Teaching Large Language Models When Not to Know: Learning Temporal Critique for Ex-Ante Reasoning
Pith reviewed 2026-06-30 20:44 UTC · model grok-4.3
The pith
A fine-tuning method trains LLMs to detect and reject answers that use knowledge unavailable before a given cutoff.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Temporal Critique Fine-Tuning framework trains models, given a query, cutoff, and candidate response, to identify post-cutoff leakage, explain temporal boundary violations, and judge temporal admissibility, thereby enabling cutoff-aware verification that prompting and standard supervised fine-tuning do not produce.
What carries the argument
Temporal Critique Fine-Tuning (TCFT), which supplies supervised examples of leakage identification and admissibility judgment to teach cutoff-aware verification.
If this is right
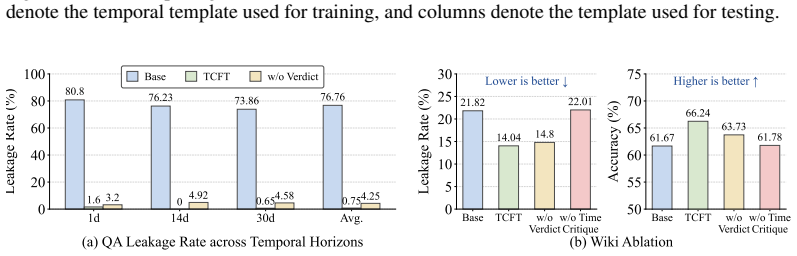
- TCFT reduces average leakage by 41.89 percentage points on Qwen2.5-7B-Instruct and 37.79 on Qwen2.5-14B-Instruct relative to prompting and SFT baselines.
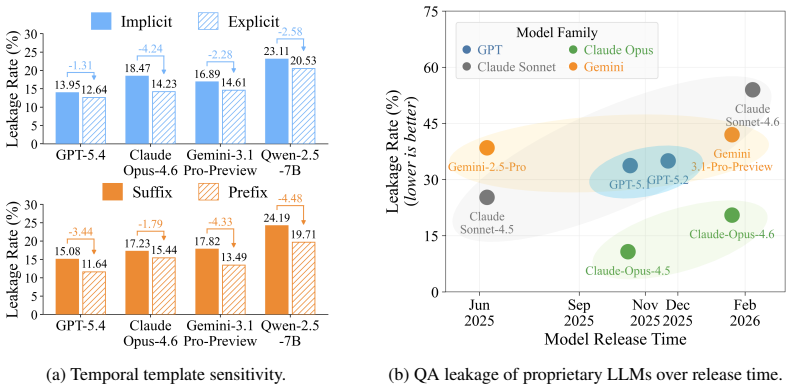
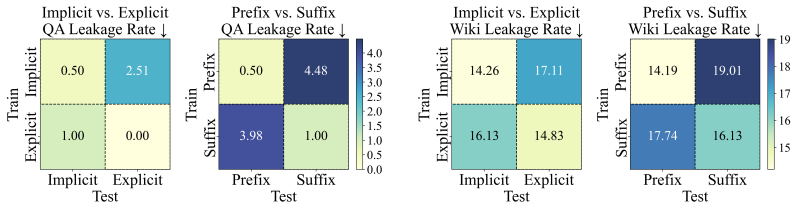
- Explicit cutoff statements outperform implicit historical framings at reducing leakage.
- Prefix constraints reduce leakage more effectively than suffix constraints.
- Ex-ante correctness cannot be learned by ordinary supervised fine-tuning because it is a relation between answer and cutoff.
Where Pith is reading between the lines
- The same critique-training pattern could be applied to other relational constraints such as domain-specific knowledge limits or source attribution.
- Verification training might improve a model's ability to refuse answers when any required fact is missing, not only temporally missing facts.
- The approach suggests a route to training models that maintain consistency across multiple time-stamped queries in a single conversation.
Load-bearing premise
Training a model to critique leakage on supervised examples will cause it to apply cutoff-aware verification during ordinary generation instead of merely memorizing critique patterns.
What would settle it
After TCFT training, evaluate the model on fresh queries whose post-cutoff facts were never seen in the critique examples; if leakage rates remain comparable to prompting baselines, the generalization claim is false.
Figures
read the original abstract
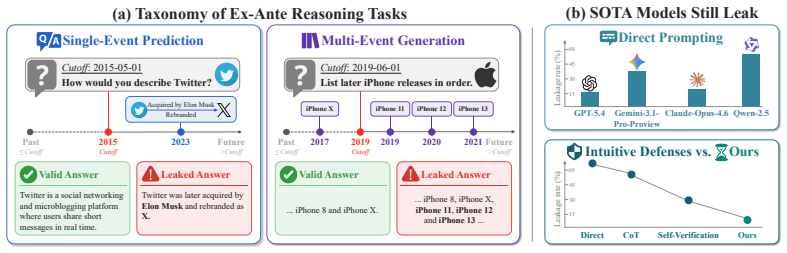
Large language models (LLMs) often fail to reason under temporal cutoffs: when prompted to answer from the standpoint of an earlier time, they exploit knowledge that became available only later. We study this failure through the lens of ex-ante reasoning, where a model must rely exclusively on information knowable before a cutoff. Through a systematic analysis of prompt-level interventions, we find that temporal leakage is highly sensitive to cutoff formulation and instruction placement: explicit cutoff statements outperform implicit historical framings, and prefix constraints reduce leakage more effectively than suffix constraints. These findings indicate that prompting can steer models into a temporal frame, but does not endow them with the ability to verify whether a response is temporally admissible. We further argue that supervised fine-tuning is insufficient, since ex-ante correctness is not an intrinsic property of an answer, but a relation between the answer and the cutoff. To address this gap, we propose TCFT, a Temporal Critique Fine-Tuning framework that trains models to acquire cutoff-aware temporal verification. Given a query, a cutoff, and a candidate response, TCFT teaches the model to identify post-cutoff leakage, explain temporal boundary violations, and judge temporal admissibility. Experiments with Qwen2.5-7B-Instruct and Qwen2.5-14B-Instruct show that TCFT consistently outperforms prompting and SFT baselines, reducing average leakage by 41.89 and 37.79 percentage points, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs fail at ex-ante reasoning under temporal cutoffs by leaking post-cutoff knowledge. Systematic prompt analysis shows leakage is sensitive to cutoff formulation and instruction placement, with explicit prefixes most effective, but prompting alone cannot teach verification. The authors argue SFT is insufficient because temporal admissibility is relational rather than intrinsic to an answer. They introduce TCFT, which fine-tunes on (query, cutoff, response) triples to produce leakage identification, violation explanations, and admissibility judgments. Experiments on Qwen2.5-7B-Instruct and Qwen2.5-14B-Instruct report that TCFT reduces average leakage by 41.89 and 37.79 percentage points over prompting and SFT baselines.
Significance. If the gains prove robust to distribution shift, the work would be significant for temporal reasoning in LLMs, a capability relevant to historical QA, forecasting, and knowledge-grounded generation. The explicit separation of steering (prompting) from learned verification (critique fine-tuning) is a useful conceptual contribution, and the consistent improvements across two model scales provide initial evidence that the approach is viable. The paper does not claim parameter-free derivations or machine-checked proofs, but the experimental deltas are the primary result.
major comments (3)
- [Abstract / Experiments] Abstract and Experiments section: The central claim that TCFT produces generalizable cutoff-aware verification (rather than memorization of critique patterns) rests on the reported leakage reductions, yet no description is given of held-out cutoffs, novel response styles, or out-of-distribution domains in the evaluation. Without such controls, the 37–42 pp gains could be explained by surface-pattern matching on the supervised triples.
- [Abstract] Abstract: The quantitative results (41.89 pp and 37.79 pp reductions) are presented without dataset size, leakage metric definition, baseline implementation details, or statistical significance tests. This absence prevents assessment of whether the deltas are reliable or sensitive to evaluation choices.
- [Method] Method section: The paper correctly notes that ex-ante correctness is relational, yet TCFT remains a standard supervised objective over fixed (query, cutoff, response) examples. Additional analysis is required to show how the critique objective captures the relational structure in a way that ordinary SFT on answers does not.
minor comments (1)
- [Abstract] The abstract would be clearer if it briefly stated the number of evaluation instances and how leakage is operationalized (e.g., exact knowledge overlap or human judgment).
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate planned revisions to improve clarity, rigor, and support for our claims.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: The central claim that TCFT produces generalizable cutoff-aware verification (rather than memorization of critique patterns) rests on the reported leakage reductions, yet no description is given of held-out cutoffs, novel response styles, or out-of-distribution domains in the evaluation. Without such controls, the 37–42 pp gains could be explained by surface-pattern matching on the supervised triples.
Authors: We acknowledge this limitation in the current manuscript. The reported experiments use cutoffs and response styles drawn from the same distribution as the supervised training triples, without explicit held-out cutoffs or OOD domains. This leaves open the possibility of surface-level pattern matching. In the revision we will add a new subsection in Experiments with held-out temporal cutoffs, novel response styles, and queries from out-of-distribution domains (e.g., different topical areas), reporting leakage reductions under these conditions to better substantiate the generalizability claim. revision: yes
-
Referee: [Abstract] Abstract: The quantitative results (41.89 pp and 37.79 pp reductions) are presented without dataset size, leakage metric definition, baseline implementation details, or statistical significance tests. This absence prevents assessment of whether the deltas are reliable or sensitive to evaluation choices.
Authors: We agree that the abstract should be self-contained for these details. While the full definitions, dataset sizes (approximately 12k training triples and 2.5k evaluation instances per model), leakage metric (binary post-cutoff knowledge detection), baseline implementations, and bootstrap significance tests appear in Sections 4 and 5, we will revise the abstract to include concise statements of dataset scale, metric definition, baseline descriptions, and significance results. revision: yes
-
Referee: [Method] Method section: The paper correctly notes that ex-ante correctness is relational, yet TCFT remains a standard supervised objective over fixed (query, cutoff, response) examples. Additional analysis is required to show how the critique objective captures the relational structure in a way that ordinary SFT on answers does not.
Authors: We accept that the current Method section provides only a high-level argument for the relational nature of admissibility. To demonstrate the distinction, we will add an analysis subsection that (a) compares TCFT directly against standard answer-only SFT on the same queries and cutoffs, (b) ablates the three critique heads (leakage identification, violation explanation, admissibility judgment), and (c) reports how performance on relational verification tasks degrades under answer-only supervision. This will be included in the revised manuscript. revision: yes
Circularity Check
No circularity: empirical method with external experimental validation
full rationale
The paper defines TCFT as a supervised fine-tuning procedure on (query, cutoff, response) triples that produces leakage identification, violation explanations, and admissibility judgments. It then reports performance deltas on held-out evaluations against prompting and standard SFT baselines. No equations, fitted parameters, or self-citations appear in the provided text. The central claim (leakage reduction of ~38-42 pp) is an observed experimental outcome rather than a quantity defined in terms of the training objective itself. The derivation chain therefore contains no self-definitional, fitted-input-called-prediction, or self-citation-load-bearing steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Ex-ante correctness is a relation between answer and cutoff that can be taught via supervised critique examples
Reference graph
Works this paper leans on
-
[1]
ExAnte: A benchmark for ex-ante inference in large language models
Yachuan Liu, Xiaochun Wei, Lin Shi, Xinnuo Li, Bohan Zhang, Paramveer Dhillon, and Qiaozhu Mei. ExAnte: A benchmark for ex-ante inference in large language models. InEACL (V olume 1: Long Papers), pages 1551–1571. Association for Computational Linguistics, 2026
2026
-
[2]
Large language models in finance (finllms)
Jean Lee, Nicholas Stevens, and Soyeon Caren Han. Large language models in finance (finllms). Neural Comput. Appl., 37(30):24853–24867, 2025
2025
-
[3]
Chatgpt for textual analysis? how to use generative llms in accounting research
Ties de Kok. Chatgpt for textual analysis? how to use generative llms in accounting research. Manag. Sci., 71(9):7888–7906, 2025
2025
-
[4]
Battleagent: Multi-modal dynamic emulation on historical battles to complement historical analysis
Shuhang Lin, Wenyue Hua, Lingyao Li, Che-Jui Chang, Lizhou Fan, Jianchao Ji, Hang Hua, Mingyu Jin, Jiebo Luo, and Yongfeng Zhang. Battleagent: Multi-modal dynamic emulation on historical battles to complement historical analysis. InEMNLP (System Demonstrations), pages 172–181. Association for Computational Linguistics, 2024
2024
-
[5]
Researchagent: Iterative research idea generation over scientific literature with large language models
Jinheon Baek, Sujay Kumar Jauhar, Silviu Cucerzan, and Sung Ju Hwang. Researchagent: Iterative research idea generation over scientific literature with large language models. In NAACL (Long Papers), pages 6709–6738. Association for Computational Linguistics, 2025
2025
-
[6]
OpenAI. GPT-4 technical report.CoRR, abs/2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team. Gemini: A family of highly capable multimodal models.CoRR, abs/2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Lawrie, Daniel Khashabi, and Ben- jamin Van Durme
Jeffrey Cheng, Marc Marone, Orion Weller, Dawn J. Lawrie, Daniel Khashabi, and Ben- jamin Van Durme. Dated data: Tracing knowledge cutoffs in large language models.CoRR, abs/2403.12958, 2024
-
[9]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V . Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InNeurIPS, 2022
2022
-
[10]
Towards mitigating LLM hallucination via self reflection
Ziwei Ji, Tiezheng Yu, Yan Xu, Nayeon Lee, Etsuko Ishii, and Pascale Fung. Towards mitigating LLM hallucination via self reflection. InEMNLP (Findings), Findings of ACL, pages 1827–
-
[11]
Association for Computational Linguistics, 2023
2023
-
[12]
Yubo Wang, Xiang Yue, and Wenhu Chen. Critique Fine-Tuning: Learning to critique is more effective than learning to imitate.CoRR, abs/2501.17703, 2025
-
[13]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. InICLR. OpenReview.net, 2022
2022
-
[14]
Victor Sanh, Albert Webson, Colin Raffel, Stephen H. Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, Arnaud Stiegler, Arun Raja, Manan Dey, M Saiful Bari, Canwen Xu, Urmish Thakker, Shanya Sharma Sharma, Eliza Szczechla, Taewoon Kim, Gunjan Chhablani, Nihal V . Nayak, Debajyoti Datta, Jonathan Chang, Mike Tian-Jian Jiang, Han Wang, Matteo Manica, ...
2022
-
[15]
Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M
Jason Wei, Maarten Bosma, Vincent Y . Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, and Quoc V . Le. Finetuned language models are zero-shot learners. In ICLR. OpenReview.net, 2022. 10
2022
-
[16]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human fee...
2022
-
[17]
Smith, Daniel Khashabi, and Hannaneh Hajishirzi
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language models with self-generated instruc- tions. InACL (1), pages 13484–13508. Association for Computational Linguistics, 2023
2023
-
[18]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InICLR. OpenReview.net, 2024
2024
-
[20]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tingyu X...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Wikipedia
Wikimedia Foundation. Wikipedia. https://www.wikipedia.org/, 2026. Accessed: 2026- 05-07
2026
-
[22]
Large language models are zero-shot time series forecasters.Advances in neural information processing systems, 36:19622– 19635, 2023
Nate Gruver, Marc Finzi, Shikai Qiu, and Andrew G Wilson. Large language models are zero-shot time series forecasters.Advances in neural information processing systems, 36:19622– 19635, 2023
2023
-
[23]
Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
Ming Jin, Shiyu Wang, Lintao Ma, Zhixuan Chu, James Y Zhang, Xiaoming Shi, Pin-Yu Chen, Yuxuan Liang, Yuan-Fang Li, Shirui Pan, et al. Time-llm: Time series forecasting by reprogramming large language models.arXiv preprint arXiv:2310.01728, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Order matters: Investigate the position bias in multi-constraint instruction following.Seed, 1(2):3–4
Multi-Constraint Instruction. Order matters: Investigate the position bias in multi-constraint instruction following.Seed, 1(2):3–4
-
[25]
Introducing gpt-5.4
OpenAI. Introducing gpt-5.4. https://openai.com/index/introducing-gpt-5-4/ ,
-
[26]
Accessed: 2026-05-07
2026
-
[27]
Living in the moment: Can large language models grasp co-temporal reasoning? InACL (1), pages 13014–13033
Zhaochen Su, Juntao Li, Jun Zhang, Tong Zhu, Xiaoye Qu, Pan Zhou, Yan Bowen, Yu Cheng, and Min Zhang. Living in the moment: Can large language models grasp co-temporal reasoning? InACL (1), pages 13014–13033. Association for Computational Linguistics, 2024
2024
-
[28]
Towards benchmarking and improving the temporal reasoning capability of large language models
Qingyu Tan, Hwee Tou Ng, and Lidong Bing. Towards benchmarking and improving the temporal reasoning capability of large language models. InACL (1), pages 14820–14835. Association for Computational Linguistics, 2023
2023
-
[29]
TRAM: benchmarking temporal reasoning for large language models
Yuqing Wang and Yun Zhao. TRAM: benchmarking temporal reasoning for large language models. InACL (Findings), Findings of ACL, pages 6389–6415. Association for Computational Linguistics, 2024
2024
-
[30]
TimeBench: A comprehensive evaluation of temporal reasoning abilities in large language models
Zheng Chu, Jingchang Chen, Qianglong Chen, Weijiang Yu, Haotian Wang, Ming Liu, and Bing Qin. TimeBench: A comprehensive evaluation of temporal reasoning abilities in large language models. InACL (1), pages 1204–1228. Association for Computational Linguistics, 2024
2024
-
[31]
Test of Time: A benchmark for evaluating llms on temporal reasoning
Bahare Fatemi, Mehran Kazemi, Anton Tsitsulin, Karishma Malkan, Jinyeong Yim, John Palowitch, Sungyong Seo, Jonathan Halcrow, and Bryan Perozzi. Test of Time: A benchmark for evaluating llms on temporal reasoning. InICLR. OpenReview.net, 2025. 11
2025
-
[32]
StreamingQA: A benchmark for adaptation to new knowledge over time in question answering models
Adam Liska, Tomás Kociský, Elena Gribovskaya, Tayfun Terzi, Eren Sezener, Devang Agrawal, Cyprien de Masson d’Autume, Tim Scholtes, Manzil Zaheer, Susannah Young, Ellen Gilsenan- McMahon, Sophia Austin, Phil Blunsom, and Angeliki Lazaridou. StreamingQA: A benchmark for adaptation to new knowledge over time in question answering models. InICML, Proceedings...
2022
-
[33]
Time travel in llms: Tracing data contamination in large language models
Shahriar Golchin and Mihai Surdeanu. Time travel in llms: Tracing data contamination in large language models. InICLR. OpenReview.net, 2024
2024
-
[34]
To the cutoff
Manley Roberts, Himanshu Thakur, Christine Herlihy, Colin White, and Samuel Dooley. To the cutoff... and beyond? A longitudinal perspective on LLM data contamination. InICLR. OpenReview.net, 2024
2024
-
[35]
In-context unlearning: Language models as few-shot unlearners
Martin Pawelczyk, Seth Neel, and Himabindu Lakkaraju. In-context unlearning: Language models as few-shot unlearners. InICML. OpenReview.net, 2024
2024
-
[37]
Unified parameter-efficient unlearning for llms
Chenlu Ding, Jiancan Wu, Yancheng Yuan, Jinda Lu, Kai Zhang, Alex Su, Xiang Wang, and Xiangnan He. Unified parameter-efficient unlearning for llms. InICLR. OpenReview.net, 2025
2025
-
[38]
Machine unlearning in generative AI: A survey.CoRR, abs/2407.20516, 2024
Zheyuan Liu, Guangyao Dou, Zhaoxuan Tan, Yijun Tian, and Meng Jiang. Machine unlearning in generative AI: A survey.CoRR, abs/2407.20516, 2024
-
[39]
Towards safer large language models through machine unlearning
Zheyuan Liu, Guangyao Dou, Zhaoxuan Tan, Yijun Tian, and Meng Jiang. Towards safer large language models through machine unlearning. InACL (Findings), Findings of ACL, pages 1817–1829. Association for Computational Linguistics, 2024
2024
-
[40]
Unrolling sgd: Understanding factors influencing machine unlearning
Anvith Thudi, Gabriel Deza, Varun Chandrasekaran, and Nicolas Papernot. Unrolling sgd: Understanding factors influencing machine unlearning. In2022 IEEE 7th European Symposium on Security and Privacy (EuroS&P), pages 303–319. IEEE, 2022
2022
-
[41]
Negative Preference Optimization: From Catastrophic Collapse to Effective Unlearning
Ruiqi Zhang, Licong Lin, Yu Bai, and Song Mei. Negative preference optimization: From catastrophic collapse to effective unlearning.CoRR, abs/2404.05868, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Chenlu Ding, Jiancan Wu, Leheng Sheng, Fan Zhang, Yancheng Yuan, Xiang Wang, and Xiangnan He. Mllmeraser: Achieving test-time unlearning in multimodal large language models through activation steering.CoRR, abs/2510.04217, 2025
-
[43]
Lookahead bias in pretrained language models
Suproteem K Sarkar and Keyon Vafa. Lookahead bias in pretrained language models. InICML 2025 Workshop on Reliable and Responsible F oundation Models, 2024
2025
-
[44]
Self-refine: Iterative refinement with self-feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self-refine: Iterative refinement with self-feedback. InNeurIPS, 2023
2023
-
[45]
Reflexion: language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: language agents with verbal reinforcement learning. InNeurIPS, 2023
2023
-
[46]
CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing
Zhibin Gou, Zhihong Shao, Yeyun Gong, Yelong Shen, Yujiu Yang, Nan Duan, and Weizhu Chen. Critic: Large language models can self-correct with tool-interactive critiquing.arXiv preprint arXiv:2305.11738, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[47]
Xin Xu, Tianhao Chen, Fan Zhang, Wanlong Liu, Pengxiang Li, Ajay Kumar Jaiswal, Yuchen Yan, Jishan Hu, Yang Wang, Hao Chen, et al. Double-checker: Enhancing reasoning of slow-thinking llms via self-critical fine-tuning.arXiv preprint arXiv:2506.21285, 2025
-
[48]
Karthik Valmeekam, Matthew Marquez, and Subbarao Kambhampati. Can large language models really improve by self-critiquing their own plans?arXiv preprint arXiv:2310.08118, 2023. 12
-
[49]
Solving math word problems with process- and outcome-based feedback
Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. Solving math word problems with process-and outcome-based feedback.arXiv preprint arXiv:2211.14275, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[50]
Math-shepherd: Verify and reinforce llms step-by-step without human annotations
Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. Math-shepherd: Verify and reinforce llms step-by-step without human annotations. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 9426–9439, 2024
2024
-
[51]
arXiv preprint arXiv:2412.01981 , year=
Lifan Yuan, Wendi Li, Huayu Chen, Ganqu Cui, Ning Ding, Kaiyan Zhang, Bowen Zhou, Zhiyuan Liu, and Hao Peng. Free process rewards without process labels.arXiv preprint arXiv:2412.01981, 2024
-
[52]
arXiv preprint arXiv:2408.11791 , year =
Zachary Ankner, Mansheej Paul, Brandon Cui, Jonathan D Chang, and Prithviraj Ammanabrolu. Critique-out-loud reward models.arXiv preprint arXiv:2408.11791, 2024
-
[53]
Factscore: Fine-grained atomic evaluation of factual precision in long form text generation
Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. Factscore: Fine-grained atomic evaluation of factual precision in long form text generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12076–12100, 2023
2023
-
[54]
Introducing claude opus 4.6
Anthropic. Introducing claude opus 4.6. https://www.anthropic.com/news/ claude-opus-4-6, 2026. Accessed: 2026-05-07
2026
-
[55]
Gemini 3.1 pro preview
Google. Gemini 3.1 pro preview. https://ai.google.dev/gemini-api/docs/models/ gemini-3.1-pro-preview, 2026. Accessed: 2026-05-07
2026
-
[56]
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[57]
prefix advantage
Ziwei Ji, Tiezheng Yu, Yan Xu, Nayeon Lee, Etsuko Ishii, and Pascale Fung. Towards mitigating llm hallucination via self reflection. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 1827–1843, 2023. A Related Work A.1 Temporal Reasoning Evaluating LLMs on time-related dimensions has historically centered on temporal reasoning...
2023
-
[58]
The 2020 Summer Olympics were scheduled to take place in Tokyo, Japan
2020
-
[59]
The opening ceremony of the 2020 Summer Olympics was planned for July 24, 2020
2020
-
[60]
The 2020 Summer Olympics were originally set to include 33 sports across 339 events
2020
-
[61]
The Olympic Village for the 2020 Summer Olympics was located in Musashino Forest Park
2020
-
[62]
I don’t know
The torch relay for the 2020 Summer Olympics began on March 26, 2020. 19 Critique 1–3 are fine as of Jan. 1, 2020: Tokyo was the host city, the opening ceremony was scheduled for July 24, 2020, and the program was planned for 33 sports and 339 events. 4 is wrong factually. Musashino Forest Park was a venue, not the Olympic Village. The Olympic Village was...
2020
-
[67]
Few-shot
Emma Watson has blonde hair and blue eyes. Few-shot
-
[69]
She played the role of Hermione Granger in the Harry Potter film series
-
[70]
Emma Watson was appointed as a UN Women Goodwill Ambassador in 2014(after the cutoff)
2014
-
[71]
She graduated from Brown University in 2017 with a degree in English literature and French studies(post-cutoff; actual graduation was in 2014)
2017
-
[72]
21 Chain-of-thought
As of January 1st, 2011, she was known for her roles in the Harry Potter films and had not yet become a UN Women Goodwill Ambassador. 21 Chain-of-thought
2011
-
[74]
Emma Watson played the character Hermione Granger in the Harry Potter film series
-
[75]
Emma Watson is an English actress and UN Women Goodwill Ambassador(appointed in Jul. 2014)
2014
-
[76]
Emma Watson graduated from Brown University in 2014(after the cutoff)
2014
-
[77]
Self-verification
Emma Watson has blonde hair and blue eyes. Self-verification
-
[79]
The Perks of Being a Wallflower
On January 1, 2011, Emma Watson was starring in the film “The Perks of Being a Wallflower.”
2011
-
[80]
As of January 1, 2011, Emma Watson had completed her role as Hermione Granger in the Harry Potter film series
2011
-
[81]
Emma Watson was on an academic leave from Brown University(announced after the cutoff)as of January 1, 2011
2011
-
[82]
Ours (TCFT)
By January 1, 2011, Emma Watson had been involved in various UN Women campaigns promoting gender equality (UN Women involvement began after the cutoff). Ours (TCFT)
2011
-
[83]
Emma Watson was born on April 15, 1990
1990
-
[84]
She was known for her role as Hermione Granger in the Harry Potter film series
-
[85]
On January 1, 2011, she was 20 years old
2011
-
[86]
Harry Potter and the Deathly Hallows – Part 1
She had appeared in the film “Harry Potter and the Deathly Hallows – Part 1” before this date
-
[87]
She was a British actress. 22
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.