Recognition: no theorem link
An Amortized Efficiency Threshold for Comparing Neural and Heuristic Solvers in Combinatorial Optimization
Pith reviewed 2026-05-15 04:44 UTC · model grok-4.3
The pith
Neural solvers become net energy-efficient after a fixed number of deployments once training cost is amortized against lower per-instance use.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
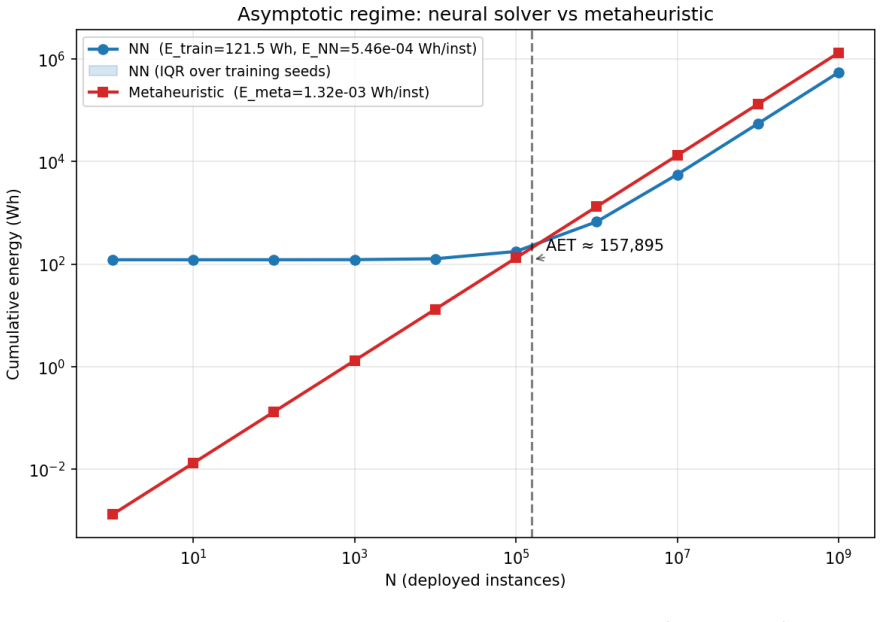
The cumulative-energy ratio between neural and heuristic solvers tends to a constant strictly below one whenever the network wins per-instance, and this limit is independent of training-cost measurement. The Amortized Efficiency Threshold is the deployment volume above which the neural solver therefore breaks even in total energy or carbon while meeting the same solution-quality target.
What carries the argument
The Amortized Efficiency Threshold (AET), the deployment volume at which cumulative energy of the neural solver drops below the heuristic baseline after adding fixed training energy and symmetric embodied-carbon costs.
If this is right
- Past the AET the neural solver delivers strictly lower total energy for every additional instance solved.
- The long-term efficiency limit equals the per-instance energy ratio and is unaffected by the exact value of training energy.
- Embodied-carbon costs for GPU and CPU hardware are divided equally across all instances and do not alter the convergence of the ratio.
- On the tested 20-customer multi-task VRP the ratio converges to 0.41, placing the break-even point near 158000 instances.
- The same accounting applies to any neural versus heuristic comparison once per-instance energies and quality constraints are recorded.
Where Pith is reading between the lines
- At larger problem sizes the AET would fall if neural per-instance energy grows slower than heuristic run time.
- Lifecycle carbon accounting for optimization software should treat deployment volume as the decisive variable rather than training cost alone.
- The framework supplies a protocol for deciding when to switch from heuristic to neural solvers in production pipelines.
- Future measurements could test whether the ratio convergence remains stable across different GPU generations or problem classes.
Load-bearing premise
The neural solver uses less energy per instance than the heuristic and this per-instance cost stays constant no matter how many times the solver is deployed.
What would settle it
Measure total energy for both solvers at one million deployed instances on the same problem set and check whether the cumulative ratio has stabilized below 1.0 for the neural solver.
Figures




read the original abstract
A common critique of neural combinatorial-optimization solvers is that they are less energy-efficient than CPU metaheuristics, given the operational energy cost of training them on GPUs. This paper examines the inferential step from "training is expensive" to "neural solvers are net-inefficient", which is where the critique actually goes wrong. Training the network costs a large fixed amount of GPU energy; running the metaheuristic costs a small amount of CPU energy on every instance, repeated as long as the solver is deployed. The two are not commensurable until a deployment volume is fixed. We define the Amortized Efficiency Threshold (AET) as the deployment volume above which a neural solver breaks even with a heuristic baseline in total energy or carbon, under an explicit constraint on solution quality. We show that the cumulative-energy ratio between the two solvers tends to a constant strictly below one whenever the network wins per-instance, and that this limit does not depend on how the training cost was measured. An embodied-carbon term amortizes hardware fabrication symmetrically on both sides. We instantiate the framework on the Multi-Task VRP (MTVRP) environment at n=20 customers across 19 problem variants and five training seeds, with HGS via PyVRP as the heuristic baseline. The measured crossover sits near $1.58 \times 10^5$ deployed instances; the per-instance ratio is 0.41, reflecting the moderate size of the instances tested. The contribution is the framework, the open instrumentation, and the measurement protocol; structural convergence of the ratio at larger problem sizes is left to future empirical work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Amortized Efficiency Threshold (AET) as the deployment volume at which a neural combinatorial optimization solver achieves lower total energy or carbon cost than a heuristic baseline, subject to an explicit solution-quality constraint. It shows that the cumulative energy ratio (T + N E_n) / (N E_h) converges to the per-instance ratio E_n / E_h < 1 whenever the neural solver is more efficient per instance, independent of the fixed training cost T. The framework is instantiated on the Multi-Task VRP (n=20) across 19 variants and five seeds with HGS/PyVRP as baseline, yielding a measured crossover near 1.58 × 10^5 instances and per-instance ratio 0.41. The contribution centers on the framework, open instrumentation, and measurement protocol.
Significance. If the central convergence result holds, the paper supplies a rigorous, deployment-volume-aware method for comparing neural and heuristic solvers on energy grounds, directly addressing a frequent critique of neural CO methods. The mathematical limit is parameter-free once per-instance energies are measured, and the symmetric treatment of embodied carbon is a clear strength. The empirical protocol on MTVRP demonstrates feasibility and provides reproducible instrumentation, which is valuable for the field even if larger-scale structural convergence is left open.
major comments (1)
- [§4] §4 (empirical evaluation): the reported crossover of 1.58 × 10^5 instances and per-instance ratio of 0.41 are given without error bars, standard deviations across the five seeds, or details on instance exclusion criteria; these omissions weaken confidence in the precise numerical value of the measured AET even though the qualitative claim (ratio < 1) remains intact.
minor comments (3)
- [Abstract, §3] Abstract and §3: the quality constraint is invoked but its precise enforcement (e.g., optimality gap threshold or feasibility filter) is not restated in the main derivation; a one-sentence reminder would improve readability.
- [§2] Notation: E_n and E_h are used before being formally defined in the text; adding a short definitions paragraph at the start of §2 would eliminate ambiguity.
- [Conclusion] The manuscript states that code and instrumentation are open; the camera-ready version should include an explicit repository URL and a brief reproducibility checklist.
Simulated Author's Rebuttal
We thank the referee for their constructive comments and the recommendation for minor revision. We respond to the major comment below and have made the corresponding revisions to the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (empirical evaluation): the reported crossover of 1.58 × 10^5 instances and per-instance ratio of 0.41 are given without error bars, standard deviations across the five seeds, or details on instance exclusion criteria; these omissions weaken confidence in the precise numerical value of the measured AET even though the qualitative claim (ratio < 1) remains intact.
Authors: We thank the referee for pointing this out. The five seeds provide multiple measurements, and we have now included the standard deviation across seeds for both the AET and the per-instance ratio in the revised §4. Error bars have been added to the relevant plots. We have also expanded the description of the experimental protocol to include the instance exclusion criteria, which were applied uniformly: instances were excluded if either solver failed to produce a feasible solution or if the solution quality violated the constraint by more than the allowed threshold. The reported values are means over the valid instances and seeds. This addresses the concern and increases the transparency of our results. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The central derivation is the algebraic limit of the cumulative energy ratio (T + N E_n) / (N E_h) → E_n / E_h as deployment volume N → ∞. This follows directly from the ratio expression without any fitting, ansatz, or self-citation; the paper measures per-instance energies E_n and E_h empirically on MTVRP instances and reports the observed ratio 0.41 < 1. The AET is defined as the finite N where the ratio equals 1, but the convergence claim itself is independent of that threshold and does not reduce to any input by construction. No load-bearing self-citations, uniqueness theorems, or renamed empirical patterns appear in the provided derivation steps.
Axiom & Free-Parameter Ledger
free parameters (1)
- per-instance energy ratio =
0.41
axioms (1)
- domain assumption Training cost is a fixed one-time GPU energy expense independent of deployment volume
invented entities (1)
-
Amortized Efficiency Threshold (AET)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Product environmental reports.https://www.apple.com/environment/, 2023
Apple Inc. Product environmental reports.https://www.apple.com/environment/, 2023
work page 2023
-
[2]
Le, Mohammad Norouzi, and Samy Bengio
Irwan Bello, Hieu Pham, Quoc V. Le, Mohammad Norouzi, and Samy Bengio. Neural combinatorial optimization with reinforcement learning. InICLR Workshop, 2017
work page 2017
-
[3]
RL4CO: An extensive reinforcement learning for combinatorial optimization benchmark
Federico Berto, Chuanbo Hua, Junyoung Park, Laurin Luttmann, Yining Ma, Fanchen Bu, Jiarui Wang, Haoran Ye, Minsu Kim, Sanghyeok Choi, André Hottung, Jianan Zhou, Jieyi Bi, Yu Hu, Fei Liu, Hyeonah Kim, Jiwoo Son, Haeyeon Kim, Wouter Kool, Zhiguang Cao, Jie Zhang, Kijung Shin, Cathy Wu, Sungsoo Ahn, Guojie Song, Changhyun Kwon, Lin Xie, and Jinkyoo Park. R...
work page 2024
-
[4]
Lee, Gu-Yeon Wei, David Brooks, and Carole-Jean Wu
Udit Gupta, Young Geun Kim, Sylvia Lee, Jordan Tse, Hsien-Hsin S. Lee, Gu-Yeon Wei, David Brooks, and Carole-Jean Wu. Chasing carbon: The elusive environmental footprint of computing. InHPCA, 2021
work page 2021
-
[5]
Keld Helsgaun. An extension of the Lin-Kernighan-Helsgaun TSP solver for constrained traveling salesman and vehicle routing problems.Roskilde University Technical Report, 2017
work page 2017
-
[6]
Towards the systematic reporting of the energy and carbon footprints of machine learning
Peter Henderson, Jieru Hu, Joshua Romoff, Emma Brunskill, Dan Jurafsky, and Joelle Pineau. Towards the systematic reporting of the energy and carbon footprints of machine learning. Journal of Machine Learning Research, 21(248):1–43, 2020. 14
work page 2020
-
[7]
Efficient active search for combinatorial optimization problems
André Hottung, Yeong-Dae Kwon, and Kevin Tierney. Efficient active search for combinatorial optimization problems. InICLR, 2022
work page 2022
-
[8]
David S. Johnson and Lyle A. McGeoch. The traveling salesman problem: A case study in local optimization.Local Search in Combinatorial Optimization, pages 215–310, 1997. DIMACS Implementation Challenges
work page 1997
-
[9]
Joshi, Quentin Cappart, Louis-Martin Rousseau, and Thomas Laurent
Chaitanya K. Joshi, Quentin Cappart, Louis-Martin Rousseau, and Thomas Laurent. Learning the travelling salesperson problem requires rethinking generalization.Constraints, 27(1–2):70–98, 2022
work page 2022
-
[10]
Attention, learn to solve routing problems! InICLR, 2019
Wouter Kool, Herke van Hoof, and Max Welling. Attention, learn to solve routing problems! InICLR, 2019
work page 2019
-
[11]
POMO: Policy optimization with multiple optima for reinforcement learning
Yeong-Dae Kwon, Jinho Choo, Byoungjip Kim, Iljoo Yoon, Youngjune Gwon, and Seungjai Min. POMO: Policy optimization with multiple optima for reinforcement learning. InNeurIPS, 2020
work page 2020
-
[12]
Quantifying the Carbon Emissions of Machine Learning
Alexandre Lacoste, Alexandra Luccioni, Victor Schmidt, and Thomas Dandres. Quantifying the carbon emissions of machine learning.arXiv preprint arXiv:1910.09700, 2019
work page internal anchor Pith review arXiv 1910
-
[13]
Alexandra Sasha Luccioni, Sylvain Viguier, and Anne-Laure Ligozat. Estimating the carbon footprint of BLOOM, a 176B parameter language model.Journal of Machine Learning Research, 24(253):1–15, 2023
work page 2023
-
[14]
Carbon Emissions and Large Neural Network Training
David Patterson, Joseph Gonzalez, Quoc Le, Chen Liang, Lluis-Miquel Munguia, Daniel Rothchild, David So, Maud Texier, and Jeff Dean. Carbon emissions and large neural network training.arXiv preprint arXiv:2104.10350, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[15]
Roy Schwartz, Jesse Dodge, Noah A. Smith, and Oren Etzioni. Green AI.Communications of the ACM, 63(12):54–63, 2020
work page 2020
-
[16]
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. InICLR, 2017
work page 2017
-
[17]
Arman Shehabi, Sarah Smith, Dale Sartor, Richard Brown, Magnus Herrlin, Jonathan Koomey, Eric Masanet, Nathaniel Horner, Inês Azevedo, and William Lintner. United states data center energy usage report.Lawrence Berkeley National Laboratory Technical Report LBNL-1005775, 2016
work page 2016
-
[18]
Masked label prediction: Unified message passing model for semi-supervised classification
Yunsheng Shi, Zhengjie Huang, Shikun Feng, Hui Zhong, Wenjing Wang, and Yu Sun. Masked label prediction: Unified message passing model for semi-supervised classification. InIJCAI, 2021
work page 2021
-
[19]
Energy and policy considerations for deep learning in NLP
Emma Strubell, Ananya Ganesh, and Andrew McCallum. Energy and policy considerations for deep learning in NLP. InACL, 2019
work page 2019
-
[20]
Algorithm selection on a meta level.Machine Learning, 112(4):1255–1290, 2023
Alexander Tornede, Lukas Gehring, Tanja Tornede, Marcel Wever, and Eyke Hüllermeier. Algorithm selection on a meta level.Machine Learning, 112(4):1255–1290, 2023
work page 2023
-
[21]
CVRPLIB: Capacitated vehicle routing problem library.http://vrp.atd-lab.inf
Eduardo Uchoa, Diego Pecin, Artur Pessoa, Marcus Poggi, Thibaut Vidal, and Anand Subra- manian. CVRPLIB: Capacitated vehicle routing problem library.http://vrp.atd-lab.inf. puc-rio.br/, 2017. 15
work page 2017
-
[22]
Thibaut Vidal. Hybrid genetic search for the CVRP: Open-source implementation and SWAP* neighborhood.Computers & Operations Research, 140:105643, 2022
work page 2022
-
[23]
Thibaut Vidal, Teodor Gabriel Crainic, Michel Gendreau, Nadia Lahrichi, and Walter Rei. A hybrid genetic algorithm for multidepot and periodic vehicle routing problems.Operations Research, 60(3):611–624, 2012
work page 2012
-
[24]
Oriol Vinyals, Meire Fortunato, and Navdeep Jaitly. Pointer networks. InNeurIPS, 2015
work page 2015
-
[25]
Wouda, Leon Lan, and Wouter Kool
Niels A. Wouda, Leon Lan, and Wouter Kool. PyVRP: A high-performance VRP solver package. INFORMS Journal on Computing, 2024
work page 2024
-
[26]
Lee, Bugra Akyildiz, Maximilian Balandat, Joe Spisak, Ravi Jain, Mike Rabbat, and Kim Hazelwood
Carole-Jean Wu, Ramya Raghavendra, Udit Gupta, Bilge Acun, Newsha Ardalani, Kiwan Maeng, Gloria Chang, Fiona Aga Behram, James Huang, Charles Bai, Michael Gschwind, Anurag Gupta, Myle Ott, Anastasia Melnikov, Salvatore Candido, David Brooks, Geeta Chauhan, Benjamin Lee, Hsien-Hsin S. Lee, Bugra Akyildiz, Maximilian Balandat, Joe Spisak, Ravi Jain, Mike Ra...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.