Interestingness as an Inductive Heuristic for Future Compression Progress
Pith reviewed 2026-06-30 20:35 UTC · model grok-4.3
The pith
Expected future progress in compression depends exponentially on how recent the last breakthrough was.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
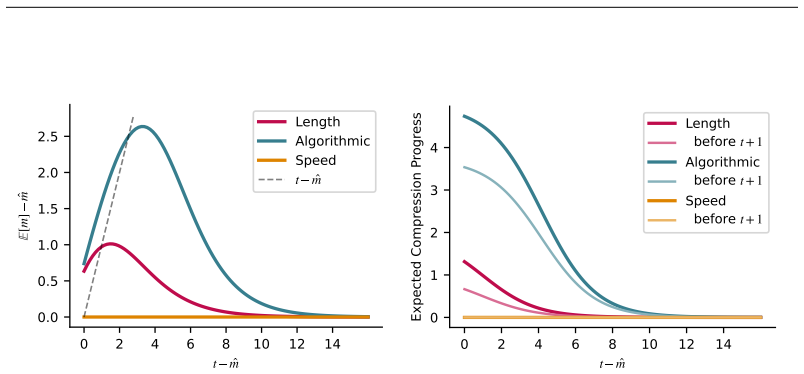
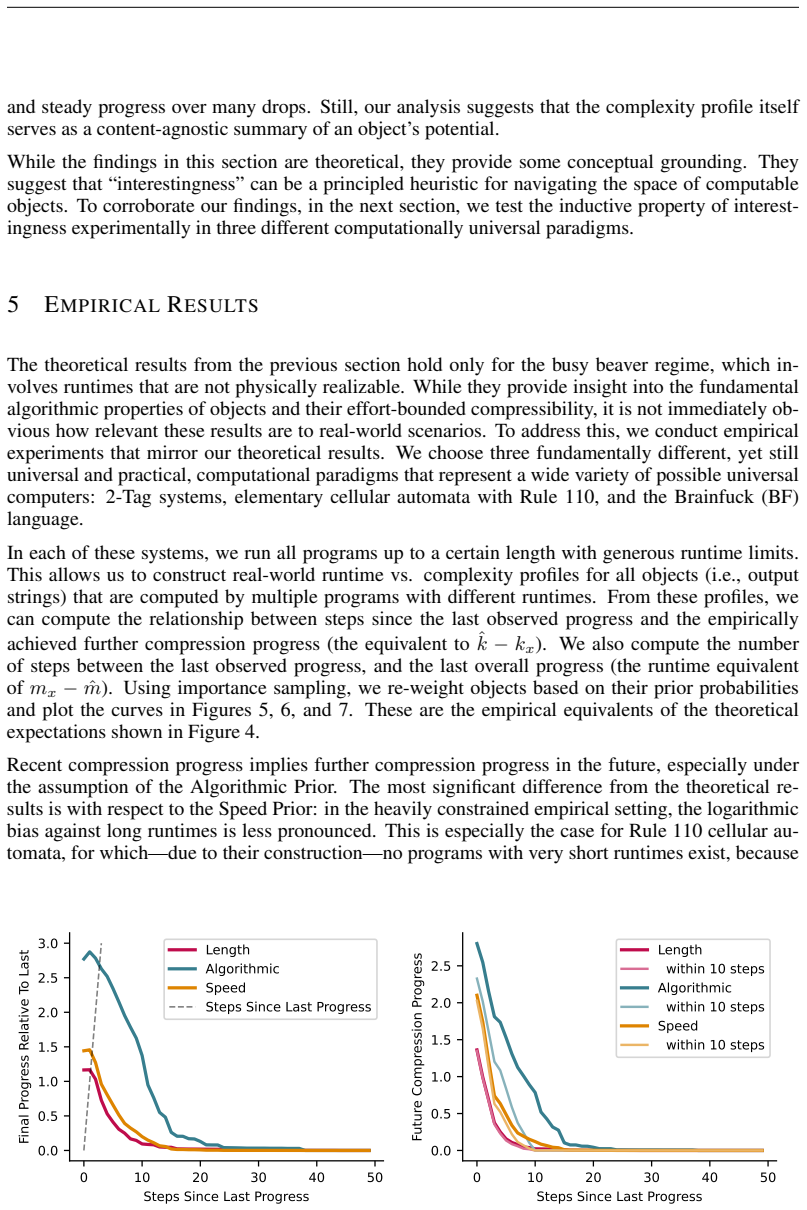
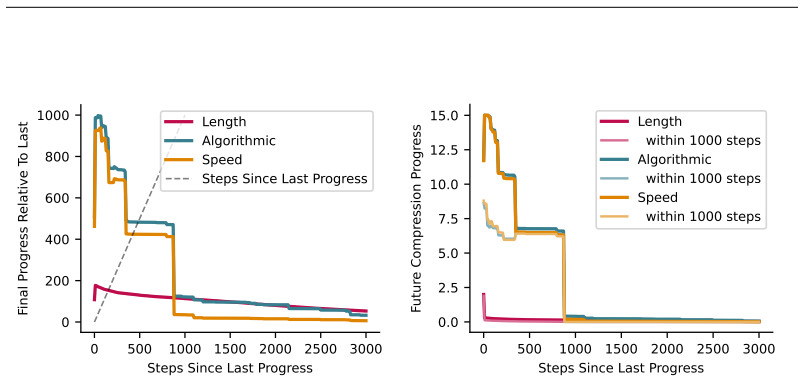
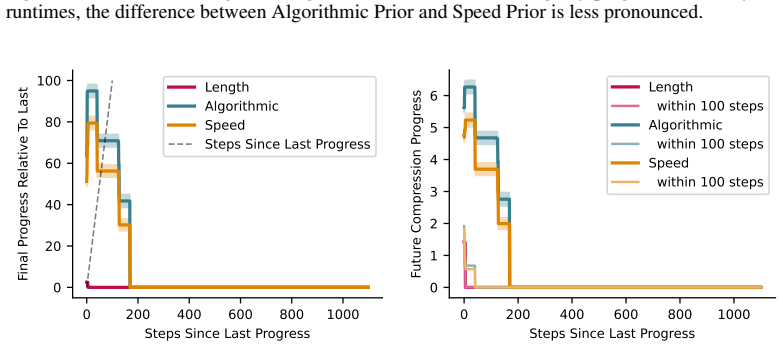
Interestingness, defined as the capacity for past progress to signal future discovery, is theoretically viable when analyzing complexity-runtime profiles under Length, Algorithmic, and Speed priors. Expected future progress depends exponentially on the recency of the last observed breakthrough, and the Algorithmic Prior yields a quadratic increase in expected discovery compared to the Length Prior for the same observed profile. This holds across three diverse universal computational paradigms.
What carries the argument
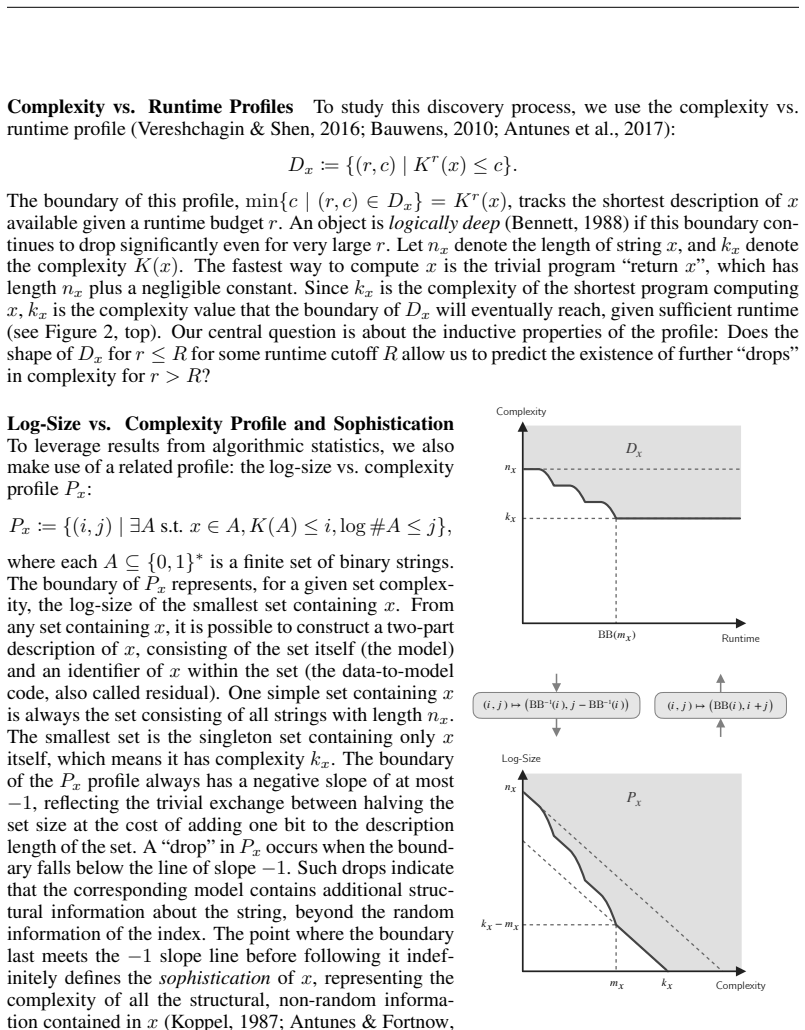
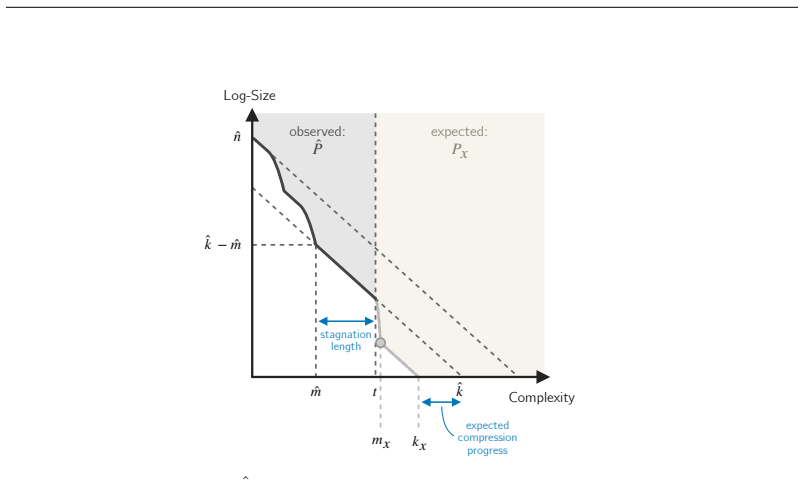
Complexity-runtime profiles analyzed under Length, Algorithmic, and Speed priors from Kolmogorov Complexity and Algorithmic Statistics, which serve as inductive heuristics for future compression progress.
If this is right
- Past breakthroughs signal exponentially higher expected future progress.
- The Algorithmic Prior is significantly more optimistic, predicting a quadratic increase in discoveries.
- Interestingness is predictable and empirically supported in multiple computational paradigms.
- Self-improving systems can use this heuristic to identify promising tasks.
Where Pith is reading between the lines
- If the priors match real discovery, AI agents could prioritize tasks based on recent progress patterns.
- This suggests a way to measure and exploit inductive bias in learning systems beyond the paper's scope.
- Extensions could test the model in real-world scientific discovery settings.
Load-bearing premise
The chosen Length, Algorithmic, and Speed priors correctly capture the inductive structure of interestingness across universal computational paradigms.
What would settle it
Measure actual future progress rates after breakthroughs of varying recency in a computational system and check if they follow the predicted exponential dependence on recency.
Figures

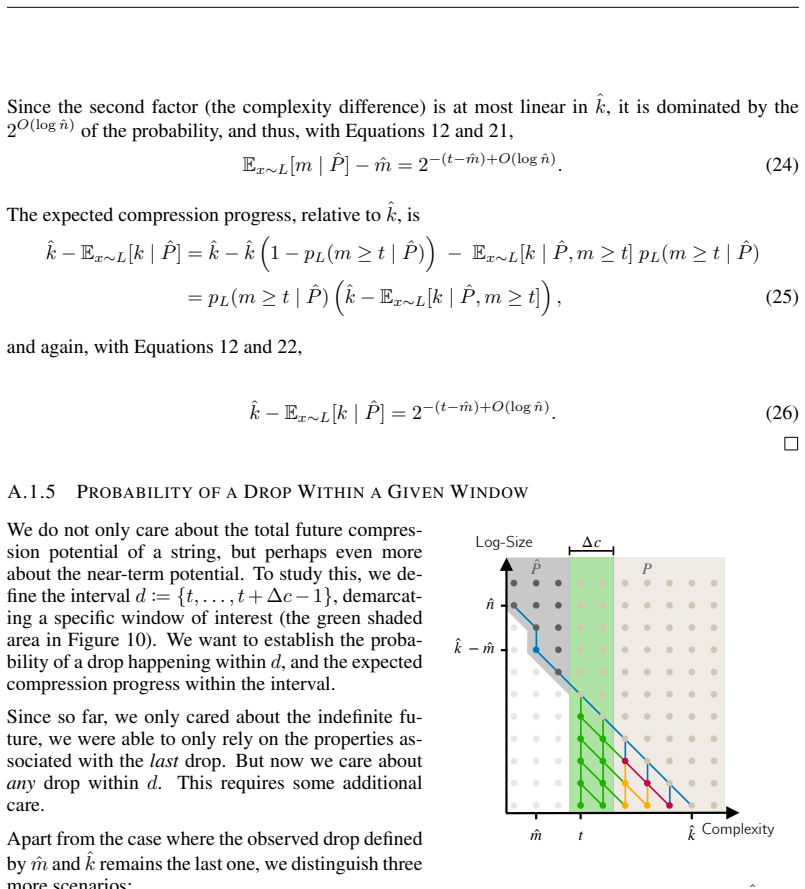

read the original abstract
One of the bottlenecks on the way towards recursively self-improving systems is the challenge of interestingness: the ability to prospectively identify which tasks or data hold the potential for future progress. We formalize interestingness as an inductive heuristic for future compression progress and investigate its predictability using tools from Kolmogorov Complexity and Algorithmic Statistics. By analyzing complexity-runtime profiles under Length, Algorithmic, and Speed priors, we demonstrate that the inductive property of interestingness -- the capacity for past progress to signal future discovery -- is theoretically viable and empirically supported. We prove that expected future progress depends exponentially on the recency of the last observed breakthrough. Furthermore, we show that the Algorithmic Prior is significantly more optimistic than the Length Prior, yielding a quadratic increase in expected discovery for the same observed profile. These findings are experimentally confirmed across three diverse universal computational paradigms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript formalizes interestingness as an inductive heuristic for future compression progress using tools from Kolmogorov complexity and algorithmic statistics. It analyzes complexity-runtime profiles under Length, Algorithmic, and Speed priors, claiming to prove that expected future progress depends exponentially on the recency of the last observed breakthrough and that the Algorithmic Prior produces a quadratic increase in expected discovery relative to the Length Prior for the same profile. These theoretical results are stated to be empirically confirmed across three universal computational paradigms.
Significance. If the alignment between the chosen priors and actual discovery dynamics can be independently established, the work would supply a formal, quantifiable basis for interestingness in the context of recursively self-improving systems, with the exponential recency dependence offering a concrete prediction about the temporal structure of progress. The comparison of priors and the cross-paradigm empirical component would strengthen the case for using algorithmic statistics to guide task selection, though the absence of sensitivity checks currently limits the generality of the claimed functional forms.
major comments (3)
- [Abstract] Abstract: The claimed proof that expected future progress depends exponentially on recency is obtained by re-applying the Length/Algorithmic/Speed priors that were used to generate the observed complexity-runtime profiles; because the inductive property is defined in terms of these same priors, the exponential form is a direct algebraic consequence of the modeling choice rather than an independent empirical signal. This is load-bearing for the central claim that interestingness is 'theoretically viable' as a heuristic.
- [Abstract] Abstract: The assertion that the Algorithmic Prior yields a quadratic increase in expected discovery over the Length Prior is likewise derived solely from the specific definitions of these priors applied to the same profiles, with no sensitivity analysis or alternative prior constructions (e.g., different universal machines or runtime weightings) provided to test whether the quadratic gain persists. This directly supports the strongest claim in the manuscript and requires independent justification.
- [Abstract] Abstract: The statement of 'experimental confirmation across three diverse universal computational paradigms' is presented without details on paradigm selection criteria, data-generation procedures, or controls for post-hoc fitting; given that the central functional forms depend on the priors, the empirical section must demonstrate that the observed profiles were not chosen to match the model predictions.
minor comments (1)
- [Abstract] The abstract refers to 'three diverse universal computational paradigms' without naming them; specifying the paradigms (e.g., Turing machines, lambda calculus, cellular automata) would improve immediate readability.
Simulated Author's Rebuttal
We thank the referee for the constructive report and the recommendation for major revision. We address each of the three major comments point-by-point below, providing clarifications on the theoretical derivations and empirical components while committing to targeted revisions where they strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract] The claimed proof that expected future progress depends exponentially on recency is obtained by re-applying the Length/Algorithmic/Speed priors that were used to generate the observed complexity-runtime profiles; because the inductive property is defined in terms of these same priors, the exponential form is a direct algebraic consequence of the modeling choice rather than an independent empirical signal. This is load-bearing for the central claim that interestingness is 'theoretically viable' as a heuristic.
Authors: We agree that the exponential dependence follows directly as an algebraic consequence once the inductive heuristic is formalized using the chosen priors. The manuscript's contribution is to show that this specific functional form (exponential decay with recency) emerges rigorously from the standard definitions in algorithmic information theory rather than being postulated ad hoc. This establishes theoretical viability within the framework. We will revise the abstract and introduction to explicitly state that the result is derived within the model and to clarify the distinction between the modeling assumptions and the derived prediction. revision: yes
-
Referee: [Abstract] The assertion that the Algorithmic Prior yields a quadratic increase in expected discovery over the Length Prior is likewise derived solely from the specific definitions of these priors applied to the same profiles, with no sensitivity analysis or alternative prior constructions (e.g., different universal machines or runtime weightings) provided to test whether the quadratic gain persists. This directly supports the strongest claim in the manuscript and requires independent justification.
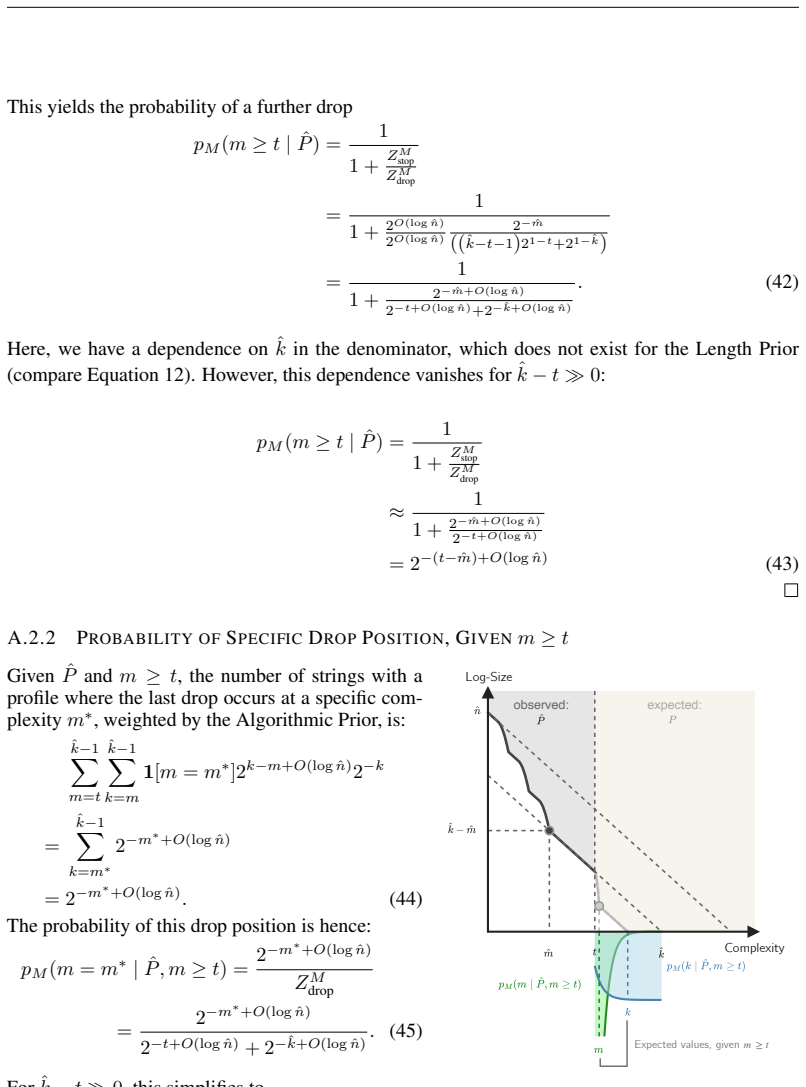
Authors: The quadratic relationship is obtained by explicit comparison of the expected values under the two priors on identical observed profiles, as stated in the manuscript. This comparison is exact for the standard definitions employed. We did not conduct sensitivity checks with alternative universal machines or weightings in the present work. We will add a limitations paragraph acknowledging that the quadratic gain is shown for the canonical priors and that generality under other constructions remains open for future investigation. revision: partial
-
Referee: [Abstract] The statement of 'experimental confirmation across three diverse universal computational paradigms' is presented without details on paradigm selection criteria, data-generation procedures, or controls for post-hoc fitting; given that the central functional forms depend on the priors, the empirical section must demonstrate that the observed profiles were not chosen to match the model predictions.
Authors: The full manuscript contains a dedicated experimental section (Section 4) that specifies the three paradigms (universal Turing machines, lambda calculus, and a register machine model), the independent generation of complexity-runtime profiles via exhaustive enumeration up to bounded size, and explicit controls (pre-specification of profile generation before prior application and cross-validation across paradigms) to guard against post-hoc fitting. The abstract summarizes these results. We will revise the abstract to briefly name the paradigms and direct readers to the experimental section for the full selection criteria and procedures. revision: yes
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Kolmogorov complexity and algorithmic probability provide the right formalization of inductive interestingness
- domain assumption The three universal computational paradigms are representative of general discovery processes
Reference graph
Works this paper leans on
-
[1]
Language Modeling Is Compression
Del´etang, G., Ruoss, A., Duquenne, P.-A., Catt, E., Genewein, T., Mattern, C., Grau-Moya, J., Wenliang, L. K., Aitchison, M., Orseau, L., et al. Language modeling is compression.arXiv preprint arXiv:2309.10668,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Faldor, M., Zhang, J., Cully, A., and Clune, J. Omni-epic: Open-endedness via models of human notions of interestingness with environments programmed in code.arXiv preprint arXiv:2405.15568,
-
[3]
Finzi, M., Qiu, S., Jiang, Y ., Izmailov, P., Kolter, J. Z., and Wilson, A. G. From entropy to epiplexity: Rethinking information for computationally bounded intelligence.arXiv preprint arXiv:2601.03220,
-
[4]
Herrmann, V ., Alcaide, E., Wand, M., and Schmidhuber, J. Multiple token divergence: Measuring and steering in-context computation density.arXiv preprint arXiv:2512.22944, 2025a. Herrmann, V ., Csord´as, R., and Schmidhuber, J. Measuring in-context computation complexity via hidden state prediction. InProceedings of the 42nd International Conference on Ma...
-
[5]
Jansma, A. and Hoel, E. Engineering emergence.arXiv preprint arXiv:2510.02649,
-
[6]
H., Houghton, B., Sampedro, R., Zhokhov, P., Baker, B., Ecoffet, A., Tang, J., et al
Kanitscheider, I., Huizinga, J., Farhi, D., Guss, W. H., Houghton, B., Sampedro, R., Zhokhov, P., Baker, B., Ecoffet, A., Tang, J., et al. Multi-task curriculum learning in a complex, visual, hard- exploration domain: Minecraft.arXiv preprint arXiv:2106.14876,
-
[7]
A., Kobayashi, S., Richards, B., Lajoie, G., Steger, A., Hutter, M., Manyika, J., et al
Meulemans, A., Nasser, R., Wołczyk, M., Weis, M. A., Kobayashi, S., Richards, B., Lajoie, G., Steger, A., Hutter, M., Manyika, J., et al. Embedded universal predictive intelligence: a coherent framework for multi-agent learning.arXiv preprint arXiv:2511.22226,
-
[8]
Snowbird’98, Utah, 1998; see also?
ftp://ftp.idsia.ch/pub/juergen/interest.ps.gz; extended abstract in Proc. Snowbird’98, Utah, 1998; see also?. Schmidhuber, J. Artificial curiosity based on discovering novel algorithmic predictability through coevolution. InProceedings of the 1999 congress on evolutionary computation-cec99 (cat. no. 99th8406), volume 3, pp. 1612–1618. IEEE,
1998
-
[9]
Formal theory of creativity, fun, and intrinsic motivation (1990-2010).IEEE Transactions on Autonomous Mental Development, 2(3):230–247,
Schmidhuber, J. Formal theory of creativity, fun, and intrinsic motivation (1990-2010).IEEE Transactions on Autonomous Mental Development, 2(3):230–247,
1990
-
[10]
Formal theory of creativity, fun, and intrinsic motivation (1990-2010)
ISSN 1943-0604. doi: 10.1109/TAMD.2010.2056368. 18 Schmidhuber, J. On learning to think: Algorithmic information theory for novel combinations of re- inforcement learning controllers and recurrent neural world models.Preprint arXiv:1511.09249,
-
[11]
and Zaslavsky, N
Tishby, N. and Zaslavsky, N. Deep learning and the information bottleneck principle.2015 IEEE Information Theory Workshop (ITW),
2015
-
[12]
Zhang, J., Lehman, J., Stanley, K. O., and Clune, J. Omni: Open-endedness via models of human notions of interestingness.ArXiv, abs/2306.01711,
-
[13]
semanticscholar.org/CorpusID:259064135
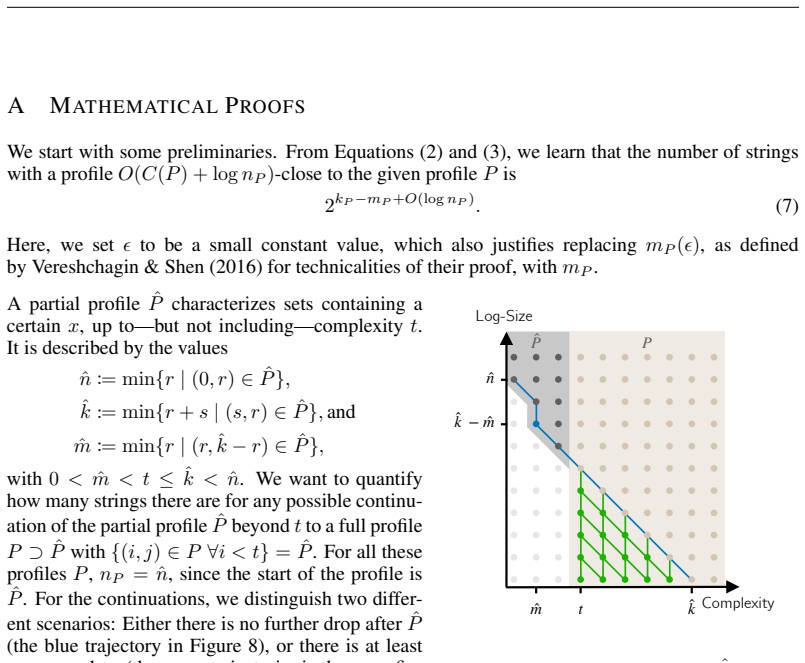
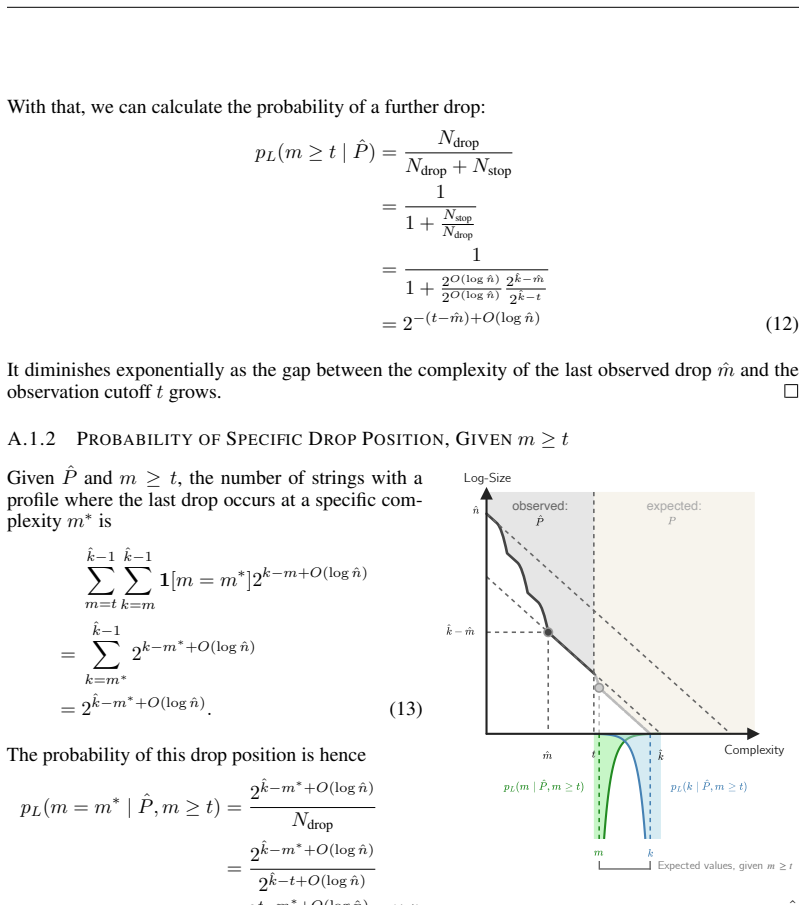
URLhttps://api. semanticscholar.org/CorpusID:259064135. 19 A MATHEMATICALPROOFS We start with some preliminaries. From Equations (2) and (3), we learn that the number of strings with a profileO(C(P) + logn P )-close to the given profilePis 2kP −mP +O(logn P ).(7) Here, we setϵto be a small constant value, which also justifies replacingm P (ϵ), as defined ...
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.