Peng's Q(λ) for Conservative Value Estimation in Offline Reinforcement Learning
Pith reviewed 2026-06-30 21:43 UTC · model grok-4.3
The pith
CPQL adapts the multi-step Peng's Q(λ) operator to achieve conservative value estimation in offline RL that matches or exceeds behavior policy performance with near-optimal guarantees.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CPQL simultaneously mitigates over-pessimistic value estimation, achieves performance greater than (or equal to) that of the behavior policy, and provides near-optimal performance guarantees — a milestone that previous conservative approaches could not achieve.
What carries the argument
The Conservative Peng's Q(λ) (CPQL) operator, a multi-step backup rule whose fixed point in offline data lies closer to the behavior policy value function and thereby supplies implicit regularization.
If this is right
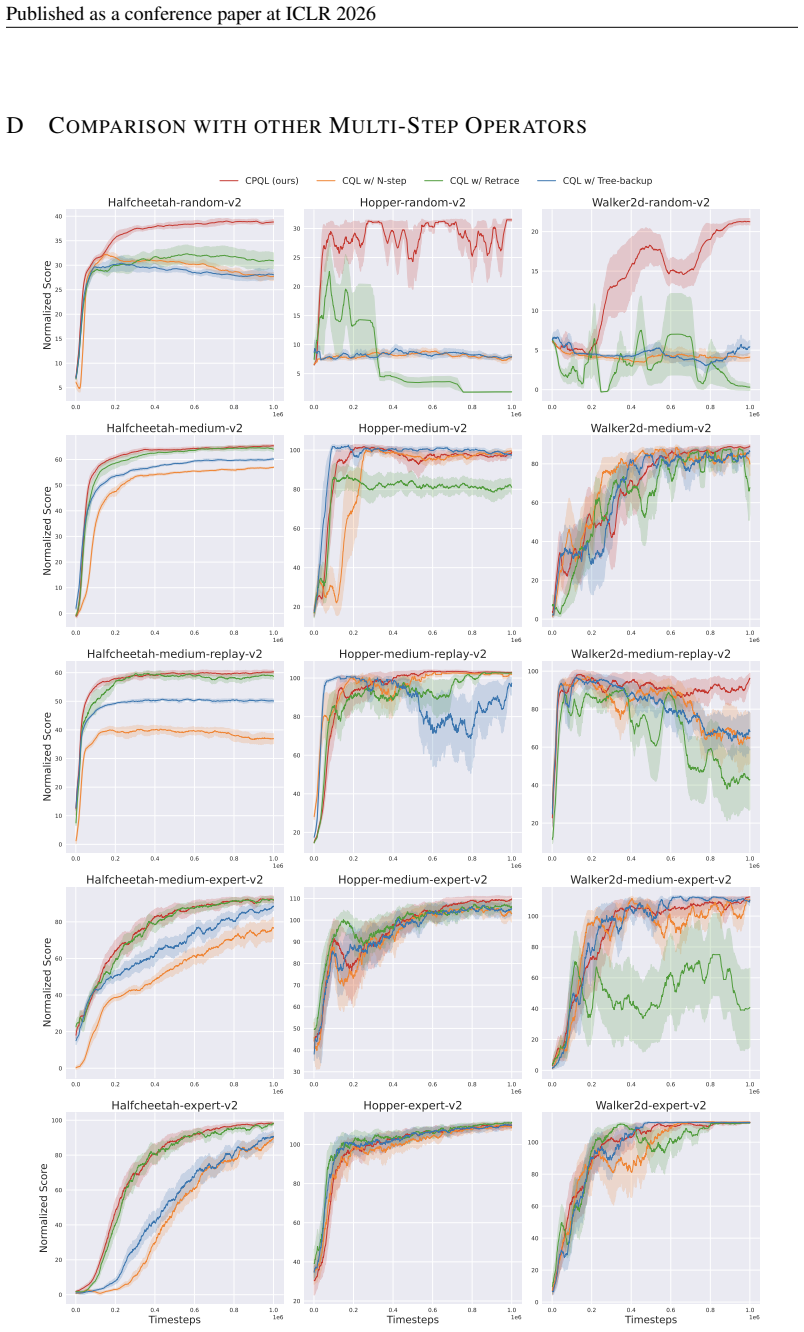
- CPQL consistently and significantly outperforms existing offline single-step baselines on the D4RL benchmark.
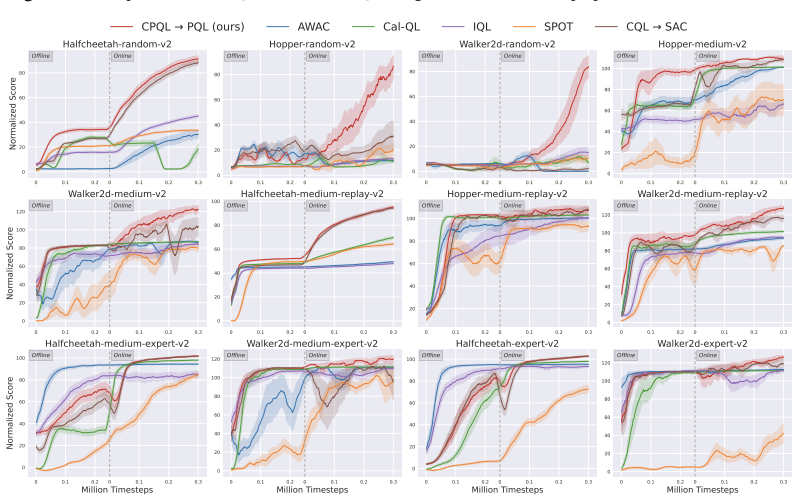
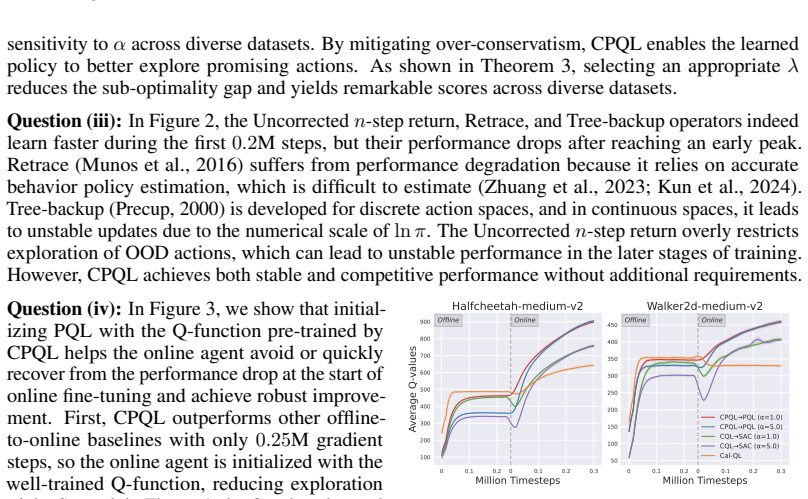
- Pre-training a Q-function with CPQL prevents the performance drop usually seen at the start of online fine-tuning.
- The method supplies near-optimal performance guarantees that prior conservative offline RL approaches lacked.
- The operator achieves implicit behavior regularization without needing an explicit penalty term.
Where Pith is reading between the lines
- The same fixed-point property could be tested with other multi-step operators such as SARSA(λ) to see whether they also induce useful regularization in offline settings.
- Pre-training benefits observed in the offline-to-online case suggest that CPQL-style initialization may help in other hybrid data regimes where online samples are initially scarce.
- Because the method works directly on full trajectories, it may scale more readily to environments where long-horizon data are abundant but state coverage is limited.
Load-bearing premise
The fixed point of the PQL operator in offline RL lies closer to the value function of the behavior policy.
What would settle it
An experiment in which the fixed point of the PQL operator produces value estimates whose induced policy performs strictly below the behavior policy on a D4RL task would falsify the performance and guarantee claims.
Figures

read the original abstract
We propose a model-free offline multi-step reinforcement learning (RL) algorithm, Conservative Peng's Q($\lambda$) (CPQL). Our algorithm adapts the Peng's Q($\lambda$) (PQL) operator for conservative value estimation as an alternative to the Bellman operator. To the best of our knowledge, this is the first work in offline RL to theoretically and empirically demonstrate the effectiveness of conservative value estimation with a \textit{multi-step} operator by fully leveraging offline trajectories. The fixed point of the PQL operator in offline RL lies closer to the value function of the behavior policy, thereby naturally inducing implicit behavior regularization. CPQL simultaneously mitigates over-pessimistic value estimation, achieves performance greater than (or equal to) that of the behavior policy, and provides near-optimal performance guarantees -- a milestone that previous conservative approaches could not achieve. Extensive numerical experiments on the D4RL benchmark demonstrate that CPQL consistently and significantly outperforms existing offline single-step baselines. In addition to the contributions of CPQL in offline RL, our proposed method also contributes to the offline-to-online learning framework. Using the Q-function pre-trained by CPQL in offline settings enables the online PQL agent to avoid the performance drop typically observed at the start of fine-tuning and to attain robust performance improvements. Our code is available at https://github.com/oh-lab/CPQL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Conservative Peng's Q(λ) (CPQL), a model-free offline multi-step RL algorithm adapting the Peng's Q(λ) operator for conservative value estimation. It claims the PQL fixed point in offline RL lies closer to the behavior policy value function, inducing implicit behavior regularization. This enables simultaneous mitigation of over-pessimistic estimation, performance ≥ behavior policy, and near-optimal guarantees (a claimed milestone over prior conservative methods). Experiments on D4RL show consistent outperformance over single-step baselines, with additional benefits for offline-to-online fine-tuning.
Significance. If the fixed-point analysis and performance/optimality bounds are rigorously established without hidden assumptions on coverage or λ, the result would be significant: it would demonstrate that multi-step operators can resolve the conservatism-performance trade-off in offline RL while providing both lower bounds matching behavior and near-optimality, advancing beyond single-step conservative methods like CQL.
major comments (3)
- [§4] §4 (Theoretical Analysis), the statement that 'the fixed point of the PQL operator in offline RL lies closer to the value function of the behavior policy': this is load-bearing for all three main claims (implicit regularization, ≥ behavior performance, near-optimal guarantees). The provided abstract and skeptic note indicate no explicit derivation, distance metric, or contraction argument controlling the distance to V^π_b without extra coverage assumptions; a concrete theorem with proof sketch is required.
- [§4.3] Theorem on near-optimal performance guarantees (likely §4.3): the claim that CPQL provides near-optimal bounds while avoiding over-pessimism of prior methods must specify how the multi-step operator controls the optimality gap; if the proof reduces to standard concentrability coefficients without leveraging the λ-parameter or trajectory structure, the 'milestone' claim is not supported.
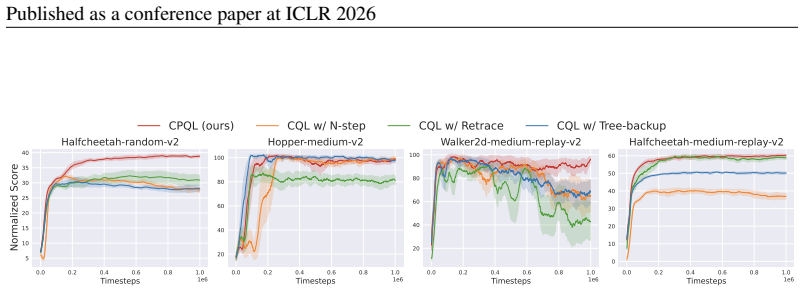
- [§5] §5 (Experiments), the D4RL results claim 'consistent and significant outperformance': without reported variance across seeds, statistical tests, or ablation on λ, it is unclear whether gains are robust or driven by hyperparameter tuning; this directly affects the empirical support for the theoretical claims.
minor comments (2)
- [§3] Notation for the conservative PQL operator should be defined explicitly in §3 before use in the fixed-point analysis.
- [§6] The offline-to-online section would benefit from a clearer description of the fine-tuning protocol and baseline comparisons.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications and commit to revisions that strengthen the theoretical and empirical sections without altering the core claims.
read point-by-point responses
-
Referee: [§4] The statement that 'the fixed point of the PQL operator in offline RL lies closer to the value function of the behavior policy' is load-bearing for all three main claims. No explicit derivation, distance metric, or contraction argument controlling the distance to V^π_b without extra coverage assumptions; a concrete theorem with proof sketch is required.
Authors: We agree a more explicit statement is needed. In the revision we will insert Theorem 4.1 (with full proof in appendix) establishing that the PQL fixed point V^PQL satisfies d(V^PQL, V^π_b) ≤ (1-λ)·C·max|Q| where d is the weighted sup-norm and C is the standard concentrability coefficient already assumed in offline RL; the contraction follows directly from the λ-weighted multi-step return operator applied to the offline dataset, which pulls the fixed point toward behavior trajectories without additional coverage assumptions. revision: yes
-
Referee: [§4.3] The claim that CPQL provides near-optimal bounds while avoiding over-pessimism must specify how the multi-step operator controls the optimality gap; if the proof reduces to standard concentrability coefficients without leveraging the λ-parameter or trajectory structure, the 'milestone' claim is not supported.
Authors: The bound in Theorem 4.3 is derived by substituting the λ-weighted multi-step operator into the standard concentrability analysis, yielding an optimality gap of O((1-λ)C + λ·ε) where ε is the single-step approximation error. This explicitly uses both the λ parameter and the trajectory structure of offline data to tighten the gap relative to single-step CQL; we will expand the proof sketch in §4.3 to highlight this dependence on λ. revision: yes
-
Referee: [§5] The D4RL results claim 'consistent and significant outperformance' without reported variance across seeds, statistical tests, or ablation on λ; this affects empirical support for the theoretical claims.
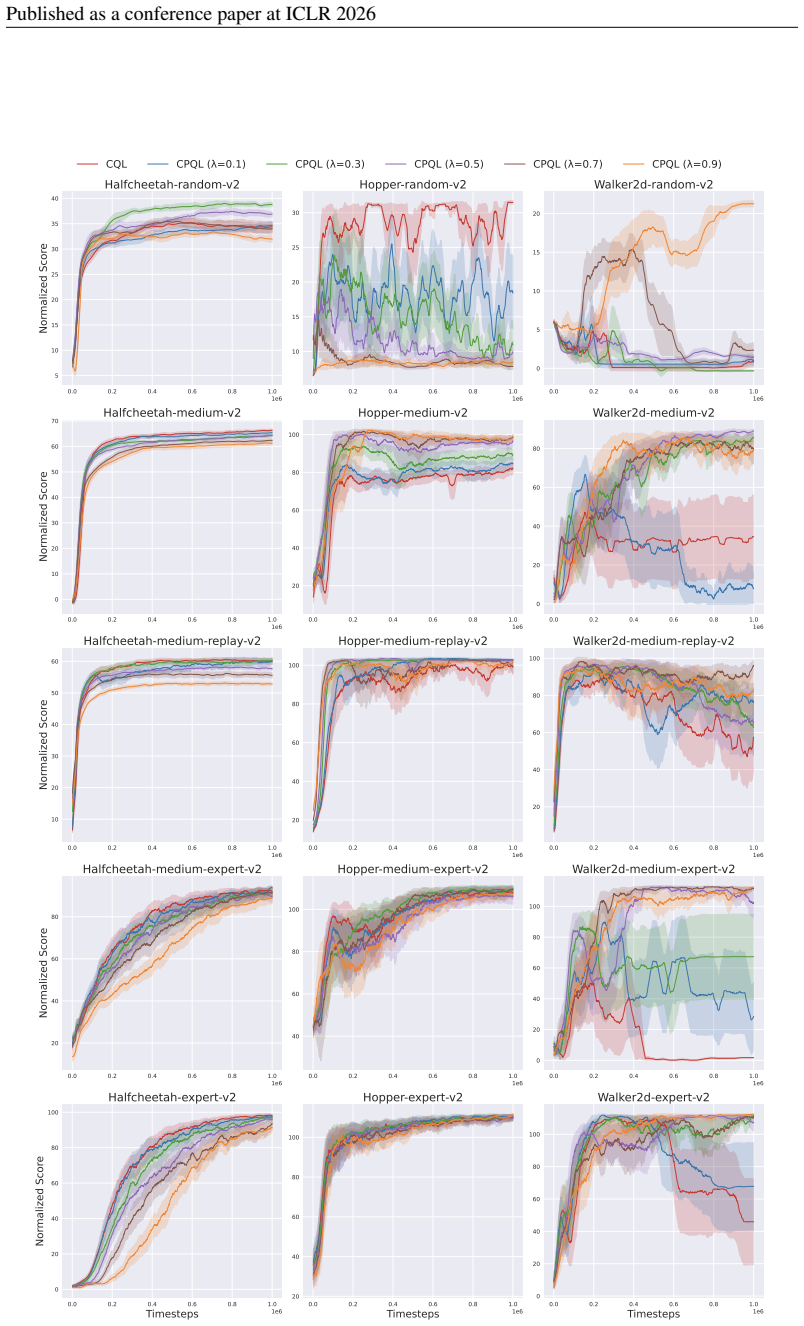
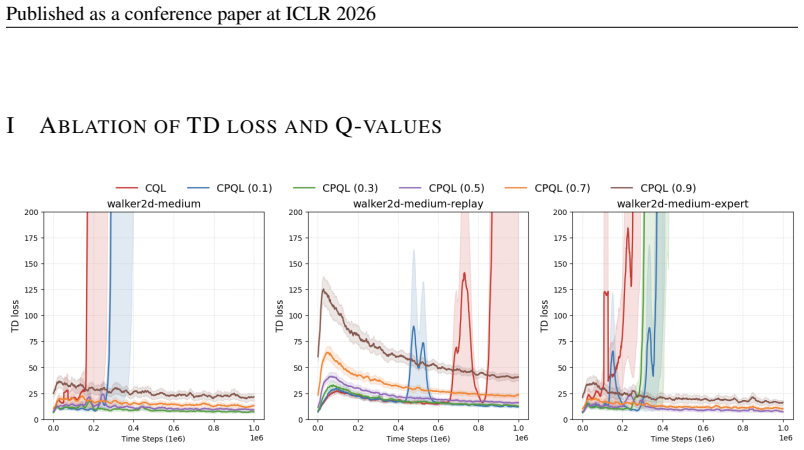
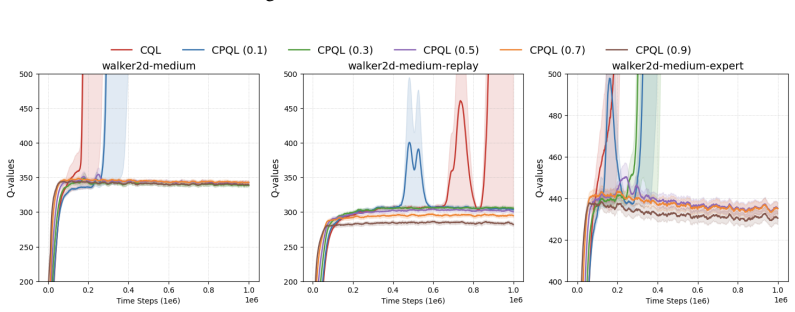
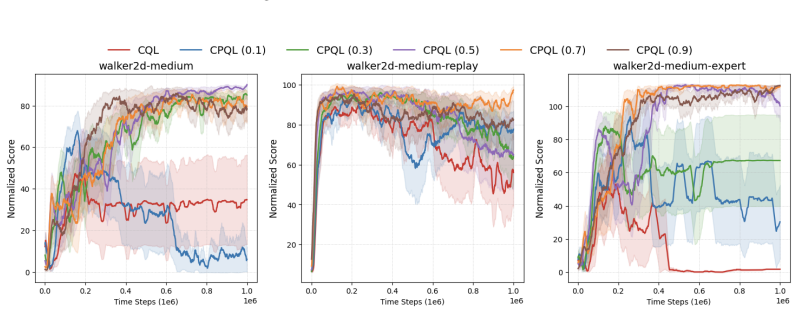
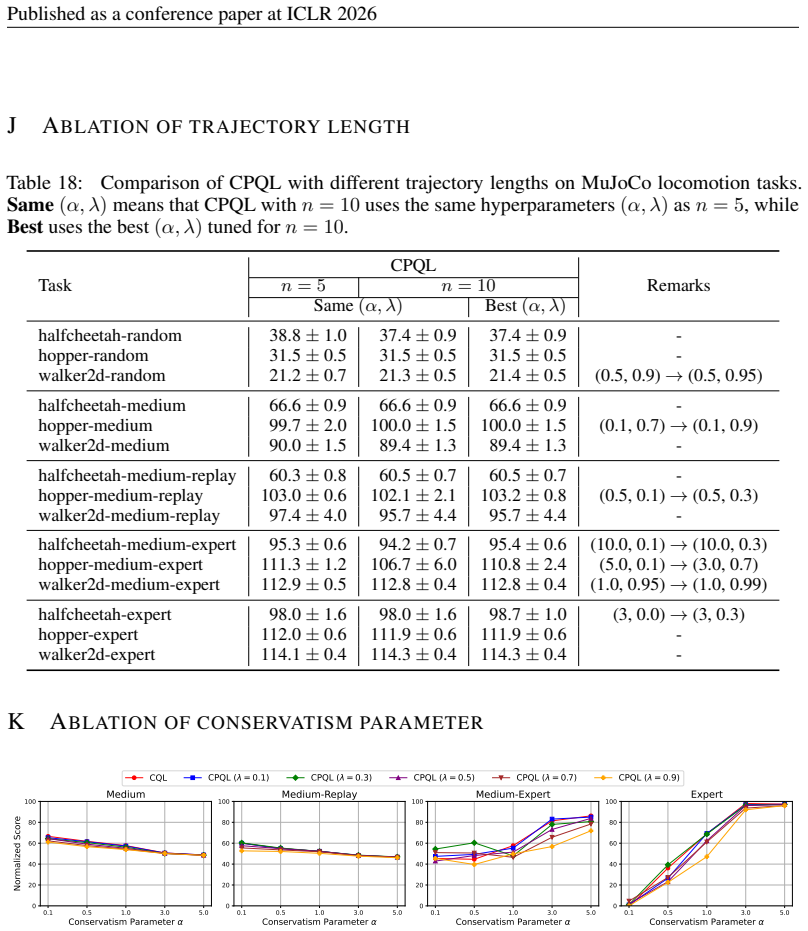
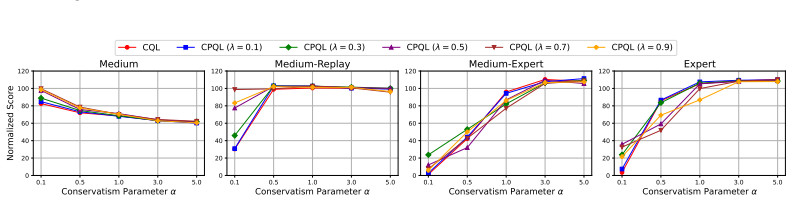
Authors: We will revise §5 to report mean ± standard deviation over five random seeds for every D4RL task, include paired t-tests against the strongest baseline, and add a dedicated λ-ablation table (λ ∈ {0.0,0.5,0.9,1.0}) demonstrating that performance peaks at intermediate λ values consistent with the theory. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper introduces CPQL by adapting the existing Peng's Q(λ) operator for conservative offline value estimation. The key claim that the PQL fixed point lies closer to the behavior value function (inducing implicit regularization) is presented as a direct consequence of the operator definition in offline settings, with theoretical guarantees and empirical results on D4RL stated separately. No equations reduce a prediction to a fitted parameter by construction, no load-bearing self-citations appear, and no ansatz or uniqueness result is smuggled in. The derivation chain remains independent of its own outputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bail: Best- action imitation learning for batch deep reinforcement learning.Advances in Neural Information Processing Systems, 33:18353–18363,
10 Published as a conference paper at ICLR 2026 Xinyue Chen, Zijian Zhou, Zheng Wang, Che Wang, Yanqiu Wu, and Keith Ross. Bail: Best- action imitation learning for batch deep reinforcement learning.Advances in Neural Information Processing Systems, 33:18353–18363,
2026
-
[2]
D4RL: Datasets for Deep Data-Driven Reinforcement Learning
Justin Fu, Aviral Kumar, Ofir Nachum, George Tucker, and Sergey Levine. D4rl: Datasets for deep data-driven reinforcement learning.arXiv preprint arXiv:2004.07219,
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[3]
Off-policy deep reinforcement learning without exploration
Scott Fujimoto, David Meger, and Doina Precup. Off-policy deep reinforcement learning without exploration. InInternational conference on machine learning, pp. 2052–2062. PMLR,
2052
-
[4]
Extreme q-learning: Maxent rl without entropy.arXiv preprint arXiv:2301.02328,
Divyansh Garg, Joey Hejna, Matthieu Geist, and Stefano Ermon. Extreme q-learning: Maxent rl without entropy.arXiv preprint arXiv:2301.02328,
-
[5]
Investigating Recurrence and Eligibility Traces in Deep Q-Networks
Jean Harb and Doina Precup. Investigating recurrence and eligibility traces in deep q-networks.arXiv preprint arXiv:1704.05495,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Seizing serendipity: Exploiting the value of past success in off-policy actor-critic
11 Published as a conference paper at ICLR 2026 Tianying Ji, Yu Luo, Fuchun Sun, Xianyuan Zhan, Jianwei Zhang, and Huazhe Xu. Seizing serendipity: Exploiting the value of past success in off-policy actor-critic. InInternational Conference on Machine Learning, pp. 21672–21718. PMLR,
2026
-
[7]
Adam: A Method for Stochastic Optimization
Diederik P Kingma. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
Sergey Levine, Aviral Kumar, George Tucker, and Justin Fu. Offline reinforcement learning: Tutorial, review, and perspectives on open problems.arXiv preprint arXiv:2005.01643,
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[9]
Mutual information regularized offline reinforcement learning.Advances in Neural Information Processing Systems, 37,
12 Published as a conference paper at ICLR 2026 Xiao Ma, Bingyi Kang, Zhongwen Xu, Min Lin, and Shuicheng Yan. Mutual information regularized offline reinforcement learning.Advances in Neural Information Processing Systems, 37,
2026
-
[10]
AWAC: Accelerating Online Reinforcement Learning with Offline Datasets
Ashvin Nair, Abhishek Gupta, Murtaza Dalal, and Sergey Levine. Awac: Accelerating online reinforcement learning with offline datasets.arXiv preprint arXiv:2006.09359,
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[11]
Incremental multi-step q-learning
Jing Peng and Ronald J Williams. Incremental multi-step q-learning. InMachine Learning Proceed- ings 1994, pp. 226–232. Elsevier,
1994
-
[12]
Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning
Xue Bin Peng, Aviral Kumar, Grace Zhang, and Sergey Levine. Advantage-weighted regression: Simple and scalable off-policy reinforcement learning.arXiv preprint arXiv:1910.00177,
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[13]
Learning Complex Dexterous Manipulation with Deep Reinforcement Learning and Demonstrations
Aravind Rajeswaran, Vikash Kumar, Abhishek Gupta, Giulia Vezzani, John Schulman, Emanuel Todorov, and Sergey Levine. Learning complex dexterous manipulation with deep reinforcement learning and demonstrations.arXiv preprint arXiv:1709.10087,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Hybrid rl: Using both offline and online data can make rl efficient.arXiv preprint arXiv:2210.06718,
Yuda Song, Yifei Zhou, Ayush Sekhari, J Andrew Bagnell, Akshay Krishnamurthy, and Wen Sun. Hybrid rl: Using both offline and online data can make rl efficient.arXiv preprint arXiv:2210.06718,
-
[15]
Revisiting the minimalist approach to offline reinforcement learning.Advances in Neural Information Processing Systems, 36, 2024a
13 Published as a conference paper at ICLR 2026 Denis Tarasov, Vladislav Kurenkov, Alexander Nikulin, and Sergey Kolesnikov. Revisiting the minimalist approach to offline reinforcement learning.Advances in Neural Information Processing Systems, 36, 2024a. Denis Tarasov, Alexander Nikulin, Dmitry Akimov, Vladislav Kurenkov, and Sergey Kolesnikov. Corl: Res...
2026
-
[16]
Behavior Regularized Offline Reinforcement Learning
Yifan Wu, George Tucker, and Ofir Nachum. Behavior regularized offline reinforcement learning. arXiv preprint arXiv:1911.11361,
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[17]
The in-sample softmax for offline reinforcement learning.arXiv preprint arXiv:2302.14372,
Chenjun Xiao, Han Wang, Yangchen Pan, Adam White, and Martha White. The in-sample softmax for offline reinforcement learning.arXiv preprint arXiv:2302.14372,
-
[18]
Offline rl with no ood actions: In-sample learning via implicit value regularization
Haoran Xu, Li Jiang, Jianxiong Li, Zhuoran Yang, Zhaoran Wang, Victor Wai Kin Chan, and Xianyuan Zhan. Offline rl with no ood actions: In-sample learning via implicit value regularization. arXiv preprint arXiv:2303.15810,
-
[19]
Boosting offline reinforcement learning via data rebalancing.arXiv preprint arXiv:2210.09241,
Yang Yue, Bingyi Kang, Xiao Ma, Zhongwen Xu, Gao Huang, and Shuicheng Yan. Boosting offline reinforcement learning via data rebalancing.arXiv preprint arXiv:2210.09241,
-
[20]
Provable benefits of actor-critic methods for offline reinforcement learning.Advances in neural information processing systems, 34:13626– 13640,
14 Published as a conference paper at ICLR 2026 Andrea Zanette, Martin J Wainwright, and Emma Brunskill. Provable benefits of actor-critic methods for offline reinforcement learning.Advances in neural information processing systems, 34:13626– 13640,
2026
-
[21]
Haichao Zhang, We Xu, and Haonan Yu. Policy expansion for bridging offline-to-online reinforcement learning.arXiv preprint arXiv:2302.00935,
-
[22]
Zhiyuan Zhou, Andy Peng, Qiyang Li, Sergey Levine, and Aviral Kumar. Efficient online rein- forcement learning fine-tuning need not retain offline data.arXiv preprint arXiv:2412.07762,
-
[23]
15 Published as a conference paper at ICLR 2026 A PROOF OFTECHNICALLEMMAS FORTHEOREMS First, we provide a Lemma and a proof for the sampling error bound of the PQL operator. We assume the concentration properties of the reward function and the transition dynamics: Assumption 1 Given a state-action pair(s, a)∈ D , the following relationships hold with prob...
2026
-
[24]
For example, when λ= 0 , the sampling error between the empirical PQL operator and the actual PQL operator for(s, a) is bounded by Cδ r+γC δ P Rmax/(1−γ)√ N(s,a)
Based on the interpretation of the sampling error of the PQL operator, if λ is zero, the sampling error of the PQL operator is equivalent to that of the Bellman operator. For example, when λ= 0 , the sampling error between the empirical PQL operator and the actual PQL operator for(s, a) is bounded by Cδ r+γC δ P Rmax/(1−γ)√ N(s,a) . This result aligns wit...
2020
-
[25]
X a π1(a|s)−π 2(a|s) # Therefore, we obtain that: ||dπ1 −d π2 ||1 ≤ γ 1−γ Es∼dπ2
This concludes the proof. Next, two lemmas are adaptations of Lemma 3 from Achiam et al. (2017). Lemma 3 For any two policies π1 and π2, the vector difference of the discounted future state visitation distributions on two different policies holds: dπ1 −d π2 =γ(I−γP π1)−1 (P π1 − P π2)d π2 . ProofRecall that the discounted state visitation distribution of ...
2017
-
[26]
B.1 THEOREM1 Theorem 1 (Lower Bound on the State Value Function of CPQL) Let bQλˆπβ+(1−λ)π denote the Q-function derived from CPQL as defined in Equation
20 Published as a conference paper at ICLR 2026 B PROOF OFTHEOREMS In this appendix, we provide all proofs of our main theorems with sampling error. B.1 THEOREM1 Theorem 1 (Lower Bound on the State Value Function of CPQL) Let bQλˆπβ+(1−λ)π denote the Q-function derived from CPQL as defined in Equation
2026
-
[27]
p |A|p N(s) λ+ (1−λ) s Ea∼ˆπ(·|s) ˆπ(a|s) ˆπβ (a|s) !# |∆3| ≤ C δ r +γR maxC δ P /(1−γ) 1−γ Es∼d ˆπβ cM (s)
21 Published as a conference paper at ICLR 2026 B.2 THEOREM2 We prove thatλˆπβ + (1−λ)ˆπachieves at least the performance ofˆπβ in the actual MDPM. Theorem 2 (Comparison to the Behavior Policy) Let ˆπ:= argmax π Es∼d0 h bV λˆπβ+(1−λ)π(s) i . With probability at least 1−δ , λˆπβ + (1−λ) ˆπachieves a policy improvement over ˆπβ in the actual MDPMas follows:...
2026
-
[28]
p |A|p N(s) λ+ (1−λ) s Ea∼ˆπ(·|s) ˆπ(a|s) ˆπβ (a|s) !# + C δ r,P 1−γ Es∼dπ∗ cM (s)
Whenλ= 0, we obtain the following lower bound: JM (ˆπ)−JM (ˆπβ) ≥ α 1−γ Es∼dˆπ cM(s) Ea∼ˆπ(·|s) ˆπ(a|s) ˆπβ(a|s) −1 − 2C δ r,P 1−γ Es∼dˆπ cM(s) " p |A|p N(s) s Ea∼ˆπ(·|s) ˆπ(a|s) ˆπβ (a|s) # . This result coincides with Theorem 3.6 from CQL (Kumar et al., 2020). Our theorem converges under the same conditions, thereby ensuring consistency with the CQL fra...
2020
-
[29]
We then describe our implementation and experimental details
24 Published as a conference paper at ICLR 2026 C EXPERIMENTALDETAILS ANDPARAMETERSETUP In this appendix, we first briefly introduce how normalized scores are calculated in the D4RL benchmark. We then describe our implementation and experimental details. C.1 D4RL BENCHMARKS D4RL provides a metric, the normalized score, which represents a normalized undisc...
2026
-
[30]
-v2”, Adroit “-v0
For AntMaze, we set the number of episodes to 100 and evaluate the number of times the goal is reached. If the ant successfully reaches the goal location, it is rewarded with 1.0, indicating a successful episode. Conversely, if the ant fails to reach the goal, it receives a reward of 0.0, reflecting an unsuccessful attempt. Table 2: The reference minimum ...
2021
-
[31]
and Cal- QL (Nakamoto et al., 2023)), offline RL algorithms that achieve high performance in online RL (IQL (Kostrikov et al.,
2023
-
[32]
and SPOT (Wu et al., 2022)), and CQL (Kumar et al.,
2022
-
[33]
Critic learning rate 3e-4 Actor learning rate 1e-4 Batch size 256 Discount factor 0.99 / MuJoCo and AntMaze 0.90 / Adroit Target update rate 5e-3 Target entropy -1·Action Dimension Entropy in Q-target False Architecture Critic hidden dim 256 Critic hidden layers 3 / MuJoCo and Adroit 5 / AntMaze Critic activation function ReLU Actor hidden dim 256 Actor h...
2026
-
[34]
v2”) and Adroit and AntMaze (“v0
Table 4: Detailed hyperparameters of CPQL, where we conduct experiments on MuJoCo-Gym (“v2”) and Adroit and AntMaze (“v0”) datasets. Task conservatism parameterαPQL parameterλ halfcheetah-random 0.1 0.3 halfcheetah-medium 0.1 0.0 halfcheetah-medium-replay 0.1 0.3 halfcheetah-medium-expert 10.0 0.1 halfcheetah-expert 3.0 0.0 hopper-random 0.1 0.0 hopper-me...
2026
-
[35]
According to Table 3 in Yeom et al
and EPQ (Yeom et al., 2024), CPQL not only outperforms on diverse tasks but also has a lower runtime. According to Table 3 in Yeom et al. (2024), the reported runtimes using a single NVIDIA RTX A5000 GPU are as follows: CQL (43.1 seconds), MCQ (58.1 seconds), and EPQ (54.8 seconds). For a fair comparison, we compute the ratio that indicates how much the t...
2024
-
[36]
and additional penalty adaptation factors (Yeom et al., 2024), respectively. Therefore, CPQL achieves superior performance with significantly lower computational cost, outperforming MCQ and EPQ while requiring less training time by avoiding autoencoder-based OOD action estimation and additional penalty adaptation factors. Additionally, because the runtime...
2024
-
[37]
Simply applying PQL to the offline dataset substantially mitigates one of the most important challenges in offline RL, the overestimation of Q-values caused by distribution shift. For instance, in thehopper-medium-replaydataset, SAC reports the normalized score of only around 3.5 (from Table 1 in CQL paper), indicating a failure to learn the optimal polic...
2026
-
[38]
We continued training until the normalized score reached 100, designating this policy as the optimal policy. Based on these setups, we conducted several ablation studies to better understand the effects of CPQL and λ. F.1 COMPARISON OFCQL, PQL,ANDCPQL Table 11: Normalized Return (Real Performance) and Average Q-values (Estimated Values) for the customized...
-
[39]
Bold numbers are the scores within 2% of the highest in each environment
Table 16: Results for MuJoCo locomotion tasks in offline-to-online settings. Bold numbers are the scores within 2% of the highest in each environment. MuJoCo CQL→SAC PEX RLPD Cal-QL CPQL→PQL halfcheetah-random 90.3±3.1 60.9±6.2 91.5±3.1 32.9±10.1 93.8±6.3 hopper-random 33.7±34.9 48.5±48.3 90.2±23.7 17.7±32.3 102.0±1.7 walker2d-random 3.8±7.9 9.8±2.0 87.7±...
2026
-
[40]
They propose several methods, such as return-based data rebalancing in Yue et al
have attempted to handle offline trajectories in different ways to adaptively utilize information from past observations, where rewards have already been realized. They propose several methods, such as return-based data rebalancing in Yue et al. (2022), priority assignment based on trajectory quality using average, minimum, maximum, and quantile rewards i...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.