Small, Private Language Models as Teammates for Educational Assessment Design
Pith reviewed 2026-06-30 20:15 UTC · model grok-4.3
The pith
Small language models match large ones in generating pedagogically aligned assessment questions while supporting local private deployment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SLMs achieve competitive performance across key pedagogically motivated quality dimensions while enabling local, privacy-sensitive deployment. However, model-based evaluations also exhibit systematic inconsistencies and bias relative to expert ratings. These findings provide evidence to posit language models as bounded assistants in assessment workflows and underscore the necessity of Human-in-the-Loop.
What carries the argument
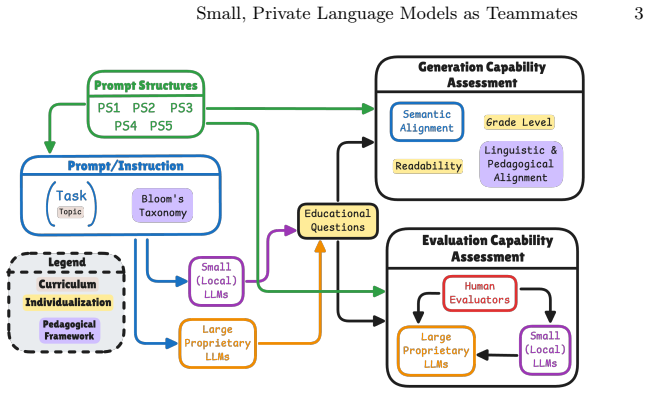
Systematic comparison of LLMs and SLMs on assessment question generation, scored via reproducible metrics aligned with Bloom's taxonomy levels and validated against expert-informed ratings.
If this is right
- SLMs can support local deployment for educational tasks that require data privacy.
- Model-based judging of generated questions introduces bias and cannot replace expert review.
- Language models function best as assistants rather than independent designers in assessment creation.
- Automated question generation research must incorporate deployment constraints and evaluation reliability.
Where Pith is reading between the lines
- Teacher tools could incorporate small models to create draft questions without sending student data to external servers.
- The approach could be extended to other taxonomies or subject areas to test where small models hold up best.
- Workflows that combine model generation with targeted human review may reduce teacher workload while preserving quality.
Load-bearing premise
The selected evaluation metrics and expert-informed ratings accurately capture pedagogical quality without significant bias or subjectivity.
What would settle it
A replication study with more questions and raters that finds either SLMs underperform LLMs on the quality metrics or that model judgments align closely with experts would challenge the central claims.
Figures
read the original abstract
Generative AI increasingly supports educational design tasks, e.g., through Large Language Models (LLMs), demonstrating the capability to design assessment questions that are aligned with pedagogical frameworks (e.g., Bloom's taxonomy). However, they often rely on subjective or limited evaluation methods; focus primarily on proprietary models; or rarely systematically examine generation, evaluation, or deployment constraints in real educational settings. Meanwhile, Small Language Models (SLMs) have emerged as local alternatives that better address privacy and resource limitations; yet their effectiveness for assessment tasks remains underexplored. To address this gap, we systematically compare LLMs and SLMs for assessment question design; evaluate generation quality across Bloom's taxonomy levels using reproducible, pedagogically grounded metrics; and further assess model-based judging against expert-informed evaluation by analyzing reliability and agreement patterns. Results show that SLMs achieve competitive performance across key pedagogically motivated quality dimensions while enabling local, privacy-sensitive deployment. However, model-based evaluations also exhibit systematic inconsistencies and bias relative to expert ratings. These findings provide evidence to posit language models as bounded assistants in assessment workflows; underscore the necessity of Human-in-the-Loop; and advance the automated educational question generation field by examining quality, reliability, and deployment-aware trade-offs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper systematically compares LLMs and SLMs for generating assessment questions aligned with Bloom's taxonomy. It evaluates generation quality via reproducible pedagogically grounded metrics, compares model-based judging to expert ratings for reliability and agreement, and concludes that SLMs deliver competitive performance on key quality dimensions while supporting local privacy-sensitive deployment, though model-based evaluations show systematic inconsistencies and bias relative to experts. The work positions language models as bounded assistants requiring human-in-the-loop oversight.
Significance. If the empirical comparisons and bias analyses hold with adequate controls and validation, the results would provide concrete evidence for deploying SLMs in educational workflows where privacy and resource constraints matter, while underscoring limitations of automated evaluation. This advances the automated question generation literature by jointly addressing quality, reliability, and deployment trade-offs rather than focusing solely on proprietary LLMs.
major comments (2)
- [Abstract / Methods] Abstract and methods description: no concrete details are supplied on the specific SLM/LLM instances, prompt templates, generation parameters, dataset size, or inter-rater agreement statistics for the expert ratings. These omissions are load-bearing for the central claim of 'competitive performance' and for the reported inconsistencies between model-based and expert evaluations.
- [Evaluation] Evaluation section: the pedagogically grounded metrics are described as 'reproducible' but no definitions, formulas, or validation against human judgments are provided in the available text, preventing assessment of whether they actually capture the intended Bloom's taxonomy dimensions without circularity or subjectivity.
minor comments (1)
- [Abstract] The abstract refers to 'systematic inconsistencies and bias' without quantifying effect sizes or providing example disagreement cases; a table or figure illustrating specific rating discrepancies would strengthen the presentation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on methodological transparency and metric definitions. These points identify areas where the submitted version could be strengthened for reproducibility. We address each below and have incorporated the requested details into the revised manuscript.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and methods description: no concrete details are supplied on the specific SLM/LLM instances, prompt templates, generation parameters, dataset size, or inter-rater agreement statistics for the expert ratings. These omissions are load-bearing for the central claim of 'competitive performance' and for the reported inconsistencies between model-based and expert evaluations.
Authors: We agree these specifics are essential for evaluating the 'competitive performance' claim and the model-expert discrepancies. The initial submission summarized the approach at a high level in the abstract and Methods overview but omitted instance-level details. In the revision we have expanded the Methods section (now 3.1) to specify: SLMs (Phi-2 2.7B, Gemma-2B, Mistral-7B), LLMs (GPT-4-turbo, Claude-3-Haiku), exact prompt templates (reproduced in new Appendix A), generation parameters (temperature=0.7, top-p=0.9, max tokens=256), dataset (240 questions, 40 per Bloom level across 6 levels), and expert inter-rater agreement (Fleiss' kappa=0.78 on a 20% overlap sample). These additions directly support the reported results without altering any findings. revision: yes
-
Referee: [Evaluation] Evaluation section: the pedagogically grounded metrics are described as 'reproducible' but no definitions, formulas, or validation against human judgments are provided in the available text, preventing assessment of whether they actually capture the intended Bloom's taxonomy dimensions without circularity or subjectivity.
Authors: The referee correctly notes that the submitted text did not include explicit formulas or validation statistics for the metrics. Section 4.2 described the metrics at a conceptual level (keyword overlap + embedding similarity to Bloom descriptors) but lacked the operational definitions. We have revised this section to add: (i) precise formulas for each metric (e.g., Bloom-Alignment Score = (1/6) * sum cosine_sim(embedding(q), descriptor_l) for level l), (ii) the full validation procedure against 50 expert-rated items (Pearson r=0.81 with expert Bloom assignments), and (iii) discussion of safeguards against circularity (metrics use fixed taxonomy descriptors independent of model output). These changes make the reproducibility claim verifiable. revision: yes
Circularity Check
No significant circularity
full rationale
This is an empirical comparison study of LLMs and SLMs for assessment question generation. The abstract and available text contain no equations, derivations, fitted parameters presented as predictions, or self-citations used to justify uniqueness theorems or ansatzes. All claims rest on external model outputs evaluated against expert ratings and pedagogically motivated metrics, with no internal reduction of results to the paper's own inputs by construction. The study is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- Selection of specific SLM and LLM instances
- Prompt templates and generation parameters
axioms (1)
- domain assumption Bloom's taxonomy levels provide a valid and sufficient framework for measuring assessment question quality
Reference graph
Works this paper leans on
-
[1]
Journal of the Medical Library Association: JMLA103(3), 152 (2015)
Adams, N.E.: Bloom’s taxonomy of cognitive learning objectives. Journal of the Medical Library Association: JMLA103(3), 152 (2015)
2015
-
[2]
Allison, J., Hwang, G.J., Mayer, R.E., Pellas, N., et al.: From generative ai to extended reality: Multidisciplinary perspectives on the challenges, opportunities, and future of educational computing (2025)
2025
-
[3]
Vanderbilt University Center for Teaching 12(05), 2023 (2010)
Armstrong, P.: Bloom’s taxonomy. Vanderbilt University Center for Teaching 12(05), 2023 (2010)
2023
-
[4]
Blooms Taxonomy LM Analysis.https://github.com/kastle-lab/ bloom-taxonomy-lm-analysis, accessed: 2026-01-21
2026
-
[5]
In: AIED (2025)
Borchers, C., Shou, T.: Can large language models match tutoring system adap- tivity? a benchmarking study. In: AIED (2025)
2025
-
[6]
In: AIED (2023)
Bulathwela, S., Muse, H., Yilmaz, E.: Scalable educational question generation with pre-trained language models. In: AIED (2023)
2023
-
[7]
Elkins, S., Kochmar, E., Serban, I., Cheung, J.C.: How useful are educational questions generated by large language models? In: International Conference on Artificial Intelligence in Education. pp. 536–542 (2023)
2023
-
[8]
In: AIED (2024)
Fawzi, F., Balan, S., et al.: Towards human-like educational question generation with small language models. In: AIED (2024)
2024
-
[9]
Journal of applied psychology34(6), 384 (1950)
Flesch, R.: Measuring the level of abstraction. Journal of applied psychology34(6), 384 (1950)
1950
-
[10]
Journal of applied psychology32(3), 221 (1948)
Flesch, R.: A new readability yardstick. Journal of applied psychology32(3), 221 (1948)
1948
-
[11]
In: AIED (2024)
Hwang, K., Wang, K., et al.: Towards automated multiple choice question genera- tion and evaluation: aligning with bloom’s taxonomy. In: AIED (2024)
2024
-
[12]
Ilkou, E., Alexiou, T., Antoniou, G., Viberg, O.: Dyslexia and ai: Do language models align with dyslexic style guide criteria? In: AIED (2025)
2025
-
[13]
In: Proceedings of ISWC’24 (2024)
Ilkou, E., Linzbach, S., Wallat, J.: Hybrid evaluation of socratic questioning for teaching. In: Proceedings of ISWC’24 (2024)
2024
-
[14]
Master’s thesis, Wright State University (2025) Small, Private Language Models as Teammates 15
Jaldi, C.D.: Impact of Graph Structures for RAG Outcomes in LLMs. Master’s thesis, Wright State University (2025) Small, Private Language Models as Teammates 15
2025
-
[15]
Journal of Web Semantics85, 100857 (2025)
Jaldi, C.D., Ilkou, E., Schroeder, N., Shimizu, C.: Education in the era of neu- rosymbolic ai. Journal of Web Semantics85, 100857 (2025)
2025
-
[16]
Kabir,M.R.,Lin,F.:Anllm-poweredadaptivepracticingsystem.In:LLM@AIED. pp. 43–52 (2023)
2023
-
[17]
Learning and individual differences (2023)
Kasneci, E., et al.: Chatgpt for good? on opportunities and challenges of large language models for education. Learning and individual differences (2023)
2023
-
[18]
arXiv preprint arXiv:2405.11579 , year=
Maity, S., Deroy, A., Sarkar, S.: Exploring the capabilities of prompted large language models in educational and assessment applications. arXiv preprint arXiv:2405.11579 (2024)
-
[19]
Computers in Human Behavior: Artificial Humans2(1), 100053 (2024)
Memarian, B., Doleck, T.: Human-in-the-loop in artificial intelligence in education: A review and entity-relationship (er) analysis. Computers in Human Behavior: Artificial Humans2(1), 100053 (2024)
2024
-
[20]
Computers and Education: Artificial Intelligence (2024)
Meyer, J., et al.: Using llms to bring evidence-based feedback into the classroom: Ai-generated feedback increases secondary students’ text revision, motivation, and positive emotions. Computers and Education: Artificial Intelligence (2024)
2024
-
[21]
Thinking Skills and Creativity p
Raz, T., Luchini, S.A., et al.: Automated scoring of question complexity with trans- former language models. Thinking Skills and Creativity p. 102090 (2025)
2025
-
[22]
arXiv preprint arXiv:2506.05925 (2025)
Reza, Z., Mazur, A., Dugdale, M., Ray-Chaudhuri, R.: Small models, big support: A local llm framework for teacher-centric content creation and assessment using rag and cag. arXiv preprint arXiv:2506.05925 (2025)
-
[23]
In: International Conference on Artificial Intelligence in Education (2024)
Scaria, N., Dharani Chenna, S., et al.: Automated educational question generation at different bloom’s skill levels using large language models: Strategies and evalu- ation. In: International Conference on Artificial Intelligence in Education (2024)
2024
-
[24]
arXiv preprint arXiv:2009.07118 (2020)
Schick, T., Schütze, H.: It’s not just size that matters: Small language models are also few-shot learners. arXiv preprint arXiv:2009.07118 (2020)
-
[25]
In: AIED (2024)
Stamper, J., Xiao, R., Hou, X.: Enhancing llm-based feedback: Insights from in- telligent tutoring systems and the learning sciences. In: AIED (2024)
2024
-
[26]
arXiv preprint arXiv:2408.02442 (2024)
Tam, Z.R., Wu, Lin, et al.: Let me speak freely? a study on the impact of format restrictions on performance of large language models. arXiv preprint arXiv:2408.02442 (2024)
-
[27]
Umoke, C.C., Nwangbo, S.O., Onwe, O.A.: The governance of ai in education: Developing ethical policy frameworks for adaptive learning technologies
-
[28]
arXiv preprint arXiv:2409.15981 (2024)
Vanzo, A., Chowdhury, S.P., et al.: Gpt-4 as a homework tutor can improve student engagement and learning outcomes. arXiv preprint arXiv:2409.15981 (2024)
-
[29]
arXiv preprint arXiv:2402.12702 (2024)
Vuruma, S.K.R., Margetts, A., Su, J., Ahmed, F., Srivastava, B.: From cloud to edge: Rethinking generative ai for low-resource design challenges. arXiv preprint arXiv:2402.12702 (2024)
-
[30]
In: AIED (2022)
Wang, Z., Valdez, J., et al.: Towards human-like educational question generation with large language models. In: AIED (2022)
2022
-
[31]
ASM Science Journal19, 1895 (2024)
Zhang, H., Leong, W.: Transforming rural and underserved schools with ai-powered education solutions. ASM Science Journal19, 1895 (2024)
2024
-
[32]
Educational Psychology Review (2024)
Zhang, S., Palaguachi, C., Pitera, M., Jaldi, C.D., Schroeder, N.L., et al.: Semi- automating the scoping review process: Is it worthwhile? a methodological evalu- ation. Educational Psychology Review (2024)
2024
-
[33]
BERTScore: Evaluating Text Generation with BERT
Zhang, T., Kishore, V., Wu, F., Weinberger, K.Q., Artzi, Y.: Bertscore: Evaluating text generation with bert. arXiv preprint arXiv:1904.09675 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[34]
Ad- vances in neural information processing systems (2023)
Zheng, L., et al.: Judging llm-as-a-judge with mt-bench and chatbot arena. Ad- vances in neural information processing systems (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.