Unbiased and Second-Order-Free Training for High-Dimensional PDEs
Pith reviewed 2026-06-30 21:26 UTC · model grok-4.3
The pith
A new training framework removes Euler-Maruyama bias from BSDE PDE solvers without second-order derivatives or added overhead.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
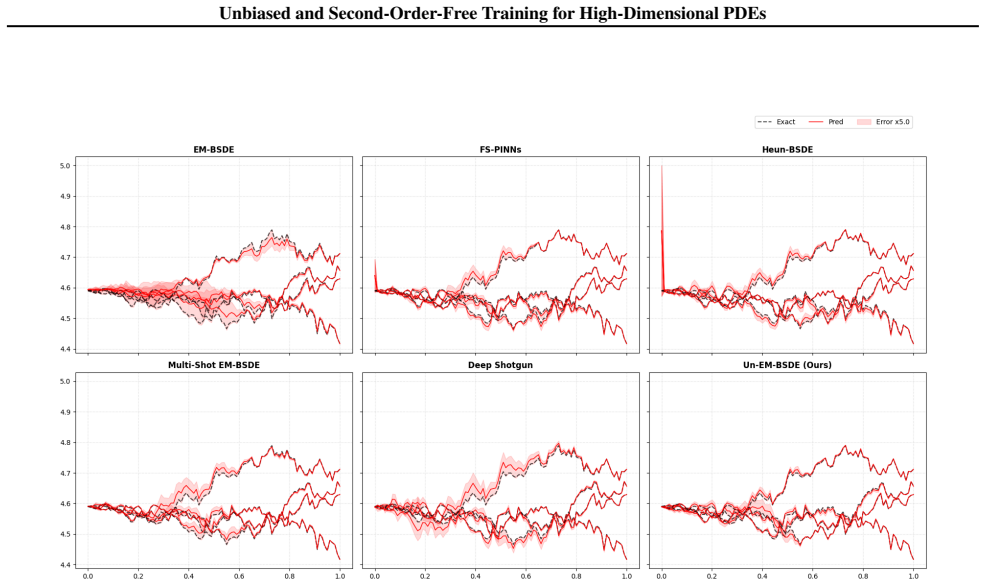
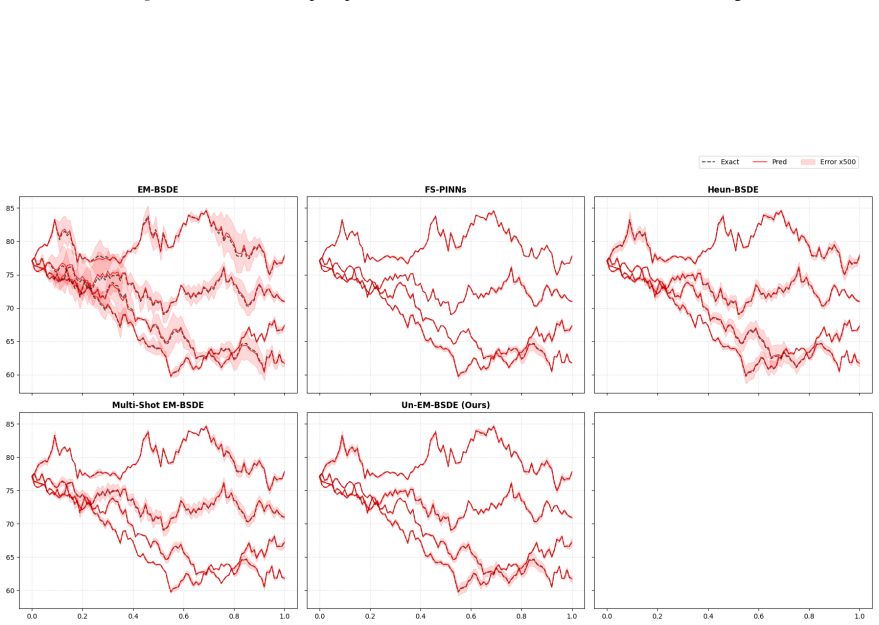
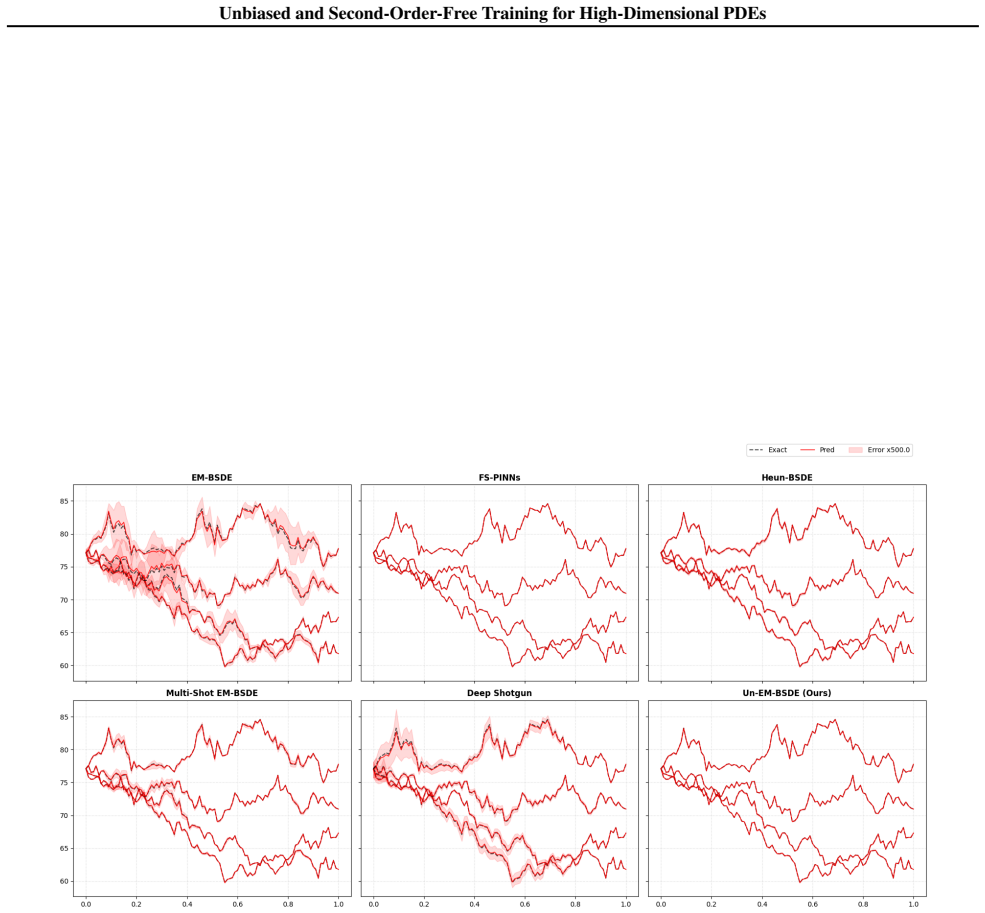
The paper shows through analysis that the Euler-Maruyama discretization induces a specific bias in BSDE training losses. It proposes an unbiased training framework that corrects this bias directly in the loss function, preserving the second-order-free property and computational advantages of BSDE methods for high-dimensional PDEs.
What carries the argument
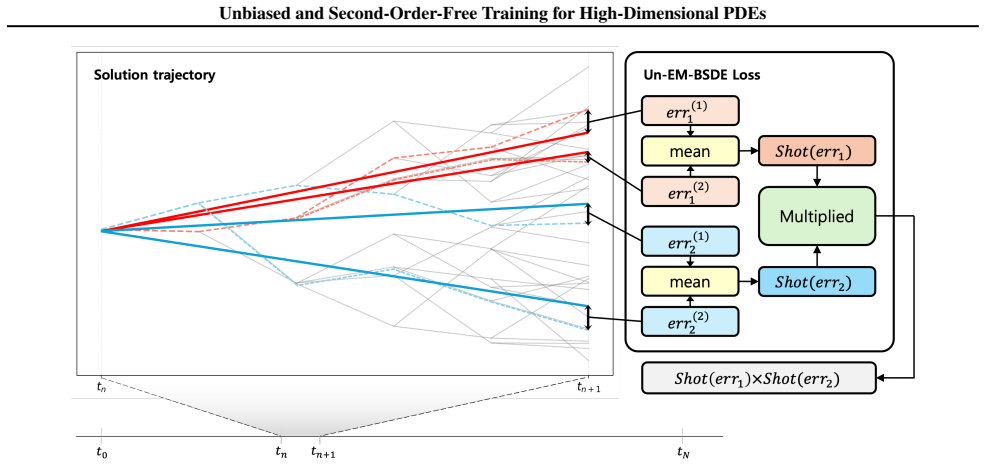
The unbiased loss function obtained from the EM bias analysis, which adjusts the training objective to cancel the discretization error without Hessian evaluations.
If this is right
- BSDE-based solvers achieve unbiased training at the cost level of standard Euler-Maruyama schemes.
- High-dimensional PDE accuracy improves without raising the order of spatial derivatives required.
- The probabilistic representation advantages of BSDE methods remain intact.
- Computational cost stays comparable to first-order methods even after bias removal.
Where Pith is reading between the lines
- The bias-correction approach could apply to other time discretizations used in stochastic differential equation solvers.
- Reduced bias accumulation might improve accuracy for PDEs integrated over long time horizons.
- Similar loss adjustments could be tested in related deep-learning PDE methods that rely on probabilistic representations.
Load-bearing premise
The bias correction can be applied exactly in the loss during training without creating new approximation errors or needing extra derivative computations.
What would settle it
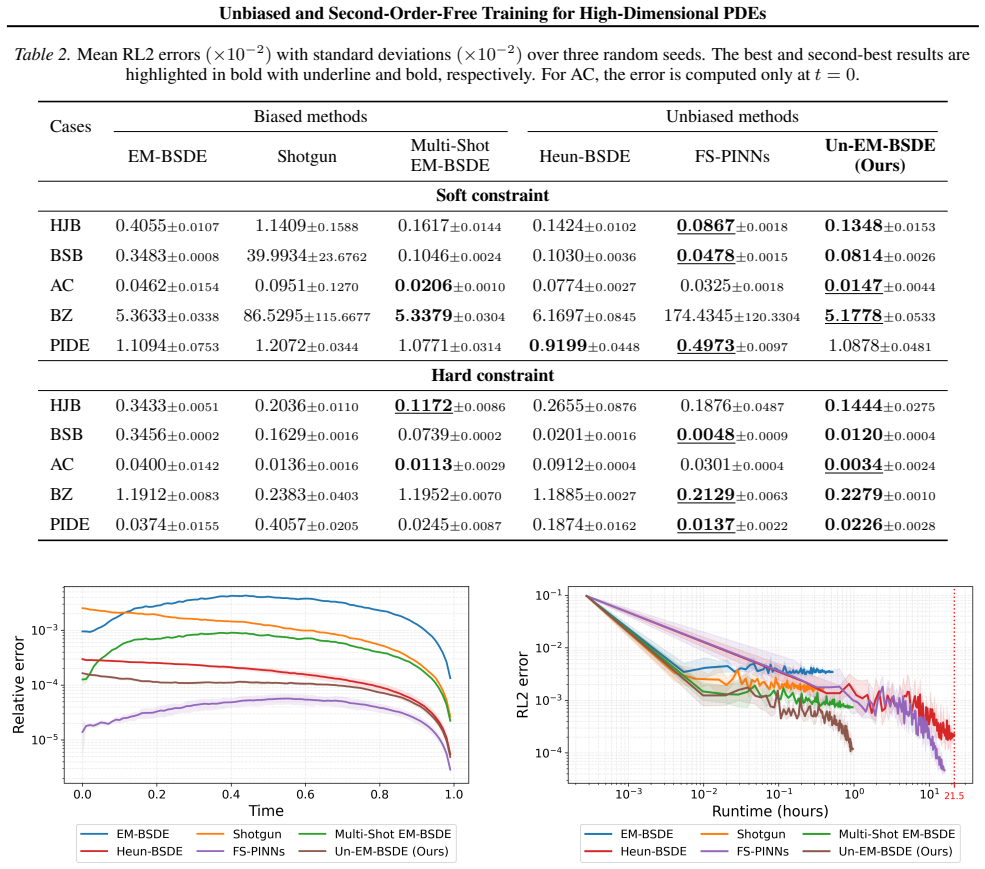
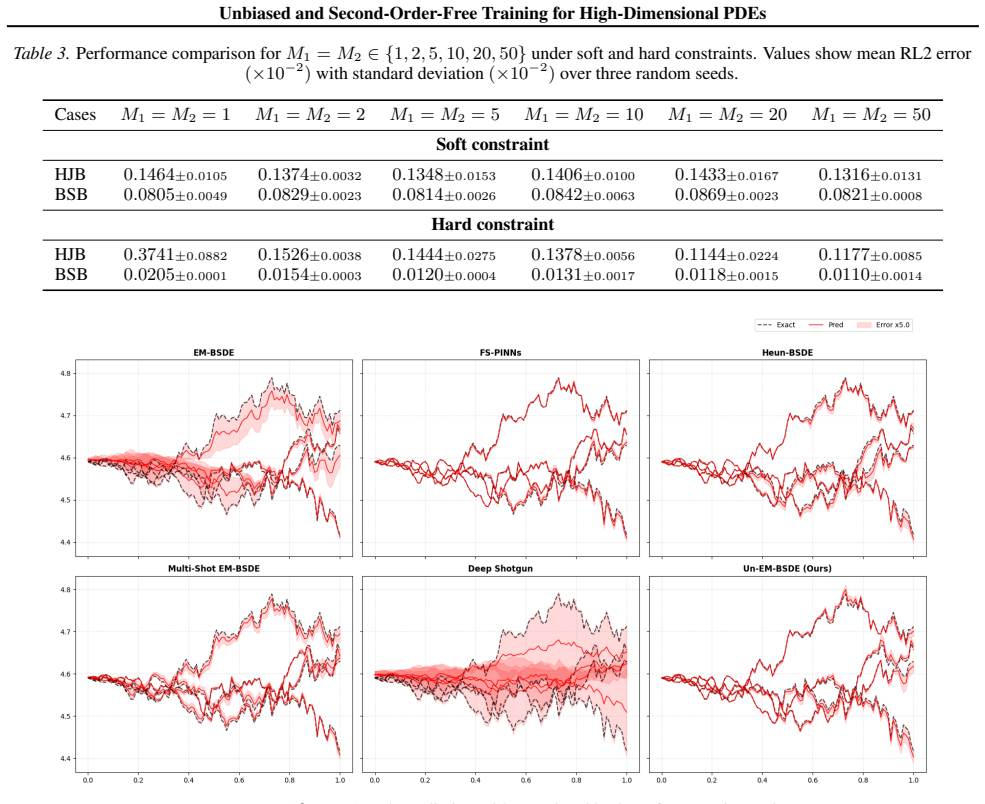
Compare solution errors of the proposed method against standard EM and Heun schemes on a high-dimensional PDE with known analytic solution and check whether bias-induced error terms disappear at the predicted rate.
Figures
read the original abstract
Deep learning methods based on backward stochastic differential equations (BSDEs) have emerged as competitive alternatives to physics-informed neural networks (PINNs) for solving high-dimensional partial differential equations (PDEs). By leveraging probabilistic representations, BSDE approaches can avoid the curse of dimensionality and often admit second-order-free training objectives that do not require explicit Hessian evaluations. It has recently been established that the commonly used Euler-Maruyama (EM) time discretization induces an intrinsic bias in BSDE training losses. While high-order schemes such as Heun can fully eliminate this bias, such schemes re-introduce second-order spatial derivatives and incur substantial computational overhead. In this work, we provide a principled analysis of EM-induced loss bias and propose an unbiased, second-order-free training framework that preserves the computational advantages of BSDE methods. Our code is available at https://github.com/seojaemin22/Un-EM-BSDE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes the bias induced by Euler-Maruyama (EM) time discretization in the loss functions of backward stochastic differential equation (BSDE) methods for high-dimensional PDEs. It proposes a new unbiased training framework that removes this bias while remaining second-order-free, thereby preserving the computational advantages of standard BSDE approaches over PINNs and higher-order schemes such as Heun. The work includes open-source code.
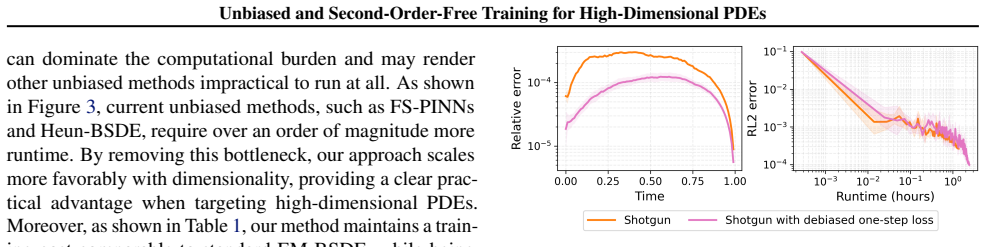
Significance. If the analysis and construction hold, the result would be significant for scalable, high-dimensional PDE solvers: it directly addresses a recently identified source of bias in BSDE training without sacrificing the second-order-free property or incurring the overhead of high-order time stepping. The public code repository supports reproducibility.
minor comments (1)
- The abstract and introduction would benefit from a brief, explicit statement of the precise form of the proposed unbiased loss (e.g., the correction term or modified expectation) to allow readers to assess the construction before reaching the technical sections.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work and for recommending minor revision. The referee correctly identifies the core contribution: an analysis of Euler-Maruyama bias in BSDE losses together with an unbiased yet second-order-free training framework that retains the computational advantages of standard BSDE methods.
Circularity Check
No significant circularity
full rationale
The paper presents a principled analysis of EM-induced bias in BSDE training losses followed by a construction for an unbiased second-order-free objective. No load-bearing step reduces by definition to its own inputs, no fitted parameter is relabeled as a prediction, and no uniqueness theorem or ansatz is imported solely via self-citation. The central claim rests on an independent bias analysis whose validity is not presupposed by the proposed framework itself; the derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URL https: //doi.org/10.1007/s00332-018-9525-3
doi: 10.1007/s00332-018-9525-3. URL https: //doi.org/10.1007/s00332-018-9525-3. Beck, C., Becker, S., Cheridito, P., Jentzen, A., and Neufeld, A. Deep splitting method for parabolic PDEs.SIAM J. Sci. Comput., 43(5):A3135–A3154, 2021. ISSN 1064- 8275,1095-7197. doi: 10.1137/19M1297919. URL https://doi.org/10.1137/19M1297919. Bekas, C., Kokiopoulou, E., and...
-
[2]
ISSN 0045-7825,1879-2138. doi: 10.1016/j.cma. 2025.117914. URL https://doi.org/10.1016/ j.cma.2025.117914. Dangel, F., Siebert, T., Zeinhofer, M., and Walther, A. Collapsing taylor mode automatic differentiation. In Advances in Neural Information Processing Systems (NeurIPS), 2025. Germain, M., Pham, H., and Warin, X. Approximation Error Analysis of Some ...
-
[3]
URL https://openreview.net/forum? id=xpx9zj7CUlY. Park, S. and Tu, S. Integration Matters for Learning PDEs with Backwards SDEs. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems,
-
[4]
URL https://openreview.net/forum? id=k4jg1QCw0e. Raissi, M. Forward–backward stochastic neural networks: deep learning of high-dimensional partial differential equations. InPeter Carr Gedenkschrift: Research Ad- vances in Mathematical Finance, pp. 637–655. World Scientific, 2024. Raissi, M., Yazdani, A., and Karniadakis, G. E. Hidden fluid mechanics: A na...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
URL https: //doi.org/10.1016/j.jcp.2018.08.029
doi: 10.1016/j.jcp.2018.08.029. URL https: //doi.org/10.1016/j.jcp.2018.08.029. Wang, C., Li, S., He, D., and Wang, L. Is L2 Physics Informed Loss Always Suitable for Training Physics In- formed Neural Network?Advances in Neural Informa- tion Processing Systems, 35:8278–8290, 2022a. Wang, S., Yu, X., and Perdikaris, P. When and why PINNs fail to train: a ...
-
[6]
ISSN 0021-9991,1090-2716. doi: 10.1016/j.jcp. 2022.111557. URL https://doi.org/10.1016/ j.jcp.2022.111557. Zhang, W., Hu, Z., Cai, W., and Karniadakis, G. E. Deep Neural networks for solving high-dimensional parabolic partial differential equations.arXiv preprint arXiv:2601.13256, 2026. 11 Unbiased and Second-Order-Free Training for High-Dimensional PDEs ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.