SR-Platform: An Agentic Pipeline for Natural Language-Driven Robot Simulation Environment Synthesis
Pith reviewed 2026-06-30 20:56 UTC · model grok-4.3
The pith
SR-Platform converts natural language prompts into executable MuJoCo robot scenes via a four-stage agentic pipeline.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SR-Platform is a production-deployed agentic system that converts free-form natural language descriptions into executable, physically valid MuJoCo environments by decomposing scene synthesis into an LLM-based orchestrator, an asset forge that retrieves cached assets or generates new geometry through LLM-to-CadQuery synthesis, a layout architect that assigns poses and verifies constraints, and a bridge layer that assembles the final MJCF scene and merges the robot model.
What carries the argument
The four-stage agentic pipeline (LLM orchestrator, asset forge with LLM-to-CadQuery, layout architect, and MJCF bridge layer) that handles intent parsing, geometry creation or retrieval, spatial arrangement, and final scene assembly.
If this is right
- Users without 3D modeling skills can create diverse robot training environments from plain English prompts.
- Cache-accelerated scenes finish in 30-40 seconds median latency.
- The asset forge recovers automatically on the 11.3 percent of first attempts that fail.
- Cached asset retrieval eliminates repeated LLM calls for previously generated object types.
Where Pith is reading between the lines
- The reported latencies and retry rates suggest the system could support iterative scene design loops inside a single training session.
- If the physical-validity assumption holds at scale, the platform could be chained directly to reinforcement-learning loops that request new environments on demand.
- Extending the layout architect to handle articulated objects or dynamic constraints would be a direct next step implied by the current separation of forge and architect stages.
Load-bearing premise
The LLM-driven asset forge and layout architect produce scenes that are physically valid, collision-free, and directly executable in MuJoCo without post-generation human correction.
What would settle it
A measured failure rate above 20 percent when loading and simulating the generated five-object scenes in MuJoCo for standard robot tasks such as grasping or navigation.
Figures





read the original abstract
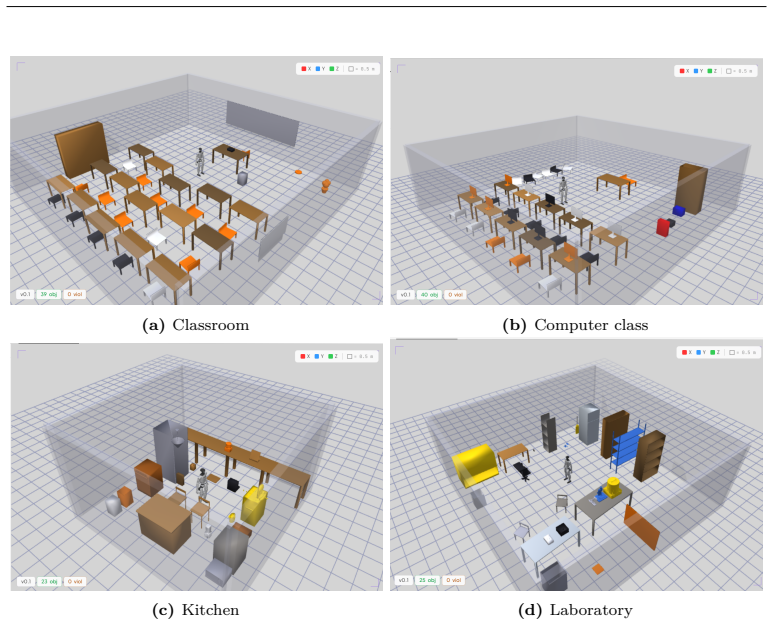
Generating robot simulation environments remains a major bottleneck in simulation-based robot learning. Constructing a training-ready MuJoCo scene typically requires expertise in 3D asset modeling, MJCF specification, spatial layout, collision avoidance, and robot-model integration. We present SR-Platform, a production-deployed agentic system that converts free-form natural language descriptions into executable, physically valid MuJoCo environments. SR-Platform decomposes scene synthesis into four stages: an LLM-based orchestrator that converts user intent into a structured scene plan; an asset forge that retrieves cached assets or generates new 3D geometry through LLM-to-CadQuery synthesis; a layout architect that assigns object poses and verifies industrial constraints; and a bridge layer that assembles the final MJCF scene and merges the selected robot model. The system is deployed as a nine-service Docker stack with WebSocket progress streaming, MinIO-backed mesh storage, Qdrant-based semantic asset retrieval, Redis job state, and InfluxDB telemetry. Using 30 days of production telemetry covering 611 successful LLM calls, SR-Platform generates five-object scenes with a median end-to-end latency of approximately 50 s, while cache-accelerated scenes complete in approximately 30-40 s. The asset forge shows an 11.3% first-attempt retry rate with automatic recovery, and cached asset retrieval removes per-object LLM calls for previously generated object types. These results show that agentic scene synthesis can reduce the manual effort required to create diverse robot training environments, enabling users to produce executable MuJoCo scenes from plain English prompts in under one minute.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents SR-Platform, a production-deployed agentic pipeline that converts free-form natural language descriptions into executable MuJoCo simulation environments via four stages: an LLM orchestrator for scene planning, an asset forge using LLM-to-CadQuery synthesis with caching, a layout architect for pose assignment and constraint verification, and a bridge layer for MJCF assembly and robot integration. The system is implemented as a nine-service Docker stack with supporting infrastructure for storage, retrieval, and telemetry. Production data from 30 days covering 611 successful LLM calls reports median end-to-end latency of ~50 s (30-40 s for cached scenes) and an 11.3% first-attempt retry rate for asset generation with automatic recovery.
Significance. If the pipeline reliably produces physically valid and collision-free scenes, the work would meaningfully lower the barrier to creating diverse robot training environments, shifting scene synthesis from manual expertise to natural language interaction. The reported deployment metrics demonstrate practical latency and recovery behavior in a real production setting, which is a concrete strength.
major comments (1)
- [Abstract] Abstract: the central claim that SR-Platform yields 'executable, physically valid MuJoCo environments' rests on an unverified assumption. The only quantitative results are latency and asset-forge retry rates from 611 calls; no metrics are supplied on MuJoCo XML executability, interpenetration rates, collision-avoidance success, joint-limit violations, or the fraction of scenes requiring post-generation human edits before use in robot training.
minor comments (1)
- [Abstract] Abstract: the phrase 'verifies industrial constraints' is used without definition or examples of the specific constraints enforced by the layout architect.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and evaluation scope. We respond to the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that SR-Platform yields 'executable, physically valid MuJoCo environments' rests on an unverified assumption. The only quantitative results are latency and asset-forge retry rates from 611 calls; no metrics are supplied on MuJoCo XML executability, interpenetration rates, collision-avoidance success, joint-limit violations, or the fraction of scenes requiring post-generation human edits before use in robot training.
Authors: We agree that the reported results center on deployment metrics (latency and retry rates) rather than direct quantitative validation of physical properties. The manuscript describes architectural mechanisms intended to promote validity—the layout architect performs explicit constraint verification and pose assignment with collision considerations, while the bridge layer handles MJCF assembly—but these are design features, not measured outcomes. No interpenetration rates, executability failure fractions, or post-generation edit statistics are provided. We will revise the abstract to qualify the claim (e.g., replacing the unqualified 'physically valid' phrasing with language tied to the verified components) and add a limitations paragraph noting the absence of these metrics and the value of future targeted evaluation. revision: yes
Circularity Check
No circularity; empirical telemetry reports observed performance without derivations or self-referential predictions
full rationale
The paper describes a deployed agentic pipeline and reports direct production telemetry (611 LLM calls, ~50s median latency, 11.3% asset retry rate) as observed measurements. No equations, fitted parameters, predictions derived from inputs, or load-bearing self-citations appear in the provided text. The central claims rest on external deployment data rather than any reduction to the paper's own definitions or prior author work. This is a standard non-circular systems report.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM outputs can be reliably converted into valid CadQuery geometry and constraint-satisfying layouts that produce executable MuJoCo scenes.
Reference graph
Works this paper leans on
-
[1]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, et al. Language models are few-shot learners. Advances in Neural Information Processing Systems, 33:1877–1901,
1901
-
[2]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
PaLM-E: An Embodied Multimodal Language Model
Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. Palm-e: An embodied multimodal language model.arXiv preprint arXiv:2303.03378,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Eureka: Human-Level Reward Design via Coding Large Language Models
Yecheng Jason Ma, William Liang, Guanzhi Wang, et al. Eureka: Human-level reward design via coding large language models.arXiv preprint arXiv:2310.12931,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
DreamFusion: Text-to-3D using 2D Diffusion
Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. DreamFusion: Text-to-3d using 2d diffusion.arXiv preprint arXiv:2209.14988,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, et al. Voyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291, 2023a. Yufei Wang, Zhou Jiang, Feng Chen, et al. RoboGen: Towards unleashing infinite data for automated robot learning via generative simulation.arXiv preprint arXiv:2311.01455, 2023b. Shunyu Yao, Jeffrey Zhao, Di...
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.