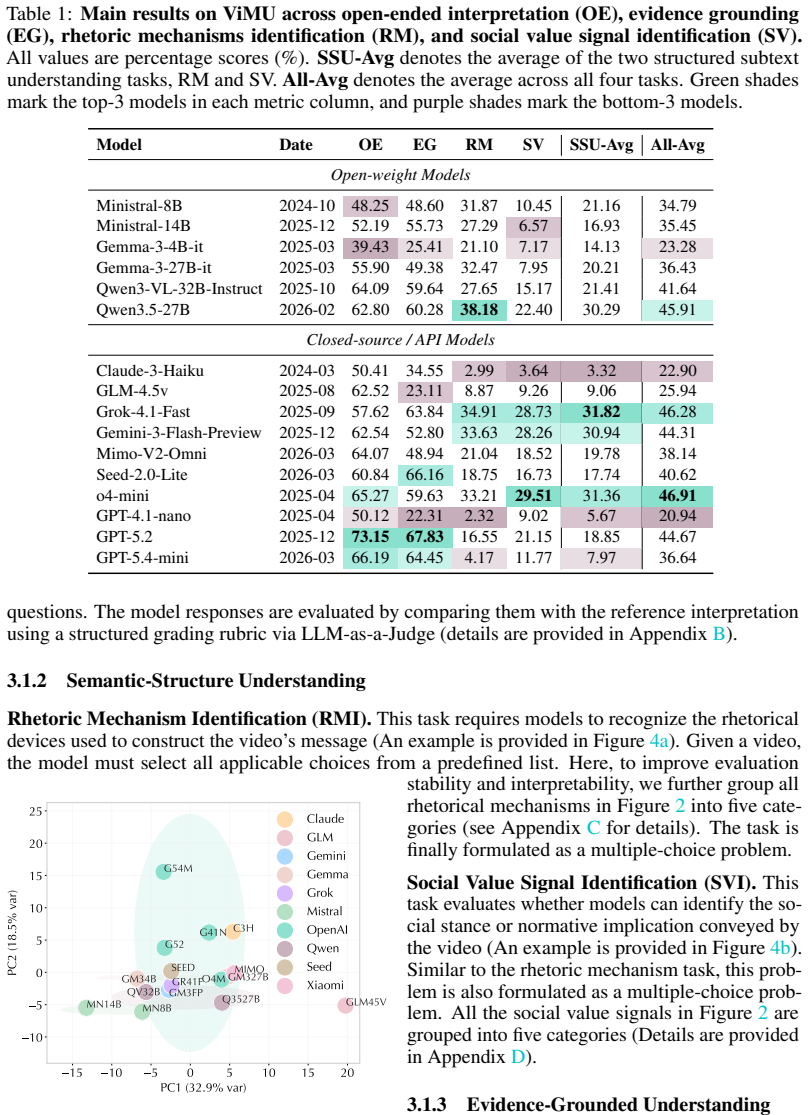
Summary. The paper introduces ViMU as the first benchmark for systematically evaluating frontier video understanding models on their ability to infer metaphorical, ironic, and social subtext, using hint-free open-ended and multiple-choice questions that require grounding interpretations in multimodal evidence rather than literal content.
Significance. If the benchmark is constructed with validated questions, human baselines, and demonstrated resistance to shortcuts, it would address a clear gap in video understanding evaluation, moving beyond literal perception tasks to implicit meaning inference across cultural contexts.
major comments (4)
- [Abstract] Abstract and introduction: the central claim that ViMU 'systematically evaluate[s] the subtext understanding capabilities' and that 'all questions are designed to be hint-free' is unsupported because the manuscript provides no concrete question examples, video descriptions, or annotation guidelines.
- [Benchmark Construction] Benchmark design section: no inter-annotator agreement scores, human performance baselines, or analysis of potential shortcuts (e.g., language priors or visual heuristics) are reported, which are required to establish that the questions distinguish genuine multimodal inference from guessing or pattern matching.
- [Experiments] Evaluation and results: the manuscript supplies no model results, comparisons to existing video benchmarks, or falsifiable predictions, leaving the claim that ViMU can assess frontier models without any empirical demonstration.
- [Question Design] Question validation: the assertion that questions are 'grounded in evidence' and reliably measure subtext lacks any reported validation procedure or pilot study data, undermining the measurement instrument's validity.
minor comments (2)
- [Dataset Statistics] Clarify the exact number of videos and questions in the benchmark and provide a data release plan or link.
- [Introduction] Ensure consistent use of terminology such as 'subtext' versus 'implicit meaning' across sections.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments identify important areas where additional transparency and evidence are needed to support the benchmark's validity and utility. We will revise the manuscript to address each point.
read point-by-point responses
-
Referee: [Abstract] Abstract and introduction: the central claim that ViMU 'systematically evaluate[s] the subtext understanding capabilities' and that 'all questions are designed to be hint-free' is unsupported because the manuscript provides no concrete question examples, video descriptions, or annotation guidelines.
Authors: We agree that the abstract and introduction would be strengthened by concrete support. In the revision we will insert specific question examples, brief video descriptions, and a summary of the annotation guidelines directly into these sections. revision: yes
-
Referee: [Benchmark Construction] Benchmark design section: no inter-annotator agreement scores, human performance baselines, or analysis of potential shortcuts (e.g., language priors or visual heuristics) are reported, which are required to establish that the questions distinguish genuine multimodal inference from guessing or pattern matching.
Authors: We accept that these quantitative validations are necessary. The revised manuscript will report inter-annotator agreement scores, human performance baselines on the full set, and a dedicated analysis of possible shortcuts including language priors and visual heuristics. revision: yes
-
Referee: [Experiments] Evaluation and results: the manuscript supplies no model results, comparisons to existing video benchmarks, or falsifiable predictions, leaving the claim that ViMU can assess frontier models without any empirical demonstration.
Authors: The current draft centers on benchmark construction. To provide the requested empirical demonstration we will add, in the revision, results from multiple frontier video models, direct comparisons against existing video benchmarks, and a short discussion of falsifiable predictions. revision: yes
-
Referee: [Question Design] Question validation: the assertion that questions are 'grounded in evidence' and reliably measure subtext lacks any reported validation procedure or pilot study data, undermining the measurement instrument's validity.
Authors: We will expand the question-design section to describe the full validation procedure, including pilot-study results and the criteria used to confirm that questions are grounded in multimodal evidence. revision: yes
Circularity Check
No circularity: benchmark definition with no derivation chain
full rationale
The paper introduces ViMU as a new benchmark for video subtext understanding without any mathematical derivations, equations, fitted parameters, predictions, or self-citations that reduce the central claim to its own inputs. The contribution consists of benchmark curation and question design, which are presented as definitional rather than derived quantities. No load-bearing steps exist that match the enumerated circularity patterns; the manuscript is self-contained as an empirical evaluation resource.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Video subtext such as metaphor and irony can be systematically evaluated through hint-free questions grounded in multimodal evidence.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we introduce ViMU, the first benchmark designed to systematically evaluate the subtext understanding capabilities of frontier models in videos
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Mythologies (book).https://en.wikipedia.org/wiki/Mythologies_(book)
-
[2]
Openrouter: Unified api for large language models.https://openrouter.ai
-
[3]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Tieyuan Chen, Huabin Liu, Tianyao He, Yihang Chen, Chaofan Gan, Xiao Ma, Cheng Zhong, Yang Zhang, Yingxue Wang, Hui Lin, et al. Mecd: Unlocking multi-event causal discovery in video reasoning.Advances in neural information processing systems, 37:92554–92580, 2024
work page 2024
-
[6]
Tieyuan Chen, Huabin Liu, Yi Wang, Yihang Chen, Tianyao He, Chaofan Gan, Huanyu He, and Weiyao Lin. Mecd+: Unlocking event-level causal graph discovery for video reasoning.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
work page 2025
-
[7]
Tieyuan Chen, Huabin Liu, Yi Wang, Chaofan Gan, Mingxi Lyu, Ziran Qin, Shijie Li, Liquan Shen, Junhui Hou, Zheng Wang, et al. Looking beyond visible cues: Implicit video question answering via dual-clue reasoning.arXiv preprint arXiv:2506.07811, 2025. 10
-
[8]
Video2commonsense: Generating commonsense descriptions to enrich video captioning
Zhiyuan Fang, Tejas Gokhale, Pratyay Banerjee, Chitta Baral, and Yezhou Yang. Video2commonsense: Generating commonsense descriptions to enrich video captioning. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 840–860, 2020
work page 2020
-
[9]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24108–24118, 2025
work page 2025
-
[10]
Dong Guo, Faming Wu, Feida Zhu, Fuxing Leng, Guang Shi, Haobin Chen, Haoqi Fan, Jian Wang, Jianyu Jiang, Jiawei Wang, et al. Seed1. 5-vl technical report.arXiv preprint arXiv:2505.07062, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Stuart Hall. Encoding—decoding (1980). InCrime and media, pages 44–55. Routledge, 2019
work page 1980
-
[12]
Chien-yu Huang, Ke-Han Lu, Shih-Heng Wang, Chi-Yuan Hsiao, Chun-Yi Kuan, Haibin Wu, Siddhant Arora, Kai-Wei Chang, Jiatong Shi, Yifan Peng, et al. Dynamic-superb: Towards a dynamic, collaborative, and comprehensive instruction-tuning benchmark for speech. In ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)...
work page 2024
-
[13]
Xilin Jiang, Qiaolin Wang, Junkai Wu, Xiaomin He, Zhongweiyang Xu, Yinghao Ma, Minshuo Piao, Kaiyi Yang, Xiuwen Zheng, Riki Shimizu, et al. Avmeme exam: A multimodal multilin- gual multicultural benchmark for llms’ contextual and cultural knowledge and thinking.arXiv preprint arXiv:2601.17645, 2026
-
[14]
Douwe Kiela, Hamed Firooz, Aravind Mohan, Vedanuj Goswami, Amanpreet Singh, Pratik Ringshia, and Davide Testuggine. The hateful memes challenge: Detecting hate speech in multimodal memes.Advances in neural information processing systems, 33:2611–2624, 2020
work page 2020
-
[15]
Gunther Kress and Theo Van Leeuwen.Reading images: The grammar of visual design. Routledge, 2020
work page 2020
- [16]
-
[17]
Are vision-language models safe in the wild? a meme-based benchmark study
DongGeon Lee, Joonwon Jang, Jihae Jeong, and Hwanjo Yu. Are vision-language models safe in the wild? a meme-based benchmark study. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 30533–30576, 2025
work page 2025
-
[18]
Mvbench: A comprehensive multi-modal video understanding benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A comprehensive multi-modal video understanding benchmark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22195–22206, 2024
work page 2024
-
[19]
CoLA: A Choice Leakage Attack Framework to Expose Privacy Risks in Subset Training
Qi Li, Cheng-Long Wang, Yinzhi Cao, and Di Wang. Cola: A choice leakage attack framework to expose privacy risks in subset training.arXiv preprint arXiv:2604.12342, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Qi Li, Runpeng Yu, and Xinchao Wang. Vid-sme: Membership inference attacks against large video understanding models.Advances in Neural Information Processing Systems, 38:111572– 111596, 2026
work page 2026
-
[21]
Hongzhan Lin, Ziyang Luo, Bo Wang, Ruichao Yang, and Jing Ma. Goat-bench: Safety insights to large multimodal models through meme-based social abuse.ACM Transactions on Intelligent Systems and Technology, 2024
work page 2024
-
[22]
Ziyang Ma, Yinghao Ma, Yanqiao Zhu, Chen Yang, Yi-Wen Chao, Ruiyang Xu, Wenxi Chen, Yuanzhe Chen, Zhuo Chen, Jian Cong, et al. Mmar: A challenging benchmark for deep reasoning in speech, audio, music, and their mix.arXiv preprint arXiv:2505.13032, 2025
-
[23]
Visu- alcomet: Reasoning about the dynamic context of a still image
Jae Sung Park, Chandra Bhagavatula, Roozbeh Mottaghi, Ali Farhadi, and Yejin Choi. Visu- alcomet: Reasoning about the dynamic context of a still image. InEuropean Conference on Computer Vision, pages 508–524. Springer, 2020. 11
work page 2020
-
[24]
MMAU: A Massive Multi-Task Audio Understanding and Reasoning Benchmark
Sakshi Sakshi, Utkarsh Tyagi, Sonal Kumar, Ashish Seth, Ramaneswaran Selvakumar, Oriol Nieto, Ramani Duraiswami, Sreyan Ghosh, and Dinesh Manocha. Mmau: A massive multi-task audio understanding and reasoning benchmark.arXiv preprint arXiv:2410.19168, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
What do you meme? generating explanations for visual semantic role labelling in memes
Shivam Sharma, Siddhant Agarwal, Tharun Suresh, Preslav Nakov, Md Shad Akhtar, and Tanmoy Chakraborty. What do you meme? generating explanations for visual semantic role labelling in memes. InProceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 9763–9771, 2023
work page 2023
-
[26]
Zhengpeng Shi, Hengli Li, Yanpeng Zhao, Jianqun Zhou, Yuxuan Wang, Qinrong Cui, Wei Bi, Songchun Zhu, Bo Zhao, and Zilong Zheng. V-hub: A visual-centric humor understanding benchmark for video llms.arXiv preprint arXiv:2509.25773, 2025
-
[27]
Vrr-qa: Visual relational reasoning in videos beyond explicit cues, 2026
Sirnam Swetha, Rohit Gupta, Parth Parag Kulkarni, David G Shatwell, Jeffrey A Chan Santiago, Nyle Siddiqui, Joseph Fioresi, and Mubarak Shah. Vrr-qa: Visual relational reasoning in videos beyond explicit cues, 2026
work page 2026
-
[28]
Gemma: Open Models Based on Gemini Research and Technology
Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, et al. Gemma: Open models based on gemini research and technology.arXiv preprint arXiv:2403.08295, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Audiobench: A universal benchmark for audio large language models
Bin Wang, Xunlong Zou, Geyu Lin, Shuo Sun, Zhuohan Liu, Wenyu Zhang, Zhengyuan Liu, AiTi Aw, and Nancy Chen. Audiobench: A universal benchmark for audio large language models. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pa...
work page 2025
-
[30]
Towards lifecycle unlearning commitment management: Measuring sample-level unlearning completeness
Cheng-Long Wang, Qi Li, Zihang Xiang, Yinzhi Cao, and Di Wang. Towards lifecycle unlearning commitment management: Measuring sample-level unlearning completeness. In 34th USENIX Security Symposium (USENIX Security 25), pages 6481–6500, 2025
work page 2025
-
[31]
Lvbench: An extreme long video understanding benchmark
Weihan Wang, Zehai He, Wenyi Hong, Yean Cheng, Xiaohan Zhang, Ji Qi, Ming Ding, Xiaotao Gu, Shiyu Huang, Bin Xu, et al. Lvbench: An extreme long video understanding benchmark. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22958– 22967, 2025
work page 2025
-
[32]
Can i trust your answer? visually grounded video question answering
Junbin Xiao, Angela Yao, Yicong Li, and Tat-Seng Chua. Can i trust your answer? visually grounded video question answering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13204–13214, 2024
work page 2024
-
[33]
Funqa: Towards surprising video comprehension
Binzhu Xie, Sicheng Zhang, Zitang Zhou, Bo Li, Yuanhan Zhang, Jack Hessel, Jingkang Yang, and Ziwei Liu. Funqa: Towards surprising video comprehension. InEuropean Conference on Computer Vision, pages 39–57. Springer, 2024
work page 2024
-
[34]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Runpeng Yu, Qi Li, and Xinchao Wang. Discrete diffusion in large language and multimodal models: A survey.arXiv preprint arXiv:2506.13759, 2025
-
[36]
Memereacon: Probing contextual meme understanding in large vision-language models
Zhengyi Zhao, Shubo Zhang, Yuxi Zhang, Yanxi Zhao, Yifan Zhang, Zezhong Wang, Huimin Wang, Yutian Zhao, Bin Liang, Yefeng Zheng, et al. Memereacon: Probing contextual meme understanding in large vision-language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 3559–3582, 2025
work page 2025
-
[37]
Mlvu: Benchmarking multi-task long video understanding
Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Zhengyang Liang, Shitao Xiao, Minghao Qin, Xi Yang, Yongping Xiong, Bo Zhang, et al. Mlvu: Benchmarking multi-task long video understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13691–13701, 2025. 12 A Details of the Dataset Curation Process The construction of V...
work page 2025
-
[38]
- Do not assume any external posting context beyond the video itself
Transcript from audio ASR (may be empty, noisy, or partial): <transcript> Important constraints: - You must infer visible on-screen text directly from the frames when relevant. - Do not assume any external posting context beyond the video itself. - Separateliteral contentfromintended meaning. - Use only evidence supported by frames, transcript, visible te...
-
[39]
Does the question leak the semantic field or sensitive framing?
-
[40]
Can the question be answered correctly using only surface-level description?
-
[41]
Does it force understanding of the intended meaning?
-
[42]
Is the difficulty appropriate given the video’s taxonomy?
-
[43]
Is the gold answer aligned with the intended meaning?
-
[44]
Is the rubric strong enough for later LLM judging? If the question is flawed, provide a better revised_question that is harder and less revealing while still evaluable. This prompt defines the structured validation step. Iterative Refinement Prompt (Augmented Generation) You are given the annotation for a video. Taxonomy JSON: <taxonomy json> Task:Create ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.