Recognition: 2 theorem links
· Lean TheoremMultiEmo-Bench: Multi-label Visual Emotion Analysis for Multi-modal Large Language Models
Pith reviewed 2026-05-15 05:43 UTC · model grok-4.3
The pith
A multi-label benchmark with aggregated annotator votes shows recent MLLMs have advanced on visual emotion prediction but still leave substantial room for improvement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
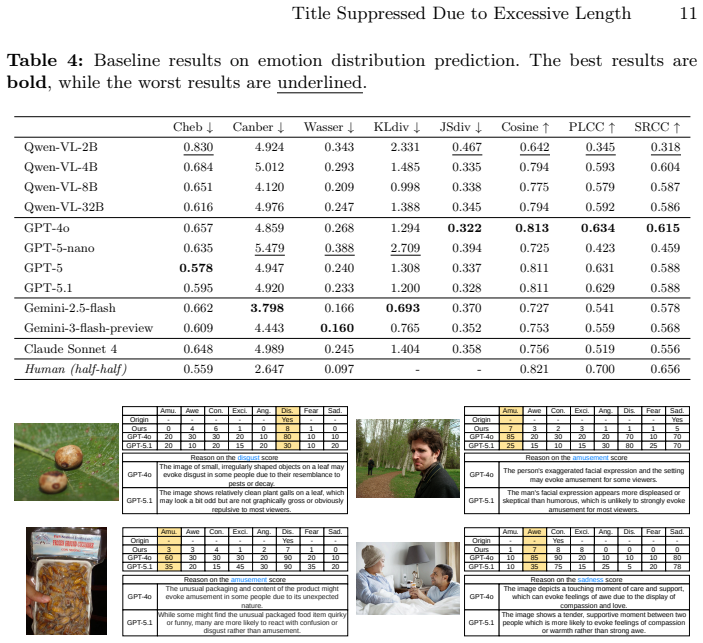
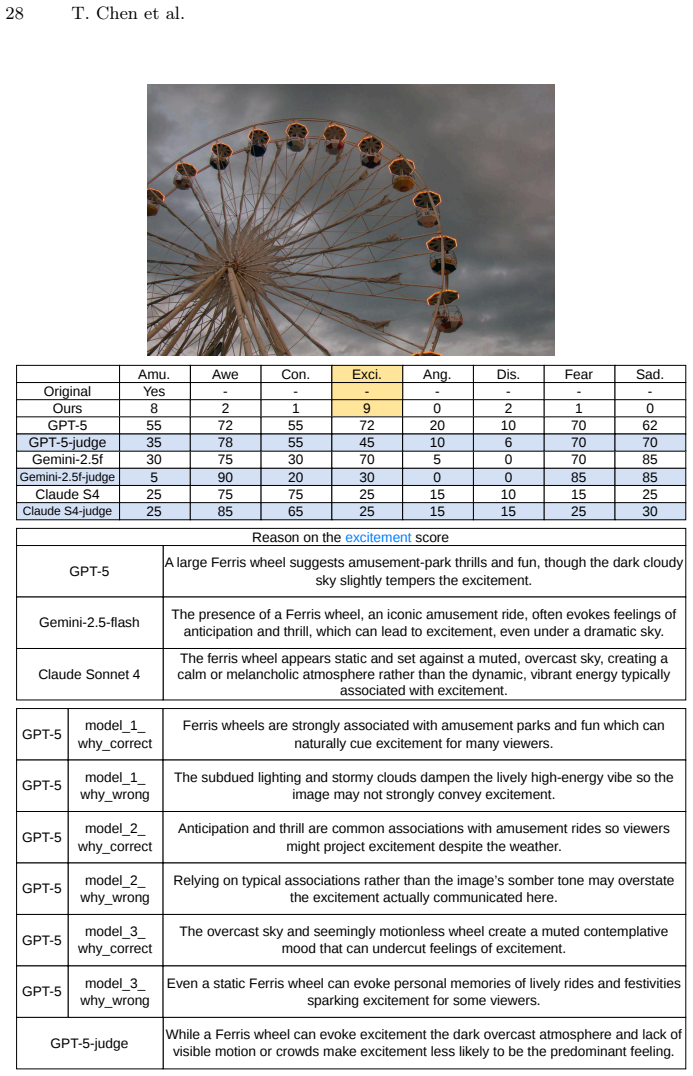
The paper establishes that a multi-label visual emotion benchmark created by aggregating independent selections from twenty annotators per image into vote distributions yields a more representative ground truth than prior single-label schemes. Evaluations of current MLLMs on this benchmark demonstrate measurable progress in both dominant emotion prediction and emotion distribution prediction, while also revealing persistent gaps; additionally, the LLM-as-a-judge approach does not consistently improve results on this subjective task.
What carries the argument
Aggregation of twenty independent annotator selections into per-image vote distributions across eight emotion categories, used as the evaluation target for both dominant and distributional prediction.
If this is right
- MLLMs can now be measured against human vote distributions rather than single forced labels, giving a clearer picture of their multimodal emotion understanding.
- Progress on the benchmark by models such as Qwen3-VL indicates recent advances in handling mixed visual signals, yet the remaining gap points to needed improvements in capturing intensity and multiplicity.
- The LLM-as-a-judge technique shows inconsistent gains, implying it may not be a general solution for subjective perceptual tasks.
- The dataset supplies a ready source of soft labels that could support training or calibration of future models on emotion distributions instead of hard single labels.
Where Pith is reading between the lines
- The same twenty-annotator aggregation approach could be applied to other subjective image properties such as aesthetic quality or implied narrative to create more robust benchmarks.
- Training models directly to match vote distributions rather than single labels might reduce overconfidence on ambiguous images.
- Cultural or demographic differences in emotion perception could be quantified by repeating the annotation process with distinct annotator pools and comparing resulting distributions.
Load-bearing premise
Aggregating independent selections from twenty annotators per image produces a reliable and representative distribution of the emotions actually evoked by each image.
What would settle it
A replication study that collects fresh annotations from a new set of twenty annotators on the same images and finds statistically different emotion distributions would falsify the benchmark's claim to representativeness.
Figures














read the original abstract
This paper introduces a multi-label visual emotion analysis benchmark dataset for comprehensively evaluating the ability of multimodal large language models (MLLMs) to predict the emotions evoked by images. Recent user studies report an unintuitive finding: humans may prefer the predictions of MLLMs over the labels in existing datasets. We argue that this phenomenon stems from the suboptimal annotation scheme used in existing datasets, where each annotator is shown a single candidate emotion for each image and judges whether it is evoked or not. This approach is clearly limited because a single image can evoke multiple emotions with varying intensities. As a result, evaluations based on these datasets may underestimate the capabilities of MLLMs, yet an appropriate benchmark for evaluating such models remains lacking. To address this issue, we introduce a new multi-label benchmark dataset for visual emotion analysis toward MLLMs evaluation. We hire $20$ annotators per image and ask them to select all emotions they feel from an image. Then, we aggregate the votes across all annotators, providing a more reliable and representative dataset labeled with a distribution of emotions. The resulting dataset contains $10,344$ images with $236,998$ valid votes across eight emotions. Based on this benchmark dataset, we evaluate several recent models, including Qwen3-VL, OpenAI's GPT, Gemini, and Claude. We assess model performance on both dominant emotion prediction and emotion distribution prediction. Our results demonstrate the progress achieved by recent MLLMs while also indicating that substantial room for improvement remains. Furthermore, our experiments with LLM-as-a-judge show that the method does not consistently improve MLLMs' performance, indicating its limitations for the subjective task of visual emotion analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MultiEmo-Bench, a multi-label visual emotion dataset of 10,344 images where 20 annotators per image independently select all applicable emotions from eight categories; votes are aggregated into per-image distributions that serve as ground truth. It evaluates recent MLLMs (Qwen3-VL, GPT variants, Gemini, Claude) on dominant-emotion prediction and full distribution prediction, reports measurable progress relative to prior single-label benchmarks, notes substantial remaining headroom, and finds that LLM-as-a-judge does not consistently improve results.
Significance. If the aggregated distributions prove stable, the benchmark supplies a more representative evaluation target for subjective visual-emotion tasks than existing single-label collections and can usefully quantify both advances and limitations in current MLLMs.
major comments (2)
- [Dataset construction] Dataset construction section: the paper collects independent selections from 20 annotators per image and treats the resulting counts as representative ground truth, yet reports no inter-annotator agreement statistics (multi-label Fleiss' kappa, average pairwise Jaccard, or split-half correlation on the 8D vote vectors). For a subjective labeling task this omission leaves open the possibility that label noise rather than model capability drives the observed performance gaps, directly weakening the central claim of measurable progress.
- [Evaluation] Evaluation section: the precise aggregation rule that converts the 20 binary selections into the final distribution (e.g., normalized counts, thresholding) and the exact metric definitions for distribution prediction (KL divergence, Earth-mover distance, or other) are not stated, preventing independent verification of the reported numbers.
minor comments (1)
- Clarify in the abstract and methods whether the 236,998 valid votes exclude images with zero selections or other filtering steps.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the presentation of MultiEmo-Bench. We address each major point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Dataset construction] Dataset construction section: the paper collects independent selections from 20 annotators per image and treats the resulting counts as representative ground truth, yet reports no inter-annotator agreement statistics (multi-label Fleiss' kappa, average pairwise Jaccard, or split-half correlation on the 8D vote vectors). For a subjective labeling task this omission leaves open the possibility that label noise rather than model capability drives the observed performance gaps, directly weakening the central claim of measurable progress.
Authors: We agree that inter-annotator agreement statistics are necessary to establish the stability of the aggregated distributions for this subjective task. In the revised manuscript we will add multi-label Fleiss' kappa, average pairwise Jaccard similarity, and split-half correlation computed on the 8-dimensional vote vectors. These metrics will quantify label consistency and directly support the reliability of the ground-truth distributions used to demonstrate progress over prior single-label benchmarks. revision: yes
-
Referee: [Evaluation] Evaluation section: the precise aggregation rule that converts the 20 binary selections into the final distribution (e.g., normalized counts, thresholding) and the exact metric definitions for distribution prediction (KL divergence, Earth-mover distance, or other) are not stated, preventing independent verification of the reported numbers.
Authors: We apologize for the omission of these implementation details. The aggregation rule is normalized vote counts (number of annotators selecting each emotion divided by 20), with no thresholding. Distribution-prediction metrics are KL divergence and Earth Mover's Distance. We will insert explicit statements of both the aggregation procedure and the metric formulas into the Evaluation section of the revised manuscript to permit full reproducibility. revision: yes
Circularity Check
Benchmark labels constructed independently of model evaluations
full rationale
The paper collects 20 independent human annotations per image, aggregates the votes into fixed emotion distributions, and then evaluates external MLLMs (Qwen3-VL, GPT, Gemini, Claude) against those labels on dominant-emotion and distribution tasks. No equation or claim reduces a model prediction to a fitted parameter, self-definition, or self-citation chain; the ground truth is external to the evaluated models. The LLM-as-a-judge ablation is likewise a direct comparison against the same fixed labels. This is a standard benchmark-construction workflow with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Images evoke emotions that can be categorized into a fixed set of eight emotions.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We hire 20 annotators per image and ask them to select all emotions they feel from an image. Then, we aggregate the votes across all annotators, providing a more reliable and representative dataset labeled with a distribution of emotions.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Anthropic: System card: Claude opus 4 & claude sonnet 4. Tech. rep., Anthropic (May 2025)
work page 2025
-
[3]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y., Tang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
In: Chiruzzo, L., Ritter, A., Wang, L
Bhattacharyya, S., Wang, J.Z.: Evaluating vision-language models for emotion recognition. In: Chiruzzo, L., Ritter, A., Wang, L. (eds.) NAACL Findings. pp. 1798–1820. Association for Computational Linguistics (2025)
work page 2025
- [5]
-
[6]
Cheng, Z., Cheng, Z., He, J., Wang, K., Lin, Y., Lian, Z., Peng, X., Hauptmann, A.G.: Emotion-llama: Multimodal emotion recognition and reasoning with instruc- tion tuning. In: NeurIPS (2024)
work page 2024
- [7]
- [8]
-
[9]
Gao, L., Jia, Z., Zeng, Y., Sun, W., Zhang, Y., Zhou, W., Zhai, G., Min, X.: Eemo-bench: A benchmark for multi-modal large language models on image evoked emotion assessment. In: Gurrin, C., Schoeffmann, K., Zhang, M., Rossetto, L., Rudinac, S., Dang-Nguyen, D., Cheng, W., Chen, P., Benois-Pineau, J. (eds.) ACM MM. pp. 7064–7073 (2025)
work page 2025
-
[10]
Google DeepMind: Gemini 3 flash model card (Feb 2026)
work page 2026
-
[11]
EmoVerse: A MLLMs-Driven Emotion Representation Dataset for Interpretable Visual Emotion Analysis
Guo, Y., Hong, D., Chen, W., She, Z., Ye, C., Chang, X., Mao, Z.: Emoverse: A mllms-driven emotion representation dataset for interpretable visual emotion analysis. arXiv e-printsabs/2511.12554(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Huang, Y., Sheng, X., Yang, Z., Yuan, Q., Duan, Z., Chen, P., Li, L., Lin, W., Shi, G.: Aesexpert: Towards multi-modality foundation model for image aesthetics perception. In: ACM MM. pp. 5911–5920 (2024)
work page 2024
-
[13]
arXiv e-printsabs/2401.08276(2024) 16 T
Huang, Y., Yuan, Q., Sheng, X., Yang, Z., Wu, H., Chen, P., Yang, Y., Li, L., Lin, W.: Aesbench: An expert benchmark for multimodal large language models on image aesthetics perception. arXiv e-printsabs/2401.08276(2024) 16 T. Chen et al
-
[14]
NIMH Center for the Study of Emotion and Attention1(39-58), 3 (1997)
Lang, P.J., Bradley, M.M., Cuthbert, B.N., et al.: International affective picture system (iaps): Technical manual and affective ratings. NIMH Center for the Study of Emotion and Attention1(39-58), 3 (1997)
work page 1997
- [15]
-
[16]
arXiv e-printsabs/2407.07653 (2024)
Lian, Z., Sun, H., Sun, L., Yi, J., Liu, B., Tao, J.: Affectgpt: Dataset and framework for explainable multimodal emotion recognition. arXiv e-printsabs/2407.07653 (2024)
-
[17]
arXiv e-printsabs/2503.23907(2025)
Liao, Z., Liu, X., Qin, W., Li, Q., Wang, Q., Wan, P., Zhang, D., Zeng, L., Feng, P.: Humanaesexpert: Advancing a multi-modality foundation model for human image aesthetic assessment. arXiv e-printsabs/2503.23907(2025)
- [18]
-
[19]
In: Bimbo, A.D., Chang, S., Smeulders, A.W.M
Machajdik, J., Hanbury, A.: Affective image classification using features inspired by psychology and art theory. In: Bimbo, A.D., Chang, S., Smeulders, A.W.M. (eds.) ACM MM. pp. 83–92. ACM (2010)
work page 2010
-
[20]
In: Globersons, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J.M., Zhang, C
Mertens, L., Yargholi, E., de Beeck, H.P.O., den Stock, J.V., Vennekens, J.: Find- ingemo: An image dataset for emotion recognition in the wild. In: Globersons, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J.M., Zhang, C. (eds.) AAAI (2024)
work page 2024
-
[21]
Behavior Research Methods37, 626–630 (2005)
Mikels, J.A., Fredrickson, B.L., Larkin, G.R.S., Lindberg, C.M., Maglio, S.J., Reuter-Lorenz, P.A.: Emotional category data on images from the international affective picture system. Behavior Research Methods37, 626–630 (2005)
work page 2005
- [22]
-
[23]
OpenAI: Gpt-4o system card. arXiv e-printsabs/2410.21276(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
OpenAI: Gpt-5.1 instant and gpt-5.1 thinking system card addendum (Nov 2025)
work page 2025
-
[25]
OpenAI: Openai GPT-5 system card. arXiv e-printsabs/2601.03267(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [26]
-
[27]
Team, G.: Gemini 2.5: Pushing the frontier with advanced reasoning, multi- modality, long context, and next generation agentic capabilities. arXiv e-prints abs/2507.06261(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [28]
- [29]
-
[30]
Yang, J., Sun, M., Sun, X.: Learning visual sentiment distributions via augmented conditional probability neural network. In: Singh, S., Markovitch, S. (eds.) AAAI. pp. 224–230 (2017)
work page 2017
-
[31]
In: Schuurmans, D., Wellman, M.P
You, Q., Luo, J., Jin, H., Yang, J.: Building a large scale dataset for image emotion recognition: The fine print and the benchmark. In: Schuurmans, D., Wellman, M.P. (eds.) AAAI. pp. 308–314 (2016)
work page 2016
-
[32]
Zhang, C., Xie, H., Wen, B., Zuo, S., Zhang, R., Cheng, W.: Emoart: A mul- tidimensional dataset for emotion-aware artistic generation. In: ACM MM. pp. 12644–12650 (2025) Title Suppressed Due to Excessive Length 17
work page 2025
-
[33]
Zhao, S., Yao, X., Yang, J., Jia, G., Ding, G., Chua, T., Schuller, B.W., Keutzer, K.: Affective image content analysis: Two decades review and new perspectives. TPAMI44(10), 6729–6751 (2022)
work page 2022
-
[34]
Zhou, H., Tang, L., Yang, R., Qin, G., Zhang, Y., Hu, R., Li, X.: Uniqa: Unified vision-language pre-training for image quality and aesthetic assessment. arXiv e- printsabs/2406.01069(2024) 18 T. Chen et al. Do you think this image will makes people feel ${emotion}? GPT-5: Yes Gemini-2.5-flash: Yes Claude Sonnet 4: Yes -- - YesYes - - - Ang.AweCon.Exci.Am...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.