Chain-of-Procedure: Hierarchical Visual-Language Reasoning for Procedural QA
Pith reviewed 2026-06-30 20:44 UTC · model grok-4.3
The pith
A retrieval-then-decomposition pipeline lets vision-language models answer next-step questions from procedure photos with up to 13 percent higher accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
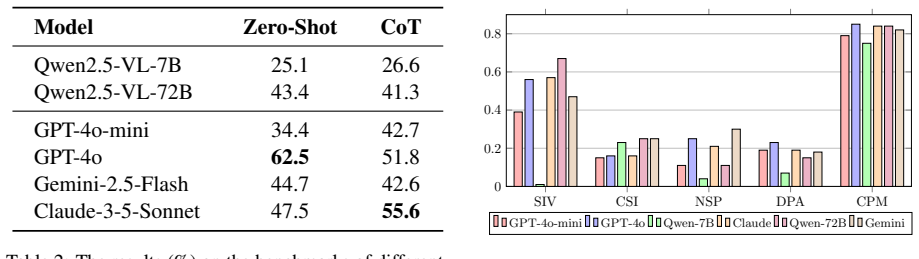
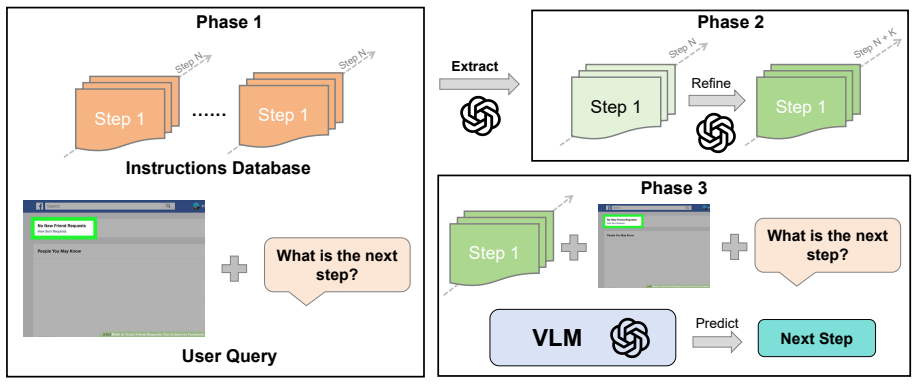
The authors claim that the two limitations of inadequate cross-modal retrieval of structured procedures and misalignment between image-sequence granularity and textual step decomposition are the main obstacles for VLMs on visual procedure QA. They argue that a hierarchical framework called Chain-of-Procedure, which retrieves relevant instructions using visual cues, performs step refinement through semantic decomposition, and then generates the next step, directly mitigates both problems. Experiments on the new ProcedureVQA benchmark across six VLMs show absolute gains of up to 13 percent over standard prompting baselines.
What carries the argument
Chain-of-Procedure (CoP), the three-stage pipeline of visual retrieval of instructions, semantic step decomposition, and next-step generation.
If this is right
- Vision-language models gain up to 13 percent absolute accuracy on next-step prediction when the retrieval and decomposition stages are added.
- The ProcedureVQA benchmark provides a standardized test set for measuring procedural reasoning from intermediate visual states.
- The same hierarchical pattern improves results across six different vision-language models without retraining.
- Explicit separation of retrieval from generation addresses the cross-modal and granularity problems that standard end-to-end prompting leaves unsolved.
Where Pith is reading between the lines
- If retrieval is the dominant bottleneck, then stronger visual search modules inside VLMs could produce further gains even without the full CoP pipeline.
- The same staged approach might transfer to video sequences or to non-procedural tasks that also require matching visual states to textual plans.
- Success on ProcedureVQA would suggest that many current VLM failures on sequential tasks stem from missing explicit alignment mechanisms rather than insufficient model capacity.
Load-bearing premise
The two limitations named in the abstract—inadequate cross-modal retrieval and granularity misalignment—are the primary causes of poor performance and can be fixed by the retrieval-then-decomposition pipeline.
What would settle it
A controlled test in which the retrieval stage is replaced by perfect ground-truth instructions and step boundaries are manually aligned, yet accuracy gains disappear or remain below 3 percent.
Figures

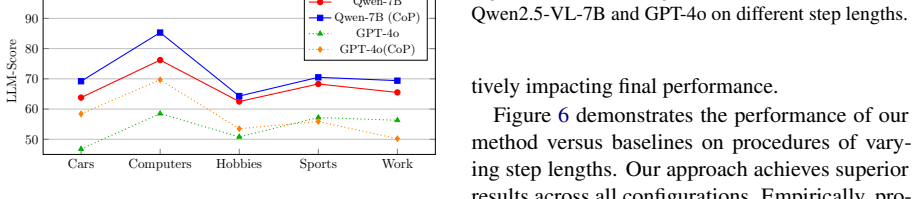
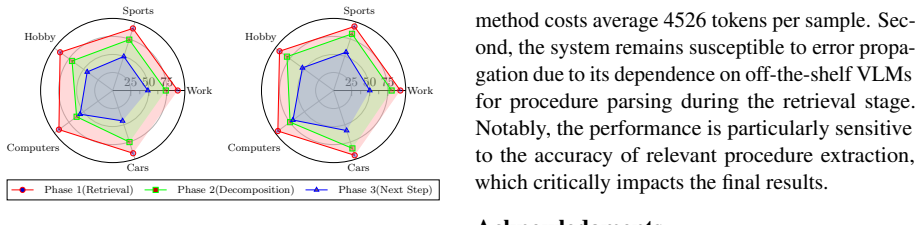
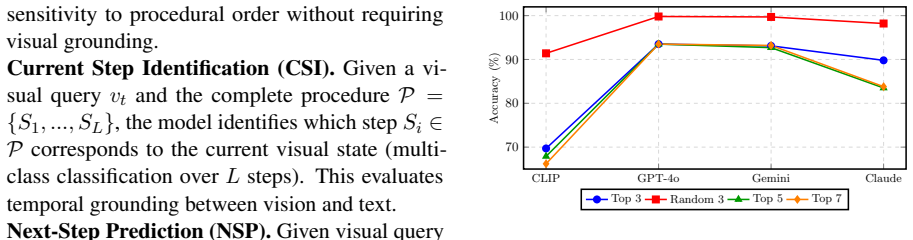
read the original abstract
Recent advances in vision-language models (VLMs) have achieved impressive results on standard image-text tasks, yet their potential for visual procedure question answering (VP-QA) remains largely unexplored. VP-QA presents unique challenges where users query next-step actions by uploading images for intermediate states of complex procedures. To systematically evaluate VLMs on this practical task, we propose ProcedureVQA, a novel multimodal benchmark specifically designed for visual procedural reasoning. Through comprehensive analysis, we identify two critical limitations in current VLMs: inadequate cross-modal retrieval of structured procedures given visual states, and misalignment between image sequence granularity and textual step decomposition. To address these issues, we present Chain-of-Procedure (CoP), a hierarchical reasoning framework that first retrieves relevant instructions using visual cues, then performs step refinement through semantic decomposition, and finally generates the next step. Experiments across six VLMs demonstrate CoP's effectiveness, achieving up to 13% absolute improvement over standard baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ProcedureVQA, a new multimodal benchmark for visual procedural question answering (VP-QA), and proposes Chain-of-Procedure (CoP), a hierarchical visual-language reasoning framework. CoP first retrieves relevant instructions using visual cues, performs step refinement via semantic decomposition, and generates the next step. The abstract identifies two limitations in current VLMs (inadequate cross-modal retrieval of structured procedures and misalignment between image sequence granularity and textual step decomposition) and reports that experiments across six VLMs show CoP achieving up to 13% absolute improvement over standard baselines.
Significance. If the empirical results hold under rigorous evaluation, the work would be significant for the field by establishing a dedicated benchmark for an underexplored practical task (VP-QA) and demonstrating a retrieval-then-decomposition pipeline that targets specific cross-modal and granularity issues in VLMs. The approach could inform future procedural reasoning systems in applications such as instructional guidance.
major comments (2)
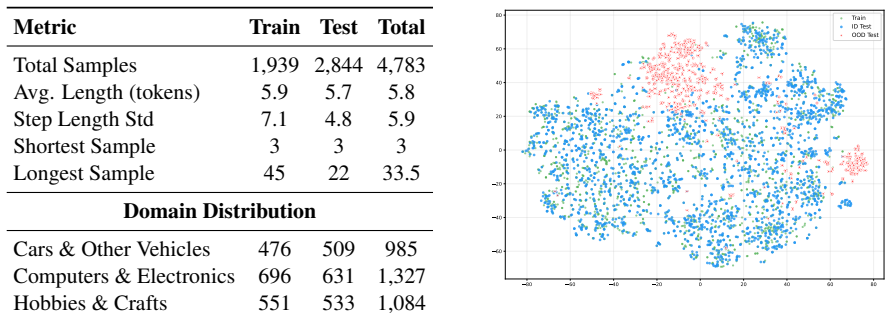
- [Abstract and §4] Abstract and §4 (Experiments): The central claim of up to 13% absolute improvement is load-bearing for the paper's contribution, yet no baseline definitions, dataset statistics (e.g., number of procedures, images per procedure, question types), evaluation metrics, or error analysis are supplied. This prevents verification of whether the gains are attributable to CoP rather than benchmark artifacts or weak baselines.
- [§3 and §5] §3 (Benchmark Construction) and §5 (Analysis): The identification of the two critical limitations as primary causes of poor VP-QA performance is asserted via 'comprehensive analysis,' but without quantitative evidence (e.g., retrieval accuracy metrics before/after CoP or granularity mismatch measurements) or ablations isolating each CoP component, the motivation and mitigation claims cannot be assessed as load-bearing.
minor comments (1)
- [§2] Notation for the three stages of CoP (retrieval, refinement, generation) should be formalized with consistent symbols or pseudocode to improve clarity of the hierarchical pipeline.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and outline the revisions we will make to improve clarity and verifiability of our claims.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The central claim of up to 13% absolute improvement is load-bearing for the paper's contribution, yet no baseline definitions, dataset statistics (e.g., number of procedures, images per procedure, question types), evaluation metrics, or error analysis are supplied. This prevents verification of whether the gains are attributable to CoP rather than benchmark artifacts or weak baselines.
Authors: We agree that the abstract and experimental section would benefit from explicit inclusion of these details to strengthen verifiability. The full manuscript contains dataset construction details in §3 and experimental setup in §4, but we will revise the abstract to summarize key statistics (number of procedures, images per procedure, question types) and metrics. We will also add explicit baseline definitions, a summary table, and an error analysis subsection in §4. These changes will be incorporated in the revised version. revision: yes
-
Referee: [§3 and §5] §3 (Benchmark Construction) and §5 (Analysis): The identification of the two critical limitations as primary causes of poor VP-QA performance is asserted via 'comprehensive analysis,' but without quantitative evidence (e.g., retrieval accuracy metrics before/after CoP or granularity mismatch measurements) or ablations isolating each CoP component, the motivation and mitigation claims cannot be assessed as load-bearing.
Authors: We acknowledge the need for stronger quantitative support. While §3 and §5 present analysis of the identified limitations, we will add retrieval accuracy metrics (before/after CoP), granularity mismatch measurements, and component-wise ablations in the revised §5 to provide direct evidence. This will better substantiate the motivation and effectiveness of CoP. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces a new benchmark (ProcedureVQA) and an empirical framework (CoP) consisting of retrieval-then-decomposition steps, evaluated directly via accuracy gains on six VLMs. No equations, closed-form derivations, fitted parameters, or self-citation chains appear in the provided abstract or description. The central claims reduce to experimental comparisons rather than any construction that equates outputs to inputs by definition. This matches the default expectation of a non-circular empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Anthropic . 2025. https://assets.anthropic.com/m/785e231869ea8b3b/original/claude-3-7-sonnet-system-card.pdf Claude 3.7 sonnet system card
2025
-
[4]
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. 2023. Qwen-vl: A frontier large vision-language model with versatile abilities. arXiv preprint arXiv:2308.12966
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Yakoub Bazi, Mohamad Mahmoud Al Rahhal, Laila Bashmal, and Mansour Zuair. 2023. Vision--language model for visual question answering in medical imagery. Bioengineering, 10(3):380
2023
-
[6]
Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. 2020. Piqa: Reasoning about physical commonsense in natural language. In Proceedings of the AAAI conference on artificial intelligence, volume 34
2020
-
[7]
Guanhua Chen, Yutong Yao, Lidia S. Chao, Xuebo Liu, and Derek F. Wong. 2025 a . https://doi.org/10.18653/v1/2025.acl-long.1376 SGIC : A self-guided iterative calibration framework for RAG . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 28357--28370, Vienna, Austria. Association fo...
- [8]
- [9]
- [10]
-
[11]
Bhavana Dalvi and 1 others. 2018. https://www.researchgate.net/publication/325445109_Tracking_State_Changes_in_Procedural_Text_a_Challenge_Dataset_and_Models_for_Process_Paragraph_Comprehension Tracking state changes in procedural text: a challenge dataset and models for process paragraph comprehension . arXiv preprint arXiv:1805.06975
-
[12]
Shen Gao, Haotong Zhang, Xiuying Chen, Rui Yan, and Dongyan Zhao. 2022. https://api.semanticscholar.org/CorpusID:256631022 Summarizing procedural text: Data and approach . In Conference on Empirical Methods in Natural Language Processing
2022
-
[13]
Diogo Gl \' o ria - Silva, David Semedo, and Jo \ a o Magalh \ a es. 2024. https://doi.org/10.18653/V1/2024.EMNLP-MAIN.1191 Show and guide: Instructional-plan grounded vision and language model . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, EMNLP 2024, Miami, FL, USA, November 12-16, 2024 , pages 21371--21389....
-
[14]
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, Miguel Martin, Tushar Nagarajan, Ilija Radosavovic, Santhosh Kumar Ramakrishnan, Fiona Ryan, Jayant Sharma, Michael Wray, Mengmeng Xu, Eric Zhongcong Xu, and 66 others. 2022. https://doi.org/10.1109/CVPR52688...
-
[15]
Jiaxian Guo, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Boyang Li, Dacheng Tao, and Steven Hoi. 2023. From images to textual prompts: Zero-shot visual question answering with frozen large language models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10867--10877
2023
-
[16]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770--778
2016
-
[17]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, and 1 others. 2022. Lora: Low-rank adaptation of large language models. ICLR, 1(2):3
2022
-
[18]
OpenAI Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, Aleksander Mkadry, Alex Baker-Whitcomb, Alex Beutel, Alex Borzunov, Alex Carney, Alex Chow, Alexander Kirillov, Alex Nichol, Alex Paino, and 397 others. 2024. https://api.semanticscholar.org/CorpusID:273662196 G...
2024
-
[19]
Kushal Kafle and Christopher Kanan. 2017. Visual question answering: Datasets, algorithms, and future challenges. Computer Vision and Image Understanding, 163:3--20
2017
- [20]
-
[21]
Abdullah Faiz Ur Rahman Khilji, Riyanka Manna, Sahinur Rahman Laskar, Partha Pakray, Dipankar Das, Sivaji Bandyopadhyay, and Alexander F. Gelbukh. 2021. https://api.semanticscholar.org/CorpusID:230988601 Cookingqa: Answering questions and recommending recipes based on ingredients . Arabian Journal for Science and Engineering, 46:3701 -- 3712
2021
- [22]
-
[23]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual instruction tuning. Advances in neural information processing systems, 36:34892--34916
2023
-
[24]
Yujie Lu, Pan Lu, Zhiyu Chen, Wanrong Zhu, Xin Wang, and William Yang Wang. 2024. https://doi.org/10.18653/V1/2024.FINDINGS-EMNLP.641 Multimodal procedural planning via dual text-image prompting . In Findings of the Association for Computational Linguistics: EMNLP 2024, Miami, Florida, USA, November 12-16, 2024 , Findings of ACL , pages 10931--10954. Asso...
-
[25]
Chao, and Derek F
Jingkun Ma, Runzhe Zhan, Yang Li, Di Sun, Hou Pong Chan, Lidia S. Chao, and Derek F. Wong. 2025. https://openreview.net/forum?id=frp6TqqcTF Visaidmath: Benchmarking visual-aided mathematical reasoning . In 1st Workshop on VLM4RWD @ NeurIPS 2025
2025
-
[26]
Antoine Miech, Dimitri Zhukov, Jean-Baptiste Alayrac, Makarand Tapaswi, Ivan Laptev, and Josef Sivic. 2019. Howto100m: Learning a text-video embedding by watching hundred million narrated video clips. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
2019
- [27]
- [28]
-
[29]
OpenAI. 2023. https://doi.org/10.48550/ARXIV.2303.08774 GPT-4 technical report . CoRR, abs/2303.08774
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08774 2023
-
[30]
OpenAI . 2025. https://openai.com/index/gpt-4-1/ Introducing gpt-4.1 in the api
2025
-
[31]
Pranoy Panda, Ankush Agarwal, Chaitanya Devaguptapu, Manohar Kaul, and Prathosh Ap. 2024. https://doi.org/10.18653/v1/2024.acl-long.717 HOLMES : Hyper-relational knowledge graphs for multi-hop question answering using LLM s . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13263--13...
-
[32]
Aman Priyanshu, Yash Maurya, and Zuofei Hong. 2024. https://doi.org/10.48550/ARXIV.2407.01557 AI governance and accountability: An analysis of anthropic's claude . CoRR, abs/2407.01557
-
[33]
Jielin Qiu, Andrea Madotto, Zhaojiang Lin, Paul A Crook, Yifan Ethan Xu, Xin Luna Dong, Christos Faloutsos, Lei Li, Babak Damavandi, and Seungwhan Moon. 2024. Snapntell: Enhancing entity-centric visual question answering with retrieval augmented multimodal llm. arXiv preprint arXiv:2403.04735
-
[34]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, and 1 others. 2021. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748--8763. PmLR
2021
-
[35]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Machel Reid, Nikolay Savinov, Denis Teplyashin, Dmitry Lepikhin, Timothy P. Lillicrap, Jean - Baptiste Alayrac, Radu Soricut, Angeliki Lazaridou, Orhan Firat, Julian Schrittwieser, Ioannis Antonoglou, Rohan Anil, Sebastian Borgeaud, Andrew M. Dai, Katie Millican, Ethan Dyer, Mia Glaese, Thibault Sottiaux, Benjamin Lee, and 34 others. 2024. https://doi.org...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2403.05530 2024
-
[36]
Nils Reimers and Iryna Gurevych. 2019. https://doi.org/10.18653/V1/D19-1410 Sentence-bert: Sentence embeddings using siamese bert-networks . In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3-7, ...
-
[37]
Fangzhou Song, Bin Zhu, Yanbin Hao, and Shuo Wang. 2023. https://api.semanticscholar.org/CorpusID:266149406 Enhancing recipe retrieval with foundation models: A data augmentation perspective . In European Conference on Computer Vision
2023
-
[38]
Niket Tandon, Keisuke Sakaguchi, Bhavana Dalvi, Dheeraj Rajagopal, Peter Clark, Michal Guerquin, Kyle Richardson, and Eduard Hovy. 2020. A dataset for tracking entities in open domain procedural text. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6408--6417
2020
-
[39]
Yansong Tang, Dajun Ding, Yongming Rao, Yu Zheng, Danyang Zhang, Lili Zhao, Jiwen Lu, and Jie Zhou. 2019. https://doi.org/10.1109/CVPR.2019.00130 COIN: A large-scale dataset for comprehensive instructional video analysis . In IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019 , pages 1207--1216. Co...
-
[40]
Gemini Team. 2023. https://doi.org/10.48550/ARXIV.2312.11805 Gemini: A family of highly capable multimodal models . CoRR, abs/2312.11805
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2312.11805 2023
-
[41]
Qwen Team. 2025. https://arxiv.org/abs/2505.09388 Qwen3 technical report . Preprint, arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. 2024. Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution. arXiv preprint arXiv:2409.12191
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022 a . http://papers.nips.cc/paper\_files/paper/2022/hash/9d5609613524ecf4f15af0f7b31abca4-Abstract-Conference.html Chain-of-thought prompting elicits reasoning in large language models . In Advances in Neural Information Processing Syst...
2022
-
[44]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, and 1 others. 2022 b . Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824--24837
2022
-
[45]
Semih Yagcioglu, Aykut Erdem, Erkut Erdem, and Nazli Ikizler-Cinbis. 2018. https://doi.org/10.18653/v1/D18-1166 R ecipe QA : A challenge dataset for multimodal comprehension of cooking recipes . In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 1358--1368, Brussels, Belgium. Association for Computational Linguistics
- [46]
-
[47]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W Cohen, Ruslan Salakhutdinov, and Christopher D Manning. 2018. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. arXiv preprint arXiv:1809.09600
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[48]
Yuehao Yin, Huiyan Qi, Bin Zhu, Jingjing Chen, Yu-Gang Jiang, and Chong-Wah Ngo. 2023. https://api.semanticscholar.org/CorpusID:266551671 Foodlmm: A versatile food assistant using large multi-modal model . IEEE Transactions on Multimedia, 27:6949--6961
2023
-
[49]
Shi Yu, Chaoyue Tang, Bokai Xu, Junbo Cui, Junhao Ran, Yukun Yan, Zhenghao Liu, Shuo Wang, Xu Han, Zhiyuan Liu, and Maosong Sun. 2025. https://openreview.net/forum?id=zG459X3Xge Visrag: Vision-based retrieval-augmented generation on multi-modality documents . In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, Apr...
2025
-
[50]
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Weinberger, and Yoav Artzi. 2019. Bertscore: Evaluating text generation with bert. arXiv preprint arXiv:1904.09675
work page internal anchor Pith review Pith/arXiv arXiv 2019
- [51]
-
[52]
Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, Zheyan Luo, Zhangchi Feng, and Yongqiang Ma. 2024. http://arxiv.org/abs/2403.13372 Llamafactory: Unified efficient fine-tuning of 100+ language models . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), Bangkok, Thailand. Assoc...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
Gengze Zhou, Yicong Hong, Zun Wang, Xin Eric Wang, and Qi Wu. 2024. https://doi.org/10.1007/978-3-031-72667-5\_15 Navgpt-2: Unleashing navigational reasoning capability for large vision-language models . In Computer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part VII , Lecture Notes in Computer ...
-
[54]
Fouhey, Ivan Laptev, and Josef Sivic
Dimitri Zhukov, Jean-Baptiste Alayrac, Ramazan Gokberk Cinbis, David F. Fouhey, Ivan Laptev, and Josef Sivic. 2019. https://api.semanticscholar.org/CorpusID:84187266 Cross-task weakly supervised learning from instructional videos . 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3532--3540
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.