Exploring Bottlenecks in VLM-LLM Navigation: How 3D Scene Understanding Capability Impacts Zero-Shot VLN
Pith reviewed 2026-06-30 20:51 UTC · model grok-4.3
The pith
3D perception accuracy in zero-shot VLN reaches diminishing returns after a moderate threshold, capping gains from pixel-level precision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
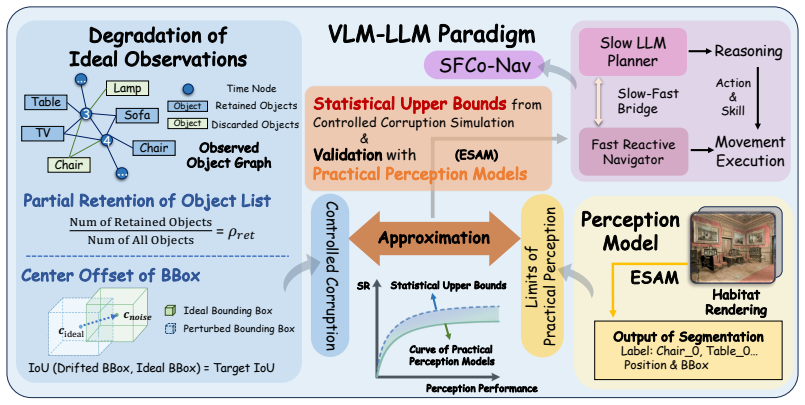
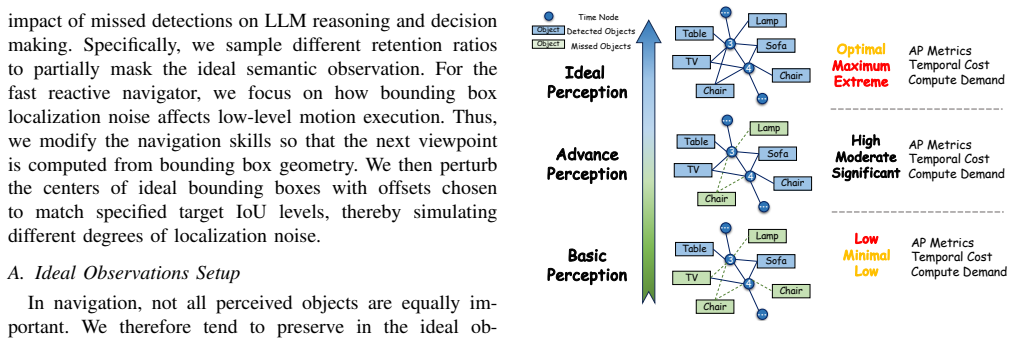
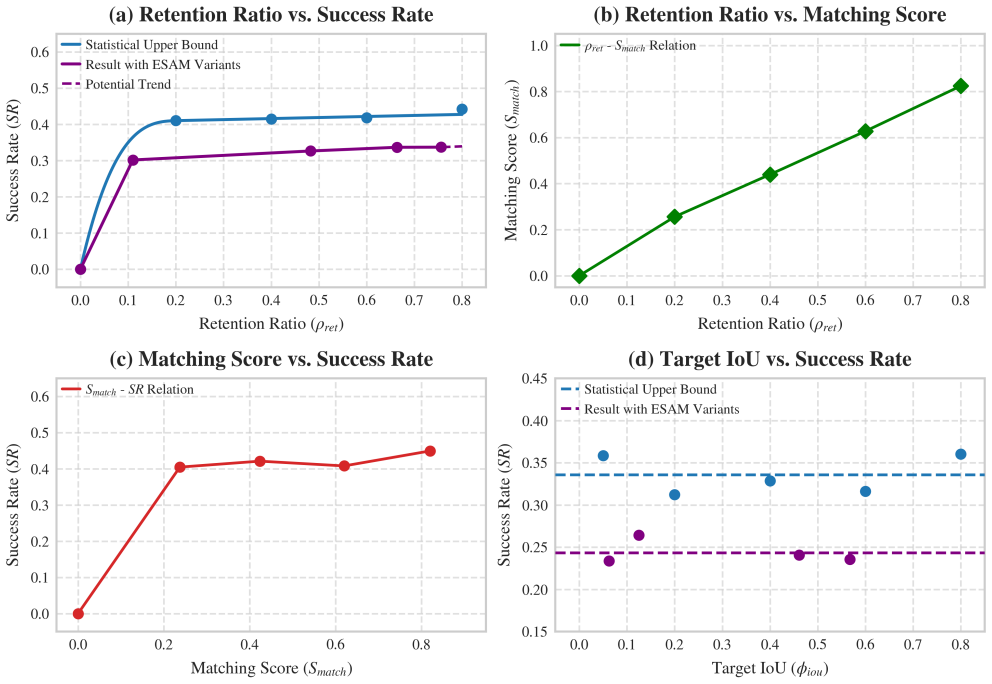
Based on typical VLM-LLM frameworks, the paper proposes statistical success rate upper bounds for the slow LLM planner relying on topological mapping semantics and the fast reactive navigator using spatial coordinates and bounding boxes. Evaluations with state-of-the-art 3D scene understanding models validate the bounds and reveal a perception saturation phenomenon in which further accuracy gains beyond a threshold produce diminishing returns in navigation success. The findings indicate that 3D scene understanding for VLN should shift priority from strict pixel-level precision to navigation-relevant core vocabularies and accurate bounding box proportions.
What carries the argument
statistical success rate upper bounds on the LLM planner (topological mapping semantics) and reactive navigator (spatial coordinates and bounding boxes) subsystems
If this is right
- VLN success rates remain limited by 3D perception quality up to the identified saturation threshold.
- Accuracy improvements beyond moderate levels deliver negligible additional navigation benefit.
- Perception models for navigation should target core vocabularies and bounding-box fidelity rather than pixel-level detail.
- Embodied systems can meet real-time limits by relaxing demands for high-precision 3D reconstruction.
Where Pith is reading between the lines
- Specialized perception training on navigation vocabularies could reach required accuracy with lower compute cost.
- The saturation pattern may appear in other embodied tasks such as object manipulation or exploration.
- Hybrid planners could adapt their reliance on perception quality in real time using the derived bounds.
Load-bearing premise
The proposed statistical success rate upper bounds for the slow LLM planner and fast reactive navigator correctly capture the limiting impact of 3D scene understanding on overall VLN performance without additional unstated modeling assumptions about subsystem independence or error propagation.
What would settle it
Navigation trials that increase 3D perception accuracy past the reported saturation threshold and record sustained large gains in success rate would falsify the diminishing-returns claim.
Figures

read the original abstract
Zero-shot vision-and-language navigation (VLN) has gained significant attention due to its minimal data collection costs and inherent generalization. This paradigm is typically driven by the integration of pre-trained Vision-Language Models (VLMs) and Large Language Models (LLMs), where VLMs construct 3D scene graphs while LLMs handle high-level reasoning and decision-making. However, a critical bottleneck exists in this system: current 3D perception models prioritize pixel-level accuracy, directly conflicting with the strict computational limits and real-time efficiency demanded by embodied navigation. To address this gap, this paper quantifies the actual impact of 3D scene understanding capability on VLN performance. Based on typical VLM-LLM frameworks, we propose statistical success rate (SR) upper bounds for two core subsystems: 1) the slow LLM planner, which relies on topological mapping semantics, and 2) the fast reactive navigator, which utilizes spatial coordinates and bounding boxes to execute LLM decisions. Evaluations using state-of-the-art 3D scene understanding models validate our proposed bounds and reveal a perception saturation phenomenon, indicating that improvements in perception accuracy beyond a certain threshold yield diminishing returns in navigation success. Our findings suggest that 3D scene understanding for VLN should pivot away from strict pixel-level precision, prioritizing instead navigation-relevant core vocabularies and accurate bounding box proportions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates bottlenecks in zero-shot VLN within VLM-LLM frameworks. It proposes statistical success rate (SR) upper bounds separately for the slow LLM planner (relying on topological mapping semantics) and the fast reactive navigator (using spatial coordinates and bounding boxes). Evaluations with state-of-the-art 3D scene understanding models are claimed to validate these bounds and demonstrate a perception saturation phenomenon, where accuracy improvements beyond a threshold yield diminishing returns in navigation success. The authors conclude that 3D scene understanding for VLN should prioritize navigation-relevant core vocabularies and accurate bounding box proportions over strict pixel-level precision.
Significance. If the statistical bounds are shown to be valid under explicit modeling assumptions, the work offers a quantitative lens on perception-navigation trade-offs that could usefully redirect research toward task-specific rather than generic 3D perception models. The saturation finding, if robust, would be a concrete contribution to embodied AI efficiency discussions. The manuscript does not ship machine-checked proofs or fully reproducible code, but the empirical validation with SOTA models is a positive element if the underlying derivations hold.
major comments (2)
- [Abstract / bounds derivation] Abstract and methods (bounds proposal): The statistical SR upper bounds are defined separately for the LLM planner and reactive navigator without any demonstration that the subsystems are statistically independent or that error propagation between them (via shared VLM features) is negligible. This modeling step is load-bearing for both the saturation claim and the policy recommendation; if perception errors are correlated, the separate bounds become loose or invalid.
- [Evaluations] Evaluation section: The claim that evaluations 'validate our proposed bounds' and reveal saturation is presented without details on how the bounds are computed from perception metrics, whether parameters were fitted post-hoc, or any sensitivity analysis to the independence assumption. This leaves open the possibility that the observed diminishing returns are an artifact of the bound construction rather than an empirical phenomenon.
minor comments (2)
- [Introduction] Notation for the two subsystems (planner vs. navigator) should be introduced with explicit symbols early in the text to improve readability when the bounds are later referenced.
- [Abstract] The abstract states that current 3D perception models 'prioritize pixel-level accuracy' in conflict with real-time limits; a brief citation or quantitative example of this conflict would strengthen the motivation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below regarding the independence assumption in the bounds and the evaluation details. We will revise the manuscript to strengthen these aspects.
read point-by-point responses
-
Referee: [Abstract / bounds derivation] Abstract and methods (bounds proposal): The statistical SR upper bounds are defined separately for the LLM planner and reactive navigator without any demonstration that the subsystems are statistically independent or that error propagation between them (via shared VLM features) is negligible. This modeling step is load-bearing for both the saturation claim and the policy recommendation; if perception errors are correlated, the separate bounds become loose or invalid.
Authors: The separate bounds are derived from the distinct roles and input types of each subsystem (topological semantics for the planner vs. spatial coordinates/bounding boxes for the navigator), which is a standard modular decomposition in VLN literature. We agree that an explicit statement of the independence assumption and discussion of potential correlations through shared VLM features is warranted. In revision we will add a paragraph in Section 3 detailing the assumption, its justification based on processing stages, and a note that the bounds may be loose under strong correlation. revision: yes
-
Referee: [Evaluations] Evaluation section: The claim that evaluations 'validate our proposed bounds' and reveal saturation is presented without details on how the bounds are computed from perception metrics, whether parameters were fitted post-hoc, or any sensitivity analysis to the independence assumption. This leaves open the possibility that the observed diminishing returns are an artifact of the bound construction rather than an empirical phenomenon.
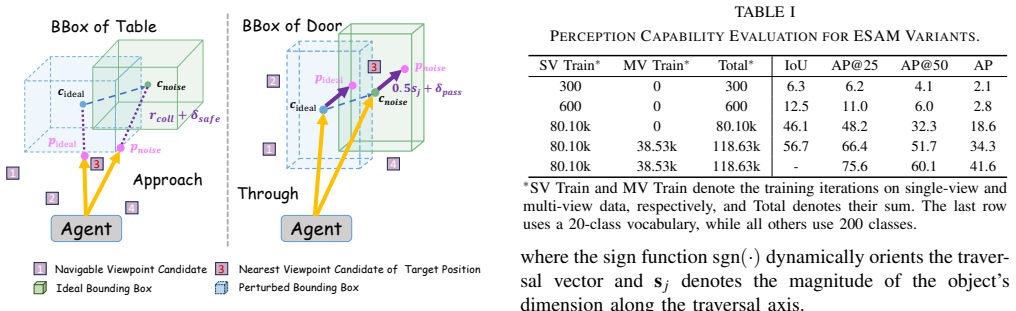
Authors: Bounds are obtained by substituting the empirical perception metrics (detection accuracy, IoU, etc.) reported by each 3D model directly into the closed-form statistical expressions; no post-hoc parameter fitting occurs. We will revise the evaluation section to include the exact substitution steps, example calculations, and a sensitivity analysis that varies the correlation coefficient between subsystems to confirm the saturation trend persists. revision: yes
Circularity Check
No circularity: bounds proposed from framework structure and validated empirically
full rationale
The paper proposes statistical SR upper bounds for the slow LLM planner (topological semantics) and fast reactive navigator (spatial coordinates/bounding boxes) based on typical VLM-LLM frameworks, then validates them via evaluations with SOTA 3D models to identify saturation. No equations, fitted parameters, self-citations, or self-definitional reductions appear in the abstract or described claims; the bounds are presented as theoretical proposals whose validity is checked externally rather than derived from the target VLN performance by construction. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sensing, social, and motion intelligence in embodied navigation: A comprehensive survey,
C. Xiong, Y . Huang, F. Yu, C. Chen, Y . Wang, S. Xia, and L. Pei, “Sensing, social, and motion intelligence in embodied navigation: A comprehensive survey,”arXiv preprint arXiv:2508.15354, 2025
-
[2]
C. Xiong, L. Wei, X. Hu, K. Ma, Z. Xia, Z. Jiang, Z. Sun, and L. Pei, “Sfco-nav: Efficient zero-shot visual language navigation via collaboration of slow llm and fast attributed graph alignment,”arXiv preprint arXiv:2603.01477, 2026
-
[3]
Navcot: Boosting llm-based vision-and-language naviga- tion via learning disentangled reasoning,
B. Lin, Y . Nie, Z. Wei, J. Chen, S. Ma, J. Han, H. Xu, X. Chang, and X. Liang, “Navcot: Boosting llm-based vision-and-language naviga- tion via learning disentangled reasoning,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 47, no. 7, pp. 5945–5957, 2025
2025
-
[4]
Blip: Bootstrapping language- image pre-training for unified vision-language understanding and generation,
J. Li, D. Li, C. Xiong, and S. Hoi, “Blip: Bootstrapping language- image pre-training for unified vision-language understanding and generation,” inInternational conference on machine learning. PMLR, 2022, pp. 12 888–12 900
2022
-
[5]
NavGPT: Explicit reasoning in vision- and-language navigation with large language models,
G. Zhou, Y . Hong, and Q. Wu, “NavGPT: Explicit reasoning in vision- and-language navigation with large language models,” inProc. AAAI Conf. Artif. Intell. (AAAI). AAAI Press, 2024, pp. 849–857
2024
-
[6]
J. Li, D. Li, S. Savarese, and S. Hoi, “Blip-2: Bootstrapping language- image pre-training with frozen image encoders and large language models,”arXiv preprint arXiv:2301.12597, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
[Online]. Available: https://arxiv.org/abs/2303.08774
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
MapGPT: Map-guided prompting with adaptive path planning for vision-and- language navigation,
J. Chen, B. Lin, R. Xu, Z. Chai, X. Liang, and K.-Y . Wong, “MapGPT: Map-guided prompting with adaptive path planning for vision-and- language navigation,” inProc. Annu. Meet. Assoc. Comput. Linguist. (ACL). Bangkok, Thailand: Assoc. Comput. Linguist., 2024, pp. 9796–9810
2024
-
[10]
Open-nav: Exploring zero-shot vision-and-language naviga- tion in continuous environment with open-source llms,
Y . Qiao, W. Lyu, H. Wang, Z. Wang, Z. Li, Y . Zhang, M. Tan, and Q. Wu, “Open-nav: Exploring zero-shot vision-and-language naviga- tion in continuous environment with open-source llms,” inProc. IEEE Int. Conf. Robot. Autom. (ICRA), 2025
2025
-
[11]
Spatialbot: Precise spatial understanding with vision lan- guage models,
W. Cai, I. Ponomarenko, J. Yuan, X. Li, W. Yang, H. Dong, and B. Zhao, “Spatialbot: Precise spatial understanding with vision lan- guage models,” inProc. IEEE Int. Conf. Robot. Autom. (ICRA), 2025, pp. 9490–9498
2025
-
[12]
Recognize anything: A strong image tagging model,
Y . Zhang, X. Huang, J. Ma, Z. Li, Z. Luo, Y . Xie, Y . Qin, T. Luo, Y . Li, S. Liuet al., “Recognize anything: A strong image tagging model,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2024, pp. 1724–1732
2024
-
[13]
Fast r-cnn,
R. Girshick, “Fast r-cnn,” inProc. IEEE Int. Conf. Comput. Vis. (ICCV), 2015, pp. 1440–1448
2015
-
[14]
Embod- iedsam: Online segment any 3d thing in real time,
X. Xu, H. Chen, L. Zhao, Z. Wang, J. Zhou, and J. Lu, “Embod- iedsam: Online segment any 3d thing in real time,”arXiv preprint arXiv:2408.11811, 2024
-
[15]
Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments,
P. Andersonet al., “Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2018, pp. 3674–3683
2018
-
[16]
Habitat 2.0: Training home assistants to rearrange their habitat,
A. Szotet al., “Habitat 2.0: Training home assistants to rearrange their habitat,”arXiv preprint arXiv:2106.14405, 2021
-
[17]
Scannet: Richly-annotated 3d reconstructions of indoor scenes,
A. Dai, A. X. Chang, M. Savva, M. Halber, T. Funkhouser, and M. Nießner, “Scannet: Richly-annotated 3d reconstructions of indoor scenes,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2017, pp. 5828–5839
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.