COPRA: Conditional Parameter Adaptation with Reinforcement Learning for Video Anomaly Detection
Pith reviewed 2026-05-19 16:09 UTC · model grok-4.3
The pith
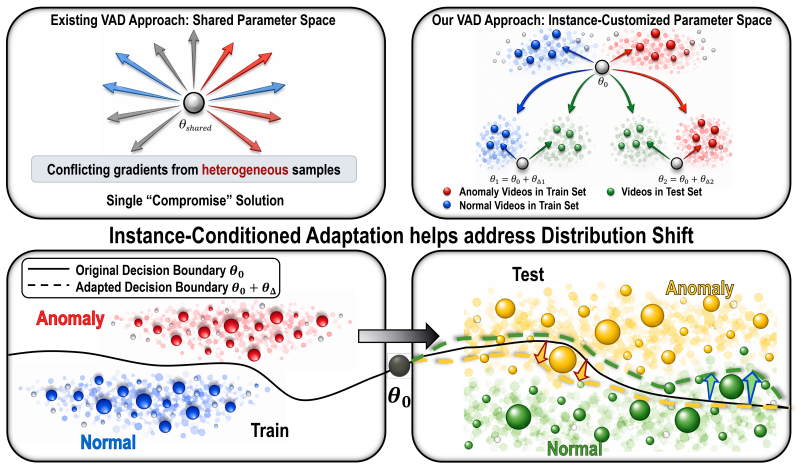
COPRA uses reinforcement learning to generate input-specific parameter updates that dynamically adapt a frozen vision-language model to each video segment for anomaly detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
COPRA is a conditional parameter adaptation framework that employs reinforcement learning to produce input-specific parameter updates, thereby dynamically adapting a frozen vision-language model to each video segment during both training and inference and resolving mismatches in data distribution and model configuration that limit prior VLM-based video anomaly detection methods.
What carries the argument
A reinforcement learning policy that outputs input-conditioned parameter updates applied to a frozen VLM for each video segment.
If this is right
- COPRA outperforms static adaptation baselines on in-domain video anomaly detection benchmarks.
- It improves generalization to cross-domain settings involving unseen environments or anomaly types.
- The same adaptation mechanism transfers to unseen tasks such as multiple-choice video question answering and dense captioning.
- It functions as a weight-space generation approach supporting scalable and context-aware video understanding.
Where Pith is reading between the lines
- Keeping the base VLM frozen while generating small per-segment updates could lower the cost of deploying such models across many different video domains.
- The approach may suit real-time video monitoring where input statistics change over time without requiring model reloading.
- Conditional parameter generation of this form could be tested on other foundation models facing similar train-inference distribution shifts in vision or multimodal settings.
Load-bearing premise
Reinforcement learning can stably generate useful input-conditioned parameter updates for a frozen VLM without instability or extensive per-domain hyperparameter tuning when new video distributions appear.
What would settle it
On a held-out video dataset with clear distribution shift, COPRA matching or underperforming a static post-training adaptation baseline in detection accuracy would falsify the central claim.
Figures






read the original abstract
Vision-language models (VLMs) have shown strong performance in video anomaly detection (VAD) while providing interpretable predictions. However, existing VLM-based VAD methods suffer from a fundamental mismatch between training and inference in both data distribution and model configuration. First, most approaches rely on static post-training adaptation, limiting generalization under distribution shifts such as unseen environments or anomaly types. Second, they train VLMs on sparse frames from long videos, but perform inference on densely sampled short segments, creating inconsistencies between training and testing. To address these limitations, we propose COPRA, a conditional parameter adaptation framework for VLM-based VAD. Instead of fixed prompts or shared parameter updates, COPRA generates input-specific parameter updates to dynamically adapt a frozen VLM for each video segment during both training and inference. Experiments show strong performance on standard VAD benchmarks, consistently outperforming static baselines in both in-domain and cross-domain settings. Moreover, COPRA generalizes beyond VAD to unseen tasks such as multiple-choice Video Question Answering and Dense Captioning. These results highlight COPRA as an effective weight-space generation framework for scalable, adaptive, and context-aware video understanding. The code will be released at https://github.com/THE-MALT-LAB/COPRA
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes COPRA, a conditional parameter adaptation framework that employs reinforcement learning to generate input-specific parameter updates for dynamically adapting a frozen vision-language model (VLM) on a per-video-segment basis. This addresses mismatches in data distribution and model configuration between training (sparse frames from long videos) and inference (dense short segments) in video anomaly detection (VAD). The method is claimed to outperform static baselines in both in-domain and cross-domain settings on standard VAD benchmarks while also generalizing to unseen tasks such as multiple-choice Video Question Answering and Dense Captioning. Code release is promised.
Significance. If the results hold under scrutiny, the work offers a potentially impactful approach to making VLMs more adaptive and generalizable for video tasks without full retraining, by operating in weight space via RL-generated deltas. Strengths include the explicit handling of train-inference mismatch, the cross-domain and cross-task generalization claims, and the commitment to code release which aids reproducibility. This could influence future designs for context-aware video understanding systems.
major comments (3)
- [Section 3.2] Section 3.2 (Policy Network): The architecture and conditioning mechanism of the policy network that produces input-specific parameter deltas are described at a high level but lack sufficient implementation details (e.g., input features from the video segment, output parameterization of the updates, and any regularization to prevent large deviations from the frozen VLM weights). This is load-bearing for the central claim of stable, useful conditional adaptation.
- [Section 4.2] Section 4.2 and Table 3: The reward formulation for the RL objective is not specified in enough detail to evaluate alignment with VAD performance metrics or robustness to distribution shifts; without this, it is difficult to determine whether reported gains rely on dataset-specific tuning or generalize as claimed.
- [Section 4.3] Section 4.3 (Ablations): No ablation studies isolate the contribution of the RL component versus simpler conditioning mechanisms (e.g., direct feature concatenation or hypernetwork baselines), which is necessary to substantiate that reinforcement learning is the key enabler rather than the overall adaptation idea.
minor comments (3)
- [Abstract] Abstract: The claim of 'strong performance' would be strengthened by briefly noting the specific metrics (e.g., AUC or F1) and number of benchmarks used.
- [Figure 2] Figure 2: The framework diagram would benefit from explicit arrows or labels indicating the flow of the RL-generated parameter updates during inference.
- [Related Work] Related Work: A short paragraph contrasting COPRA with prior parameter-efficient adaptation methods (e.g., LoRA or prompt tuning in VLMs) would clarify novelty.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and will revise the paper to provide the requested clarifications and additional experiments. These changes will improve the technical exposition and strengthen the presentation of our contributions.
read point-by-point responses
-
Referee: [Section 3.2] Section 3.2 (Policy Network): The architecture and conditioning mechanism of the policy network that produces input-specific parameter deltas are described at a high level but lack sufficient implementation details (e.g., input features from the video segment, output parameterization of the updates, and any regularization to prevent large deviations from the frozen VLM weights). This is load-bearing for the central claim of stable, useful conditional adaptation.
Authors: We agree that Section 3.2 would benefit from greater specificity to support reproducibility and the central claims. In the revised manuscript we will expand the section to describe: (1) the precise input features to the policy network, which are pooled visual embeddings from the frozen VLM encoder applied to the current video segment; (2) the output parameterization, in which the policy produces low-rank deltas (LoRA-style) for selected attention and feed-forward layers; and (3) the regularization, consisting of an L2 penalty on delta magnitude together with a KL term that keeps the adapted distribution close to the original frozen weights. We will also add pseudocode and a schematic diagram of the policy network. revision: yes
-
Referee: [Section 4.2] Section 4.2 and Table 3: The reward formulation for the RL objective is not specified in enough detail to evaluate alignment with VAD performance metrics or robustness to distribution shifts; without this, it is difficult to determine whether reported gains rely on dataset-specific tuning or generalize as claimed.
Authors: We thank the referee for noting this gap. The reward is constructed to align directly with VAD evaluation metrics while promoting robustness: it comprises a primary term that rewards accurate anomaly scoring (frame-level AUC) and a consistency term across consecutive segments, plus a small penalty on policy output magnitude to discourage overfitting to training distributions. In the revision we will present the complete mathematical definition of the reward, list all weighting coefficients, and add a short analysis of reward-component sensitivity together with results under alternative formulations to illustrate generalization behavior. revision: yes
-
Referee: [Section 4.3] Section 4.3 (Ablations): No ablation studies isolate the contribution of the RL component versus simpler conditioning mechanisms (e.g., direct feature concatenation or hypernetwork baselines), which is necessary to substantiate that reinforcement learning is the key enabler rather than the overall adaptation idea.
Authors: We accept that the existing ablations in Section 4.3 compare COPRA primarily against static and non-conditional baselines and do not yet isolate the RL policy against simpler conditioning alternatives. In the revised version we will add new ablation experiments that implement (i) direct feature concatenation into the VLM and (ii) a hypernetwork baseline that generates the same parameter updates without RL. Performance on the standard VAD benchmarks will be reported for these variants, allowing readers to assess the specific benefit of the reinforcement-learning-driven policy. revision: yes
Circularity Check
No significant circularity; empirical method without self-referential derivations
full rationale
The paper proposes an empirical RL-based framework for input-conditioned parameter adaptation of frozen VLMs, evaluated via experiments on VAD benchmarks and generalization tasks. No equations, derivations, or fitted parameters are presented that reduce any claimed prediction or result to the inputs by construction. The method description relies on standard RL concepts applied to parameter generation, with performance claims grounded in reported benchmark comparisons rather than self-citation chains or definitional equivalences. This is a standard empirical contribution with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
COPRA generates input-specific parameter updates to dynamically adapt a frozen VLM for each video segment during both training and inference
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We train COPRA end-to-end by learning a 'policy' g_φ2 that maps visual conditioning signals to instance-specific parameter updates
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Unlocking vision-language models for video anomaly detection via fine-grained prompting , author=. WACV , pages=
-
[2]
Real-world anomaly detection in surveillance videos , author=. CVPR , pages=
-
[3]
Workshop on Neural Network Weights as a New Data Modality , year=
Uncovering Latent Chain of Thought Vectors in Large Language Models , author=. Workshop on Neural Network Weights as a New Data Modality , year=
-
[4]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks , author=. CVPR , pages=
-
[5]
A Survey of Weight Space Learning: Understanding, Representation, and Generation , author=. 2026 , eprint=
work page 2026
-
[6]
Huang, Chao and Shi, Yushu and Wen, Jie and Wang, Wei and Xu, Yong and Cao, Xiaochun , booktitle =. Ex-. 2025 , volume =
work page 2025
-
[7]
Zhang, Huaxin and Xu, Xiaohao and Wang, Xiang and Zuo, Jialong and Han, Chuchu and Huang, Xiaonan and Gao, Changxin and Wang, Yuehuan and Sang, Nong , journal=
-
[8]
Zhu, Liyun and Chen, Qixiang and Shen, Xi and Cun, Xiaodong , journal=
-
[9]
Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time , author =. ICML , pages =. 2022 , volume =
work page 2022
- [10]
- [11]
-
[12]
Self-Supervised Representation Learning on Neural Network Weights for Model Characteristic Prediction , author=. NeurIPS , year=
-
[13]
Learning to Learn with Generative Models of Neural Network Checkpoints , author=. 2022 , eprint=
work page 2022
-
[14]
What does a platypus look like? generating customized prompts for zero-shot image classification , author=. ICCV , pages=
-
[15]
Video Anomaly Detection and Explanation via Large Language Models , author=. 2024 , eprint=
work page 2024
-
[16]
Visual Instruction Tuning , url =
Liu, Haotian and Li, Chunyuan and Wu, Qingyang and Lee, Yong Jae , booktitle =. Visual Instruction Tuning , url =
-
[17]
MLE-UVAD: Minimal Latent Entropy Autoencoder for Fully Unsupervised Video Anomaly Detection
Yuang Geng and Junkai Zhou and Kang Yang and Pan He and Zhuoyang Zhou and Jose C. Principe and Joel Harley and Ivan Ruchkin , year=. 2603.23868 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
- [18]
-
[19]
Edward J Hu and yelong shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=. Lo. 2022 , url=
work page 2022
-
[20]
Thuau, S\'ebastien and Haidar, Siba and Chelouah, Rachid , booktitle=. Federated Learning for Video Violence Detection: Complementary Roles of Lightweight CNNs and Vision-Language Models for Energy-Efficient Use , year=
-
[21]
Borodin, Kirill and Kondrashov, Kirill and Vasiliev, Nikita and Gladkova, Ksenia and Larina, Inna and Gorodnichev, Mikhail and Mkrtchian, Grach , TITLE =. Journal of Imaging , VOLUME =. 2025 , NUMBER =
work page 2025
-
[22]
Proceedings of the 33rd ACM International Conference on Multimedia , pages =
Cai, Zhaolin and Li, Fan and Zheng, Ziwei and Qin, Yanjun , title =. Proceedings of the 33rd ACM International Conference on Multimedia , pages =. 2025 , isbn =. doi:10.1145/3746027.3755575 , abstract =
-
[23]
Ye, Muchao and Liu, Weiyang and He, Pan , title =. CVPR , month =. 2025 , pages =
work page 2025
-
[24]
Ubnormal: New benchmark for supervised open-set video anomaly detection , author=. CVPR , pages=
-
[25]
Zhang, Huaxin and Xu, Xiaohao and Wang, Xiang and Zuo, Jialong and Huang, Xiaonan and Gao, Changxin and Zhang, Shanjun and Yu, Li and Sang, Nong , booktitle=. Holmes-. 2025 , volume=
work page 2025
-
[26]
Yang, Yuchen and Lee, Kwonjoon and Dariush, Behzad and Cao, Yinzhi and Lo, Shao-Yuan , title =. ECCV , pages =. 2024 , isbn =. doi:10.1007/978-3-031-73004-7_18 , abstract =
-
[27]
Harnessing Large Language Models for Training-free Video Anomaly Detection , author=. CVPR , pages=
-
[28]
Shuai Bai and Keqin Chen and Xuejing Liu and Jialin Wang and Wenbin Ge and Sibo Song and Kai Dang and Peng Wang and Shijie Wang and Jun Tang and Humen Zhong and Yuanzhi Zhu and Mingkun Yang and Zhaohai Li and Jianqiang Wan and Pengfei Wang and Wei Ding and Zheren Fu and Yiheng Xu and Jiabo Ye and Xi Zhang and Tianbao Xie and Zesen Cheng and Hang Zhang and...
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling , author=. 2025 , eprint=
work page 2025
-
[30]
Liu, Haotian and Li, Chunyuan and Li, Yuheng and Lee, Yong Jae , title =. CVPR , month =. 2024 , pages =
work page 2024
-
[31]
The CropAndWeed Dataset: A Multi-Modal Learning Approach for Efficient Crop and Weed Manipulation
Thakare, Kamalakar Vijay and Raghuwanshi, Yash and Dogra, Debi Prosad and Choi, Heeseung and Kim, Ig-Jae , booktitle =. 2023 , volume =. doi:10.1109/WACV56688.2023.00550 , url =
-
[32]
Zaigham and Mahmood, Arif and Khan, M
Zaheer, M. Zaigham and Mahmood, Arif and Khan, M. Haris and Segu, Mattia and Yu, Fisher and Lee, Seung-Ik , booktitle=. Generative Cooperative Learning for Unsupervised Video Anomaly Detection , year=
-
[33]
Learning Memory-guided Normality for Anomaly Detection , author=. CVPR , pages=
-
[34]
Gong, Dong and Liu, Lingqiao and Le, Vuong and Saha, Budhaditya and Mansour, Moussa Reda and Venkatesh, Svetha and Van Den Hengel, Anton , booktitle=. Memorizing Normality to Detect Anomaly: Memory-Augmented Deep Autoencoder for Unsupervised Anomaly Detection , year=
-
[35]
URL https://ieeexplore.ieee.org/document/ 10658325/
Wu, Peng and Zhou, Xuerong and Pang, Guansong and Sun, Yujia and Liu, Jing and Wang, Peng and Zhang, Yanning , booktitle =. 2024 , volume =. doi:10.1109/CVPR52733.2024.01732 , url =
-
[36]
Zhou, Hang and Yu, Junqing and Yang, Wei , title =. AAAI , articleno =. 2023 , isbn =. doi:10.1609/aaai.v37i3.25489 , abstract =
-
[37]
Wu, Peng and Zhou, Xuerong and Pang, Guansong and Zhou, Lingru and Yan, Qingsen and Wang, Peng and Zhang, Yanning , title =. AAAI , articleno =. 2024 , isbn =. doi:10.1609/aaai.v38i6.28423 , abstract =
-
[38]
Text Prompt with Normality Guidance for Weakly Supervised Video Anomaly Detection , year=
Yang, Zhiwei and Liu, Jing and Wu, Peng , booktitle=. Text Prompt with Normality Guidance for Weakly Supervised Video Anomaly Detection , year=
-
[39]
Joo, Hyekang Kevin and Vo, Khoa and Yamazaki, Kashu and Le, Ngan , booktitle=. 2023 , volume=
work page 2023
-
[40]
Chen, Yingxian and Liu, Zhengzhe and Zhang, Baoheng and Fok, Wilton and Qi, Xiaojuan and Wu, Yik-Chung , title =. AAAI , articleno =. 2023 , isbn =. doi:10.1609/aaai.v37i1.25112 , abstract =
-
[41]
Self-Training Multi-Sequence Learning with Transformer for Weakly Supervised Video Anomaly Detection , author=. AAAI , year=
-
[42]
Tian, Yu and Pang, Guansong and Chen, Yuanhong and Singh, Rajvinder and Verjans, Johan W. and Carneiro, Gustavo , booktitle =. 2021 , volume =. doi:10.1109/ICCV48922.2021.00493 , url =
-
[43]
Scale-aware spatio-temporal relation learning for video anomaly detection , author=. ECCV , pages=. 2022 , organization=
work page 2022
-
[44]
and Abdel-Aty, Mohamed , title =
Kim, Younggun and Abdelrahman, Ahmed S. and Abdel-Aty, Mohamed , title =. ICCV , month =. 2025 , pages =
work page 2025
-
[45]
Yao, Yu and Wang, Xizi and Xu, Mingze and Pu, Zelin and Wang, Yuchen and Atkins, Ella and Crandall, David J. , journal=. 2023 , volume=. doi:10.1109/TPAMI.2022.3150763 , url =
- [46]
-
[47]
Shen, Haozhan and Liu, Peng and Li, Jingcheng and Fang, Chunxin and Ma, Yibo and Liao, Jiajia and Shen, Qiaoli and Zhang, Zilun and Zhao, Kangjia and Zhang, Qianqian and others , journal=
-
[48]
Not only Look, but also Listen: Learning Multimodal Violence Detection under Weak Supervision , author=. ECCV , year=
-
[49]
SPICE : Semantic Propositional Image Caption Evaluation
Anderson, Peter and Fernando, Basura and Johnson, Mark and Gould, Stephen. SPICE : Semantic Propositional Image Caption Evaluation. ECCV. 2016
work page 2016
-
[50]
METEOR : An Automatic Metric for MT Evaluation with High Levels of Correlation with Human Judgments
Lavie, Alon and Agarwal, Abhaya. METEOR : An Automatic Metric for MT Evaluation with High Levels of Correlation with Human Judgments. Proceedings of the Second Workshop on Statistical Machine Translation. 2007
work page 2007
-
[51]
COMET : A Neural Framework for MT Evaluation
Rei, Ricardo and Stewart, Craig and Farinha, Ana C and Lavie, Alon. COMET : A Neural Framework for MT Evaluation. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.213
-
[52]
ROUGE : A Package for Automatic Evaluation of Summaries
Lin, Chin-Yew. ROUGE : A Package for Automatic Evaluation of Summaries. Text Summarization Branches Out. 2004
work page 2004
-
[53]
Bleu: a Method for Automatic Evaluation of Machine Translation , booktitle =
Papineni, Kishore and Roukos, Salim and Ward, Todd and Zhu, Wei-Jing. B leu: a Method for Automatic Evaluation of Machine Translation. Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. 2002. doi:10.3115/1073083.1073135
-
[54]
Lawrence Zitnick and Devi Parikh , booktitle=
Ramakrishna Vedantam and C. Lawrence Zitnick and Devi Parikh , booktitle=. 2014 , pages=
work page 2014
-
[55]
Wu, Jhih-Ciang and Hsieh, He-Yen and Chen, Ding-Jie and Fuh, Chiou-Shann and Liu, Tyng-Luh , title =. ECCV , pages =. 2022 , isbn =. doi:10.1007/978-3-031-19778-9_42 , abstract =
- [56]
-
[57]
Lu, Cewu and Shi, Jianping and Jia, Jiaya , title =. ICCV , pages =. 2013 , isbn =. doi:10.1109/ICCV.2013.338 , abstract =
-
[58]
Gods: Generalized one-class discriminative subspaces for anomaly detection , author=. ICCV , pages=
-
[59]
Thakare, Kamalakar Vijay and Dogra, Debi Prosad and Choi, Heeseung and Kim, Haksub and Kim, Ig-Jae , title =. 2023 , issue_date =. doi:10.1016/j.patcog.2023.109567 , journal =
-
[60]
Fang, Jianwu and Yan, Dingxin and Qiao, Jiahuan and Xue, Jianru and Wang, He and Li, Sen , booktitle=. 2019 , organization=
work page 2019
-
[61]
Silhouettes: A graphical aid to the in- terpretation and validation of cluster analysis,
Peter J. Rousseeuw , keywords =. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis , journal =. 1987 , issn =. doi:https://doi.org/10.1016/0377-0427(87)90125-7 , url =
-
[62]
Journal of Machine Learning Research , year =
Laurens van der Maaten and Geoffrey Hinton , title =. Journal of Machine Learning Research , year =
-
[63]
Scaling Sentence Embeddings with Large Language Models
Jiang, Ting and Huang, Shaohan and Luan, Zhongzhi and Wang, Deqing and Zhuang, Fuzhen. Scaling Sentence Embeddings with Large Language Models. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.181
-
[64]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models , author=. 2025 , eprint=
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.