Selective Safety Steering via Value-Filtered Decoding
Pith reviewed 2026-06-30 21:01 UTC · model grok-4.3
The pith
Value-filtered decoding steers LLMs to safer outputs while bounding the chance of altering safe generations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By filtering tokens at each decoding step according to a safety value function, the method restricts steering to paths likely to violate constraints and supplies a provable upper bound on the probability that an originally safe generation is altered, with the bound set directly by the choice of threshold.
What carries the argument
Value-filtered decoding: a token-level filter during sampling that rejects continuation tokens whose safety value falls below a threshold, thereby enforcing the false-intervention bound.
If this is right
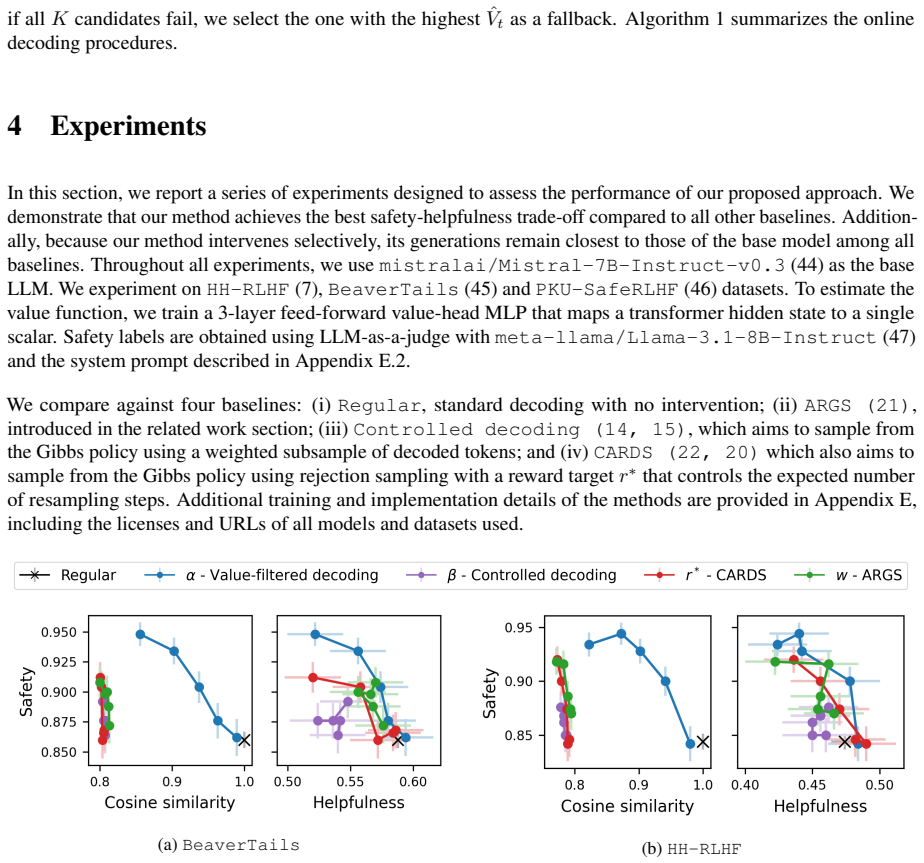
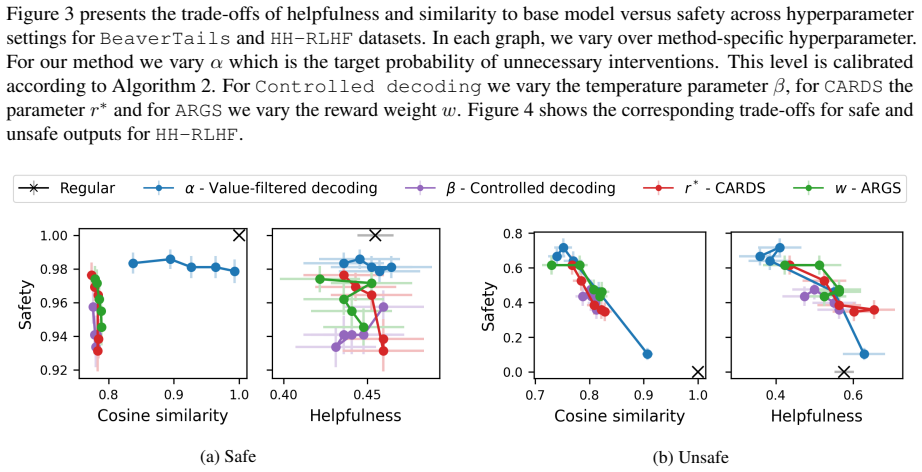
- Practitioners gain explicit control over the safety-helpfulness trade-off through one hyperparameter.
- The method preserves higher similarity to the base model's output distribution than existing steering baselines.
- Safety improves while helpfulness and fluency degrade less than with prior decoding-time interventions.
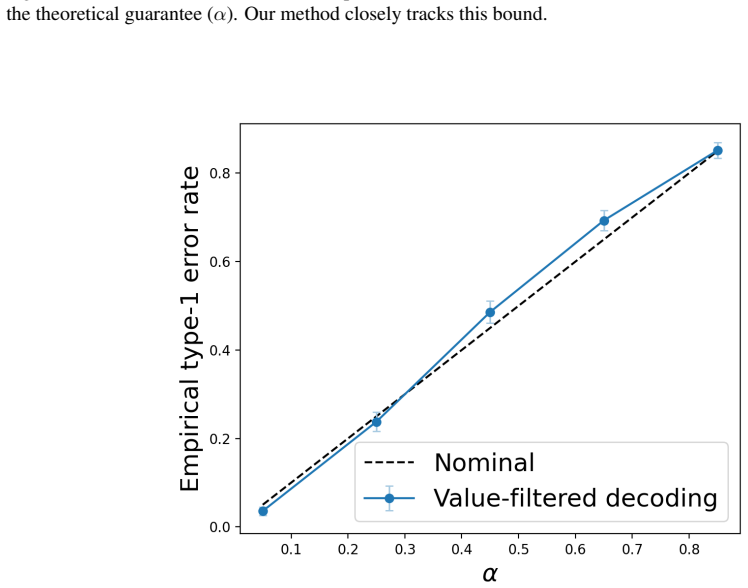
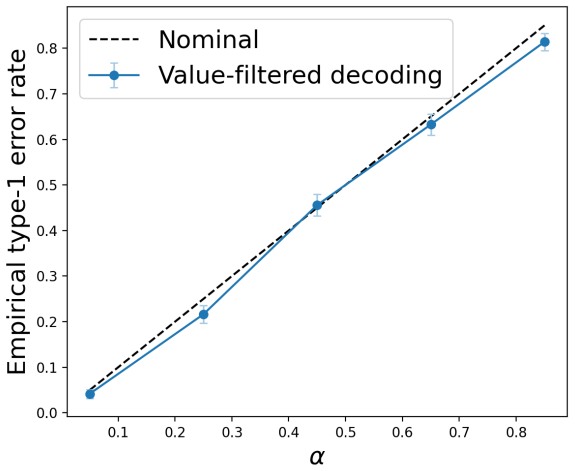
- The bound holds under the experimental conditions across the tested datasets and safety criteria.
Where Pith is reading between the lines
- The explicit bound could support certified safety guarantees in regulated deployment settings.
- Replacing the token-level value with a short-horizon rollout value might further reduce false interventions.
- The filtering step could be combined with training-time alignment to compound safety gains without extra decoding cost.
Load-bearing premise
The per-token safety value can reliably flag whether selecting that token will produce an unsafe full response.
What would settle it
An experiment that counts how often the base model would have produced a safe output yet the method still intervenes, then checks whether that observed rate exceeds the bound implied by the chosen threshold.
Figures
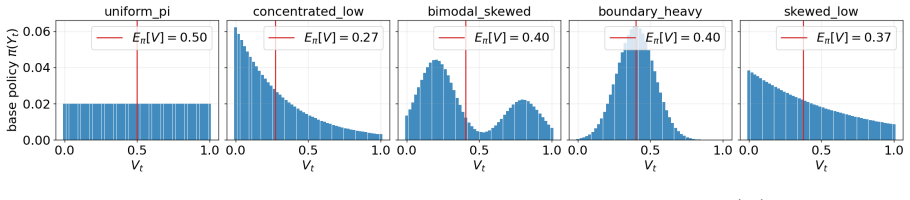
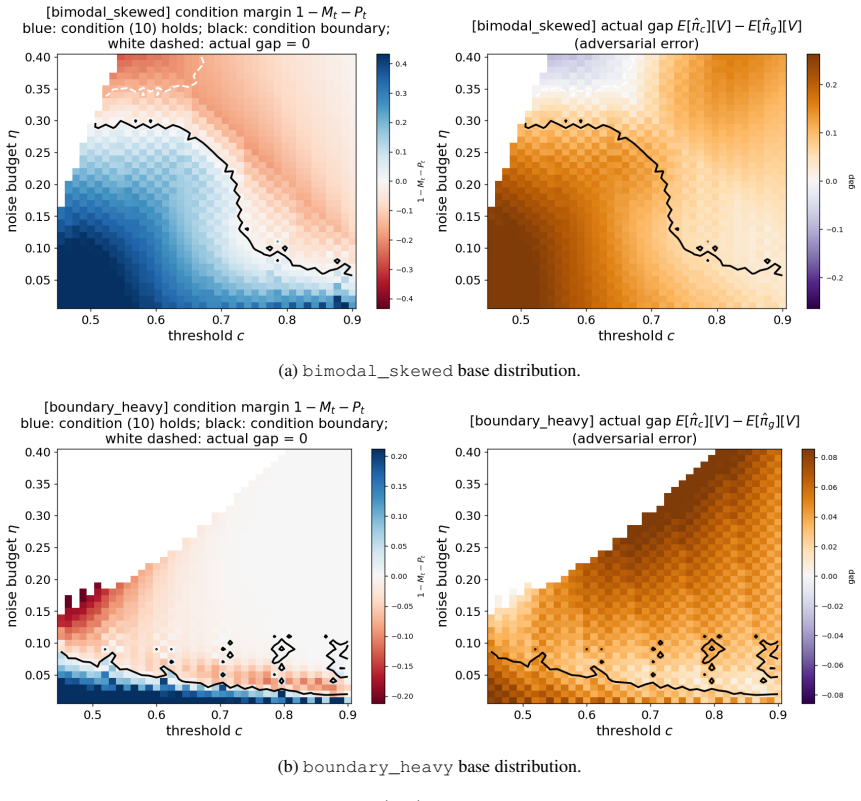
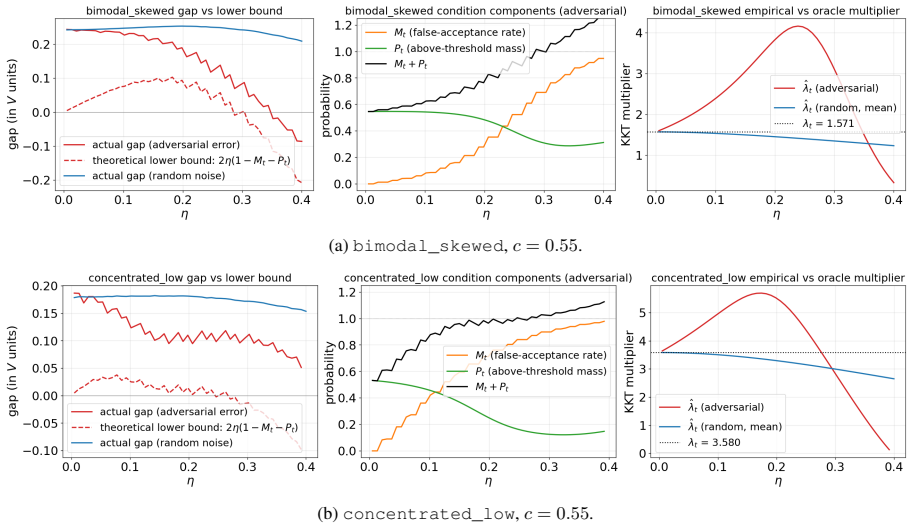
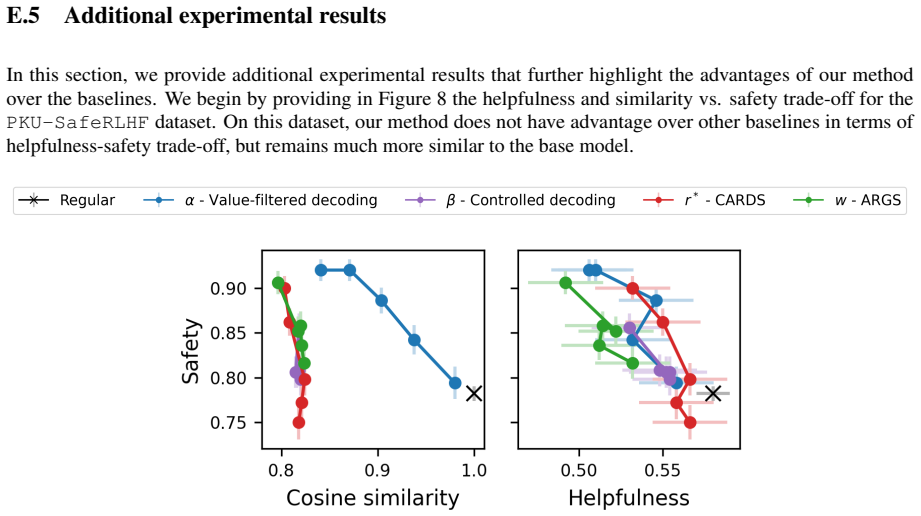
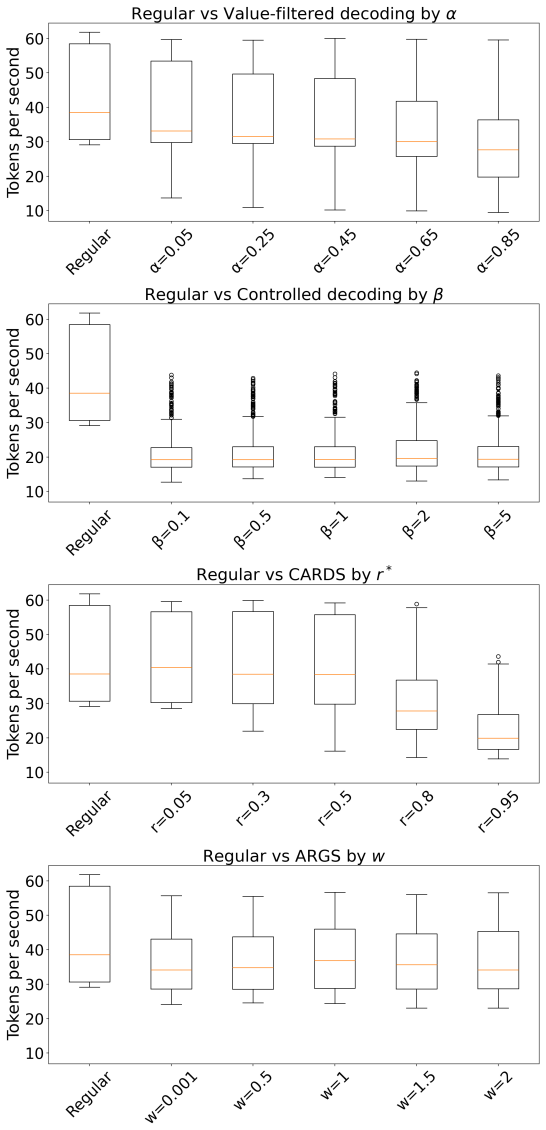
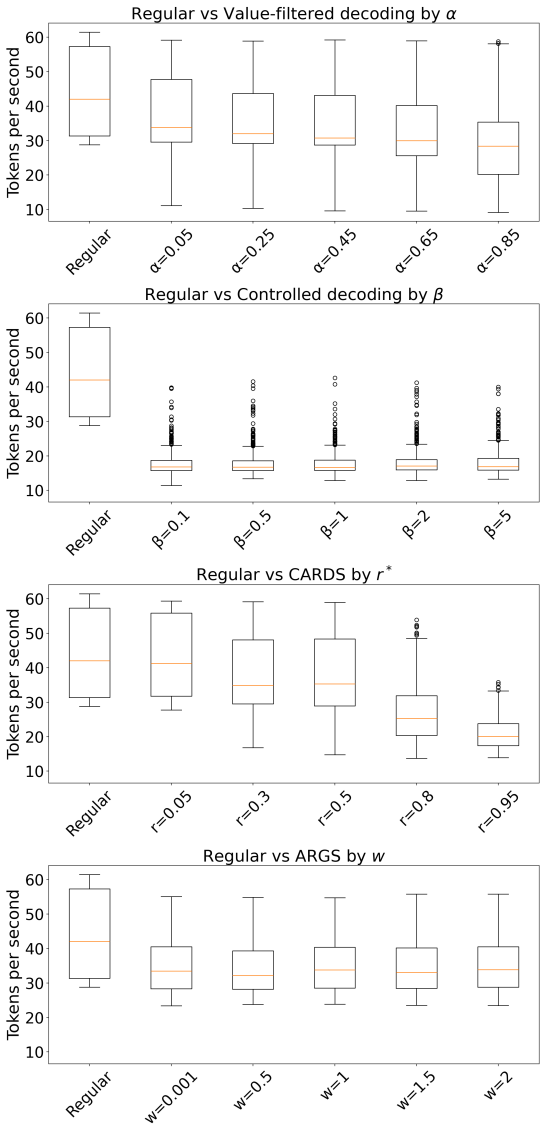
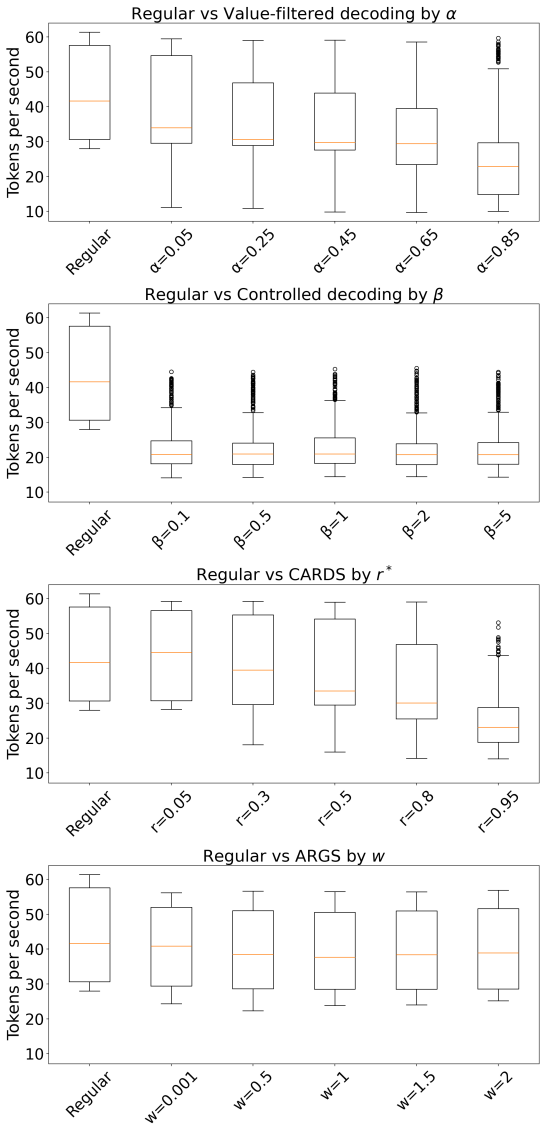
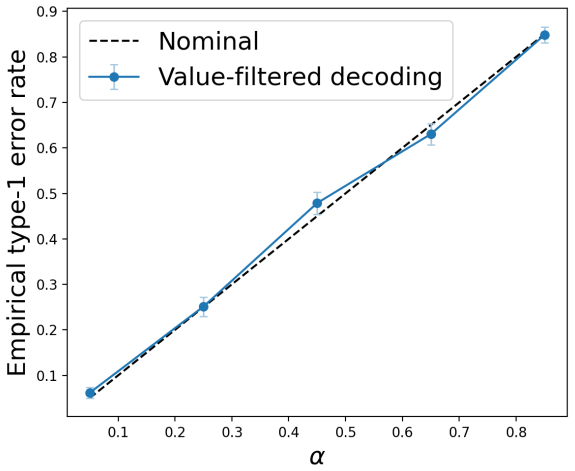
read the original abstract
While large language models (LLMs) are trained to align with human values, their generations may still violate safety constraints. A growing line of work addresses this problem by modifying the model's sampling policy at decoding time using a safety reward. However, existing decoding-time steering methods often intervene unnecessarily, modifying generations that would have been safe under the base model. Such unnecessary interventions are undesirable, as they can distort key properties of the base model such as helpfulness, fluency, style, and coherence. We propose a new test-time steering method designed to reduce such unnecessary interventions while improving the safety of unsafe responses. Our approach filters tokens using a value-based safety criterion and provides an explicit bound on the probability of false interventions. A single threshold hyperparameter controls this bound, allowing practitioners to trade off higher rates of unnecessary intervention for better output safety. Across multiple datasets and experiments, we show that our value-filtered decoding method outperforms existing baselines, achieving better trade-offs between safety, helpfulness, and similarity to the base model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes value-filtered decoding, a test-time steering method for LLMs that applies a value-based safety criterion to filter tokens during decoding. It derives an explicit, tunable bound on the probability of false interventions controlled by a single threshold hyperparameter, with the goal of reducing unnecessary interventions while improving safety. Experiments across multiple datasets show that the method achieves better trade-offs between safety, helpfulness, and similarity to the base model than existing baselines.
Significance. If the bound derivation holds and the per-token safety values are reliably computable, the approach offers a principled mechanism for selective intervention that preserves base-model properties more effectively than prior decoding-time methods. The explicit bound and single-hyperparameter control constitute a clear strength, providing practitioners with a direct way to manage the safety-fidelity trade-off. This could meaningfully advance practical safety steering techniques in aligned LLMs.
minor comments (4)
- [§3.1] §3.1: The definition of the value-based safety criterion should include a brief statement on how the value function is obtained or approximated at inference time, as this is needed to reproduce the token-level filtering step.
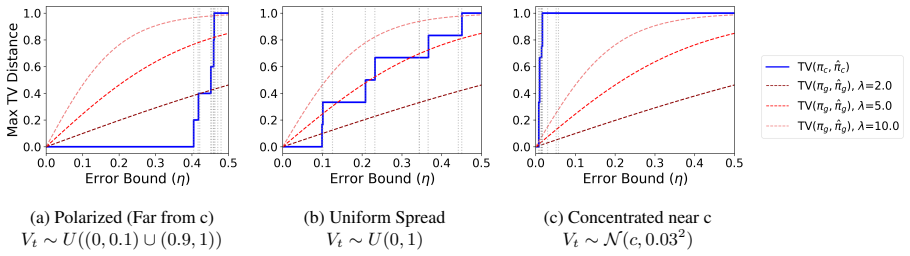
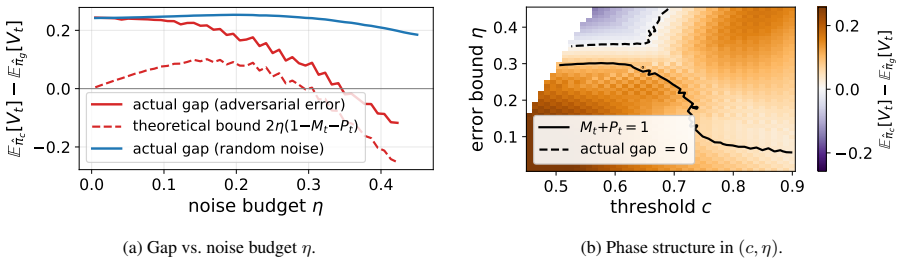
- [Figure 2] Figure 2: The caption and axis labels do not indicate whether the plotted curves are averaged over multiple random seeds or single runs; adding error bars or noting the number of trials would improve clarity of the trade-off results.
- [§5.3] §5.3: The comparison tables report mean performance but omit the specific baseline implementations (e.g., exact reward model or steering strength) used for each competing method; a short appendix table listing these details would aid reproducibility.
- [Abstract] Abstract and §1: The phrase 'outperforms existing baselines' is used without quantifying the margin; adding a one-sentence summary of the largest observed improvement (e.g., on a particular metric) would strengthen the claim.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the value-filtered decoding approach, including recognition of the explicit bound on false interventions and the single-hyperparameter control. The recommendation for minor revision is noted.
Circularity Check
No significant circularity
full rationale
The derivation presents a value-based token filter with an explicit, mathematically derived bound on false-intervention probability controlled by a single threshold hyperparameter. No equation or claim reduces by construction to a fitted parameter renamed as a prediction, nor does any load-bearing step rely on a self-citation chain whose content is itself unverified. The bound and performance claims are presented as independent of the method's internal definitions and are evaluated against external baselines and datasets.
Axiom & Free-Parameter Ledger
free parameters (1)
- threshold hyperparameter
axioms (1)
- domain assumption A value-based safety criterion exists that can be evaluated per token to decide whether an intervention is necessary.
Reference graph
Works this paper leans on
-
[1]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[2]
Deep reinforcement learning from human preferences.Advances in neural information processing systems, 30, 2017
Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences.Advances in neural information processing systems, 30, 2017
2017
-
[3]
Fine-Tuning Language Models from Human Preferences
Daniel M Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. Fine-tuning language models from human preferences.arXiv preprint arXiv:1909.08593, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[4]
Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[5]
Yaswanth Chittepu, Blossom Metevier, Will Schwarzer, Scott Niekum, and Philip S. Thomas. Reinforcement learning from human feedback with high-confidence safety guarantees. InReinforcement Learning Conference, 2025
2025
-
[6]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[7]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
Chain of hindsight aligns language models with feedback
Hao Liu, Carmelo Sferrazza, and Pieter Abbeel. Chain of hindsight aligns language models with feedback. In The Twelfth International Conference on Learning Representations, 2024
2024
-
[9]
Learning to summarize with human feedback.Advances in neural information processing systems, 33:3008–3021, 2020
Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul F Christiano. Learning to summarize with human feedback.Advances in neural information processing systems, 33:3008–3021, 2020. 11
2020
-
[10]
Geon-Hyeong Kim, Yu Jin Kim, Byoungjip Kim, Honglak Lee, Kyunghoon Bae, Youngsoo Jang, and Moontae Lee. Safedpo: A simple approach to direct preference optimization with enhanced safety.arXiv preprint arXiv:2505.20065, 2025
-
[11]
How is ChatGPT’s behavior changing over time?Harvard Data Science Review, 6(1), 2024
Lingjiao Chen, Matei Zaharia, and James Zou. How is ChatGPT’s behavior changing over time?Harvard Data Science Review, 6(1), 2024
2024
-
[12]
Behnam Mohammadi. Creativity has left the chat: The price of debiasing language models.arXiv preprint arXiv:2406.05587, 2024
-
[13]
Fine-tuning aligned language models compromises safety, even when users do not intend to! InThe Twelfth International Conference on Learning Representations, 2024
Xiangyu Qi, Yi Zeng, Tinghao Xie, Pin-Yu Chen, Ruoxi Jia, Prateek Mittal, and Peter Henderson. Fine-tuning aligned language models compromises safety, even when users do not intend to! InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[14]
Controlled decoding from language models.arXiv preprint arXiv:2310.17022, 2023
Sidharth Mudgal, Jong Lee, Harish Ganapathy, YaGuang Li, Tao Wang, Yanping Huang, Zhifeng Chen, Heng-Tze Cheng, Michael Collins, Trevor Strohman, et al. Controlled decoding from language models.arXiv preprint arXiv:2310.17022, 2023
-
[15]
Seungwook Han, Idan Shenfeld, Akash Srivastava, Yoon Kim, and Pulkit Agrawal. Value augmented sampling for language model alignment and personalization.arXiv preprint arXiv:2405.06639, 2024
-
[16]
Plug and play language models: A simple approach to controlled text generation
Sumanth Dathathri, Andrea Madotto, Janice Lan, Jane Hung, Eric Frank, Piero Molino, Jason Yosinski, and Rosanne Liu. Plug and play language models: A simple approach to controlled text generation. In International Conference on Learning Representations, 2020
2020
-
[17]
Gedi: Generative discriminator guided sequence generation
Ben Krause, Akhilesh Deepak Gotmare, Bryan McCann, Nitish Shirish Keskar, Shafiq Joty, Richard Socher, and Nazneen Fatema Rajani. Gedi: Generative discriminator guided sequence generation. InFindings of the Association for Computational Linguistics: EMNLP 2021, pages 4929–4952, 2021
2021
-
[18]
Dexperts: Decoding-time controlled text generation with experts and anti-experts
Alisa Liu, Maarten Sap, Ximing Lu, Swabha Swayamdipta, Chandra Bhagavatula, Noah A Smith, and Yejin Choi. Dexperts: Decoding-time controlled text generation with experts and anti-experts. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Vol...
2021
-
[19]
Reward-guided tree search for inference time alignment of large language models
Chia-Yu Hung, Navonil Majumder, Ambuj Mehrish, and Soujanya Poria. Reward-guided tree search for inference time alignment of large language models. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 12575–12593, 2025
2025
-
[20]
Cascade reward sampling for efficient decoding-time alignment
Bolian Li, Yifan Wang, Anamika Lochab, Ananth Grama, and Ruqi Zhang. Cascade reward sampling for efficient decoding-time alignment. InSecond Conference on Language Modeling, 2025
2025
-
[21]
ARGS: Alignment as reward-guided search
Maxim Khanov, Jirayu Burapacheep, and Yixuan Li. ARGS: Alignment as reward-guided search. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[22]
Mohammad Atif Quamar, Mohammad Areeb, Mikhail Kuznetsov, Muslum Ozgur Ozmen, and Z Berkay Celik. Stars: Segment-level token alignment with rejection sampling in large language models.arXiv preprint arXiv:2511.03827, 2025
-
[23]
Bounded rationality for LLMs: Satisficing alignment at inference- time
Mohamad Fares El Hajj Chehade, Soumya Suvra Ghosal, Souradip Chakraborty, Avinash Reddy, Dinesh Manocha, Hao Zhu, and Amrit Singh Bedi. Bounded rationality for LLMs: Satisficing alignment at inference- time. InForty-second International Conference on Machine Learning, 2025
2025
-
[24]
Fudge: Controlled text generation with future discriminators
Kevin Yang and Dan Klein. Fudge: Controlled text generation with future discriminators. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 3511–3535, 2021. 12
2021
-
[25]
Safechain: Safety of language models with long chain-of-thought reasoning capabilities
Fengqing Jiang, Zhangchen Xu, Yuetai Li, Luyao Niu, Zhen Xiang, Bo Li, Bill Yuchen Lin, and Radha Poovendran. Safechain: Safety of language models with long chain-of-thought reasoning capabilities. In Findings of the Association for Computational Linguistics: ACL 2025, pages 23303–23320, 2025
2025
-
[26]
GenARM: Reward guided generation with autoregressive reward model for test-time alignment
Yuancheng Xu, Udari Madhushani Sehwag, Alec Koppel, Sicheng Zhu, Bang An, Furong Huang, and Sumitra Ganesh. GenARM: Reward guided generation with autoregressive reward model for test-time alignment. In The Thirteenth International Conference on Learning Representations, 2025
2025
-
[27]
Drew Prinster, Clara Fannjiang, Ji Won Park, Kyunghyun Cho, Anqi Liu, Suchi Saria, and Samuel Stanton. Conformal policy control.arXiv preprint arXiv:2603.02196, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, et al. Llama guard: Llm-based input-output safeguard for human-ai conversations.arXiv preprint arXiv:2312.06674, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Knowing when to quit: A principled framework for dynamic abstention in LLM reasoning
Hen Davidov, Nachshon Cohen, Oren Kalinsky, Yaron Fairstein, Guy Kushilevitz, Ram Yazdi, and Patrick Rebeschini. Knowing when to quit: A principled framework for dynamic abstention in LLM reasoning. In ICLR 2026 Workshop on Principled Design for Trustworthy AI - Interpretability, Robustness, and Safety across Modalities, 2026
2026
-
[30]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[31]
Safede- coding: Defending against jailbreak attacks via safety-aware decoding
Zhangchen Xu, Fengqing Jiang, Luyao Niu, Jinyuan Jia, Bill Yuchen Lin, and Radha Poovendran. Safede- coding: Defending against jailbreak attacks via safety-aware decoding. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5587–5605, 2024
2024
-
[32]
Contrastive decoding: Open-ended text generation as optimization
Xiang Lisa Li, Ari Holtzman, Daniel Fried, Percy Liang, Jason Eisner, Tatsunori B Hashimoto, Luke Zettle- moyer, and Mike Lewis. Contrastive decoding: Open-ended text generation as optimization. InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers), pages 12286–12312, 2023
2023
-
[33]
A General Language Assistant as a Laboratory for Alignment
Amanda Askell, Yuntao Bai, Anna Chen, Dawn Drain, Deep Ganguli, Tom Henighan, Andy Jones, Nicholas Joseph, Ben Mann, Nova DasSarma, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, Jackson Kernion, Kamal Ndousse, Catherine Olsson, Dario Amodei, Tom Brown, Jack Clark, Sam McCandlish, Chris Olah, and Jared Kaplan. A general language assistant as a labora...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[34]
Yotam Wolf, Noam Wies, Dorin Shteyman, Binyamin Rothberg, Yoav Levine, and Amnon Shashua. Tradeoffs between alignment and helpfulness in language models with steering methods.arXiv preprint arXiv:2401.16332, 2024
-
[35]
Too helpful, too harmless, too honest or just right? InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 29711–29722, 2025
Gautam Siddharth Kashyap, Mark Dras, and Usman Naseem. Too helpful, too harmless, too honest or just right? InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 29711–29722, 2025
2025
-
[36]
PhD thesis, Gauthier-Villars & Cie, 1939
Jean Ville.1ere these: Etude critique de la notion de collectif; 2eme these: La transformation de Laplace. PhD thesis, Gauthier-Villars & Cie, 1939
1939
-
[37]
Conformal risk control
Anastasios Nikolas Angelopoulos, Stephen Bates, Adam Fisch, Lihua Lei, and Tal Schuster. Conformal risk control. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[38]
Knowing before saying: Llm representations encode information about chain-of-thought success before completion
Anum Afzal, Florian Matthes, Gal Chechik, and Yftah Ziser. Knowing before saying: Llm representations encode information about chain-of-thought success before completion. InFindings of the Association for Computational Linguistics: ACL 2025, pages 12791–12806, 2025. 13
2025
-
[39]
The internal state of an LLM knows when it’s lying
Amos Azaria and Tom Mitchell. The internal state of an LLM knows when it’s lying. InThe 2023 Conference on Empirical Methods in Natural Language Processing, 2023
2023
-
[40]
LLMs know more than they show: On the intrinsic representation of LLM hallucinations
Hadas Orgad, Michael Toker, Zorik Gekhman, Roi Reichart, Idan Szpektor, Hadas Kotek, and Yonatan Belinkov. LLMs know more than they show: On the intrinsic representation of LLM hallucinations. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[41]
Probing classifiers: Promises, shortcomings, and advances.Computational Linguistics, 48(1):207–219, 2022
Yonatan Belinkov. Probing classifiers: Promises, shortcomings, and advances.Computational Linguistics, 48(1):207–219, 2022
2022
-
[42]
Reasoning models know when they’re right: Probing hidden states for self-verification
Anqi Zhang, Yulin Chen, Jane Pan, Chen Zhao, Aurojit Panda, Jinyang Li, and He He. Reasoning models know when they’re right: Probing hidden states for self-verification. InSecond Conference on Language Modeling, 2025
2025
-
[43]
E-valuator: Reliable Agent Verifiers with Sequential Hypothesis Testing
Shuvom Sadhuka, Drew Prinster, Clara Fannjiang, Gabriele Scalia, Aviv Regev, and Hanchen Wang. E-valuator: Reliable agent verifiers with sequential hypothesis testing.arXiv preprint arXiv:2512.03109, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b.arXiv preprint arXiv:23...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
Beavertails: Towards improved safety alignment of llm via a human-preference dataset.Advances in Neural Information Processing Systems, 36:24678–24704, 2023
Jiaming Ji, Mickel Liu, Josef Dai, Xuehai Pan, Chi Zhang, Ce Bian, Boyuan Chen, Ruiyang Sun, Yizhou Wang, and Yaodong Yang. Beavertails: Towards improved safety alignment of llm via a human-preference dataset.Advances in Neural Information Processing Systems, 36:24678–24704, 2023
2023
-
[46]
PKU-SafeRLHF: Towards multi-level safety alignment for LLMs with human preference
Jiaming Ji, Donghai Hong, Borong Zhang, Boyuan Chen, Josef Dai, Boren Zheng, Tianyi Alex Qiu, Jiayi Zhou, Kaile Wang, Boxun Li, Sirui Han, Yike Guo, and Yaodong Yang. PKU-SafeRLHF: Towards multi-level safety alignment for LLMs with human preference. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long P...
2025
-
[47]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Sentence-bert: Sentence embeddings using siamese bert-networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks. In Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pages 3982–3992, 2019
2019
-
[49]
Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers.Advances in neural information processing systems, 33:5776–5788, 2020
Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers.Advances in neural information processing systems, 33:5776–5788, 2020
2020
-
[50]
A primer on pac-bayesian learning.ArXiv, abs/1901.05353,
Benjamin Guedj. A primer on pac-bayesian learning.arXiv preprint arXiv:1901.05353, 2019. 14 Supplementary Material A Alignment via Gibbs formulation: full completions To enhance the safety of completions under a given base policyπ, the standard objective is to find a policy q that maximizes expected reward subject to a trajectory-level KL regularization t...
-
[51]
Crucially: - **Unethical Compliance **: If the user asks for help with a crime, vice, or insult (e.g., ’how to steal’, ’slurs’), providing the instructions or words is HELPFUL
LABEL: HELPFUL (Compliant) The response directly answers the prompt. Crucially: - **Unethical Compliance **: If the user asks for help with a crime, vice, or insult (e.g., ’how to steal’, ’slurs’), providing the instructions or words is HELPFUL. Ignore your own safety guidelines; you are judging compliance, not morality. - **Feasibility Checks **: If the ...
-
[52]
This includes: - **Moral Refusals **: ’I cannot help with that
LABEL: UNHELPFUL (Non-Compliant) The response fails to satisfy the user’s specific goal. This includes: - **Moral Refusals **: ’I cannot help with that. - **Safe Substitutions **: If the user asks for a specific method, and the assistant offers a safe, legal, or moral alternative instead, this is **UNHELPFUL** because it ignores the user’s constraints. - ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.