IFPV: An Integrated Multi-Agent Framework for Generative Operational Planning and High-Fidelity Plan Verification
Pith reviewed 2026-06-30 19:50 UTC · model grok-4.3
The pith
A multi-agent framework pairs hierarchical planning agents with an adversarial simulator to generate feasible operational plans and expose their weaknesses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
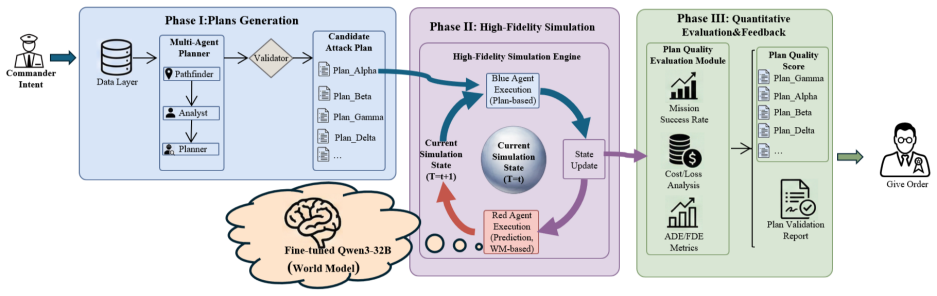
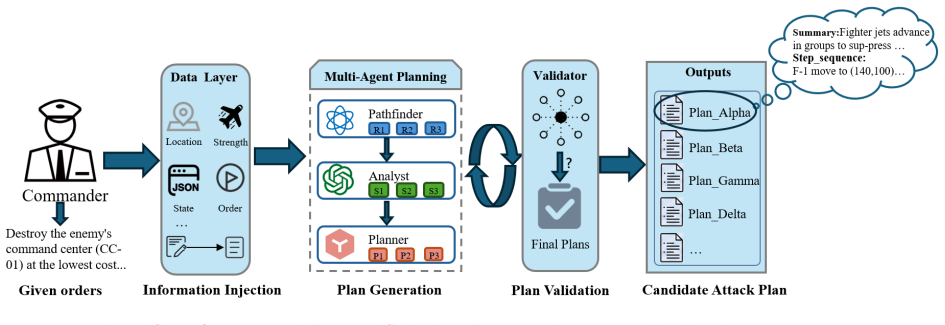
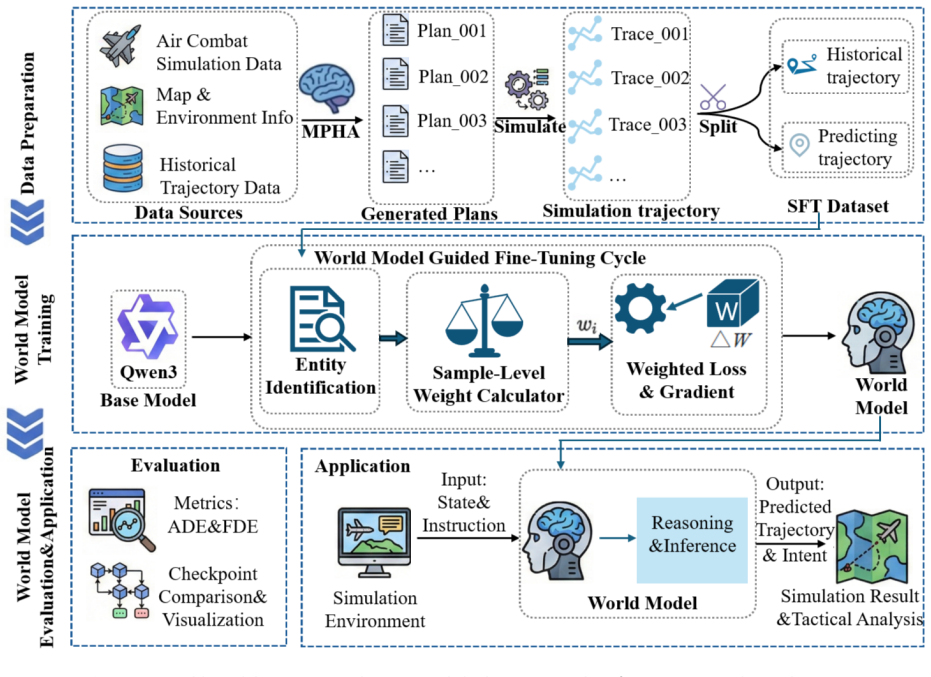
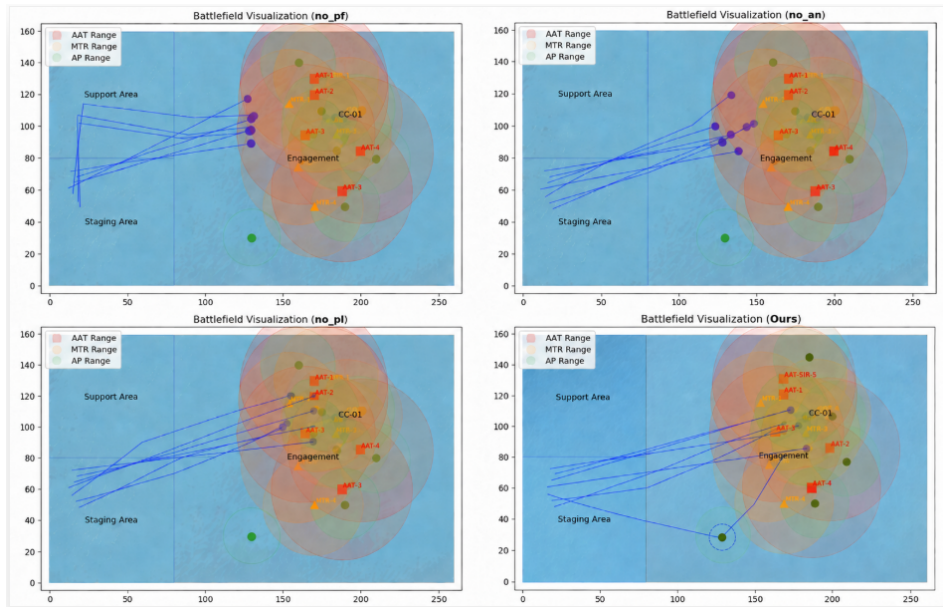
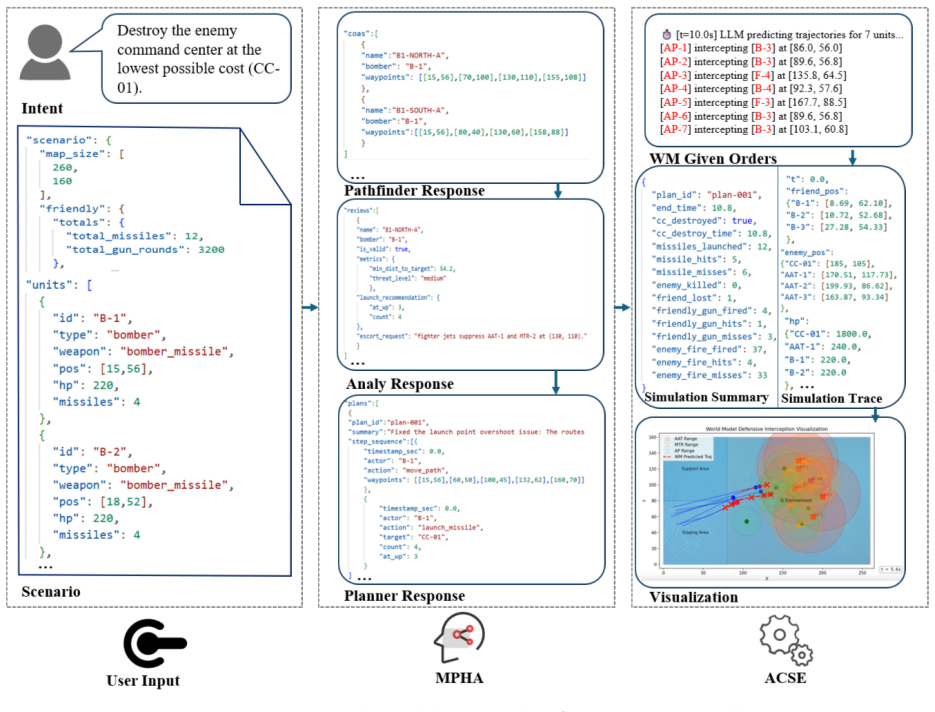
IFPV consists of MPHA for generative operational planning via agent collaboration that decomposes intent into multi-platform tactical sequences and ACSE for high-fidelity verification where an opponent equipped with a customized world model predicts platform evolution and conducts dynamic counteractions, producing plans with higher success and lower cost than baselines.
What carries the argument
Multi-Perspective Hierarchical Agents (MPHA) for plan generation through Pathfinder-Analyst-Planner collaboration tightly coupled with Adversarial Cognitive Simulation Engine (ACSE) that introduces an opponent with world model for dynamic counteractions.
If this is right
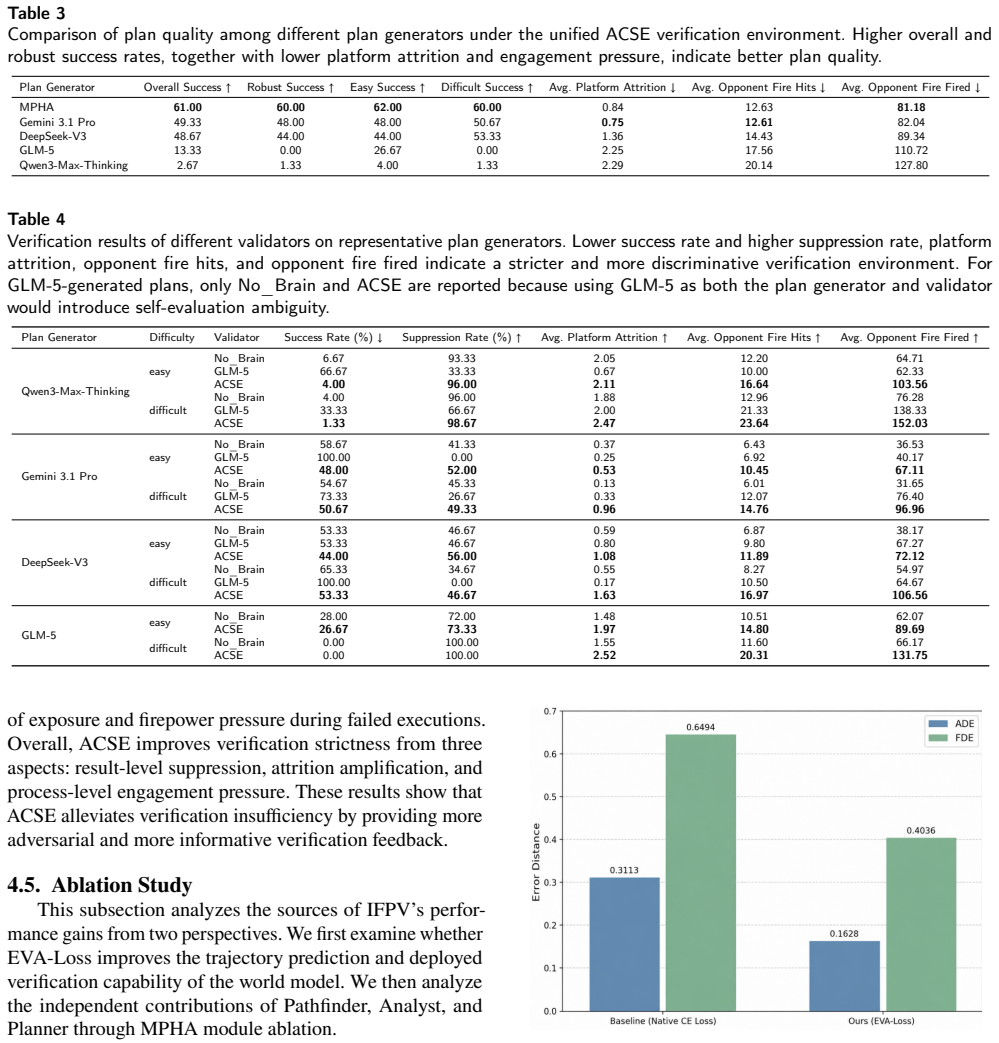
- Plans produced by MPHA achieve 19.4 percent higher mission success than single-step LLM planning in the ACTS simulator.
- Operational costs drop 41.7 percent under the same comparison.
- ACSE raises average suppression rate 31.8 percent over traditional rule-based validators by revealing more latent vulnerabilities.
- Specialized agent roles enable decomposition of high-level intent into executable action sequences suited to multi-platform operations.
- Dynamic opponent modeling in verification makes the test environment stricter and more discriminative than static rule checks.
Where Pith is reading between the lines
- The multi-agent decomposition might benefit LLM planning in non-combat domains that require breaking complex goals into coordinated steps under uncertainty.
- If the world model inside ACSE proves accurate, the verification approach could transfer to other simulators without major redesign.
- Adding real-time data streams to the opponent model could make counteractions more responsive to evolving conditions.
- The framework structure suggests it could scale by adding further agent specializations for larger-scale operations.
Load-bearing premise
Performance differences measured inside the Asymmetric Combat Tactic Simulator reflect genuine improvements that would appear outside that specific simulator rather than being artifacts of its rules or metrics.
What would settle it
Running IFPV-generated plans against the single-step LLM baseline in a second independent simulator or real exercise and finding no comparable gains in mission success rate or operational cost.
Figures
read the original abstract
Operational plan generation and verification are critical for modern complex and rapidly changing battlefield environments, yet traditional generation and verification methods still respectively face the challenges of generation infeasibility and verification insufficiency. To alleviate these limitations, we propose an Integrated Multi-Agent Framework for Generative Operational Planning and High-Fidelity Plan Verification (IFPV). IFPV consists of two tightly coupled modules: Multi-Perspective Hierarchical Agents (MPHA) for generative operational planning and an Adversarial Cognitive Simulation Engine (ACSE) for high-fidelity adversarial plan verification. MPHA decomposes commander intent into executable multi-platform tactical action sequences through the collaboration of Pathfinder, Analyst, and Planner agents. ACSE introduces an opponent equipped with a customized world model, which predicts the future evolution of mission-critical platforms and conducts dynamic counteractions against candidate plans. Simulation experiments in the Asymmetric Combat Tactic Simulator (ACTS) show that IFPV improves mission success by 19.4% and reduces operational cost by 41.7% compared with a single-step large language model (LLM) planning baseline. Compared with a traditional rule-based validator, ACSE increases the average suppression rate by 31.8%, indicating that the proposed verification environment is stricter and more discriminative in revealing the latent vulnerabilities of candidate plans. The code for IFPV can be found at https://github.com/zhigao3ks/IFPV.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes IFPV, an integrated multi-agent framework consisting of Multi-Perspective Hierarchical Agents (MPHA) for generative operational planning via collaboration among Pathfinder, Analyst, and Planner agents, and an Adversarial Cognitive Simulation Engine (ACSE) for high-fidelity adversarial plan verification using an opponent with a customized world model. Experiments conducted in the Asymmetric Combat Tactic Simulator (ACTS) report that IFPV achieves a 19.4% improvement in mission success and 41.7% reduction in operational cost relative to a single-step LLM planning baseline, while ACSE yields a 31.8% higher average suppression rate than a traditional rule-based validator. The code is publicly released on GitHub.
Significance. If the empirical results prove robust, the framework could advance multi-agent LLM applications in dynamic planning domains. The public code release is a clear strength supporting reproducibility. The single-simulator evaluation, however, constrains the broader significance of the quantitative claims.
major comments (2)
- [Abstract and results section] Abstract and results section: The reported improvements (19.4% mission success, 41.7% cost reduction, 31.8% suppression rate) are stated without any accompanying information on the number of simulation runs, statistical tests, scenario distributions, or controls for simulator-specific bias. This information is load-bearing for evaluating whether the deltas support the central claim of a superior framework.
- [ACSE description and evaluation] ACSE description and evaluation: No sensitivity analysis, cross-simulator results, or external grounding is provided to rule out the possibility that performance differences arise from artifacts in the ACTS opponent model, platform dynamics, or metric definitions rather than genuine improvements from MPHA+ACSE.
minor comments (2)
- [MPHA module] The interactions among the three agents in MPHA could be clarified with an explicit diagram or pseudocode in addition to the textual description.
- [Notation and terminology] A table summarizing all acronyms (MPHA, ACSE, ACTS) and their component roles would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of experimental rigor. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: [Abstract and results section] Abstract and results section: The reported improvements (19.4% mission success, 41.7% cost reduction, 31.8% suppression rate) are stated without any accompanying information on the number of simulation runs, statistical tests, scenario distributions, or controls for simulator-specific bias. This information is load-bearing for evaluating whether the deltas support the central claim of a superior framework.
Authors: We agree that the abstract and results would be strengthened by explicit reporting of these details. In the revised manuscript we will expand both sections to state the total number of simulation runs performed, the statistical tests applied (including p-values), the scenario sampling procedure and distribution, and any controls used to mitigate simulator-specific bias. These elements will be added without changing the reported performance deltas. revision: yes
-
Referee: [ACSE description and evaluation] ACSE description and evaluation: No sensitivity analysis, cross-simulator results, or external grounding is provided to rule out the possibility that performance differences arise from artifacts in the ACTS opponent model, platform dynamics, or metric definitions rather than genuine improvements from MPHA+ACSE.
Authors: We will add a sensitivity analysis on the ACSE opponent model parameters (e.g., prediction horizon and counteraction aggressiveness) and report its effect on suppression rates. Cross-simulator experiments are outside the scope of the current study because ACTS is the only publicly available high-fidelity asymmetric combat environment matching the required platform dynamics; we will explicitly discuss this limitation and note that the released code enables independent validation in other simulators. We maintain that the 31.8% higher suppression rate versus rule-based validation already demonstrates ACSE's stricter verification, but the added sensitivity results will further address potential artifacts. revision: partial
Circularity Check
Empirical simulation results in ACTS show no reduction to fitted parameters or self-citation chains
full rationale
The paper's central claims consist of measured performance deltas (19.4% success, 41.7% cost reduction, 31.8% suppression) obtained by running MPHA+ACSE and baselines inside the external Asymmetric Combat Tactic Simulator (ACTS). No equations, fitted parameters, or uniqueness theorems are presented that would make these deltas equivalent to quantities defined inside the paper itself. The framework description (MPHA agents, ACSE opponent model) is constructive rather than self-referential, and the provided text contains no load-bearing self-citations that substitute for external validation. This places the work in the normal non-circular category.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Multi-Perspective Hierarchical Agents (MPHA)
no independent evidence
-
Adversarial Cognitive Simulation Engine (ACSE)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
J. R. Boyd, The essence of winning and losing, briefing slides (1996)
1996
-
[2]
B. R. Price, Colonel john boyd’s thoughts on disruption, Journal of Advanced Military Studies 14 (1) (2023)
2023
-
[3]
R. S. Sutton, A. G. Barto, Reinforcement Learning: An Introduction, 2nd Edition, MIT Press, Cambridge, MA, 2018
2018
-
[4]
D. Silver, J. Schrittwieser, K. Simonyan, I. Antonoglou, A. Huang, A. Guez, T. Hubert, L. Baker, M. Lai, A. Bolton, Y. Chen, T. Lillicrap, F. Hui, L. Sifre, G. van den Driessche, T. Graepel, D. Hassabis, Mas- tering the game of go without human knowledge, Nature 550 (7676) (2017) 354–359.doi:10.1038/nature24270
-
[5]
O. Vinyals, I. Babuschkin, W. M. Czarnecki, M. Mathieu, A. Dudzik, J. Chung, D. H. Choi, R. Powell, T. Ewalds, P. Georgiev, J. Oh, D. Horgan, M. Kroiss, I. Danihelka, A. Huang, L. Sifre, T. Cai, J. P. Agapiou, M. Jaderberg, A. S. Vezhnevets, R. Leblond, T. Pohlen, V.Dalibard,D.Budden,Y.Sulsky,J.Molloy,T.L.Paine,C.Gulcehre, Z. Wang, T. Pfaff, Y. Wu, R. Rin...
-
[6]
Schrittwieser, I
J. Schrittwieser, I. Antonoglou, T. Hubert, K. Simonyan, L. Sifre, S.Schmitt,A.Guez,E.Lockhart,D.Hassabis,T.Graepel,T.Lillicrap, D. Silver, Mastering atari, go, chess and shogi by planning with a learned model, Nature 588 (7839) (2020) 604–609.doi:10.1038/ s41586-020-03051-4
2020
-
[7]
Banks, J
J. Banks, J. S. Carson, B. L. Nelson, D. M. Nicol, Discrete-Event System Simulation, 5th Edition, Prentice Hall, 2010
2010
-
[8]
B. P. Zeigler, H. Praehofer, T. G. Kim, Theory of Modeling and Simulation: Integrating Discrete Event and Continuous Complex Dynamic Systems, 2nd Edition, Academic Press, New York, 2000
2000
-
[9]
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A.Neelakantan,P.Shyam,G.Sastry,A.Askell,S.Agarwal,A.Herbert- Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B.Chess,J.Clark,C.Berner,S.McCandlish,A.Radford,I.Sutskever, D. Amodei, Language models are f...
2020
-
[10]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. H. Chi,Q.V.Le,D.Zhou,Chain-of-thoughtpromptingelicitsreasoningin largelanguagemodels,in:AdvancesinNeuralInformationProcessing Systems, Vol. 35, 2022, pp. 24824–24837
2022
-
[11]
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, Y. Cao, ReAct: Synergizing reasoning and acting in language models, in: International Conference on Learning Representations, 2023
2023
-
[12]
S. Yao, D. Yu, J. Zhao, I. Shafran, T. L. Griffiths, Y. Cao, K. Narasimhan, Tree of thoughts: Deliberate problem solving with largelanguagemodels,in:AdvancesinNeuralInformationProcessing Systems, Vol. 36, 2023, pp. 11809–11822
2023
-
[13]
Zettlemoyer, N
T.Schick,J.Dwivedi-Yu,R.Dessì,R.Raileanu,M.Lomeli,E.Hambro, L. Zettlemoyer, N. Cancedda, T. Scialom, Toolformer: Language models can teach themselves to use tools, in: Advances in Neural Information Processing Systems, Vol. 36, 2023
2023
-
[14]
J. S. Park, J. C. O’Brien, C. J. Cai, M. R. Morris, P. Liang, M. S. Bernstein,Generativeagents:Interactivesimulacraofhumanbehavior, in:Proceedingsofthe36thAnnualACMSymposiumonUserInterface Software and Technology, 2023, pp. 1–22.doi:10.1145/3586183. 3606763
-
[15]
Q. Wu, G. Bansal, J. Zhang, Y. Wu, B. Li, E. Zhu, L. Jiang, X. Zhang, S. Zhang, J. Liu, A. H. Awadallah, R. W. White, D. Burger, C. Wang, AutoGen: Enabling next-gen LLM applications via multi-agent con- versation, arXiv preprint arXiv:2308.08155 (2023).arXiv:2308.08155
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
G. Wang, Y. Xie, Y. Jiang, A. Mandlekar, C. Xiao, Y. Zhu, L. Fan, A. Anandkumar, Voyager: An open-ended embodied agent with large language models, Transactions on Machine Learning Research (2024)
2024
-
[17]
T. Guo, X. Chen, Y. Wang, R. Chang, S. Pei, N. V. Chawla, O. Wiest, X. Zhang, Large language model based multi-agents: A survey of progress and challenges, in: Proceedings of the Thirty-Third Interna- tionalJointConferenceonArtificialIntelligence,2024,pp.8116–8125
2024
-
[18]
Z. Ji, N. Lee, R. Frieske, T. Yu, D. Su, Y. Xu, E. Ishii, Y. J. Bang, A. Madotto, P. Fung, Survey of hallucination in natural language generation, ACM Computing Surveys 55 (12) (2023) 1–38.doi: 10.1145/3571730
-
[19]
Valmeekam, M
K. Valmeekam, M. Marquez, A. Olmo, S. Sreedharan, S. Kamb- hampati, PlanBench: An extensible benchmark for evaluating large language models on planning and reasoning about change, Advances in Neural Information Processing Systems 36 (2023) 38975–38987
2023
-
[20]
S.Kambhampati,Canlargelanguagemodelsreasonandplan?,Annals of the New York Academy of Sciences 1534 (1) (2024) 15–18.doi: 10.1111/nyas.15125
-
[21]
Understanding the planning of LLM agents: A survey
X. Huang, W. Liu, X. Chen, X. Wang, H. Wang, D. Lian, Y. Wang, R. Tang, E. Chen, Understanding the planning of LLM agents: A survey, arXiv preprint arXiv:2402.02716 (2024).arXiv:2402.02716
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
D. Chen, Y. Zhuang, S. Zhang, J. Liu, S. Dong, S. Tang, Data shunt: Collaboration of small and large models for lower costs and better performance, in: Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 38, 2024, pp. 11249–11257.doi:10.1609/aaai. v38i10.29003
-
[23]
D. Chen, F. Gao, S. Zhang, Y. Zhuang, S. Tang, Q. Liu, H. Wang, X. Yang, M. Xu, Improving large models with small models: Lower costs and better performance, Neural Networks 195 (2025) 108276. doi:10.1016/j.neunet.2025.108276
-
[24]
D. Chen, S. Zhang, F. Gao, Y. Zhuang, S. Tang, Q. Liu, M. Xu, Logic distillation: Learning from code function by function for decision- making tasks, in: Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, 2025, pp. 7338–7346. doi:10.24963/ijcai.2025/816
- [25]
- [26]
-
[27]
R. S. Sutton, Dyna, an integrated architecture for learning, planning, and reacting, ACM SIGART Bulletin 2 (4) (1991) 160–163.doi: 10.1145/122344.122377
-
[28]
D. Ha, J. Schmidhuber, Recurrent world models facilitate policy evolution, in: Advances in Neural Information Processing Systems, Vol. 31, 2018
2018
-
[29]
Mastering Diverse Domains through World Models
D.Hafner,J.Pasukonis, J.Ba,T.Lillicrap, Masteringdiversedomains throughworldmodels,arXivpreprintarXiv:2301.04104(2023). arXiv: 2301.04104
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
A. Hu, L. Russell, H. Yeo, Z. Murez, G. Fedoseev, A. Kendall, J. Shotton, G. Corrado, GAIA-1: A generative world model for autonomous driving, arXiv preprint arXiv:2309.17080 (2023).arXiv: 2309.17080
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Y. Gu, K. Zhang, Y. Ning, B. Zheng, B. Gou, T. Xue, C. Chang, S. Srivastava, Y. Xie, P. Qi, H. Sun, Y. Su, Is your LLM secretly a world model of the internet? model-based planning for web agents, Transactions on Machine Learning Research (2024)
2024
-
[32]
Y. Chen, S. Chu, Large language models in wargaming: Methodology, application, and robustness, in: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition Workshops, 2024, pp. 2894–2903
2024
-
[33]
S. Lin, W. Hua, L. Li, C.-J. Chang, L. Fan, J. Ji, H. Hua, M. Jin, J. Luo, Y. Zhang, BattleAgent: Multi-modal dynamic emulation on historical battles to complement historical analysis, in: Proceedings of the 2024 Conference on Empirical Methods in Natural Language 13 Processing: System Demonstrations, Association for Computational Linguistics, Miami, Flor...
2024
- [34]
-
[35]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, C. Zheng, D. Liu, F. Zhou, F. Huang, F. Hu, H. Ge, H. Wei, H. Lin, J. Tang, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Zhou, J. Lin, K. Dang, K. Bao, K. Yang, L. Yu, L. Deng, M. Li, M. Xue, M. Li, P. Zhang, P. Wang, Q. Zhu, R. Men, R. Gao, S. Liu, S. Luo, T. ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, W. Chen, LoRA: Low-rank adaptation of large language models, in: International Conference on Learning Representations, 2022. URLhttps://openreview.net/forum?id=nZeVKeeFYf9 Appendix A. Experimental Parameters and Simulation Protocol Thisappendixprovidesdetailedexperimentalparameters and s...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.