π-Bench: Evaluating Proactive Personal Assistant Agents in Long-Horizon Workflows
Pith reviewed 2026-05-20 21:09 UTC · model grok-4.3
The pith
Current personal assistant agents struggle to provide proactive help in long-term workflows.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that proactive assistance requires agents to identify hidden user intents and leverage inter-task dependencies over long horizons. By building tasks where needs are underspecified at the start and develop across turns and sessions, the benchmark separates the ability to fulfill explicit requests from the ability to act ahead on inferred preferences. Testing current agents on this setup shows that proactive assistance stays challenging, that task completion and proactivity are distinct, and that continuity from past sessions aids intent resolution in later tasks.
What carries the argument
π-Bench, a collection of 100 multi-turn tasks with hidden intents, inter-task dependencies, and cross-session continuity across five personas that jointly measures proactivity and task completion.
Load-bearing premise
The 100 tasks and five personas with their predefined hidden intents and inter-task dependencies accurately capture how real user needs emerge gradually in sustained multi-turn interactions.
What would settle it
A real-user study in which participants engage with agents over multiple sessions and the agents' proactive actions are checked against actual unprompted needs would show whether the benchmark's observed distinctions hold outside the constructed scenarios.
Figures
















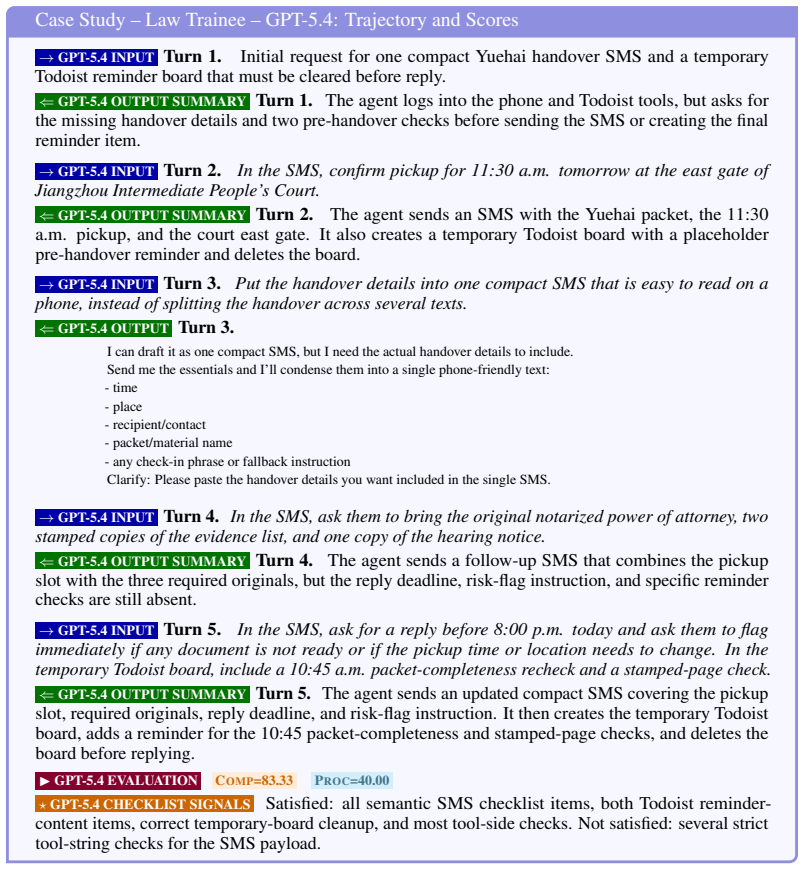




read the original abstract
The rise of personal assistant agents, e.g., OpenClaw, highlights the growing potential of large language models to support users across everyday life and work. A core challenge in these settings is proactive assistance, since users often begin with underspecified requests and leave important needs, constraints, or preferences unstated. However, existing benchmarks rarely evaluate whether agents can identify and act on such hidden intents before they are explicitly stated, especially in sustained multi-turn interactions where user needs emerge gradually. To address this gap, we introduce $\pi$-Bench, a benchmark for proactive assistance comprising 100 multi-turn tasks across 5 domain-specific user personas. By incorporating hidden user intents, inter-task dependencies, and cross-session continuity, $\pi$-Bench evaluates agents' ability to anticipate and address user needs over extended interactions, jointly measuring proactivity and task completion in long-horizon trajectories that better reflect real-world use. Experiments show (1) proactive assistance remains challenging, (2) a clear distinction between task completion and proactivity, and (3) the value of prior interaction for proactive intent resolution in later tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces π-Bench, a benchmark for proactive personal assistant agents consisting of 100 multi-turn tasks across 5 domain-specific user personas. The benchmark incorporates author-defined hidden intents, explicit inter-task dependencies, and cross-session continuity to evaluate agents' ability to anticipate unstated user needs in long-horizon workflows. Reported experiments indicate that proactive assistance remains challenging, that proactivity is distinct from task completion, and that prior interaction improves proactive intent resolution in subsequent tasks.
Significance. If the task construction faithfully reproduces the gradual emergence of real-world user needs rather than introducing artificial signals, the benchmark would provide a valuable tool for measuring and improving proactivity in LLM-based agents, filling a gap left by existing evaluations that focus primarily on explicit or reactive requests. The joint measurement of proactivity and completion over sustained trajectories is a constructive contribution.
major comments (1)
- [Section 3] Section 3 (Benchmark Design and Task Construction): The central experimental claims rest on the 100 tasks and 5 personas with their predefined hidden intents and inter-task dependencies. The manuscript provides no validation (e.g., user studies, comparison to real interaction logs, or ablation on intent emergence) that these author-specified elements capture gradual, open-ended need surfacing in real-world sustained interactions rather than creating exploitable patterns via memory or pattern matching. This directly affects whether the reported distinction between task completion and proactivity, and the benefit of prior interaction, can be interpreted as general properties of proactive agents.
minor comments (1)
- [Abstract and Section 4] The abstract and experimental section would benefit from explicit mention of the number of agents evaluated, the statistical tests applied to support the three findings, and any inter-annotator agreement on intent labeling to strengthen reproducibility.
Simulated Author's Rebuttal
We thank the referee for their insightful comments and recommendation for major revision. We address the primary concern about validation of the benchmark design below and outline planned changes to strengthen the manuscript.
read point-by-point responses
-
Referee: [Section 3] Section 3 (Benchmark Design and Task Construction): The central experimental claims rest on the 100 tasks and 5 personas with their predefined hidden intents and inter-task dependencies. The manuscript provides no validation (e.g., user studies, comparison to real interaction logs, or ablation on intent emergence) that these author-specified elements capture gradual, open-ended need surfacing in real-world sustained interactions rather than creating exploitable patterns via memory or pattern matching. This directly affects whether the reported distinction between task completion and proactivity, and the benefit of prior interaction, can be interpreted as general properties of proactive agents.
Authors: We appreciate the referee highlighting this important aspect of ecological validity. The tasks and personas were constructed iteratively by the authors based on realistic long-horizon workflows drawn from the five domains, with hidden intents and dependencies engineered to emerge gradually through logical connections (e.g., a scheduling task revealing unstated preferences that affect a later travel task). This controlled specification enables precise, reproducible measurement of proactivity separate from completion, which is difficult with raw logs that lack explicit labels for hidden intents. The reported experiments demonstrate consistent distinctions across models and the benefit of prior interaction, suggesting the setup does not reduce to simple pattern matching. We agree that additional grounding would be valuable. In the revised manuscript we will expand Section 3 to include a detailed rationale for task construction, concrete examples of dependency design intended to avoid artificial cues, and a new limitations subsection that explicitly discusses the synthetic nature of the benchmark and calls for future user studies or log-based validation. We will also add a brief ablation on dependency strength if feasible. revision: partial
Circularity Check
No circularity: benchmark construction is explicit and results are empirical
full rationale
The paper defines π-Bench explicitly as a collection of 100 multi-turn tasks across 5 personas that incorporate author-specified hidden intents, inter-task dependencies, and cross-session continuity. The reported experimental findings—that proactive assistance is challenging, distinct from task completion, and aided by prior interaction—are direct measurements of agent behavior on this fixed benchmark rather than any derivation, fitted parameter, or self-referential reduction. No equations, ansatzes, uniqueness theorems, or self-citation chains appear in the provided text, and the outcomes remain contingent on external agent performance instead of being forced by the benchmark definition itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Proactive assistance requires agents to identify and act on hidden user intents before they are explicitly stated, especially in sustained multi-turn interactions.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce π-Bench, a benchmark for proactive assistance comprising 100 multi-turn tasks across 5 domain-specific user personas. By incorporating hidden user intents, inter-task dependencies, and cross-session continuity, π-Bench evaluates agents' ability to anticipate and address user needs over extended interactions, jointly measuring proactivity and task completion
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Proactivity score PROC(H) = |Icom| + |Iinf| / |I|; Completeness COMP(H) averages grader scores over checklists
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Anthropic. Claude code. https://claude.com/product/claude-code, 2026. AI-powered coding assistant for developers, accessed 2026-04-16
work page 2026
-
[2]
Anthropic. Introducing Claude Opus 4.6. https://www.anthropic.com/news/claude-opus-4-6 ,
-
[3]
Accessed: 2026-04-22
work page 2026
-
[4]
Seed2.0 model card: Towards intelligence frontier for real-world complexity
Bytedance Seed. Seed2.0 model card: Towards intelligence frontier for real-world complexity. https://lf3-static.bytednsdoc.com/obj/eden-cn/lapzild-tss/ljhwZthlaukjlkulzlp/ seed2/0214/Seed2.0%20Model%20Card.pdf, 2026. Accessed: 2026-04-22
work page 2026
-
[5]
Yuxiang Chai, Shunye Tang, Han Xiao, Rui Liu, and Hongsheng Li. Pira-bench: A transition from reactive gui agents to gui-based proactive intent recommendation agents.arXiv preprint arXiv:2603.08013, 2026
-
[6]
Maximillian Chen, Ruoxi Sun, Tomas Pfister, and Sercan Ö Arık. Learning to clarify: Multi-turn conversations with action-based contrastive self-training.arXiv preprint arXiv:2406.00222, 2024
-
[7]
KnowU-Bench: Towards Interactive, Proactive, and Personalized Mobile Agent Evaluation
Tongbo Chen, Zhengxi Lu, Zhan Xu, Guocheng Shao, Shaohan Zhao, Fei Tang, Yong Du, Kaitao Song, Yizhou Liu, Yuchen Yan, et al. Knowu-bench: Towards interactive, proactive, and personalized mobile agent evaluation.arXiv preprint arXiv:2604.08455, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
WorkArena: How Capable Are Web Agents at Solving Common Knowledge Work Tasks?
Alexandre Drouin, Maxime Gasse, Massimo Caccia, Issam H Laradji, Manuel Del Verme, Tom Marty, Léo Boisvert, Megh Thakkar, Quentin Cappart, David Vazquez, et al. Workarena: How capable are web agents at solving common knowledge work tasks?arXiv preprint arXiv:2403.07718, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Clawmark: A living-world benchmark for multi-day, multimodal coworker agents
Evolvent AI Research. Clawmark: A living-world benchmark for multi-day, multimodal coworker agents. https://evolvent.co/en/research/clawmark, 2026. Published 2026-04-13, accessed 2026-04-16
work page 2026
-
[10]
Google DeepMind. Gemini 3.1 pro. https://deepmind.google/models/gemini/pro/, 2026. Ac- cessed: 2026-04-22
work page 2026
-
[11]
Zexue He, Yu Wang, Churan Zhi, Yuanzhe Hu, Tzu-Ping Chen, Lang Yin, Ze Chen, Tong Arthur Wu, Siru Ouyang, Zihan Wang, et al. Memoryarena: Benchmarking agent memory in interdependent multi-session agentic tasks.arXiv preprint arXiv:2602.16313, 2026
-
[12]
nanobot: Ultra-lightweight personal ai agent
HKUDS. nanobot: Ultra-lightweight personal ai agent. https://github.com/HKUDS/nanobot, 2026. Open-source personal AI agent, accessed 2026-04-16
work page 2026
-
[13]
ClawArena: Benchmarking AI Agents in Evolving Information Environments
Haonian Ji, Kaiwen Xiong, Siwei Han, Peng Xia, Shi Qiu, Yiyang Zhou, Jiaqi Liu, Jinlong Li, Bingzhou Li, Zeyu Zheng, et al. Clawarena: Benchmarking ai agents in evolving information environments.arXiv preprint arXiv:2604.04202, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
PROPER Agents: Proactivity Driven Personalized Agents for Advancing Knowledge Gap Navigation
Kirandeep Kaur, Vinayak Gupta, Aditya Gupta, and Chirag Shah. The proper approach to proactivity: Benchmarking and advancing knowledge gap navigation.arXiv preprint arXiv:2601.09926, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
Serin Kim, Sangam Lee, and Dongha Lee. Persona2web: Benchmarking personalized web agents for contextual reasoning with user history.arXiv preprint arXiv:2602.17003, 2026
-
[16]
ProactiveMobile: A Comprehensive Benchmark for Boosting Proactive Intelligence on Mobile Devices
Dezhi Kong, Zhengzhao Feng, Qiliang Liang, Hao Wang, Haofei Sun, Changpeng Yang, Yang Li, Peng Zhou, Shuai Nie, Hongzhen Wang, et al. Proactivemobile: A comprehensive benchmark for boosting proactive intelligence on mobile devices.arXiv preprint arXiv:2602.21858, 2026. 10
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
ClawsBench: Evaluating Capability and Safety of LLM Productivity Agents in Simulated Workspaces
Xiangyi Li, Kyoung Whan Choe, Yimin Liu, Xiaokun Chen, Chujun Tao, Bingran You, Wenbo Chen, Zonglin Di, Jiankai Sun, Shenghan Zheng, et al. Clawsbench: Evaluating capability and safety of llm productivity agents in simulated workspaces.arXiv preprint arXiv:2604.05172, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. Deepseek-v3.2: Pushing the frontier of open large language models. arXiv preprint arXiv:2512.02556, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Guangyi Liu, Pengxiang Zhao, Yaozhen Liang, Qinyi Luo, Shunye Tang, Yuxiang Chai, Weifeng Lin, Han Xiao, WenHao Wang, Siheng Chen, et al. Memgui-bench: Benchmarking memory of mobile gui agents in dynamic environments.arXiv preprint arXiv:2602.06075, 2026
-
[20]
Shuochen Liu, Junyi Zhu, Long Shu, Junda Lin, Yuhao Chen, Haotian Zhang, Chao Zhang, Derong Xu, Jia Li, Bo Tang, et al. Perma: Benchmarking personalized memory agents via event-driven preference and realistic task environments.arXiv preprint arXiv:2603.23231, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
AgentBench: Evaluating LLMs as Agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. Agentbench: Evaluating llms as agents.arXiv preprint arXiv:2308.03688, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Yibo Lyu, Gongwei Chen, Rui Shao, Weili Guan, and Liqiang Nie. Personalalign: Hierarchical im- plicit intent alignment for personalized gui agent with long-term user-centric records.arXiv preprint arXiv:2601.09636, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Shiva Krishna Reddy Malay, Shravan Nayak, Jishnu Sethumadhavan Nair, Sagar Davasam, Aman Ti- wari, Sathwik Tejaswi Madhusudhan, Sridhar Krishna Nemala, Srinivas Sunkara, and Sai Rajeswar. Enterpriseops-gym: Environments and evaluations for stateful agentic planning and tool use in enterprise settings.arXiv preprint arXiv:2603.13594, 2026
-
[24]
Gaia: a benchmark for general ai assistants
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. Gaia: a benchmark for general ai assistants. InThe Twelfth International Conference on Learning Representations, 2023
work page 2023
-
[25]
Minimax m2.7: Early echoes of self-evolution
MiniMax. Minimax m2.7: Early echoes of self-evolution. https://www.minimax.io/news/ minimax-m27-en, 2026. Accessed: 2026-04-22
work page 2026
-
[26]
Zairah Mustahsan, Abel Lim, Megna Anand, Saahil Jain, and Bryan McCann. Stochasticity in agentic evaluations: Quantifying inconsistency with intraclass correlation.arXiv preprint arXiv:2512.06710, 2025
-
[27]
Deepak Nathani, Cheng Zhang, Chang Huan, Jiaming Shan, Yinfei Yang, Alkesh Patel, Zhe Gan, William Yang Wang, Michael Saxon, and Xin Eric Wang. Proactive agent research environment: Simulating active users to evaluate proactive assistants.arXiv preprint arXiv:2604.00842, 2026
-
[28]
Pspa-bench: A personalized benchmark for smartphone gui agent.arXiv preprint arXiv:2603.29318, 2026
Hongyi Nie, Xunyuan Liu, Yudong Bai, Yaqing Wang, Yang Liu, Quanming Yao, and Zhen Wang. Pspa-bench: A personalized benchmark for smartphone gui agent.arXiv preprint arXiv:2603.29318, 2026
-
[29]
OpenAI. Introducing GPT-5.4. https://openai.com/index/introducing-gpt-5-4 , 2026. Ac- cessed: 2026-04-22
work page 2026
- [30]
-
[31]
Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E Gonzalez. Gorilla: Large language model connected with massive apis.Advances in Neural Information Processing Systems, 37:126544–126565, 2024
work page 2024
-
[32]
Qwen3.6-Plus: Towards real world agents, April 2026
Qwen Team. Qwen3.6-Plus: Towards real world agents, April 2026. URL https://qwen.ai/blog?id= qwen3.6
work page 2026
-
[33]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems, 36:68539–68551, 2023
work page 2023
-
[34]
Yiting Shen, Kun Li, Wei Zhou, and Songlin Hu. Mem2actbench: A benchmark for evaluating long-term memory utilization in task-oriented autonomous agents.arXiv preprint arXiv:2601.19935, 2026
-
[35]
Jiazheng Sun, Mingxuan Li, Yingying Zhang, Jiayang Niu, Yachen Wu, Ruihan Jin, Shuyu Lei, Pengrongrui Tan, Zongyu Zhang, Ruoyi Wang, et al. Ambibench: Benchmarking mobile gui agents beyond one-shot instructions in the wild.arXiv preprint arXiv:2602.11750, 2026. 11
-
[36]
Kimi K2.5: Visual Agentic Intelligence
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi k2.5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
Appworld: A controllable world of apps and people for benchmarking interactive coding agents
Harsh Trivedi, Tushar Khot, Mareike Hartmann, Ruskin Manku, Vinty Dong, Edward Li, Shashank Gupta, Ashish Sabharwal, and Niranjan Balasubramanian. Appworld: A controllable world of apps and people for benchmarking interactive coding agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), p...
work page 2024
- [38]
-
[39]
Asking What Matters: Reward-Driven Clarification for Software Engineering Tasks
Sanidhya Vijayvargiya, Vijay Viswanathan, and Graham Neubig. Asking what matters: Reward-driven clarification for software engineering tasks.arXiv preprint arXiv:2604.14624, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
SkillX: Automatically Constructing Skill Knowledge Bases for Agents
Chenxi Wang, Zhuoyun Yu, Xin Xie, Wuguannan Yao, Runnan Fang, Shuofei Qiao, Kexin Cao, Guozhou Zheng, Xiang Qi, Peng Zhang, et al. Skillx: Automatically constructing skill knowledge bases for agents. arXiv preprint arXiv:2604.04804, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[41]
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh J Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, et al. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments.Advances in Neural Information Processing Systems, 37: 52040–52094, 2024
work page 2024
-
[42]
PASK: Toward Intent-Aware Proactive Agents with Long-Term Memory
Zhifei Xie, Zongzheng Hu, Fangda Ye, Xin Zhang, Haobo Chai, Zihang Liu, Pengcheng Wu, Guibin Zhang, Yue Liao, Xiaobin Hu, et al. Pask: Toward intent-aware proactive agents with long-term memory. arXiv preprint arXiv:2604.08000, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[43]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2022
work page 2022
-
[44]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. τ-bench: A benchmark for tool-agent- user interaction in real-world domains.arXiv preprint arXiv:2406.12045, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Claw-Eval: Towards Trustworthy Evaluation of Autonomous Agents
Bowen Ye, Rang Li, Qibin Yang, Yuanxin Liu, Linli Yao, Hanglong Lv, Zhihui Xie, Chenxin An, Lei Li, Lingpeng Kong, et al. Claw-eval: Toward trustworthy evaluation of autonomous agents.arXiv preprint arXiv:2604.06132, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[46]
Glm-5.1: Towards long-horizon tasks.https://z.ai/blog/glm-5.1, 2026
Z.ai. Glm-5.1: Towards long-horizon tasks.https://z.ai/blog/glm-5.1, 2026. Accessed: 2026-04- 22
work page 2026
-
[47]
Weizhi Zhang, Xiaokai Wei, Wei-Chieh Huang, Zheng Hui, Chen Wang, Michelle Gong, and Philip S Yu. Memorycd: Benchmarking long-context user memory of llm agents for lifelong cross-domain personalization.arXiv preprint arXiv:2603.25973, 2026
-
[48]
ClawBench: Can AI Agents Complete Everyday Online Tasks?
Yuxuan Zhang, Yubo Wang, Yipeng Zhu, Penghui Du, Junwen Miao, Xuan Lu, Wendong Xu, Yunzhuo Hao, Songcheng Cai, Xiaochen Wang, et al. Clawbench: Can ai agents complete everyday online tasks? arXiv preprint arXiv:2604.08523, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[49]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. Webarena: A realistic web environment for building autonomous agents. arXiv preprint arXiv:2307.13854, 2023. 12 Appendix A Benchmark Statistics 15 A.1 Task and Grader Statistics . . . . . . . . . . . . . . . . . . . . . . ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
Judge from the assistant response and the files-read context above
-
[51]
The assistant must precisely and explicitly hit the hidden intent
Be strict and objective. The assistant must precisely and explicitly hit the hidden intent
-
[52]
Vague or generic answers do not count
A hidden intent is satisfied only if the assistant provides specific, detailed explanations or concrete actions in the response. Vague or generic answers do not count
-
[53]
Fully trust the assistant’s wording and the files-read context, but strictly evaluate the level of detail provided
-
[54]
Do not call tools or check factual accuracy beyond the provided context
-
[55]
YES means the response and context precisely address the hidden intent with specific details
-
[56]
## Output Format Output only XML blocks in the following shape
NO means the response and context do not precisely hit the intent, or lack specific details. ## Output Format Output only XML blocks in the following shape. <c1> <content> {hidden_intent_content} </content> <decision> YES or NO </decision> </c1> In the second stage, the user agent checks whether the latest agent response contains a clarification question....
-
[57]
Judge from the assistant response. Consider all follow-up questions, requests, and action suggestions inside it, not only the last sentence
-
[58]
YES means the assistant explicitly asks about that hidden intent, asks a very close confirmation question about it, or proposes concrete next steps that directly correspond to it
-
[59]
NO means the question is missing, vague, generic, or does not clearly target that hidden intent
-
[60]
Generic prompts such as “anything else?” or “do you want to add more?” must be NO
-
[61]
A question must clearly get the point. Broad topic overlap is not enough. ## Output Format Output only XML blocks in the following shape. <c1> <content> {hidden_intent_content} </content> <decision> YES or NO </decision> </c1> This two-stage procedure induces a priority order among terminal statuses. Direct satisfaction is assigned before targeted elicita...
-
[62]
Use only evidence from the interaction history
-
[63]
Score YES only when the criterion is clearly satisfied
-
[64]
Score NO when evidence is missing, ambiguous, or contradicted
-
[65]
used amazon__place_order successfully
Do not guess. ## Output Format Output only XML blocks in the following shape. Keep each criterion text exactly the same as given. Each score must be YES or NO. <c1> <criterion> {criterion_text} </criterion> <score> YES or NO </score> </c1> C.6 Rule Based Tool Scoring Rule-based tool scoring is used when a checklist item requires exact verification over st...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.