ReMIA: a Powerful and Efficient Alternative to Membership Inference Attacks against Synthetic Data Generators
Pith reviewed 2026-06-30 21:13 UTC · model grok-4.3
The pith
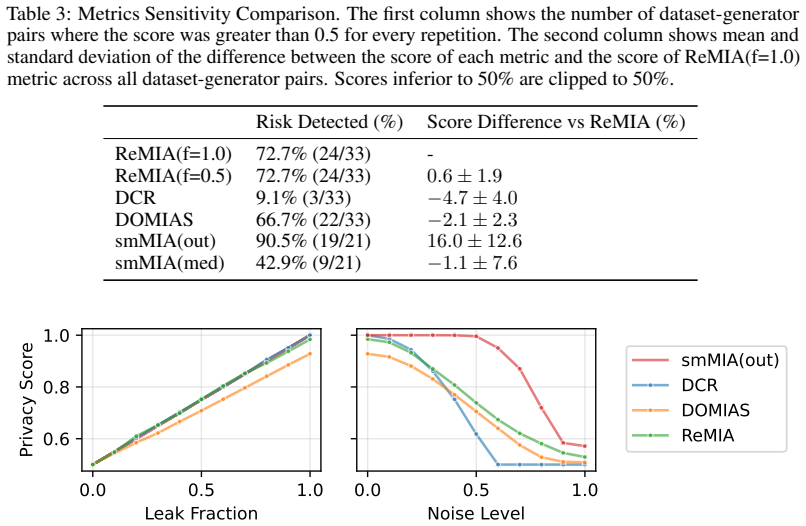
ReMIA assesses membership inference risk for synthetic tabular data by training one classifier on records drawn from two synthetic datasets generated from different source sets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
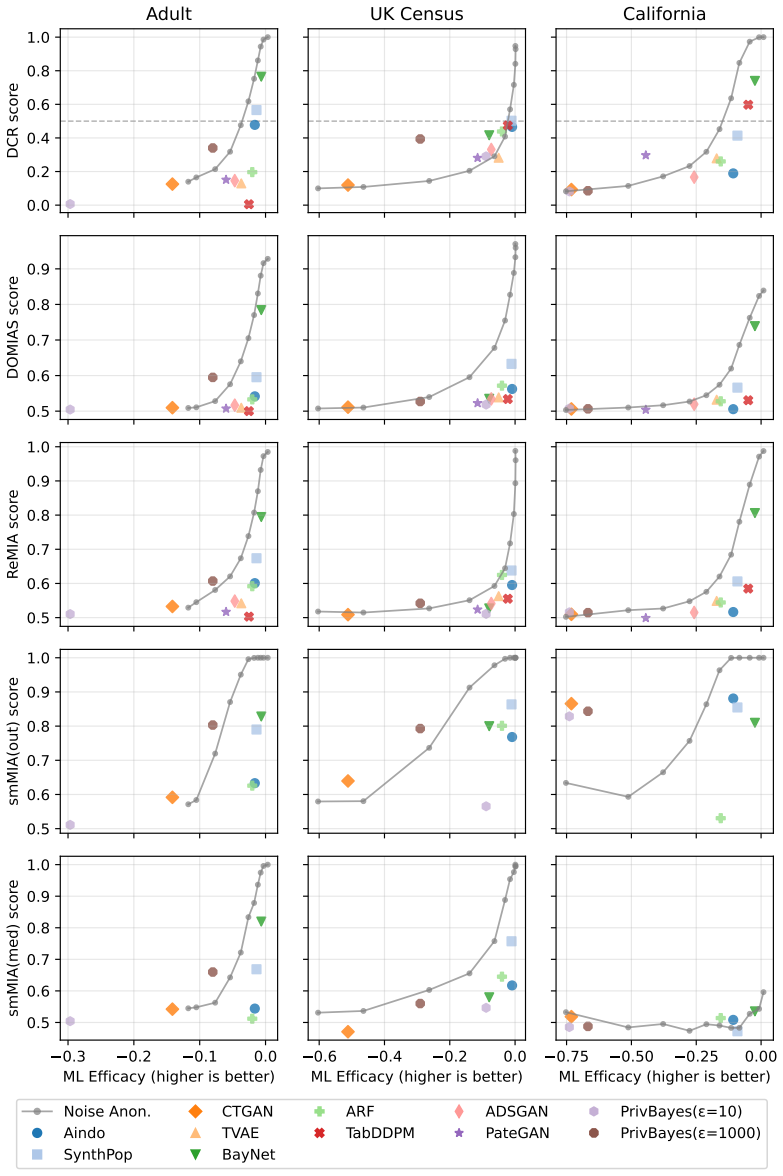
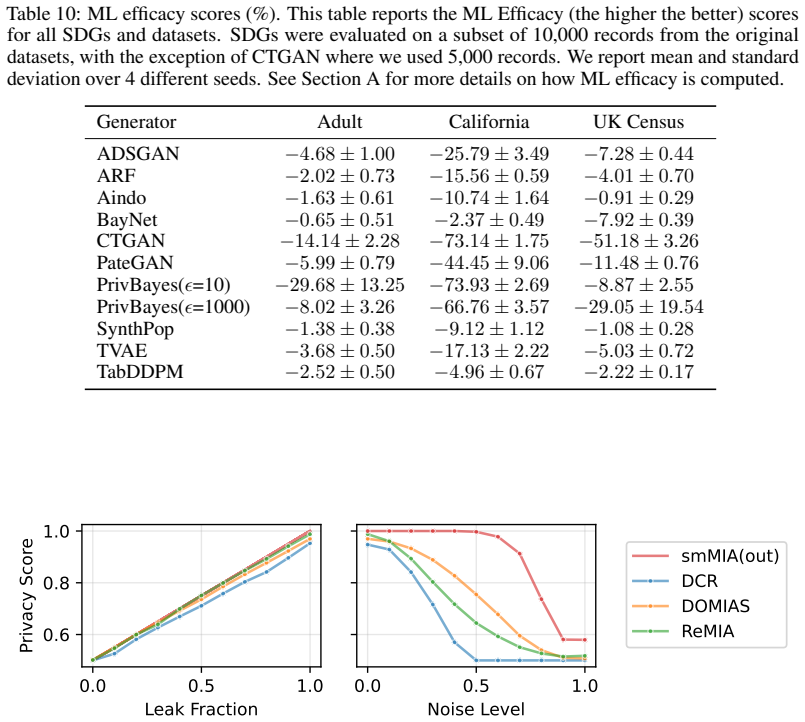
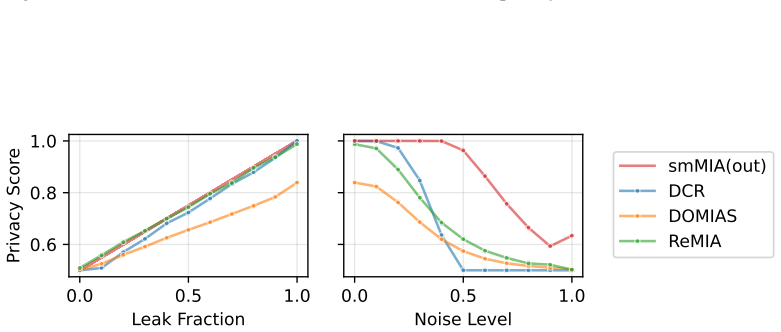
ReMIA generates two synthetic datasets from two source datasets that differ only in the inclusion of the target records, then trains a binary classifier to predict the source of each record; the classifier's accuracy on held-out records serves as a direct measure of membership inference risk for the original training set.
What carries the argument
Relative Membership Inference Attack (ReMIA), which converts membership inference risk into the distinguishability of records between two synthetic datasets generated from shifted source sets.
If this is right
- Privacy audits of synthetic data generators can be completed with two training runs instead of hundreds.
- Auxiliary data requirements drop to the size of the original training set rather than several times larger.
- Synthetic data generators can be compared for privacy risk under realistic resource constraints.
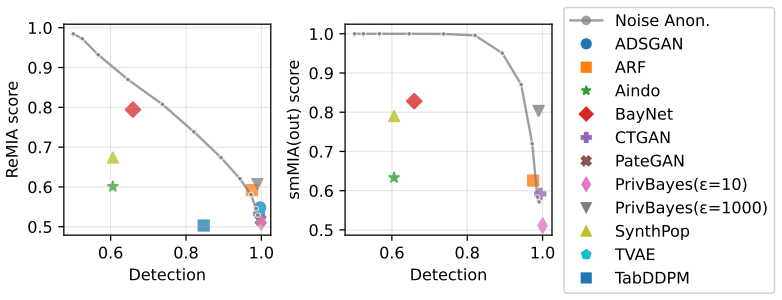
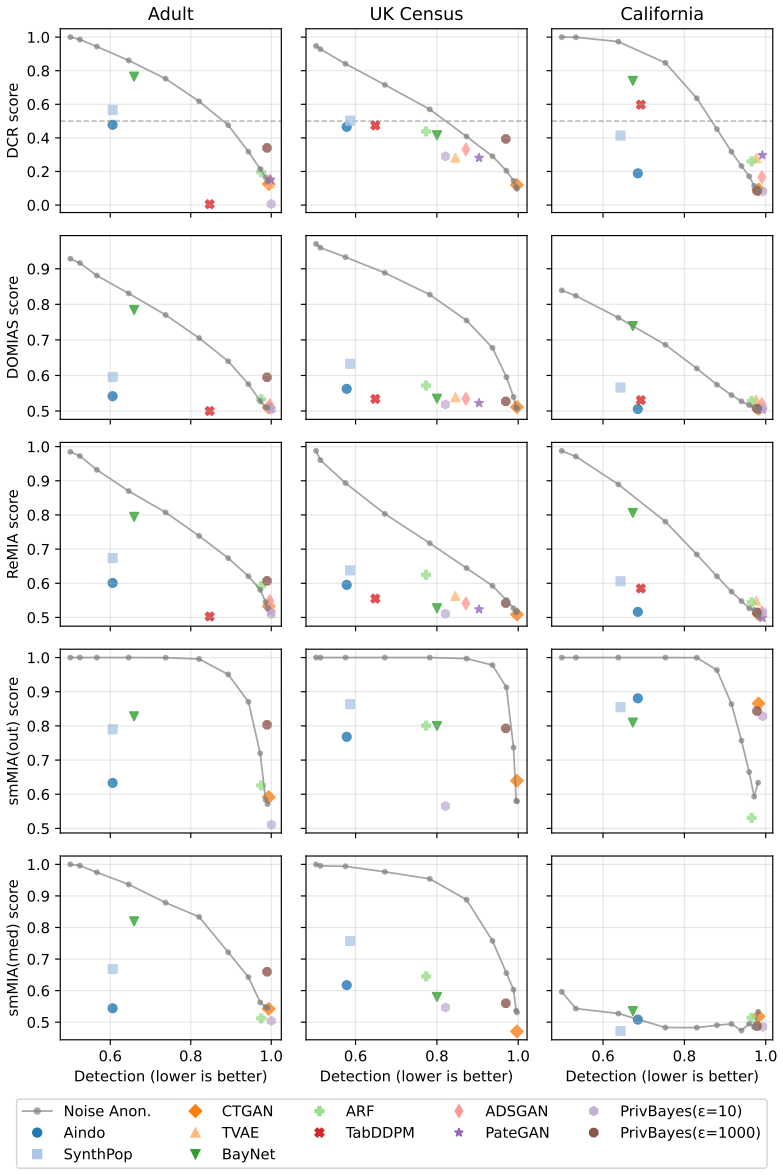
- Some generators reach privacy-utility trade-offs that noise-based anonymization methods do not achieve.
Where Pith is reading between the lines
- ReMIA could serve as a standard lightweight check before releasing synthetic versions of sensitive tabular datasets.
- The two-source comparison idea might be adapted to test other forms of information leakage beyond membership.
- Routine use would let practitioners iterate over generator hyperparameters while monitoring privacy cost in the same budget as utility tests.
Load-bearing premise
The assumption that whether a classifier can tell which of two synthetic datasets a record came from accurately reflects whether that record was present in the original training set.
What would settle it
If ReMIA scores show no consistent correlation with success rates of a standard shadow-model membership inference attack run on the same generators and records, the method would fail to measure the intended risk.
Figures
read the original abstract
Tabular data sharing under privacy constraints is increasingly important for research and collaboration. Synthetic data generators (SDGs) are a promising solution, but synthetic data remains vulnerable to attacks, such as membership inference attacks (MIAs), which aim to determine whether a specific record was part of the training data. State-of-the-art MIAs are powerful but impractical: they rely on shadow modeling, requiring hundreds of SDG training runs, and need auxiliary data several times larger than the original training set. Fast proxy metrics like distance to closest record (DCR) are efficient but have limited sensitivity to MIA risk. We introduce ReMIA (Relative Membership Inference Attack), a practical privacy metric that requires only two SDG training runs and additional data no larger than the original training set. Rather than predicting whether a record was in the training set, ReMIA generates two synthetic datasets from two source datasets and measures whether a classifier can identify which source a record came from. Experiments across multiple tabular datasets and SDGs show that ReMIA has a sensitivity comparable to state-of-the-art MIAs while being substantially more practical. We further observe that SDGs can achieve privacy-utility trade-offs that traditional noise-based anonymization methods do not match. Code is available at https://github.com/aindo-com/remia.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ReMIA, a privacy metric for tabular synthetic data generators (SDGs). It generates two synthetic datasets from two equal-sized source datasets (using the same SDG), then trains a classifier to predict which source a given record originated from. The resulting accuracy or AUC is proposed as a proxy for membership inference attack (MIA) risk on the original training set. The method requires only two SDG trainings and auxiliary data no larger than the training set. Experiments across multiple tabular datasets and SDGs claim sensitivity comparable to state-of-the-art shadow-model MIAs while being far more practical; the paper also reports that SDGs can achieve privacy-utility trade-offs superior to noise-based anonymization. Code is released at the provided GitHub link.
Significance. If the proxy is shown to be valid, ReMIA would substantially lower the barrier to routine privacy evaluation of SDGs by eliminating the need for hundreds of shadow trainings and large auxiliary datasets. The explicit code release supports reproducibility and is a clear strength. The observation on privacy-utility trade-offs, if substantiated, would also be useful for practitioners choosing between SDGs and traditional anonymization.
major comments (3)
- [Method / Experiments] The load-bearing claim is that source-distinguishability between two synthetic datasets faithfully proxies per-record membership leakage from the original training set. No section provides a direct validation (e.g., correlation between ReMIA scores and shadow-model MIA AUC on identical SDGs and records).
- [Experiments] §4 (or equivalent experimental setup): the design uses two distinct source datasets; without an ablation using identical sources (or reporting the classifier's performance on such controls), it is impossible to separate membership leakage from aggregate distributional differences between the sources.
- [Experiments] Table or figure reporting sensitivity comparisons: the paper states 'comparable sensitivity' but does not report the precise MIA baselines, their AUC values, or statistical tests against ReMIA; without these numbers the comparability claim cannot be assessed.
minor comments (2)
- [Method] Notation for the ReMIA classifier and the exact decision threshold or AUC definition should be formalized with an equation.
- [Abstract / Method] The abstract mentions 'additional data no larger than the original training set' but the main text should clarify whether this auxiliary data must be drawn from the same distribution or can be arbitrary.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments highlight important aspects of validation and reporting that we will address in revision. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [Method / Experiments] The load-bearing claim is that source-distinguishability between two synthetic datasets faithfully proxies per-record membership leakage from the original training set. No section provides a direct validation (e.g., correlation between ReMIA scores and shadow-model MIA AUC on identical SDGs and records).
Authors: We agree that an explicit correlation analysis would provide stronger empirical support for ReMIA as a proxy. In the revised manuscript we will add an experiment (or appendix) computing Pearson/Spearman correlations between ReMIA scores and shadow-model MIA AUCs across the same SDGs, datasets, and record sets. This will directly test the proxy relationship. revision: yes
-
Referee: [Experiments] §4 (or equivalent experimental setup): the design uses two distinct source datasets; without an ablation using identical sources (or reporting the classifier's performance on such controls), it is impossible to separate membership leakage from aggregate distributional differences between the sources.
Authors: This is a fair methodological concern. We will add an ablation using identical source datasets (random split of a single dataset into two equal parts) and report the resulting classifier accuracy/AUC. The expectation is performance near chance (0.5) when distributional differences are removed, which will isolate the membership signal. revision: yes
-
Referee: [Experiments] Table or figure reporting sensitivity comparisons: the paper states 'comparable sensitivity' but does not report the precise MIA baselines, their AUC values, or statistical tests against ReMIA; without these numbers the comparability claim cannot be assessed.
Authors: We will expand the relevant tables and figures to report exact AUC values for all shadow-model MIA baselines, ReMIA results, and include statistical tests (e.g., paired Wilcoxon or t-tests with p-values) comparing the two. This will make the comparability claim quantitatively verifiable. revision: yes
Circularity Check
No significant circularity detected in ReMIA definition or claims
full rationale
The paper defines ReMIA directly as the performance of a classifier distinguishing records between two synthetic datasets generated from two equal-sized source datasets. This is an independent operational definition, not derived from or equivalent to any fitted parameter, prior self-citation, or input by construction. Comparability to standard MIAs is asserted via experimental results across datasets, not by mathematical reduction or renaming. No equations, self-citation chains, or ansatzes are present that would force the central result to equal its inputs. The proxy assumption is an empirical claim open to verification, not a circularity issue.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On the fidelity versus privacy and utility trade-off of synthetic patient data.Iscience, 28(5), 2025
Tim Adams, Colin Birkenbihl, Karen Otte, Hwei Geok Ng, Jonas Adrian Rieling, Anatol-Fiete Näher, Ulrich Sax, Fabian Prasser, and Holger Fröhlich. On the fidelity versus privacy and utility trade-off of synthetic patient data.Iscience, 28(5), 2025
2025
-
[2]
Aindo anonymize.https://github.com/aindo-com/aindo-anonymize, 2025
Aindo. Aindo anonymize.https://github.com/aindo-com/aindo-anonymize, 2025
2025
-
[3]
Resprosyn
Alan Turing Institute. Resprosyn. https://github.com/alan-turing-institute/ reprosyn, 2022
2022
-
[4]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization.arXiv preprint arXiv:1607.06450, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[5]
Barry Becker and Ronny Kohavi. Adult. UCI Machine Learning Repository, 1996. DOI: https://doi.org/10.24432/C5XW20
-
[6]
Privacy and synthetic datasets
Steven M Bellovin, Preetam K Dutta, and Nathan Reitinger. Privacy and synthetic datasets. Stan. Tech. L. Rev., 22:1, 2019
2019
-
[7]
The secret sharer: Evaluating and testing unintended memorization in neural networks
Nicholas Carlini, Chang Liu, Úlfar Erlingsson, Jernej Kos, and Dawn Song. The secret sharer: Evaluating and testing unintended memorization in neural networks. In28th USENIX security symposium (USENIX security 19), pages 267–284, 2019
2019
-
[8]
Gan-leaks: A taxonomy of member- ship inference attacks against generative models
Dingfan Chen, Ning Yu, Yang Zhang, and Mario Fritz. Gan-leaks: A taxonomy of member- ship inference attacks against generative models. InProceedings of the 2020 ACM SIGSAC conference on computer and communications security, pages 343–362, 2020
2020
-
[9]
Xgboost: extreme gradient boosting.R package version 0.4-2, 1(4):1–4, 2015
Tianqi Chen, Tong He, Michael Benesty, Vadim Khotilovich, Yuan Tang, Hyunsu Cho, Kailong Chen, Rory Mitchell, Ignacio Cano, Tianyi Zhou, et al. Xgboost: extreme gradient boosting.R package version 0.4-2, 1(4):1–4, 2015
2015
-
[10]
Block neural autoregressive flow
Nicola De Cao, Wilker Aziz, and Ivan Titov. Block neural autoregressive flow. InUncertainty in artificial intelligence, pages 1263–1273. PMLR, 2020
2020
-
[11]
Differential privacy
Cynthia Dwork. Differential privacy. In Michele Bugliesi, Bart Preneel, Vladimiro Sassone, and Ingo Wegener, editors,Automata, Languages and Programming, pages 1–12, Berlin, Heidelberg,
-
[12]
ISBN 978-3-540-35908-1
Springer Berlin Heidelberg. ISBN 978-3-540-35908-1
-
[13]
Sigmoid-weighted linear units for neural network function approximation in reinforcement learning.Neural networks, 107:3–11, 2018
Stefan Elfwing, Eiji Uchibe, and Kenji Doya. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning.Neural networks, 107:3–11, 2018
2018
-
[14]
A unified framework for quantifying privacy risk in synthetic data.Proceedings on Privacy Enhancing Technologies, 2023
Matteo Giomi, Franziska Boenisch, Christoph Wehmeyer, and Borbála Tasnádi. A unified framework for quantifying privacy risk in synthetic data.Proceedings on Privacy Enhancing Technologies, 2023
2023
-
[15]
Generative adversarial networks.Communications of the ACM, 63(11):139–144, 2020
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks.Communications of the ACM, 63(11):139–144, 2020. 10
2020
-
[16]
Synthetic is all you need: removing the auxiliary data assumption for membership inference attacks against synthetic data
Florent Guépin, Matthieu Meeus, Ana-Maria Cre¸ tu, and Yves-Alexandre de Montjoye. Synthetic is all you need: removing the auxiliary data assumption for membership inference attacks against synthetic data. InEuropean Symposium on Research in Computer Security, pages 182–198. Springer, 2023
2023
-
[17]
Logan: Membership inference attacks against generative models.Proceedings on Privacy Enhancing Technologies, 2019
Jamie Hayes, Luca Melis, George Danezis, and Emiliano De Cristofaro. Logan: Membership inference attacks against generative models.Proceedings on Privacy Enhancing Technologies, 2019
2019
-
[18]
Synthetic data generation for tabular health records: A systematic review.Neurocomputing, 493:28–45, 2022
Mikel Hernandez, Gorka Epelde, Ane Alberdi, Rodrigo Cilla, and Debbie Rankin. Synthetic data generation for tabular health records: A systematic review.Neurocomputing, 493:28–45, 2022
2022
-
[19]
Monte carlo and reconstruction membership inference attacks against generative models.Proceedings on Privacy Enhancing Technologies, 2019
Benjamin Hilprecht, Martin Härterich, and Daniel Bernau. Monte carlo and reconstruction membership inference attacks against generative models.Proceedings on Privacy Enhancing Technologies, 2019
2019
-
[20]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[21]
Random decision forests
Tin Kam Ho. Random decision forests. InProceedings of 3rd International Conference on Document Analysis and Recognition, volume 1, pages 278–282. IEEE, 1995
1995
-
[22]
Resolv- ing individuals contributing trace amounts of dna to highly complex mixtures using high-density snp genotyping microarrays.PLoS genetics, 4(8):e1000167, 2008
Nils Homer, Szabolcs Szelinger, Margot Redman, David Duggan, Waibhav Tembe, Jill Muehling, John V Pearson, Dietrich A Stephan, Stanley F Nelson, and David W Craig. Resolv- ing individuals contributing trace amounts of dna to highly complex mixtures using high-density snp genotyping microarrays.PLoS genetics, 4(8):e1000167, 2008
2008
-
[23]
Tapas: a toolbox for adversarial privacy auditing of synthetic data
Florimond Houssiau, James Jordon, Samuel N Cohen, Owen Daniel, Andrew Elliott, James Geddes, Callum Mole, Camila Rangel-Smith, and Lukasz Szpruch. Tapas: a toolbox for adversarial privacy auditing of synthetic data. InNeurIPS 2022 Workshop on Synthetic Data for Empowering ML Research
2022
-
[24]
Membership inference attacks on machine learning: A survey.ACM Computing Surveys (CSUR), 54(11s):1–37, 2022
Hongsheng Hu, Zoran Salcic, Lichao Sun, Gillian Dobbie, Philip S Yu, and Xuyun Zhang. Membership inference attacks on machine learning: A survey.ACM Computing Surveys (CSUR), 54(11s):1–37, 2022
2022
-
[25]
Pate-gan: Generating synthetic data with differential privacy guarantees.Generative Modelling for Supervised, Unsupervised and Private Learning, page 116
James Jordon, Jinsung Yoon, and Mihaela van der Schaar. Pate-gan: Generating synthetic data with differential privacy guarantees.Generative Modelling for Supervised, Unsupervised and Private Learning, page 116
-
[26]
Synthetic data–what, why and how? arXiv preprint arXiv:2205.03257, 2022
James Jordon, Lukasz Szpruch, Florimond Houssiau, Mirko Bottarelli, Giovanni Cherubin, Carsten Maple, Samuel N Cohen, and Adrian Weller. Synthetic data–what, why and how? arXiv preprint arXiv:2205.03257, 2022
-
[27]
Kingma and Max Welling
Diederik P. Kingma and Max Welling. Auto-Encoding Variational Bayes. In2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, April 14-16, 2014, Conference Track Proceedings, 2014
2014
-
[28]
Tabddpm: Mod- elling tabular data with diffusion models
Akim Kotelnikov, Dmitry Baranchuk, Ivan Rubachev, and Artem Babenko. Tabddpm: Mod- elling tabular data with diffusion models. InInternational conference on machine learning, pages 17564–17579. PMLR, 2023
2023
-
[29]
Differentially private normal- izing flows for synthetic tabular data generation
Jaewoo Lee, Minjung Kim, Yonghyun Jeong, and Youngmin Ro. Differentially private normal- izing flows for synthetic tabular data generation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 7345–7353, 2022
2022
-
[30]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
Achilles’ heels: vulnerable record identification in synthetic data publishing
Matthieu Meeus, Florent Guepin, Ana-Maria Cre¸ tu, and Yves-Alexandre de Montjoye. Achilles’ heels: vulnerable record identification in synthetic data publishing. InEuropean Symposium on Research in Computer Security, pages 380–399. Springer, 2023. URL https://github.com/ imperial-aisp/MIA-synthetic. 11
2023
-
[32]
synthpop: Bespoke creation of synthetic data in r.Journal of statistical software, 74:1–26, 2016
Beata Nowok, Gillian M Raab, and Chris Dibben. synthpop: Bespoke creation of synthetic data in r.Journal of statistical software, 74:1–26, 2016
2016
-
[33]
Census microdata teaching files, 2011
Office for National Statistics. Census microdata teaching files, 2011. URL https: //www.ons.gov.uk/census/2011census/2011censusdata/censusmicrodata/ microdatateachingfile
2011
-
[34]
Sparse spatial autoregressions.Statistics & Probability Letters, 33(3):291–297, 1997
R Kelley Pace and Ronald Barry. Sparse spatial autoregressions.Statistics & Probability Letters, 33(3):291–297, 1997. URL https://scikit-learn.org/stable/modules/generated/ sklearn.datasets.fetch_california_housing.html
1997
-
[35]
Empirical Evaluation of Structured Synthetic Data Privacy Metrics: Novel experimental framework
Milton Nicolás Plasencia Palacios, Alexander Boudewijn, Sebastiano Saccani, Andrea Filippo Ferraris, Diana Sofronieva, Giuseppe D’Acquisto, Filiberto Brozzetti, Daniele Panfilo, and Luca Bortolussi. Empirical evaluation of structured synthetic data privacy metrics: Novel experimental framework.arXiv preprint arXiv:2512.16284, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Data synthesis based on generative adversarial networks.Proceedings of the VLDB Endowment, 11(10):1071–1083, 2018
Noseong Park, Mahmoud Mohammadi, Kshitij Gorde, Sushil Jajodia, Hongkyu Park, and Youngmin Kim. Data synthesis based on generative adversarial networks.Proceedings of the VLDB Endowment, 11(10):1071–1083, 2018
2018
-
[37]
The synthetic data vault
Neha Patki, Roy Wedge, and Kalyan Veeramachaneni. The synthetic data vault. In2016 IEEE international conference on data science and advanced analytics (DSAA), pages 399–410. IEEE, 2016
2016
-
[38]
Holdout-based empirical assessment of mixed-type synthetic data.Frontiers in big Data, 4:679939, 2021
Michael Platzer and Thomas Reutterer. Holdout-based empirical assessment of mixed-type synthetic data.Frontiers in big Data, 4:679939, 2021
2021
-
[39]
Synthcity: facilitating innovative use cases of synthetic data in different data modalities, 2023
Zhaozhi Qian, Bogdan-Constantin Cebere, and Mihaela van der Schaar. Synthcity: facilitating innovative use cases of synthetic data in different data modalities, 2023. URL https://arxiv. org/abs/2301.07573
-
[40]
Ahmed Salem, Yang Zhang, Mathias Humbert, Pascal Berrang, Mario Fritz, and Michael Backes. Ml-leaks: Model and data independent membership inference attacks and defenses on machine learning models.arXiv preprint arXiv:1806.01246, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[41]
Membership inference attacks against machine learning models
Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. Membership inference attacks against machine learning models. In2017 IEEE symposium on security and privacy (SP), pages 3–18. IEEE, 2017
2017
-
[42]
General and specific utility measures for synthetic data.Journal of the Royal Statistical Society Series A: Statistics in Society, 181(3):663–688, 2018
Joshua Snoke, Gillian M Raab, Beata Nowok, Chris Dibben, and Aleksandra Slavkovic. General and specific utility measures for synthetic data.Journal of the Royal Statistical Society Series A: Statistics in Society, 181(3):663–688, 2018
2018
-
[43]
Synthetic data–anonymisation groundhog day
Theresa Stadler, Bristena Oprisanu, and Carmela Troncoso. Synthetic data–anonymisation groundhog day. In31st USENIX Security Symposium (USENIX Security 22), pages 1451–1468, 2022
2022
-
[44]
Membership inference attacks against synthetic data through overfitting detection
Boris van Breugel, Hao Sun, Zhaozhi Qian, and Mihaela van der Schaar. Membership inference attacks against synthetic data through overfitting detection. InInternational Conference on Artificial Intelligence and Statistics, pages 3493–3514. PMLR, 2023. URL https://github. com/holarissun/DOMIAS
2023
-
[45]
Adversarial random forests for density estimation and generative modeling
David S Watson, Kristin Blesch, Jan Kapar, and Marvin N Wright. Adversarial random forests for density estimation and generative modeling. InInternational Conference on Artificial Intelligence and Statistics, pages 5357–5375. PMLR, 2023
2023
-
[46]
Modeling tabular data using conditional gan.Advances in neural information processing systems, 32, 2019
Lei Xu, Maria Skoularidou, Alfredo Cuesta-Infante, and Kalyan Veeramachaneni. Modeling tabular data using conditional gan.Advances in neural information processing systems, 32, 2019
2019
-
[47]
The dcr delusion: measuring the privacy risk of synthetic data
Zexi Yao, Nataša Krˇco, Georgi Ganev, and Yves-Alexandre de Montjoye. The dcr delusion: measuring the privacy risk of synthetic data. InEuropean Symposium on Research in Computer Security, pages 469–487. Springer, 2025. 12
2025
-
[48]
Anonymization through data synthesis using generative adversarial networks (ads-gan).IEEE journal of biomedical and health informatics, 24(8):2378–2388, 2020
Jinsung Yoon, Lydia N Drumright, and Mihaela Van Der Schaar. Anonymization through data synthesis using generative adversarial networks (ads-gan).IEEE journal of biomedical and health informatics, 24(8):2378–2388, 2020
2020
-
[49]
Mixed-type tabular data synthesis with score-based diffusion in latent space
Hengrui Zhang, Jiani Zhang, Zhengyuan Shen, Balasubramaniam Srinivasan, Xiao Qin, Christos Faloutsos, Huzefa Rangwala, and George Karypis. Mixed-type tabular data synthesis with score-based diffusion in latent space. InInternational Conference on Learning Representations, volume 2024, pages 52829–52857, 2024
2024
-
[50]
generated
Jun Zhang, Graham Cormode, Cecilia M Procopiuc, Divesh Srivastava, and Xiaokui Xiao. Privbayes: Private data release via bayesian networks.ACM Transactions on Database Systems (TODS), 42(4):1–41, 2017. 13 A Methods and Experimental Setup Details A.1 ReMIA Details ReMIA trains a tabular discriminator to distinguish between synthetic data from two different...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.