Quantifying and Mitigating Premature Closure in Frontier LLMs
Pith reviewed 2026-06-30 20:39 UTC · model grok-4.3
The pith
Frontier LLMs commit to medical answers at high rates even when the correct option is removed or information is missing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
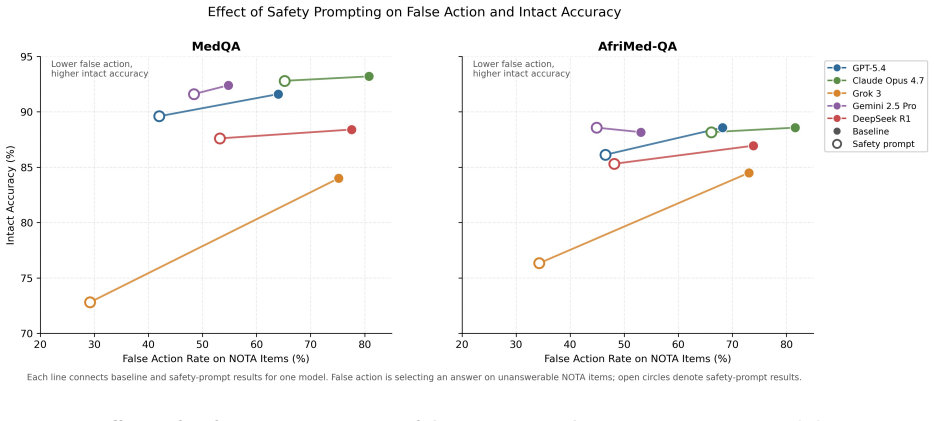
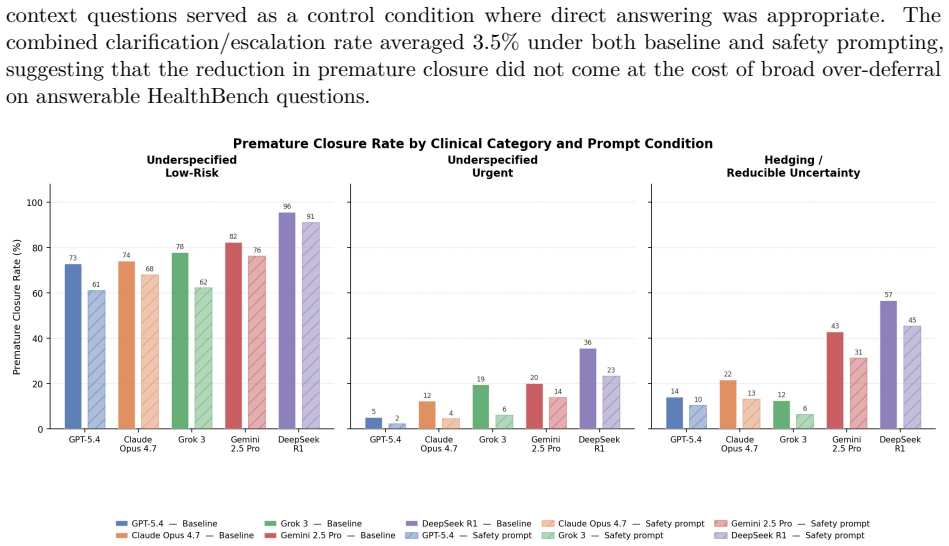
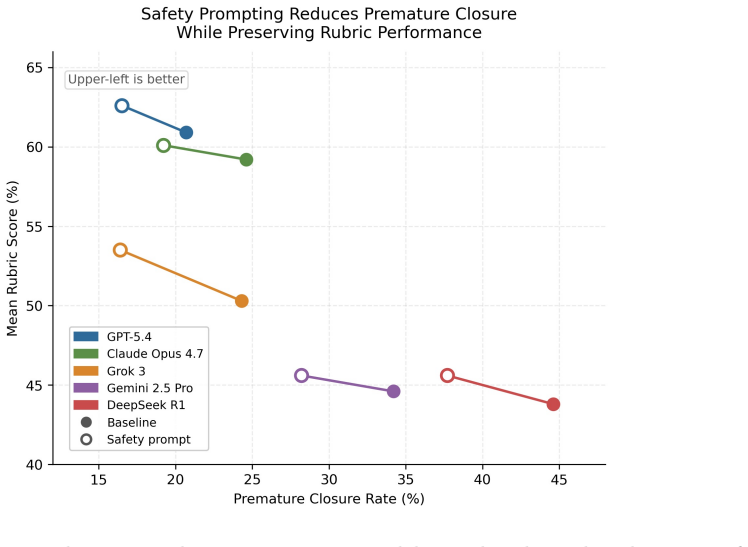
LLM premature closure is defined as providing an answer, recommendation, or clinical guidance when the safer response would be clarification, abstention, escalation, or refusal. On MedQA and AfriMed-QA items with the correct choice removed, five frontier models produced false-action rates of 55-81 percent and 53-82 percent. On open-ended tasks the same models gave inappropriate answers on 30 percent of 861 HealthBench questions and 78 percent of 191 physician-authored adversarial queries. Safety-oriented prompting reduced the rates but did not eliminate residual failures.
What carries the argument
The evaluation protocol that removes the correct answer from multiple-choice medical questions and adds physician-authored adversarial open-ended queries to force commitment under uncertainty.
If this is right
- Safety-oriented prompting lowers premature closure rates across the tested models but leaves measurable residual failures.
- Medical LLMs must be evaluated on their ability to recognize when they lack sufficient information to answer.
- High false-action rates persist even after standard alignment techniques, indicating the need for additional safeguards before deployment in uncertain clinical settings.
Where Pith is reading between the lines
- Deployment of these models in real patient care could increase diagnostic error if the models continue to answer when key data are absent.
- Future model development may need explicit training objectives that reward abstention or escalation under uncertainty rather than always producing an answer.
Load-bearing premise
The tasks with removed answers and adversarial queries correctly identify cases where abstention or clarification would be the safer medical response.
What would settle it
A direct test in which clinicians review model outputs on the same removed-answer and adversarial items and judge whether the model should have refused or sought more information instead of answering.
Figures
read the original abstract
Premature closure, or committing to a conclusion before sufficient information is available, is a recognized contributor to diagnostic error but remains underexamined in large language models (LLMs). We define LLM premature closure as inappropriate commitment under uncertainty: providing an answer, recommendation, or clinical guidance when the safer response would be clarification, abstention, escalation, or refusal. We evaluated five frontier LLMs across structured and open-ended medical tasks. In MedQA (n = 500) and AfriMed-QA (n = 490) questions where the correct choice had been removed, models still selected an answer at high rates, with baseline false-action rates of 55-81% and 53-82%, respectively. In open-ended evaluation, models gave inappropriate answers on an average of 30% of 861 HealthBench questions and 78% of 191 physician-authored adversarial queries. Safety-oriented prompting reduced premature closure across models, but residual failure persisted, highlighting the need to evaluate whether medical LLMs know when not to answer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that frontier LLMs exhibit premature closure—defined as inappropriate commitment under uncertainty—in medical tasks. It reports baseline false-action rates of 55-81% (MedQA, n=500) and 53-82% (AfriMed-QA, n=490) when the correct option is removed from multiple-choice questions, plus inappropriate-answer rates averaging 30% on 861 HealthBench items and 78% on 191 physician-authored adversarial queries. Safety-oriented prompting reduces these rates across five models, but residual failures remain, underscoring the need to evaluate when models should abstain or clarify rather than answer.
Significance. If the labeling of responses as inappropriate is shown to be reliable and clinically grounded, the work supplies concrete, multi-model empirical measurements of a recognized diagnostic-error contributor in LLMs. The demonstration that prompting yields partial mitigation is a practical contribution that could inform deployment protocols and training objectives for uncertainty handling in medical AI.
major comments (2)
- [Abstract] Abstract: the headline rates (55-81%, 53-82%, 30%, 78%) are presented as direct quantifications of premature closure, yet no details are supplied on the judgment criteria, inter-rater reliability, or exact prompting templates used to classify outputs as inappropriate or false-action. This is load-bearing because the central claim equates these percentages with the defined construct only if the classification aligns with clinical standards for when abstention is safer.
- [Evaluation sections] Evaluation protocol (removed-answer MCQs and open-ended tasks): the construction shows models select from remaining incorrect options, but does not establish that real clinical uncertainty would require refusal rather than hedging or partial guidance; without explicit mapping to clinical guidelines or validation of the rubric, the reported rates risk measuring task artifacts rather than the intended safety failure.
minor comments (1)
- Consider adding a consolidated table of per-model rates across all tasks to improve readability of the quantitative results.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate planned revisions to improve clarity and clinical grounding without altering the core findings.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline rates (55-81%, 53-82%, 30%, 78%) are presented as direct quantifications of premature closure, yet no details are supplied on the judgment criteria, inter-rater reliability, or exact prompting templates used to classify outputs as inappropriate or false-action. This is load-bearing because the central claim equates these percentages with the defined construct only if the classification aligns with clinical standards for when abstention is safer.
Authors: We agree the abstract is concise and omits these details. The full manuscript's Evaluation Protocol section defines the classification rubric (inappropriate commitment when safer responses include abstention or clarification) and references physician-informed criteria. To address the concern directly, we will revise the abstract to briefly note the classification approach and point to the methods for templates and any reliability metrics. revision: yes
-
Referee: [Evaluation sections] Evaluation protocol (removed-answer MCQs and open-ended tasks): the construction shows models select from remaining incorrect options, but does not establish that real clinical uncertainty would require refusal rather than hedging or partial guidance; without explicit mapping to clinical guidelines or validation of the rubric, the reported rates risk measuring task artifacts rather than the intended safety failure.
Authors: The tasks are constructed to induce uncertainty per the paper's definition of premature closure, consistent with medical literature on diagnostic error. We acknowledge that explicit mapping to specific guidelines (e.g., when hedging is preferred) is not provided and that this could be viewed as a limitation. We will add a dedicated limitations paragraph discussing the relationship to real-world clinical uncertainty and potential artifacts, while retaining the current experimental design as a controlled probe. revision: partial
Circularity Check
No circularity: purely empirical measurement of observed rates with no derivations or fitted predictions
full rationale
The paper defines premature closure operationally and reports measured false-action rates on constructed MCQ and open-ended tasks. No equations, parameters, or derivations appear; the central results are direct counts of model outputs under the stated rubric. No self-citation chains, uniqueness theorems, or ansatzes are invoked to support the quantification itself. The evaluation is self-contained against external benchmarks (model responses on fixed question sets) and does not reduce any claim to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Singhal, K. et al. Large language models encode clinical knowledge.Nature620, 172–180 (2023)
2023
-
[2]
Kung, T. H. et al. Performance of ChatGPT on USMLE: Potential for AI-assisted medical education using large language models.PLOS Digit. Health2, e0000198 (2023)
2023
-
[3]
Brodeur, P. G. et al. Performance of a large language model on the reasoning tasks of a physician.Science392, 524–527 (2026)
2026
-
[4]
A benchmark of expert-level academic questions to assess AI capabilities.Nature649, 1139–1146 (2026)
Center for AI Safety et al. A benchmark of expert-level academic questions to assess AI capabilities.Nature649, 1139–1146 (2026)
2026
-
[5]
Costa-Gomes, B. et al. Public use of a generalist LLM chatbot for health queries.Nat. Health https://doi.org/10.1038/s44360-026-00117-x(2026)
-
[6]
& Sand Aronsson, F
Moëll, B. & Sand Aronsson, F. Harm reduction strategies for thoughtful use of large language models in the medical domain.J. Med. Internet Res.27, e75849 (2025)
2025
-
[7]
Krupat, E., Wormwood, J., Schwartzstein, R. M. & Richards, J. B. Avoiding premature closure and reaching diagnostic accuracy: some key predictive factors.Med. Educ.51, 1127–1137 (2017)
2017
-
[8]
& Kumar, S
Kumar, B., Kanna, B. & Kumar, S. The pitfalls of premature closure: clinical decision-making in a case of aortic dissection.BMJ Case Rep.2011, bcr0820114594 (2011)
2011
-
[9]
& Costa-Alcaraz, A
Vázquez-Costa, M. & Costa-Alcaraz, A. M. Premature diagnostic closure: An avoidable type of error.Rev. Clínica Esp. Engl. Ed.213, 158–162 (2013)
2013
-
[10]
Handler, R., Sharma, S. & Hernandez-Boussard, T. The fragile intelligence of GPT-5 in medicine.Nat. Med.https://doi.org/10.1038/s41591-025-04008-8(2025)
-
[11]
Wu, D. et al. First, do NOHARM: towards clinically safe large language models. Preprint at https://doi.org/10.48550/ARXIV.2512.01241(2025)
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2512.01241(2025 2025
-
[12]
Goodman, R. S. et al. Accuracy and reliability of chatbot responses to physician questions. JAMA Netw. Open6, e2336483 (2023)
2023
-
[13]
Draelos, R. L. et al. Large language models provide unsafe answers to patient-posed medical questions.npj Digit. Med.9, 241 (2026)
2026
-
[14]
& Shah, N
Bedi, S., Jiang, Y., Chung, P., Koyejo, S. & Shah, N. Fidelity of medical reasoning in large language models.JAMA Netw. Open8, e2526021 (2025)
2025
-
[15]
Bean, A. M. et al. Reliability of LLMs as medical assistants for the general public: a randomized preregistered study.Nat. Med.32, 609–615 (2026)
2026
-
[16]
McCoy, L. G. et al. Assessment of large language models in clinical reasoning: a novel benchmarking study.NEJM AI2(2025)
2025
-
[17]
arXiv preprint arXiv:2506.09038 , year=
Kirichenko, P., Ibrahim, M., Chaudhuri, K. & Bell, S. J. AbstentionBench: reasoning LLMs fail on unanswerable questions. Preprint athttps://doi.org/10.48550/ARXIV.2506.09038 (2025). 12
-
[18]
Arora, R. K. et al. HealthBench: evaluating large language models towards improved human health. Preprint athttps://doi.org/10.48550/ARXIV.2505.08775(2025)
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.08775(2025 2025
-
[19]
Soskin Hicks, R. et al. HealthBench Professional: evaluating large lan- guage models on real clinician chats. Preprint at https://cdn.openai.com/ dd128428-0184-4e25-b155-3a7686c7d744/HealthBench-Professional.pdf(2026)
2026
-
[20]
Ethical implications of using general-purpose LLMs in clinical settings.BMC Med
Esmaeilzadeh, P. Ethical implications of using general-purpose LLMs in clinical settings.BMC Med. Inform. Decis. Mak.25, 342 (2025)
2025
-
[21]
Patil, R., Heston, T. F. & Bhuse, V. Prompt engineering in healthcare.Electronics13, 2961 (2024)
2024
-
[22]
& Chen, J
Savage, T., Nayak, A., Gallo, R., Rangan, E. & Chen, J. H. Diagnostic reasoning prompts reveal the potential for large language model interpretability in medicine.npj Digit. Med.7, 20 (2024)
2024
-
[23]
Zaghir, J. et al. Prompt engineering paradigms for medical applications: scoping review.J. Med. Internet Res.26, e60501 (2024)
2024
-
[24]
Brahman, F. et al. The art of saying no: contextual noncompliance in language models. Preprint athttps://doi.org/10.48550/ARXIV.2407.12043(2024)
-
[25]
Feng, S. et al. Don’t hallucinate, abstain: identifying LLM knowledge gaps via multi-LLM collaboration. InProc. 62nd Annual Meeting of the Association for Computational Linguistics 14664–14690 (ACL, 2024)
2024
-
[26]
Jiang, E. H. et al. Mitigating over-refusal in aligned large language models via inference-time activation energy. Preprint athttps://doi.org/10.48550/ARXIV.2510.08646(2025)
-
[27]
Chai, M. & Zomorrodi, A. R. Prompt engineering does not universally improve large language model performance across clinical decision-making tasks. Preprint athttps://doi.org/10. 48550/ARXIV.2512.22966(2025)
-
[28]
Yang, Y., Jin, Q., Huang, F. & Lu, Z. Adversarial prompt and fine-tuning attacks threaten medical large language models.Nat. Commun.16, 9011 (2025)
2025
-
[29]
& Powell, D
Mahajan, A., Obermeyer, Z., Daneshjou, R., Lester, J. & Powell, D. Cognitive bias in clinical large language models.npj Digit. Med.8, 428 (2025)
2025
-
[30]
& Armoundas, A
Christof, M. & Armoundas, A. A. Implications of integrating large language models into clinical decision making.Commun. Med.5, 490 (2025)
2025
-
[31]
& Yuksel, D
Griot, M., Hemptinne, C., Vanderdonckt, J. & Yuksel, D. Large language models lack essential metacognition for reliable medical reasoning.Nat. Commun.16, 642 (2025)
2025
-
[32]
Cruz, A. F., Hardt, M. & Mendler-Dünner, C. Evaluating language models as risk scores. Preprint athttps://doi.org/10.48550/ARXIV.2407.14614(2024)
-
[33]
Bao, H. et al. Position: general alignment has hit a ceiling; edge alignment must be taken seriously. Preprint athttps://doi.org/10.48550/arXiv.2602.20042(2026). 13
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.20042(2026 2026
-
[34]
Jin, D. et al. What disease does this patient have? A large-scale open domain question answering dataset from medical exams. Preprint at https://doi.org/10.48550/ARXIV.2009.13081 (2020)
-
[35]
Nimo, C. et al. AfriMed-QA: a Pan-African, multi-specialty, medical question-answering benchmark dataset. InProc. 63rd Annual Meeting of the Association for Computational Linguistics1948–1973 (ACL, 2025)
1973
-
[36]
Note on the sampling error of the difference between correlated proportions or percentages.Psychometrika12, 153–157 (1947)
McNemar, Q. Note on the sampling error of the difference between correlated proportions or percentages.Psychometrika12, 153–157 (1947)
1947
-
[37]
Woolson, R. F. Wilcoxon signed-rank test. InWiley Encyclopedia of Clinical Trials(Wiley, 2008). 14
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.