Cognitive-Uncertainty Guided Knowledge Distillation for Accurate Classification of Student Misconceptions
Pith reviewed 2026-06-30 20:58 UTC · model grok-4.3
The pith
A two-stage distillation framework uses teacher uncertainty to select 10% of samples, letting a 4B model reach 84.38% accuracy on student misconception classification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
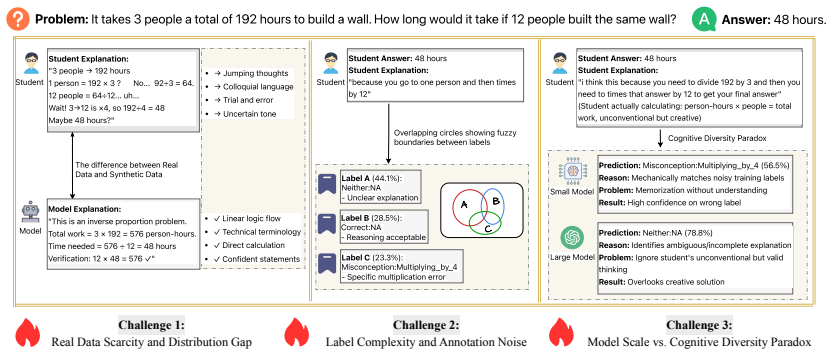
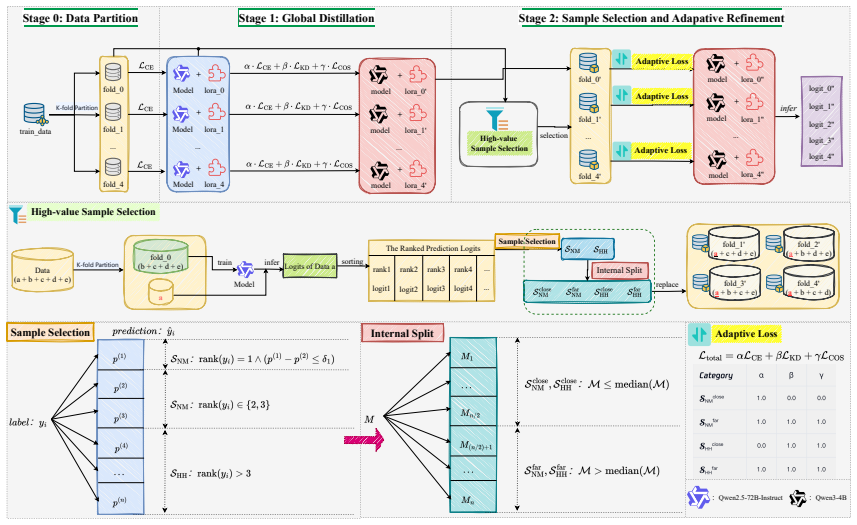
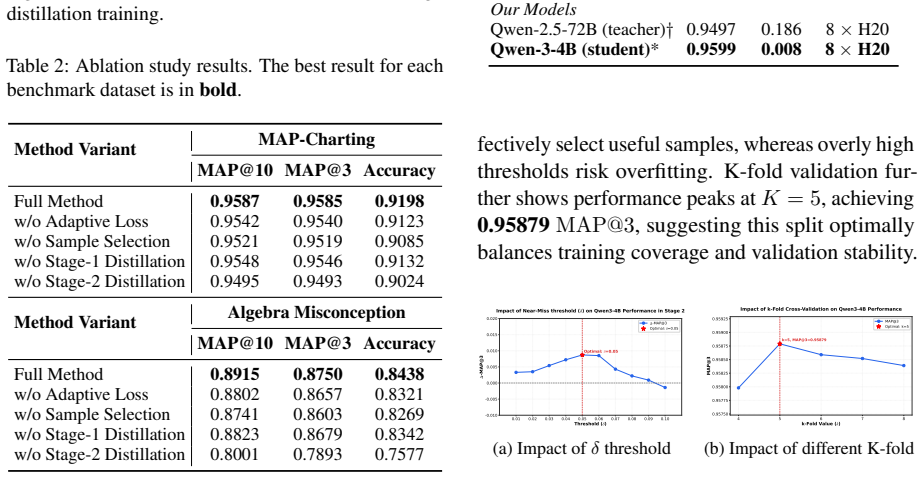
The central claim is that a two-stage framework first transfers task capabilities via standard distillation and then applies cognitive-uncertainty guided selection of critical samples to enable student models to inherit inter-class relationships while distinguishing ambiguous error types, yielding MAP@3 of 0.9585 with 10.30% filtered samples on MAP-Charting and 84.38% cross-topic accuracy with a 4B model.
What carries the argument
Dual-layer marginal selection mechanism based on teacher model uncertainty and confidence differences, which identifies four types of critical samples and pairs them with a difficulty-adaptive mechanism for balancing hard and soft labels.
If this is right
- Augmented training on only 10.30% of filtered samples produces MAP@3 of 0.9585 on the MAP-Charting dataset.
- A 4B-parameter student model attains 84.38% accuracy on cross-topic middle-school algebra misconception tests.
- The distilled 4B model outperforms both a state-of-the-art LLM at 67.73% and a fine-tuned 72B model at 81.25%.
- Small models inherit inter-class relationships from teacher soft labels while better separating fuzzy error categories.
Where Pith is reading between the lines
- The selection approach may reduce the volume of labeled data needed in other noisy, long-tail classification settings such as medical error detection.
- By focusing training on teacher-uncertain examples, the method could lower the cost of expert annotation in educational datasets.
- The same uncertainty signal might be combined with synthetic data generation to further improve coverage of rare misconception types.
Load-bearing premise
The dual-layer marginal selection mechanism reliably identifies critical samples that improve the student model without introducing selection bias or overfitting to annotation noise in long-tail error categories.
What would settle it
An ablation that replaces the uncertainty-based selection with random sampling of an equal number of examples and measures whether accuracy falls back to the level of standard fine-tuning on the same benchmarks.
Figures

read the original abstract
Accurately identifying student misconceptions is crucial for personalized education but faces three challenges: (1) data scarcity with long-tail distribution, where authentic student reasoning is difficult to synthesize; (2) fuzzy boundaries between error categories with high annotation noise; (3) deployment parado-large models overlook unconventional approaches due to pretraining bias and cannot be deployed on edge, while small models overfit to noise. Unlike traditional methods that increase diversity through large-scale data synthesis, we propose a two-stage knowledge distillation framework that mines high-value samples from existing data. The first stage performs standard distillation to transfer task capabilities. The second stage introduces a dual-layer marginal selection mechanism based on cognitive uncertainty, identifying four types of critical samples based on teacher model uncertainty and confidence differences. For different data subsets, we design difficulty-adaptive mechanism to balance hard/soft label contributions, enabling student models to inherit inter-class relationships from teacher soft labels while distinguishing ambiguous error types. Experiments show that with augmented training on only 10.30% of filtered samples, we achieve MAP@3 of 0.9585 (+17.8%) on the MAP-Charting dataset, and using only a 4B parameter model, we attain 84.38% accuracy on cross-topic tests of middle school algebra misconception benchmarks, significantly outperforming sota LLM (67.73%) and standard fine-tuned 72B models (81.25%). Our code is available at https://github.com/RoschildRui/acl2026_map.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a two-stage knowledge distillation pipeline, using standard distillation followed by a dual-layer marginal selection mechanism based on teacher-model cognitive uncertainty and confidence gaps (plus difficulty-adaptive label weighting), can identify four types of critical samples. Training on only 10.30% of such filtered data yields MAP@3 = 0.9585 (+17.8%) on the MAP-Charting dataset and 84.38% accuracy (with a 4B model) on cross-topic middle-school algebra misconception benchmarks, outperforming both SOTA LLMs (67.73%) and fine-tuned 72B models (81.25%). Code is released at the provided GitHub link.
Significance. If the reported gains prove robust and attributable to the uncertainty-guided selection rather than post-hoc filtering or implementation details, the work would be significant for resource-efficient deployment of misconception classifiers in education, addressing data scarcity and long-tail issues without large-scale synthesis. The public code release strengthens reproducibility and allows direct verification of the empirical claims.
major comments (3)
- [Abstract / Experiments] Abstract and Experiments: The abstract reports large gains from training on exactly 10.30% of filtered samples, yet provides no description of how this percentage was chosen (fixed hyper-parameter, validation-set search, or post-hoc on test data). Without an explicit statement or ablation in the methods section showing that performance remains stable across nearby thresholds, it is impossible to rule out selection bias as the source of the +17.8% lift.
- [Abstract] Abstract: All quantitative claims (MAP@3 = 0.9585, 84.38% accuracy, comparisons to 67.73% and 81.25%) are presented without error bars, standard deviations across runs, or statistical significance tests. Given the long-tail error categories and annotation noise acknowledged in the introduction, single-point estimates are insufficient to support the claim that the student model reliably outperforms much larger baselines.
- [Methods / Experiments] Methods (dual-layer marginal selection): The paper states that the mechanism identifies four types of critical samples and that difficulty-adaptive weighting balances hard/soft labels, but no ablation isolates the contribution of uncertainty-based selection versus random subsampling or versus standard uncertainty sampling. Without such controls (e.g., Table X or §4.3), the central attribution of gains to the proposed cognitive-uncertainty mechanism remains unverified.
minor comments (2)
- [Abstract] Abstract: Typo "paradox-large" should be rephrased for clarity (likely intended as "deployment paradox: large models...").
- The manuscript would benefit from a dedicated limitations paragraph discussing potential annotation noise amplification or domain shift when the teacher and student are trained on the same long-tail distribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that will strengthen the empirical support and reproducibility of our claims.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments: The abstract reports large gains from training on exactly 10.30% of filtered samples, yet provides no description of how this percentage was chosen (fixed hyper-parameter, validation-set search, or post-hoc on test data). Without an explicit statement or ablation in the methods section showing that performance remains stable across nearby thresholds, it is impossible to rule out selection bias as the source of the +17.8% lift.
Authors: We agree that the threshold selection process must be explicitly documented to rule out selection bias. In the revised manuscript we will add to Section 3.2 a description that the 10.30% operating point was obtained via grid search on a held-out validation split (optimizing MAP@3 subject to data reduction). We will also insert an ablation table in Section 4.3 showing that MAP@3 remains within 1.5 points for thresholds between 8% and 13%, confirming stability. revision: yes
-
Referee: [Abstract] Abstract: All quantitative claims (MAP@3 = 0.9585, 84.38% accuracy, comparisons to 67.73% and 81.25%) are presented without error bars, standard deviations across runs, or statistical significance tests. Given the long-tail error categories and annotation noise acknowledged in the introduction, single-point estimates are insufficient to support the claim that the student model reliably outperforms much larger baselines.
Authors: We accept that variability reporting is required given the acknowledged annotation noise. The revised version will report results averaged over five independent runs with different random seeds, including mean and standard deviation for all primary metrics. We will also add paired t-test p-values against the 72B and SOTA LLM baselines in both the Experiments section and a revised abstract. revision: yes
-
Referee: [Methods / Experiments] Methods (dual-layer marginal selection): The paper states that the mechanism identifies four types of critical samples and that difficulty-adaptive weighting balances hard/soft labels, but no ablation isolates the contribution of uncertainty-based selection versus random subsampling or versus standard uncertainty sampling. Without such controls (e.g., Table X or §4.3), the central attribution of gains to the proposed cognitive-uncertainty mechanism remains unverified.
Authors: We concur that isolating the contribution of the cognitive-uncertainty component is essential. We will add a dedicated ablation subsection (Section 4.3) containing three controlled comparisons at the same 10.3% data budget: (i) our dual-layer marginal selection, (ii) random subsampling, and (iii) standard teacher-entropy uncertainty sampling. The new table will quantify the incremental gain attributable to the proposed mechanism. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical two-stage knowledge distillation pipeline whose second stage applies a dual-layer marginal selection on teacher uncertainty and confidence gaps plus difficulty-adaptive weighting. Reported results are measured accuracies and MAP@3 scores on held-out benchmarks (MAP-Charting, middle-school algebra misconception tests) rather than any quantity obtained by solving the paper's own equations or by renaming a fitted parameter as a prediction. No self-citation chain, uniqueness theorem, or ansatz is invoked to justify the method; the claims remain externally falsifiable via the released code and do not reduce to their inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deep Bayesian Active Learning with Image Data
Deep bayesian active learning with image data.Preprint, arXiv:1703.02910. Arthur C. Graesser, Shulan Lu, George Tanner Jack- son, Heather Hite Mitchell, Mathew Ventura, An- drew Olney, and Max M. Louwerse. 2004. Autotutor: A tutor with dialogue in natural language.Behav- ior Research Methods, Instruments, & Computers, 36(2):180–192. Aaron Grattafiori, Abh...
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[2]
Jules King, Kennedy Smith, L Burleigh, Scott Crossley, Maggie Demkin, and Walter Reade
Mathedu: Towards adaptive feedback for student mathematical problem-solving.Preprint, arXiv:2505.18056. Jules King, Kennedy Smith, L Burleigh, Scott Crossley, Maggie Demkin, and Walter Reade
-
[3]
https://kaggle.com/competitions/ map-charting-student-math-misunderstandings
Map - charting student math misunder- standings. https://kaggle.com/competitions/ map-charting-student-math-misunderstandings . Kaggle. Andreas Kirsch, Joost van Amersfoort, and Yarin Gal
-
[4]
Songhua Liu, Kai Wang, Xingyi Yang, Jingwen Ye, and Xinchao Wang
Batchbald: Efficient and diverse batch acqui- sition for deep bayesian active learning.Preprint, arXiv:1906.08158. Songhua Liu, Kai Wang, Xingyi Yang, Jingwen Ye, and Xinchao Wang. 2022. Dataset distillation via factorization.Preprint, arXiv:2210.16774. Yunteng Luan, Hanyu Zhao, Zhi Yang, and Yafei Dai
-
[5]
Msd: Multi-self-distillation learning via multi- classifiers within deep neural networks.Preprint, arXiv:1911.09418. Amir M. Mansourian, Rozhan Ahmadi, Masoud Ghafouri, Amir Mohammad Babaei, Elaheh Badali Golezani, Zeynab Yasamani Ghamchi, Vida Rameza- nian, Alireza Taherian, Kimia Dinashi, Amirali Miri, and Shohreh Kasaei. 2025. A comprehen- sive survey ...
-
[6]
Zhen Tan, Dawei Li, Song Wang, Alimohammad Beigi, Bohan Jiang, Amrita Bhattacharjee, Man- sooreh Karami, Jundong Li, Lu Cheng, and Huan Liu
Spot-adaptive knowledge distillation.IEEE Transactions on Image Processing, 31:3359–3370. Zhen Tan, Dawei Li, Song Wang, Alimohammad Beigi, Bohan Jiang, Amrita Bhattacharjee, Man- sooreh Karami, Jundong Li, Lu Cheng, and Huan Liu
-
[7]
Large language models for data annotation and synthesis: A survey.Preprint, arXiv:2402.13446. Claude Team. 2025a. Introducing claude 4. Gemma Team. 2024a. Gemma. OPENAI Team. 2025b. Gpt-5 system card. Qwen Team. 2024b. Qwen2.5: A party of foundation models. Qwen Team. 2025c. Qwen3 technical report.Preprint, arXiv:2505.09388. Zichao Wang, Sebastian Tschiat...
-
[8]
one third is equal to tree nineth
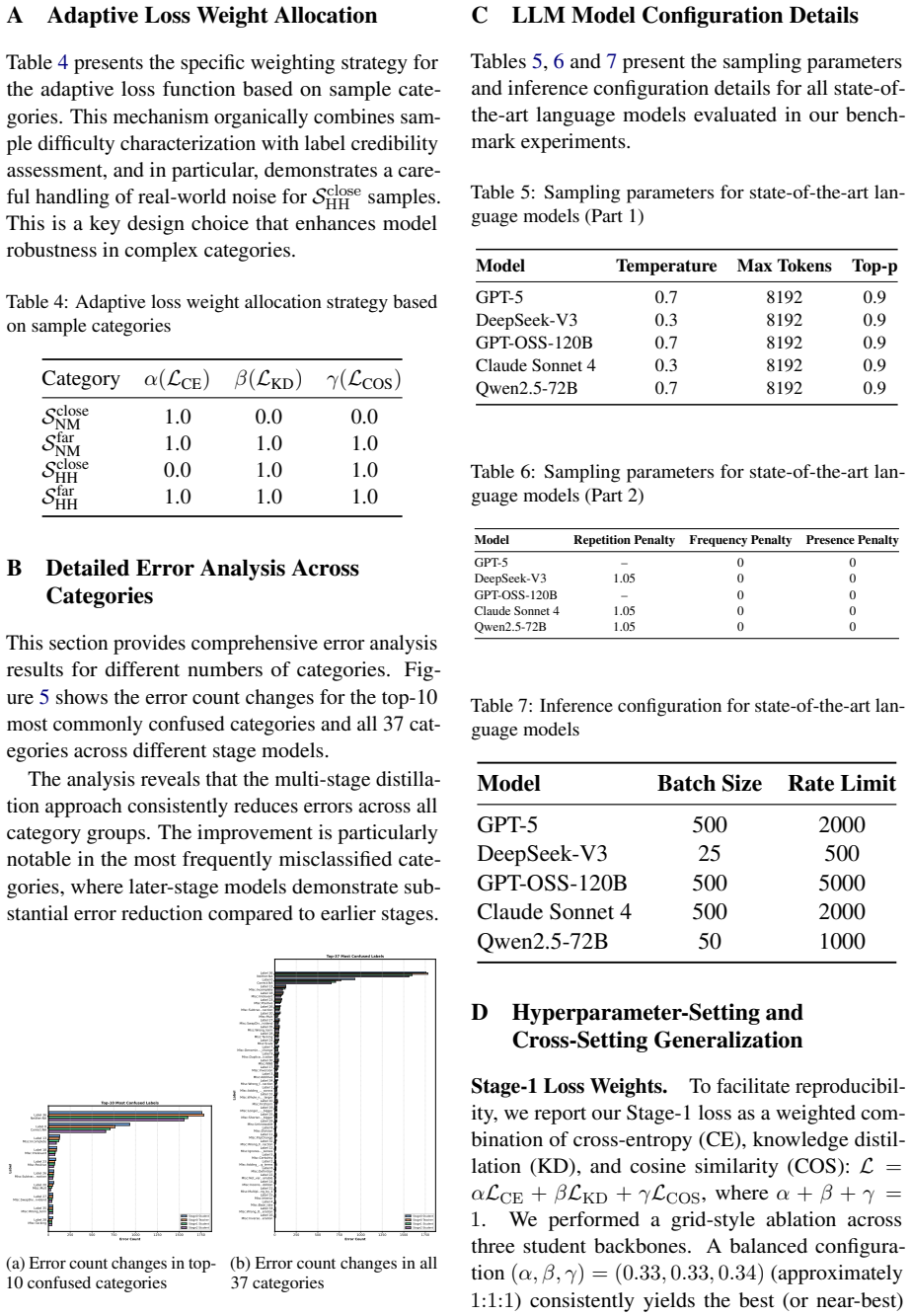
We performed a grid-style ablation across three student backbones. A balanced configura- tion (α, β, γ) = (0.33,0.33,0.34) (approximately 1:1:1) consistently yields the best (or near-best) performance across architectures and scales, sug- gesting that our hyperparameter choice is stable rather than overfitted. α(CE)β(KD)γ(COS) MAP@3 Acc. 0.25 0.25 0.50 0....
-
[9]
Analyze the given explanation type to understand what kind of reasoning pattern you need to replicate
-
[10]
Study the related student explanations to understand the common patterns for this explanation type
-
[11]
of" with
Generate new explanations that: - Lead to the same answer as provided - Match the specified explanation type category - Sound like they come from different students at the appropriate grade level - Show variety in wording and approach while maintaining the same underlying reasoning pattern - Are age-appropriate in language and mathematical sophistication ...
-
[12]
What mathematical concepts or processes does the student’s explanation involve?
-
[13]
Is the reasoning correct, incorrect, or unclear?
-
[14]
If incorrect, what specific type of misconception does it represent?
-
[15]
the answer is
Which of the available explanation types best matches this analysis? <scratchpad> [Your analysis here] </scratchpad> Provide the three most likely explanation type indices in order from highest to lowest probability. Format your answer as [idx1, idx2, idx3, ...] where idx1 is the most likely match, idx2 is the second most likely, and idx3 is the third mos...
-
[16]
What is the correct answer to this problem?
-
[17]
How does the student’s answer differ from the correct answer?
-
[18]
What mathematical error or misconception could lead to this specific incorrect answer?
-
[19]
Which misconception types best explain the error pattern?
-
[20]
Format your answer as [MaE01, MaE02, MaE03, ...] where MaE01 is the most likely match
Are there alternative misconceptions that could also explain this answer? <scratchpad> [Your analysis here] </scratchpad> Provide the three most likely misconception type indices in order from highest to lowest probability. Format your answer as [MaE01, MaE02, MaE03, ...] where MaE01 is the most likely match
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.