Understanding Imbalanced Forgetting in Rehearsal-Based Class-Incremental Learning
Pith reviewed 2026-06-30 21:41 UTC · model grok-4.3
The pith
Three last-layer gradient coefficients predict the forgetting ranking of past classes after each incremental training step in rehearsal-based class-incremental learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
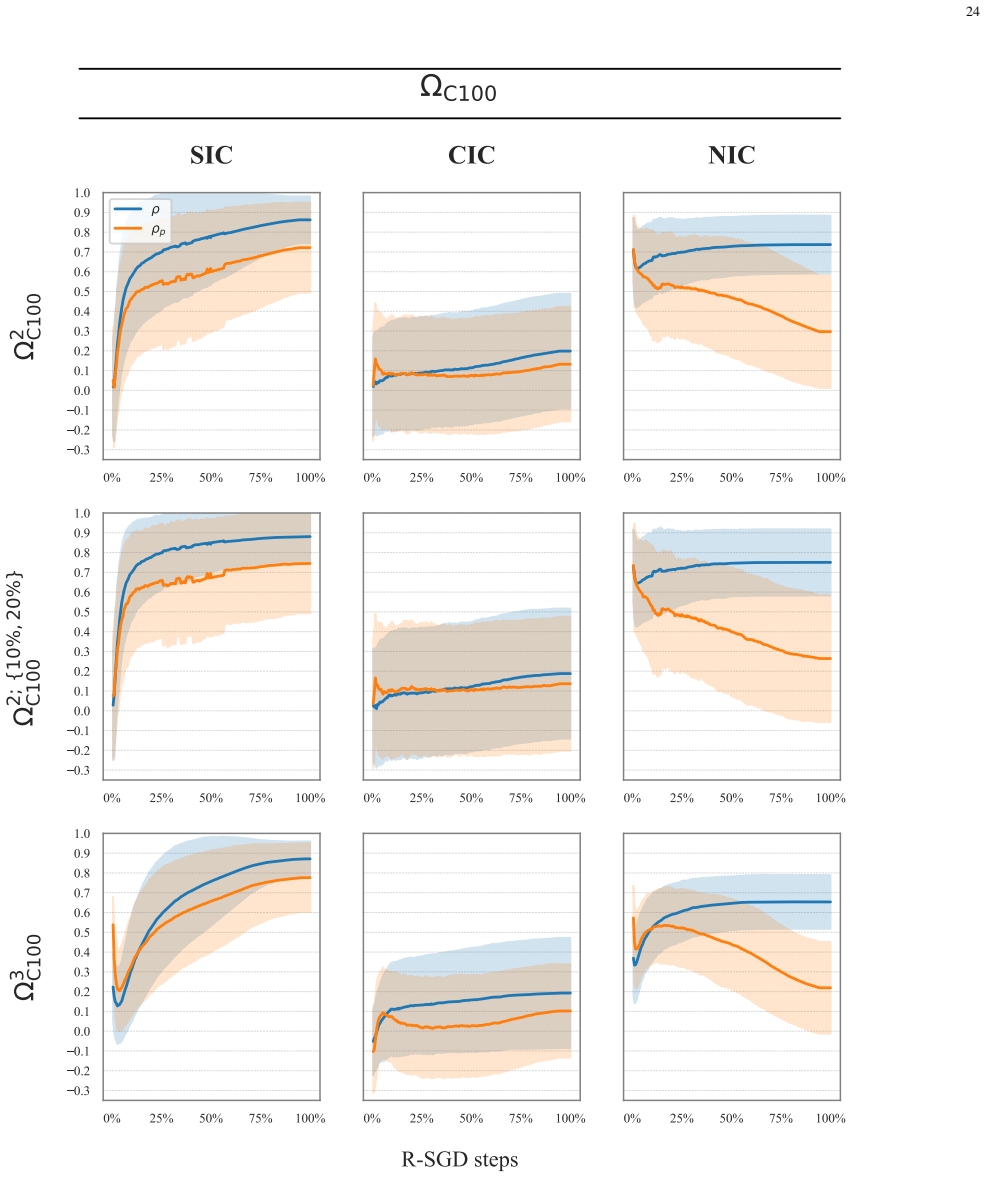
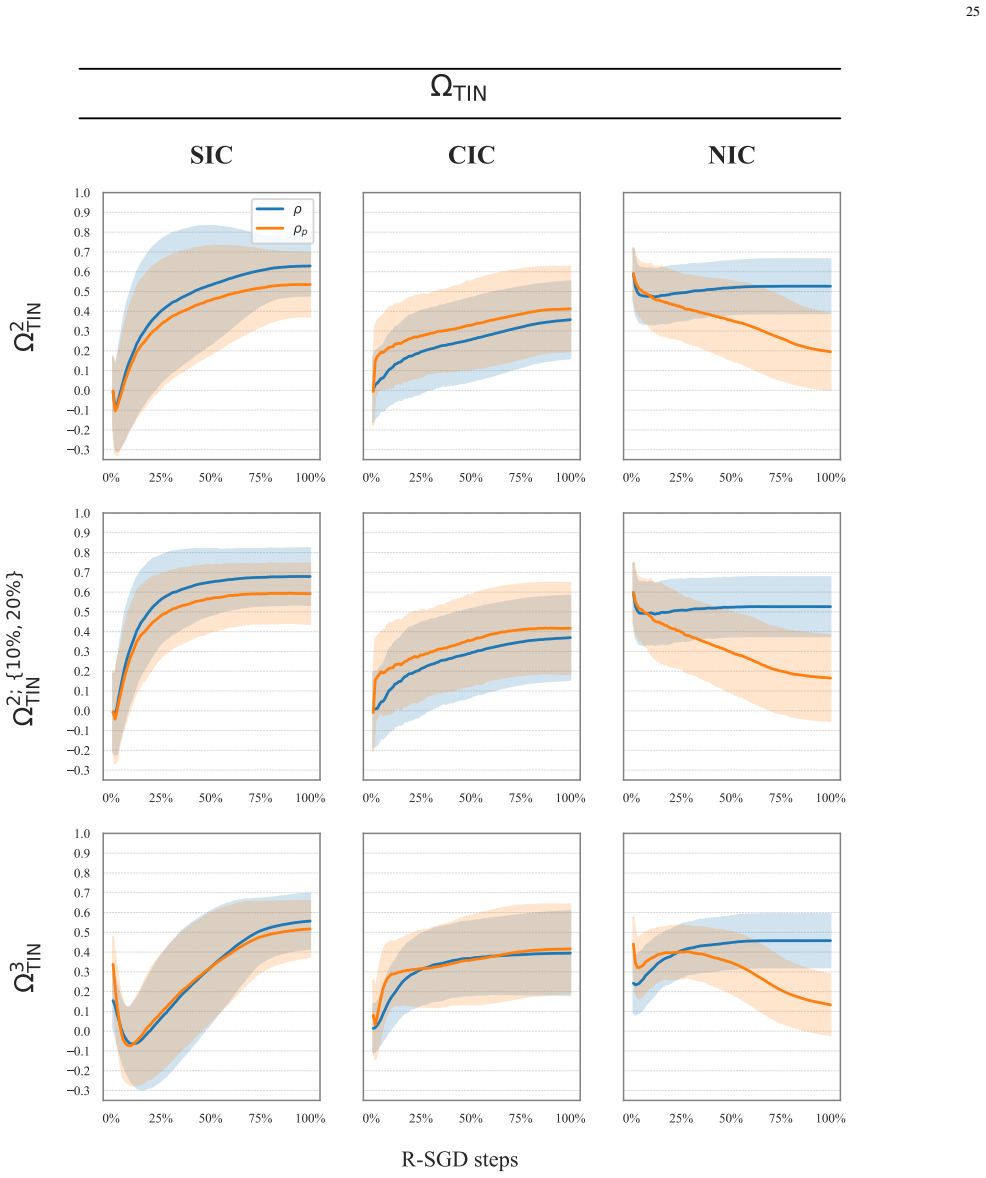
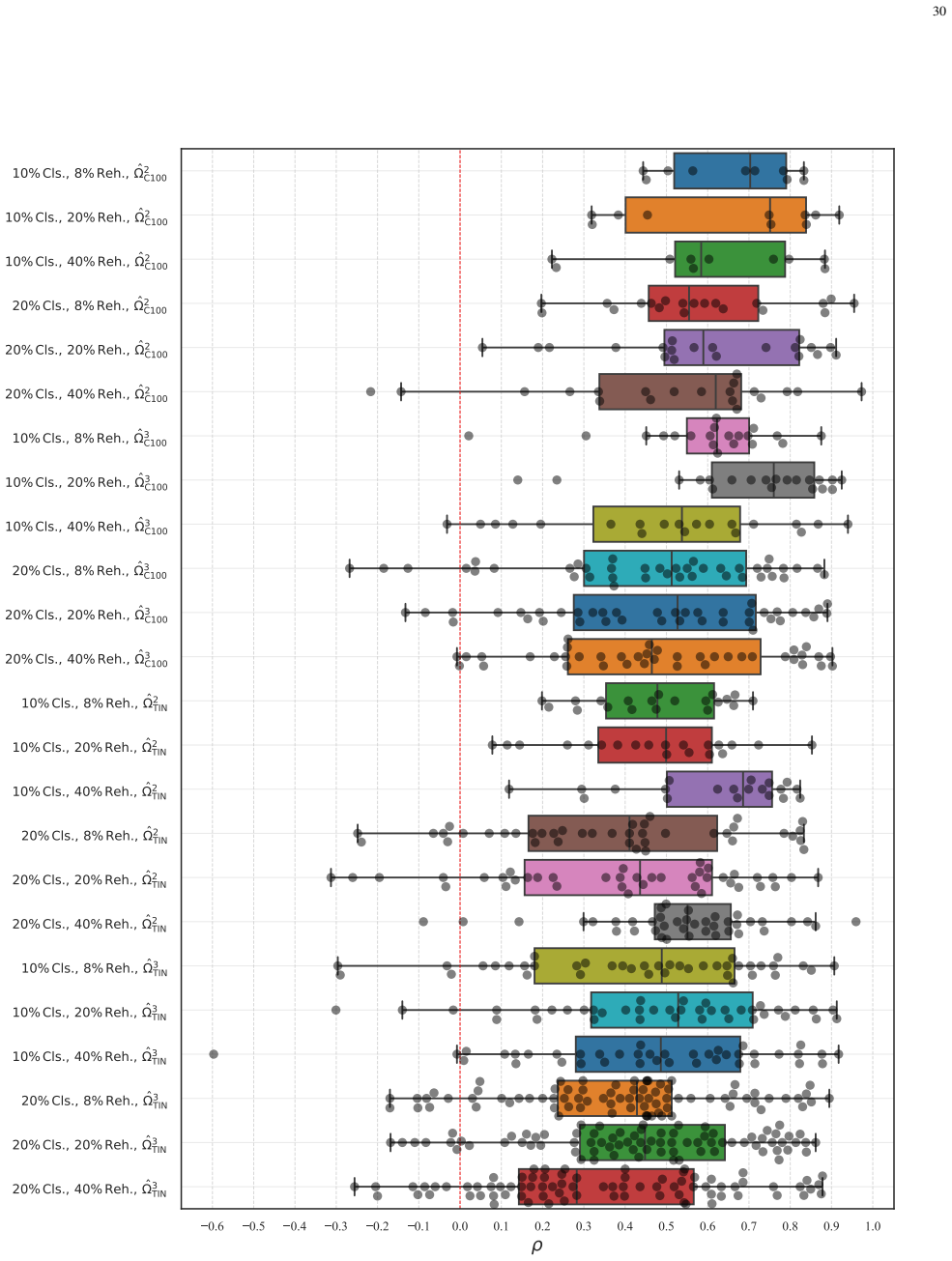
From a principled analysis of gradients, three last-layer coefficients are constructed that capture different sources of interference affecting each past class during an incremental step. Together these coefficients reliably predict how the past classes will rank in terms of forgetting at the end of the step, supporting the view that last-layer gradient interactions during training drive the observed class-level forgetting outcomes, with the self-induced interference coefficient as the dominant term.
What carries the argument
Three last-layer coefficients that quantify distinct gradient-level interference sources (including self-induced interference and new-class interference) for each past class during an incremental training step.
If this is right
- Imbalanced forgetting can be anticipated before the end of each incremental step by inspecting the three coefficients.
- Mitigation strategies can target reduction of class-wise disparities in the identified interference sources.
- Interventions focused on the self-induced interference coefficient are likely to have the largest effect on balancing forgetting.
- Because the self-induced coefficient appears influenced by the new-class coefficient, managing new-class training dynamics may indirectly affect past-class self-interference.
Where Pith is reading between the lines
- The coefficients could be used inside rehearsal-selection routines to choose samples that reduce predicted imbalances before training begins.
- The same gradient-derived measures might serve as diagnostics in other rehearsal or regularization-based continual-learning regimes.
- Directly modulating one coefficient while holding the others fixed would provide a stronger test of whether it causally drives forgetting.
- Similar last-layer gradient summaries may reveal interference patterns in non-class-incremental settings such as task-incremental or domain-incremental learning.
Load-bearing premise
That the observed ability of the three coefficients to predict forgetting rankings establishes them as a mechanistic account of forgetting, even though prediction alone does not prove causation.
What would settle it
Compute the three coefficients at the start of an incremental step and then measure actual forgetting rankings after training; if the predicted order and the observed order disagree on a majority of classes across multiple runs, the predictive link fails.
Figures
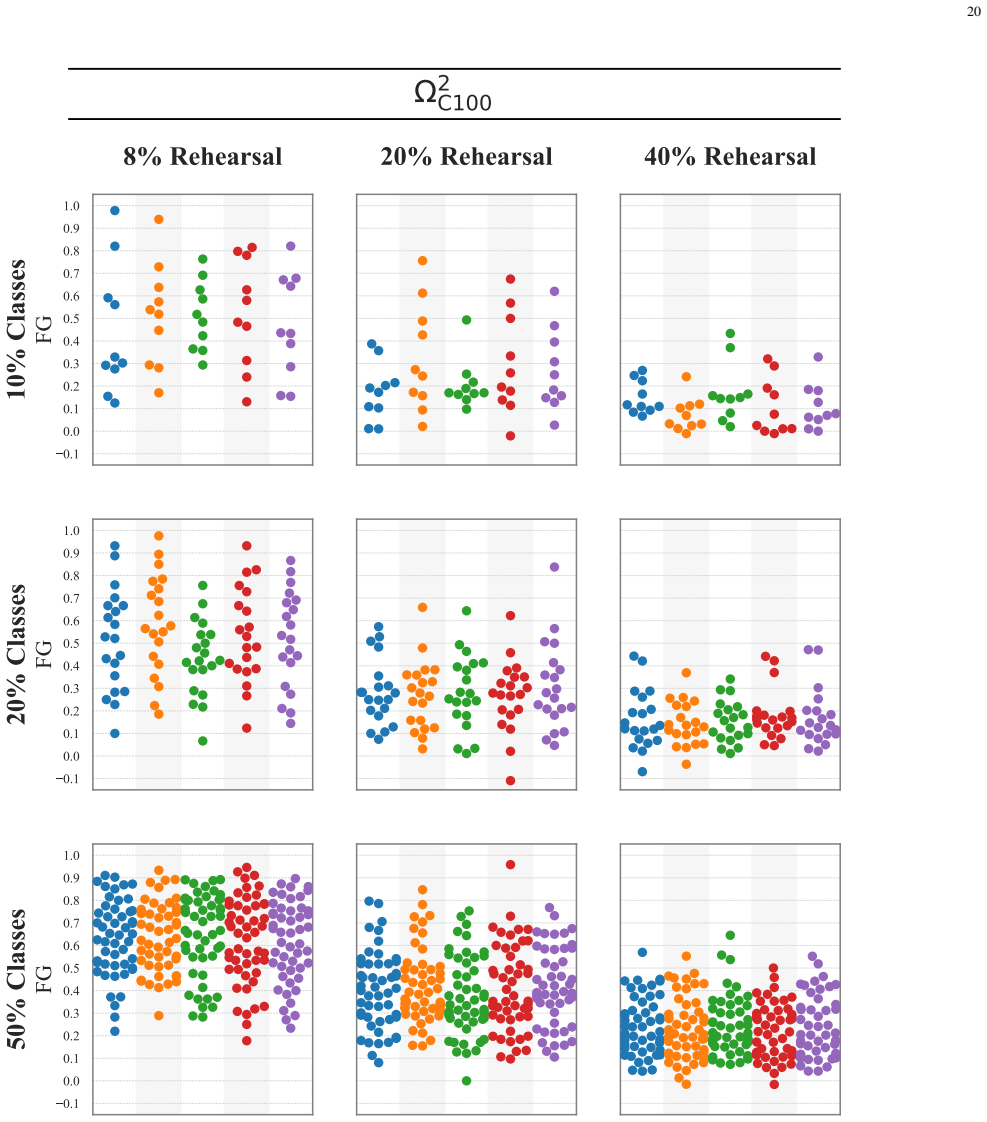
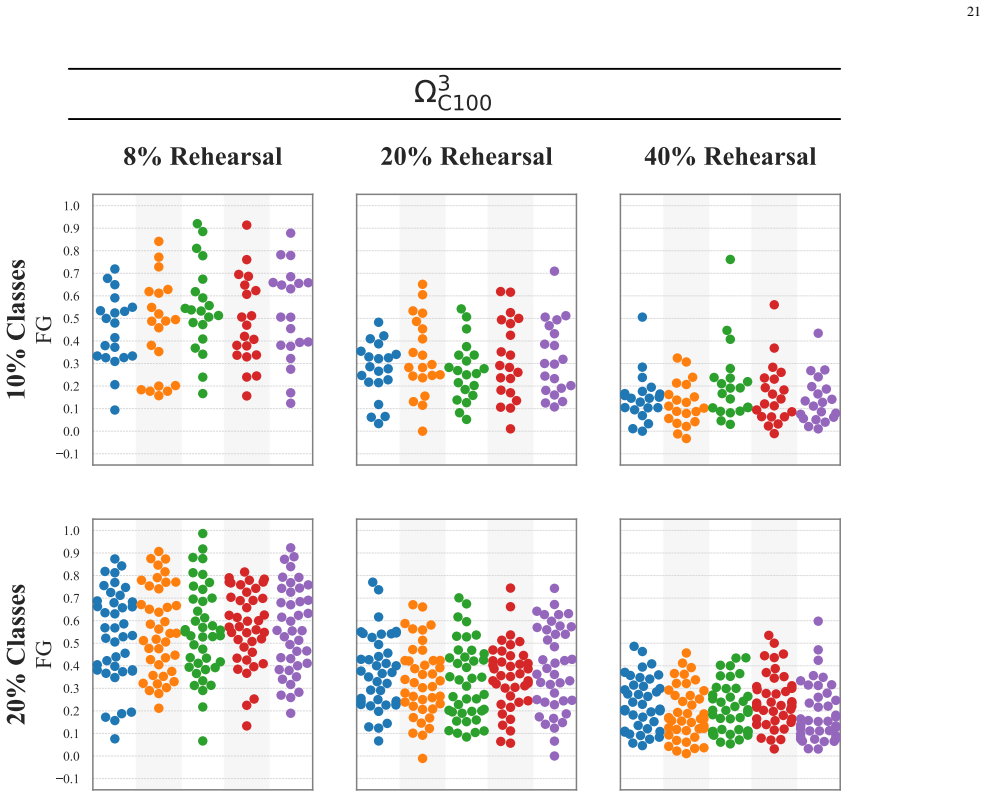
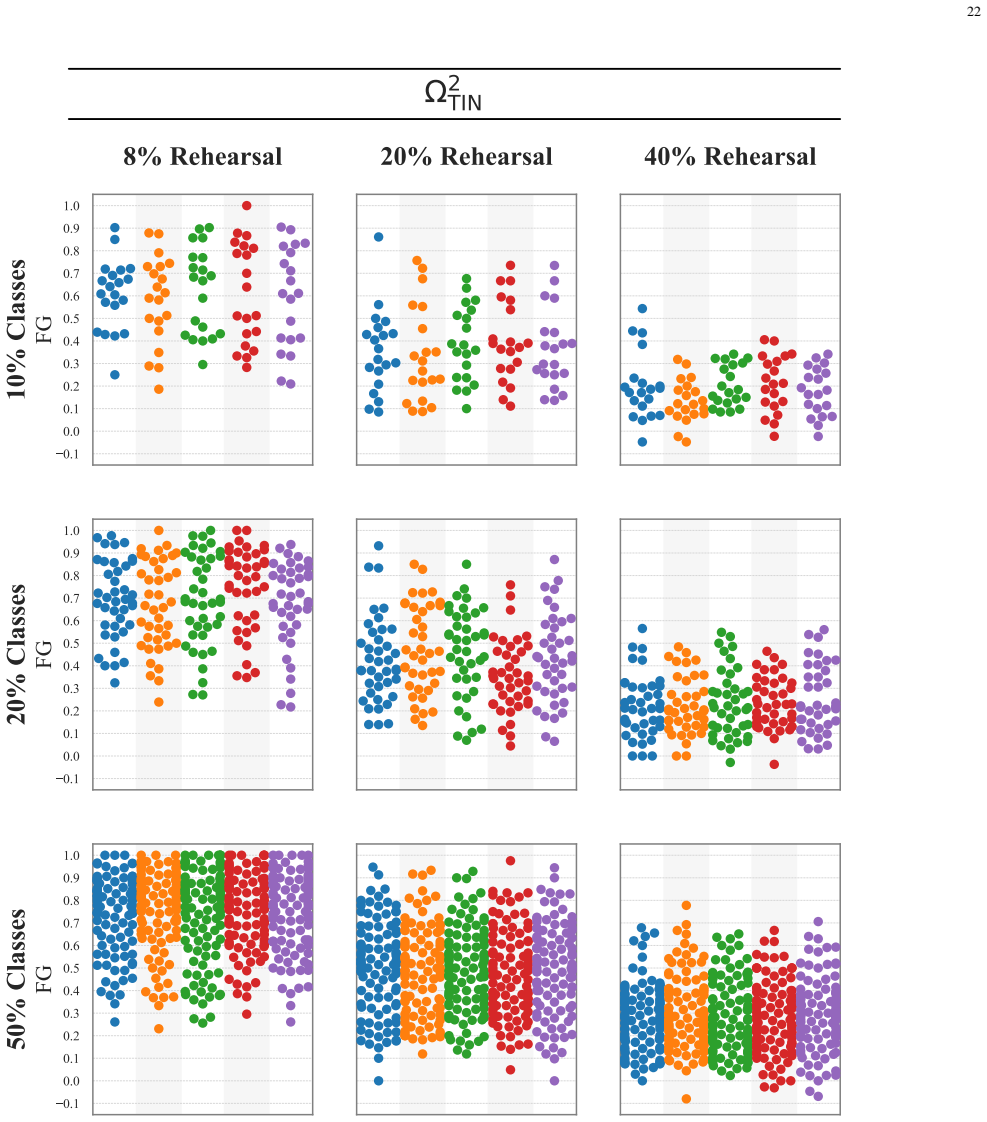
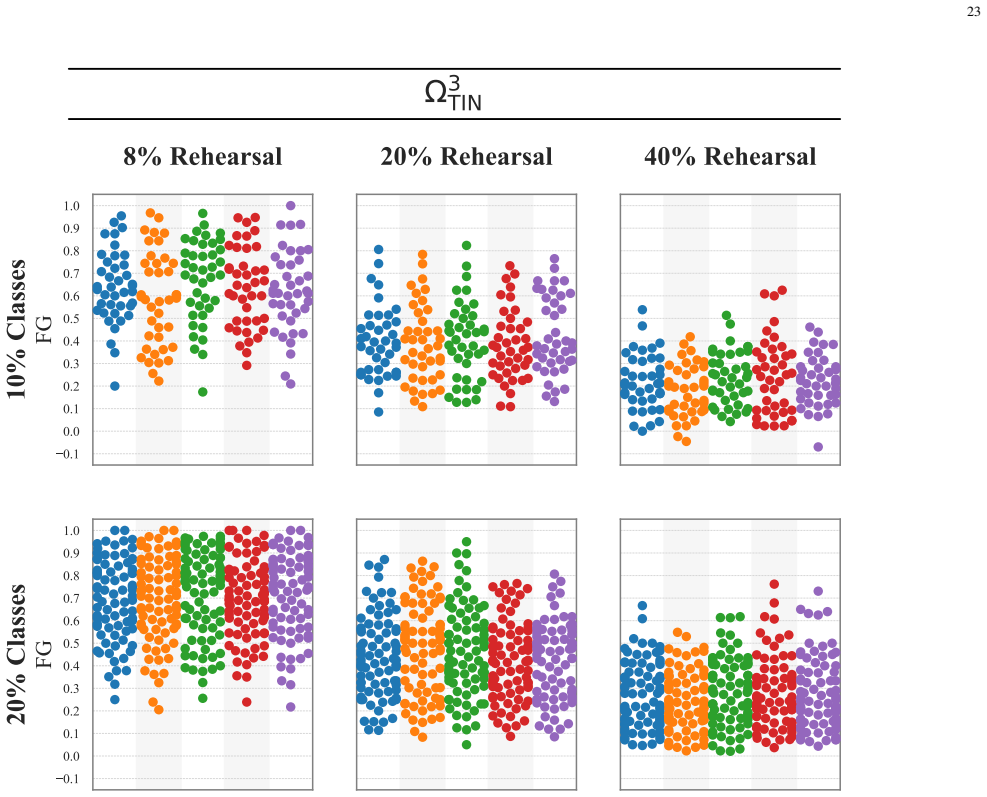
read the original abstract
Neural networks suffer from catastrophic forgetting in class-incremental learning (CIL) settings. Rehearsal$\unicode{x2013}$replaying a subset of past samples$\unicode{x2013}$is a well-established mitigation strategy. However, recent results suggest that, despite balanced rehearsal allocation, some classes are forgotten substantially more than others. Despite its relevance, this imbalanced forgetting phenomenon remains underexplored. This work shows that imbalanced forgetting arises systematically and severely in rehearsal-based CIL and investigates it extensively. Specifically, we construct, from a principled analysis, three last-layer coefficients that capture different gradient-level sources of interference affecting each past class during an incremental step. We then demonstrate that, together, they reliably predict how past classes will rank in terms of forgetting at the end of that step. While predictive performance alone does not establish causality, these results support the interpretation of the coefficients as a plausible mechanistic account linking last-layer gradient-level interactions during training to class-level forgetting outcomes. Notably, one coefficient$\unicode{x2013}$capturing self-induced interference$\unicode{x2013}$emerges as the strongest predictor, with controlled experiments providing evidence consistent with this coefficient being influenced by the new-class interference coefficient. Overall, our findings provide valuable insights and suggest promising directions for mitigating imbalanced forgetting by reducing class-wise disparities in the identified sources of interference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates imbalanced forgetting in rehearsal-based class-incremental learning (CIL), where some past classes are forgotten more than others despite balanced rehearsal. From a gradient-level analysis of the last layer, the authors derive three coefficients capturing distinct sources of interference (including self-induced interference) for each past class during an incremental step. They show that these coefficients, taken together, reliably predict the ranking of past classes by forgetting severity at the end of the step. Controlled experiments are presented as consistent with the self-induced interference coefficient being influenced by the new-class interference coefficient. The work frames the coefficients as a plausible mechanistic account without claiming that predictive performance establishes causality.
Significance. If the reported predictive relations hold under the stated controls, the paper supplies a concrete, gradient-derived lens on a practically relevant but underexplored failure mode of rehearsal-based CIL. The explicit separation of three interference sources and the identification of self-induced interference as the strongest predictor constitute a clear, falsifiable contribution that can guide targeted mitigation strategies aimed at reducing class-wise disparities in those sources.
minor comments (3)
- [Abstract / §1] The abstract and introduction would benefit from an explicit statement of the precise definition of each of the three coefficients (e.g., the functional form involving gradients or logits) before the claim that they 'reliably predict' forgetting ranks; this would allow readers to assess the 'principled analysis' claim without first consulting later sections.
- [Experiments section / Tables] Figure captions and experimental tables should report the exact number of random seeds, the precise rehearsal buffer size relative to new-class size, and whether the rank-prediction metric is computed within each incremental step or aggregated across steps; these details are necessary to evaluate the robustness of the reported predictive performance.
- [Controlled experiments subsection] The controlled experiments that test influence between coefficients would be clearer if they included an ablation that isolates the new-class interference term while holding other factors fixed; the current description leaves open whether the observed consistency could arise from correlated but non-causal factors.
Simulated Author's Rebuttal
We thank the referee for the supportive summary, the recognition of the contribution, and the recommendation for minor revision. No major comments appear in the provided report.
Circularity Check
No significant circularity
full rationale
The paper derives three coefficients via gradient analysis on last-layer weights and then tests their ability to rank-order forgetting on held-out incremental steps. No equation reduces a reported prediction to a fitted parameter defined on the same data; no self-citation chain supplies the central claim; the derivation is presented as an independent mechanistic hypothesis whose predictive utility is evaluated empirically rather than by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
icarl: Incremental classifier and representation learning,
S. A. Rebuffi, A. Kolesnikov, G. Sperl, and C. H. Lampert, “icarl: Incremental classifier and representation learning,” inProceedings - 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, vol. 2017-January. Institute of Electrical and Electronics Engineers Inc., 2017, Conference Proceedings, pp. 5533–5542
2017
-
[2]
McCloskey and N
M. McCloskey and N. J. Cohen,Catastrophic interference in connection- ist networks: The sequential learning problem. Elsevier, 1989, vol. 24, pp. 109–165
1989
-
[3]
Connectionist models of recognition memory: constraints imposed by learning and forgetting functions,
R. Ratcliff, “Connectionist models of recognition memory: constraints imposed by learning and forgetting functions,”Psychological review, vol. 97, no. 2, p. 285, 1990
1990
-
[4]
An Empirical Investigation of Catastrophic Forgetting in Gradient-Based Neural Networks
I. J. Goodfellow, M. Mirza, D. Xiao, A. Courville, and Y . Bengio, “An empirical investigation of catastrophic forgetting in gradient-based neural networks,”arXiv preprint arXiv:1312.6211, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[5]
Catastrophic forgetting, rehearsal and pseudorehearsal,
A. Robins, “Catastrophic forgetting, rehearsal and pseudorehearsal,” Connection Science, vol. 7, no. 2, pp. 123–146, 1995
1995
-
[6]
Why there are complementary learning systems in the hippocampus and neocortex: insights from the successes and failures of connectionist models of learning and memory,
J. L. McClelland, B. L. McNaughton, and R. C. O’Reilly, “Why there are complementary learning systems in the hippocampus and neocortex: insights from the successes and failures of connectionist models of learning and memory,”Psychological review, vol. 102, no. 3, p. 419, 1995
1995
-
[7]
Hippocampal and neocortical contributions to memory: Advances in the complementary learning systems framework,
R. C. O’Reilly and K. A. Norman, “Hippocampal and neocortical contributions to memory: Advances in the complementary learning systems framework,”Trends in cognitive sciences, vol. 6, no. 12, pp. 505–510, 2002
2002
-
[8]
Comple- mentary learning systems,
R. C. O’Reilly, R. Bhattacharyya, M. D. Howard, and N. Ketz, “Comple- mentary learning systems,”Cognitive science, vol. 38, no. 6, pp. 1229– 1248, 2014
2014
-
[9]
Defying imbalanced forgetting in class incremental learning,
S. Xu, G. Meng, X. Nie, B. Ni, B. Fan, and S. Xiang, “Defying imbalanced forgetting in class incremental learning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, 2024, Conference Proceedings, pp. 16 211–16 219
2024
-
[10]
Gradient episodic memory for contin- ual learning,
D. Lopez-Paz and M. Ranzato, “Gradient episodic memory for contin- ual learning,” inAdvances in Neural Information Processing Systems, I. Guyon, R. Fergus, H. Wallach, H. Wallach, I. Guyon, S. V . N. Vishwanathan, U. von Luxburg, R. Garnett, S. V . N. Vishwanathan, S. Bengio, and R. Fergus, Eds., vol. 2017-December. Neural infor- mation processing systems...
2017
-
[11]
Ef- ficient lifelong learning with a-gem,
A. Chaudhry, R. Marc’Aurelio, M. Rohrbach, and M. Elhoseiny, “Ef- ficient lifelong learning with a-gem,” in7th International Conference on Learning Representations, ICLR 2019. International Conference on Learning Representations, ICLR, 2019, Conference Proceedings
2019
-
[12]
arXiv preprint arXiv:2007.07400 , year=
V . V . Ramasesh, E. Dyer, and M. Raghu, “Anatomy of catastrophic forgetting: Hidden representations and task semantics,”arXiv preprint arXiv:2007.07400, 2020
-
[13]
Maintaining dis- crimination and fairness in class incremental learning,
B. Zhao, X. Xiao, G. Gan, B. Zhang, and S.-T. Xia, “Maintaining dis- crimination and fairness in class incremental learning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, Conference Proceedings, pp. 13 208–13 217
2020
-
[14]
Large scale incremental learning,
Y . Wu, Y . Chen, L. Wang, Y . Ye, Z. Liu, Y . Guo, and Y . Fu, “Large scale incremental learning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, Conference Proceedings, pp. 374–382
2019
-
[15]
Ss- il: Separated softmax for incremental learning,
H. Ahn, J. Kwak, S. Lim, H. Bang, H. Kim, and T. Moon, “Ss- il: Separated softmax for incremental learning,” inProceedings of the IEEE/CVF International conference on computer vision, 2021, Confer- ence Proceedings, pp. 844–853
2021
-
[16]
Scail: Classifier weights scaling for class incremental learning,
E. Belouadah and A. Popescu, “Scail: Classifier weights scaling for class incremental learning,” inProceedings of the IEEE/CVF winter confer- ence on applications of computer vision, 2020, Conference Proceedings, pp. 1266–1275
2020
-
[17]
Learning multiple layers of features from tiny images,
A. Krizhevsky and G. Hinton, “Learning multiple layers of features from tiny images,” 2009
2009
-
[18]
Theory on forgetting and generalization of continual learning,
S. Lin, P. Ju, Y . Liang, and N. Shroff, “Theory on forgetting and generalization of continual learning,” inInternational Conference on Machine Learning. PMLR, 2023, Conference Proceedings, pp. 21 078– 21 100
2023
-
[19]
Optimal task order for continual learning of multiple tasks,
Z. Li and N. Hiratani, “Optimal task order for continual learning of multiple tasks,” inForty-second International Conference on Machine Learning, Conference Proceedings
-
[20]
Tiny imagenet visual recognition challenge,
Y . Le and X. Yang, “Tiny imagenet visual recognition challenge,”CS 231N, vol. 7, no. 7, p. 3, 2015
2015
-
[21]
Rehearsal revealed: The limits and merits of revisiting samples in continual learning,
E. Verwimp, M. De Lange, and T. Tuytelaars, “Rehearsal revealed: The limits and merits of revisiting samples in continual learning,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, Conference Proceedings, pp. 9385–9394
2021
-
[22]
Multi-layer re- hearsal feature augmentation for class-incremental learning,
B. Zheng, D.-W. Zhou, H.-J. Ye, and D.-C. Zhan, “Multi-layer re- hearsal feature augmentation for class-incremental learning,” inForty- first International Conference on Machine Learning, 2024, Conference Proceedings
2024
-
[23]
Improved sample complexities for deep neural networks and robust classification via an all-layer margin,
C. Wei and T. Ma, “Improved sample complexities for deep neural networks and robust classification via an all-layer margin,” inInter- national Conference on Learning Representations, 2020, Conference Proceedings
2020
-
[24]
New insights on reducing abrupt representation change in online continual learning,
L. Caccia, R. Aljundi, N. Asadi, T. Tuytelaars, J. Pineau, and E. Belilovsky, “New insights on reducing abrupt representation change in online continual learning,” inICLR 2022 - 10th Conference on Learning Representations, 2022, Conference Proceedings
2022
-
[25]
Continual learning by modeling intra-class variation,
L. Yu, T. Hu, H. Lanqing, Z. Liu, A. Weller, and W. Liu, “Continual learning by modeling intra-class variation,”Transactions on Machine Learning Research, 2023
2023
-
[26]
Continual learning in the teacher-student setup: Impact of task similarity,
S. Lee, S. Goldt, and A. Saxe, “Continual learning in the teacher-student setup: Impact of task similarity,” inInternational Conference on Machine Learning. PMLR, 2021, Conference Proceedings, pp. 6109–6119
2021
-
[27]
The joint effect of task similarity and overparameterization on catastrophic forgetting–an analytical model,
D. Goldfarb, I. Evron, N. Weinberger, D. Soudry, and P. Hand, “The joint effect of task similarity and overparameterization on catastrophic forgetting–an analytical model,” inICLR 2024 - 12th International Con- ference on Learning Representations, 2024, Conference Proceedings
2024
-
[28]
How catastrophic can catastrophic forgetting be in linear regression?
I. Evron, E. Moroshko, R. Ward, N. Srebro, and D. Soudry, “How catastrophic can catastrophic forgetting be in linear regression?” inCon- ference on Learning Theory. PMLR, 2022, Conference Proceedings, pp. 4028–4079
2022
-
[29]
End-to-end incremental learning,
F. M. Castro, M. J. Mar ´ın-Jim´enez, N. Guil, C. Schmid, and K. Alahari, “End-to-end incremental learning,” inProceedings of the European conference on computer vision (ECCV), 2018, Conference Proceedings, pp. 233–248
2018
-
[30]
Siesta: Efficient online continual learning with sleep,
M. Y . Harun, J. Gallardo, T. L. Hayes, R. Kemker, and C. Kanan, “Siesta: Efficient online continual learning with sleep,”arXiv preprint arXiv:2303.10725, 2023
-
[31]
Gra- dient surgery for multi-task learning,
T. Yu, S. Kumar, A. Gupta, S. Levine, K. Hausman, and C. Finn, “Gra- dient surgery for multi-task learning,”Advances in neural information processing systems, vol. 33, pp. 5824–5836, 2020
2020
-
[32]
Stochastic first-and zeroth-order methods for nonconvex stochastic programming,
S. Ghadimi and G. Lan, “Stochastic first-and zeroth-order methods for nonconvex stochastic programming,”SIAM journal on optimization, vol. 23, no. 4, pp. 2341–2368, 2013
2013
-
[33]
Class-incremental learning: A survey,
D.-W. Zhou, Q.-W. Wang, Z.-H. Qi, H.-J. Ye, D.-C. Zhan, and Z. Liu, “Class-incremental learning: A survey,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[34]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in2009 IEEE conference on computer vision and pattern recognition. Ieee, 2009, Conference Proceedings, pp. 248–255
2009
-
[35]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, Conference Proceedings, pp. 770–778
2016
-
[36]
Gelman and J
A. Gelman and J. Hill,Data analysis using regression and multi- level/hierarchical models. Cambridge university press, 2007
2007
-
[37]
Memory-efficient incremental learning through feature adaptation,
A. Iscen, J. Zhang, S. Lazebnik, and C. Schmid, “Memory-efficient incremental learning through feature adaptation,” inComputer Vi- sion–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XVI 16. Springer, 2020, Conference Proceedings, pp. 699–715
2020
-
[38]
Memory-efficient class- incremental learning for image classification,
H. Zhao, H. Wang, Y . Fu, F. Wu, and X. Li, “Memory-efficient class- incremental learning for image classification,”IEEE Transactions on Neural Networks and Learning Systems, vol. 33, no. 10, pp. 5966–5977, 2021
2021
-
[39]
Continual learning with deep generative replay,
H. Shin, J. K. Lee, J. Kim, and J. Kim, “Continual learning with deep generative replay,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[40]
Learning to remember: A synaptic plasticity driven framework for continual learning,
O. Ostapenko, M. Puscas, T. Klein, P. Jahnichen, and M. Nabi, “Learning to remember: A synaptic plasticity driven framework for continual learning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, Conference Proceedings, pp. 11 321–11 329
2019
-
[41]
Ib-drr-incremental learning with information-back discrete representation replay,
J. Jiang, E. Cetin, and O. Celiktutan, “Ib-drr-incremental learning with information-back discrete representation replay,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, Conference Proceedings, pp. 3533–3542
2021
-
[42]
Class-incremental learn- ing using diffusion model for distillation and replay,
Q. Jodelet, X. Liu, Y . J. Phua, and T. Murata, “Class-incremental learn- ing using diffusion model for distillation and replay,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, Conference Proceedings, pp. 3425–3433
2023
-
[43]
Distilling the Knowledge in a Neural Network
G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,”arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[44]
Learning without forgetting,
Z. Li and D. Hoiem, “Learning without forgetting,”IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 12, pp. 2935– 2947, 2017
2017
-
[45]
Learning a unified classifier incrementally via rebalancing,
S. Hou, X. Pan, C. C. Loy, Z. Wang, and D. Lin, “Learning a unified classifier incrementally via rebalancing,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, Conference Proceedings, pp. 831–839
2019
-
[46]
Dark experience for general continual learning: a strong, simple baseline,
P. Buzzega, M. Boschini, A. Porrello, D. Abati, and S. Calderara, “Dark experience for general continual learning: a strong, simple baseline,” Advances in neural information processing systems, vol. 33, pp. 15 920– 15 930, 2020
2020
-
[47]
Der: Dynamically expandable representation for class incremental learning,
S. Yan, J. Xie, and X. He, “Der: Dynamically expandable representation for class incremental learning,” inProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, 2021, Conference Proceedings, pp. 3014–3023
2021
-
[48]
Foster: Feature boosting and compression for class-incremental learning,
F.-Y . Wang, D.-W. Zhou, H.-J. Ye, and D.-C. Zhan, “Foster: Feature boosting and compression for class-incremental learning,” inEuropean conference on computer vision. Springer, 2022, Conference Proceed- ings, pp. 398–414
2022
-
[49]
A model or 603 exemplars: Towards memory-efficient class-incremental learning,
D.-W. Z. Zhan, Q.-W. Wang, H.-J. Ye, and De-Chuan, “A model or 603 exemplars: Towards memory-efficient class-incremental learning,” inICLR 2023 - 11th Conference on Learning Representations, 2023, Conference Proceedings
2023
-
[50]
Riemannian walk for incremental learning: Understanding forgetting and intransi- gence,
A. Chaudhry, P. K. Dokania, T. Ajanthan, and P. H. Torr, “Riemannian walk for incremental learning: Understanding forgetting and intransi- gence,” inProceedings of the European conference on computer vision (ECCV), 2018, Conference Proceedings, pp. 532–547
2018
-
[51]
Rainbow memory: Continual learning with a memory of diverse samples,
J. Bang, H. Kim, Y . Yoo, J.-W. Ha, and J. Choi, “Rainbow memory: Continual learning with a memory of diverse samples,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, Conference Proceedings, pp. 8218–8227
2021
-
[52]
Gradient based sample selection for online continual learning,
R. Aljundi, M. Lin, B. Goujaud, and Y . Bengio, “Gradient based sample selection for online continual learning,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[53]
Introduction to core-sets: an updated survey,
D. Feldman, “Introduction to core-sets: an updated survey,”arXiv preprint arXiv:2011.09384, 2020
-
[54]
Gcr: Gradient coreset based replay buffer selection for continual learning,
R. Tiwari, K. Killamsetty, R. Iyer, and P. Shenoy, “Gcr: Gradient coreset based replay buffer selection for continual learning,” inProceedings of 15 the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, Conference Proceedings, pp. 99–108
2022
-
[55]
Anempiricalstudyofexampleforgettingduring deep neural network learning
M. Toneva, A. Sordoni, R. T. d. Combes, A. Trischler, Y . Bengio, and G. J. Gordon, “An empirical study of example forgetting during deep neural network learning,”arXiv preprint arXiv:1812.05159, 2018
-
[56]
Example forgetting and rehearsal in continual learning,
B. Benk ˝o, “Example forgetting and rehearsal in continual learning,” Pattern Recognition Letters, vol. 179, pp. 65–72, 2024
2024
-
[57]
Coresets via bilevel optimization for continual learning and streaming,
Z. Borsos, M. Mutny, and A. Krause, “Coresets via bilevel optimization for continual learning and streaming,”Advances in neural information processing systems, vol. 33, pp. 14 879–14 890, 2020
2020
-
[58]
Sgdr: Stochastic gradient descent with warm restarts,
I. Loshchilov and F. Hutter, “Sgdr: Stochastic gradient descent with warm restarts,” in5th International Conference on Learning Repre- sentations, ICLR 2017 - Conference Track Proceedings. International Conference on Learning Representations, ICLR, 2017, Conference Pro- ceedings
2017
-
[59]
Better bootstrap confidence intervals,
B. Efron, “Better bootstrap confidence intervals,”Journal of the Amer- ican statistical Association, vol. 82, no. 397, pp. 171–185, 1987
1987
-
[60]
Some heteroskedasticity-consistent covariance matrix estimators with improved finite sample properties,
J. G. MacKinnon and H. White, “Some heteroskedasticity-consistent covariance matrix estimators with improved finite sample properties,” Journal of econometrics, vol. 29, no. 3, pp. 305–325, 1985. APPENDIXA REHEARSAL-BASEDAPPROACHES IN CLASS-INCREMENTALLEARNING In addition to the standard formulation of rehearsal considered in the main body of this paper (...
1985
-
[61]
FOSTER [48] improves ef- ficiency by employing a model compression process based on knowledge distillation [43]
introduces a new backbone at each incremental step and aggregates the features from all backbones, which are then passed to a shared final classifier. FOSTER [48] improves ef- ficiency by employing a model compression process based on knowledge distillation [43]. MEMO [49] further optimizes the expansion protocol by selectively expanding only specialized ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.