On the Fragility of Data Attribution When Learning Is Distributed
Pith reviewed 2026-05-19 15:11 UTC · model grok-4.3
The pith
A single participant can inflate its measured attribution value in distributed training while preserving global utility.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
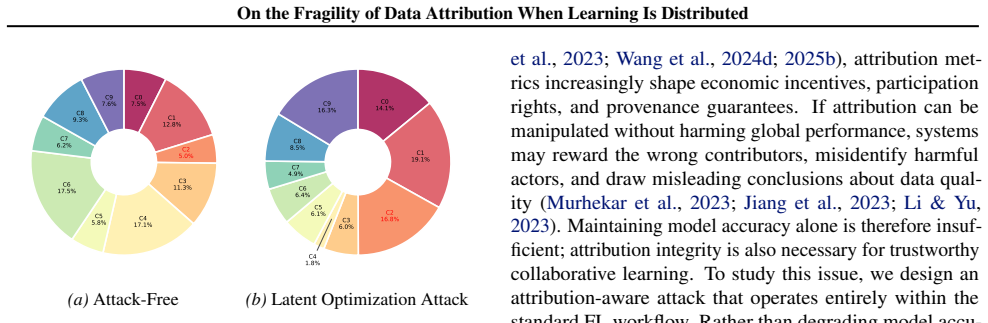
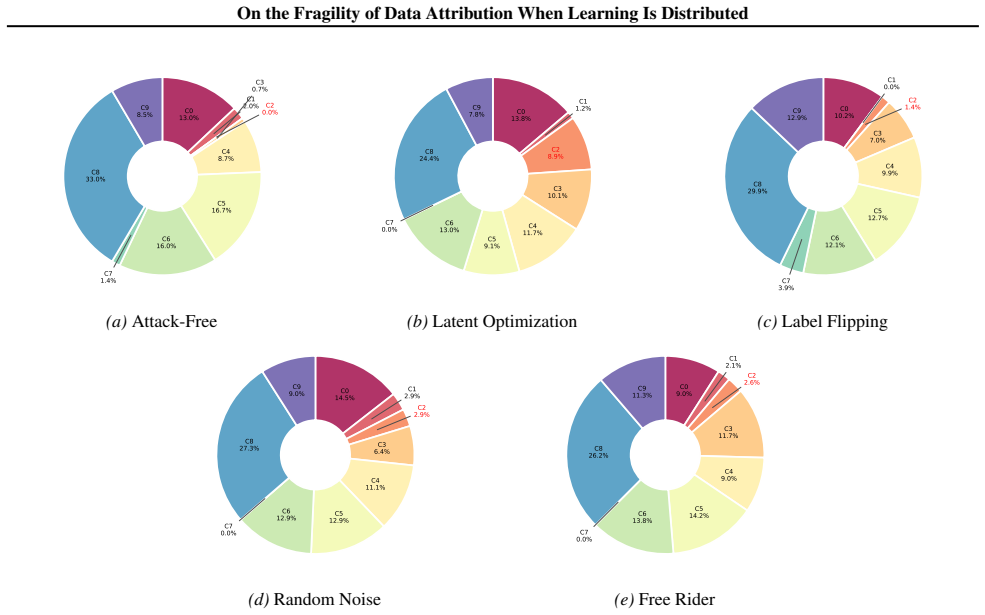
The central claim is that attribution values do not faithfully reflect participants' contributions because a single client in a standard distributed training workflow can use latent optimization to inject small synthetic batches. These batches preserve global utility while exploiting non-IID label coverage and the sensitivities of marginal-utility evaluators, consistently increasing the adversary's attribution value and reshaping the relative attribution structure among benign clients across datasets, models, and evaluators without degrading accuracy.
What carries the argument
The attribution-first attack that uses latent optimization to inject small synthetic batches exploiting non-IID label coverage and marginal-utility evaluator sensitivities.
If this is right
- Attribution methods fail to accurately measure individual contributions when training data is distributed and non-IID.
- A single malicious client can increase its own attribution score and change the ranking of benign participants.
- Global model accuracy stays the same after the attack.
- Existing geometry-based detection methods do not flag the injected batches.
- The vulnerability holds for multiple marginal-utility attribution evaluators.
Where Pith is reading between the lines
- Incentive systems that pay participants based on attribution scores may need new safeguards against synthetic data injection.
- The same manipulation tactic could appear in federated learning deployments where clients control their local data.
- Future evaluators might add checks for label-distribution anomalies introduced by small batches.
- Testing the attack with real-world non-IID partitions from production systems would reveal practical impact.
Load-bearing premise
Standard marginal-utility attribution evaluators remain sensitive to small synthetic batches that exploit non-IID label coverage in distributed settings.
What would settle it
Running the attack on a new dataset and model combination and observing no increase in the adversary's attribution value or a drop in final accuracy would falsify the claim.
Figures














read the original abstract
Data attribution has become an important component of pricing, auditing, and governance in machine learning pipelines, yet most attribution methods implicitly assume that attribution values faithfully reflect participants' contributions. We show that this assumption can fail: a single participant in a standard distributed training workflow can substantially inflate its measured attribution value while preserving global utility. Our attribution-first attack uses latent optimization to inject small synthetic batches that preserve utility while exploiting non-IID label coverage and evaluator sensitivities. Across datasets, models, and multiple marginal-utility evaluators, the attack consistently increases the adversary's attribution value and reshapes the relative attribution structure among benign clients without degrading accuracy or triggering geometry-based defenses. These results show that attribution itself forms a new attack surface and motivate the development of attribution-robust and incentive-compatible scoring mechanisms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that data attribution methods are fragile in distributed machine learning settings. A single participant in a standard distributed training workflow can substantially inflate its measured attribution value by using an attribution-first attack that employs latent optimization to inject small synthetic batches. These batches exploit non-IID label coverage and evaluator sensitivities while preserving global model utility, accuracy, and avoiding geometry-based defenses. The attack is shown to consistently increase the adversary's attribution and reshape relative attributions among benign clients across multiple datasets, models, and marginal-utility evaluators.
Significance. If the attack is feasible within the constraints of a standard participant (local data and global model only), the result would be significant for highlighting a new attack surface in attribution mechanisms used for pricing, auditing, and governance in ML pipelines. The empirical consistency across settings provides concrete evidence that attribution does not always faithfully reflect contributions, motivating development of attribution-robust and incentive-compatible scoring. The work's focus on marginal-utility evaluators and utility preservation is a strength, as is the demonstration that the attack evades existing defenses.
major comments (2)
- [Abstract] Abstract: The central claim that 'a single participant in a standard distributed training workflow' can execute the attack is load-bearing but potentially undermined by reliance on 'latent optimization to inject small synthetic batches'. Latent optimization typically presupposes access to a pre-trained generative model (VAE/GAN) and auxiliary training resources, which are not part of standard distributed protocols where clients receive only local data and the current global model. The manuscript should either demonstrate a purely local-data variant or explicitly bound the attack's requirements.
- [Experimental Results] Experimental Results: The abstract reports consistent success across datasets, models, and evaluators, but provides no error bars, exact attack hyperparameters, ablation details on synthetic batch size, or sensitivity analysis to non-IID label coverage. These omissions make it difficult to assess whether the reported attribution inflation is robust or sensitive to implementation choices.
minor comments (2)
- [Abstract] Abstract: The phrase 'attribution-first attack' is used without a brief inline definition or contrast to utility-focused attacks, which could improve immediate clarity for readers unfamiliar with the framing.
- [Notation] Notation: Attribution value symbols and evaluator definitions could be introduced with a short table or equation reference in the early sections to reduce reliance on later definitions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We provide detailed responses to each major comment below and outline the revisions we plan to make.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'a single participant in a standard distributed training workflow' can execute the attack is load-bearing but potentially undermined by reliance on 'latent optimization to inject small synthetic batches'. Latent optimization typically presupposes access to a pre-trained generative model (VAE/GAN) and auxiliary training resources, which are not part of standard distributed protocols where clients receive only local data and the current global model. The manuscript should either demonstrate a purely local-data variant or explicitly bound the attack's requirements.
Authors: We agree that the attack's reliance on latent optimization requires clarification regarding the resources needed. Our implementation uses a pre-trained VAE for optimizing in the latent space to create synthetic batches that exploit the attribution mechanism. This is not strictly limited to local data and the global model alone. In the revised manuscript, we will explicitly bound the attack requirements by stating that the adversary has access to a pre-trained generative model (e.g., trained on public datasets similar to the task), which is a reasonable assumption in many practical settings but not universal. We will not demonstrate a purely local-data variant in this work as it would require a fundamentally different attack strategy, but we will discuss this limitation and its implications for the attack's applicability. revision: partial
-
Referee: [Experimental Results] Experimental Results: The abstract reports consistent success across datasets, models, and evaluators, but provides no error bars, exact attack hyperparameters, ablation details on synthetic batch size, or sensitivity analysis to non-IID label coverage. These omissions make it difficult to assess whether the reported attribution inflation is robust or sensitive to implementation choices.
Authors: We appreciate this observation and agree that these details are important for evaluating the robustness of our findings. We will revise the experimental section to include error bars based on multiple runs with different random seeds, provide the precise hyperparameters used in the latent optimization process, add ablation experiments on the synthetic batch size, and include a sensitivity analysis varying the level of non-IID label coverage across clients. revision: yes
Circularity Check
No significant circularity in empirical attack demonstration
full rationale
The paper presents an empirical attack showing that a single participant can inflate attribution values via latent optimization on small synthetic batches while preserving utility. This is demonstrated experimentally across datasets, models, and marginal-utility evaluators rather than derived from any self-referential equations, fitted parameters renamed as predictions, or load-bearing self-citations. No derivation chain reduces to its own inputs by construction; the results rely on external experimental validation and do not invoke uniqueness theorems or ansatzes from prior author work in a circular manner.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our attribution-first attack uses latent optimization to inject small synthetic batches that preserve utility while exploiting non-IID label coverage and evaluator sensitivities.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the per-round marginal utility is defined as Δt(g) = U(wt + g) − U(wt)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
I., Cevher, V ., and Muehlebach, M
Bal, M. I., Cevher, V ., and Muehlebach, M. Adversarial training for defense against label poisoning attacks.arXiv preprint arXiv:2502.17121,
-
[2]
Chen, Q., Dong, X., Peng, Z., and Meng, G. Shapley estimated explanation (shep): A fast post-hoc attribution method for interpreting intelligent fault diagnosis.arXiv preprint arXiv:2504.03773,
-
[3]
Scaling laws for the value of individual data points in machine learning
Covert, I., Ji, W., Hashimoto, T., and Zou, J. Scaling laws for the value of individual data points in machine learning. arXiv preprint arXiv:2405.20456, 2024a. Covert, I., Kim, C., Lee, S.-I., Zou, J. Y ., and Hashimoto, T. B. Stochastic amortization: A unified approach to ac- celerate feature and data attribution.Advances in Neural Information Processin...
-
[4]
Fair and efficient contribution val- uation for vertical federated learning
Fan, Z., Fang, H., Wang, X., Zhou, Z., Pei, J., Friedlander, M., and Zhang, Y . Fair and efficient contribution val- uation for vertical federated learning. InInternational Conference on Learning Representations, volume 2024, pp. 14553–14572,
work page 2024
-
[5]
Gairola, S., B¨ohle, M., Locatello, F., and Schiele, B. How to probe: Simple yet effective techniques for improving post-hoc explanations.arXiv preprint arXiv:2503.00641,
-
[6]
Garrido Lucero, F., Heymann, B., V ono, M., Loiseau, P., and Perchet, V . Du-shapley: A shapley value proxy for ef- ficient dataset valuation.Advances in Neural Information Processing Systems, 37:1973–2000,
work page 1973
-
[7]
Hu, Y ., Wu, F., Ye, H., Forsyth, D., Zou, J., Jiang, N., Ma, J. W., and Zhao, H. A snapshot of influence: A local data attribution framework for online reinforcement learning. arXiv preprint arXiv:2505.19281,
- [8]
-
[9]
10 On the Fragility of Data Attribution When Learning Is Distributed Jiao, C., Pan, Y ., Xiao, E., Sheng, D., Jain, N., Zhao, H., Dasgupta, I., Ma, J. W., and Xiong, C. Date-lm: Bench- marking data attribution evaluation for large language models.arXiv preprint arXiv:2507.09424,
-
[10]
Kandpal, N. and Raffel, C. Position: The most expensive part of an llm should be its training data.arXiv preprint arXiv:2504.12427,
-
[11]
DataInf: Efficiently estimating data in- fluence in LoRA-tuned LLMs and diffusion models
Kwon, Y ., Wu, E., Wu, K., and Zou, J. Datainf: Efficiently estimating data influence in lora-tuned llms and diffusion models.arXiv preprint arXiv:2310.00902,
-
[12]
An efficient frame- work for crediting data contributors of diffusion models
Lin, C., Lu, M., Kim, C., and Lee, S.-I. An efficient frame- work for crediting data contributors of diffusion models. arXiv preprint arXiv:2407.03153, 2024a. Lin, J., Tao, L., Dong, M., and Xu, C. Diffusion attribution score: Evaluating training data influence in diffusion models.arXiv preprint arXiv:2410.18639, 2024b. Lin, X., Xu, X., Wu, Z., Ng, S.-K.,...
-
[13]
Liu, B., Xiao, Y ., Ye, R., Ling, Z., Ma, X., and Hui, B. DBA-DFL: towards distributed backdoor attacks with network detection in decentralized federated learn- ing. In Lynce, I., Murano, N., Vallati, M., Villata, S., Chesani, F., Milano, M., Omicini, A., and Dastani, M. (eds.),ECAI 2025 - 28th European Conference on Artificial Intelligence, 25-30 October...
work page 2025
-
[14]
URL https://doi.org/10.3233/FAIA250961
doi: 10.3233/FAIA250961. URL https://doi.org/10.3233/FAIA250961. Liu, P., Xu, X., and Wang, W. Threats, attacks and defenses to federated learning: issues, taxonomy and perspectives. Cybersecurity, 5(1):4,
-
[15]
Threats to federated learning: A survey,
Lyu, L., Yu, H., and Yang, Q. Threats to federated learning: A survey.arXiv preprint arXiv:2003.02133,
-
[16]
Mlodozeniec, B., Eschenhagen, R., Bae, J., Immer, A., Krueger, D., and Turner, R. Influence functions for scal- able data attribution in diffusion models.arXiv preprint arXiv:2410.13850,
-
[17]
Murhekar, A., Yuan, Z., Ray Chaudhury, B., Li, B., and Mehta, R
URLhttps://arxiv.org/abs/2506.06337. Murhekar, A., Yuan, Z., Ray Chaudhury, B., Li, B., and Mehta, R. Incentives in federated learning: Equilibria, dynamics, and mechanisms for welfare maximization. Advances in Neural Information Processing Systems, 36: 17811–17831,
-
[18]
Di, Yiwei Lu, Ayush Sekhari, Gautam Kamath, and Seth Neel
Pawelczyk, M., Di, J. Z., Lu, Y ., Sekhari, A., Kamath, G., and Neel, S. Machine unlearning fails to remove data poisoning attacks.arXiv preprint arXiv:2406.17216,
- [19]
-
[20]
Rubinstein, I. and Hopkins, S. B. Rescaled influence func- tions: Accurate data attribution in high dimension.arXiv preprint arXiv:2506.06656,
-
[21]
Sardana, S., Gupta, S., Donode, A., Prasad, A., and Karthik, G. M. Defending machine learning and deep learning models: Detecting and preventing data poisoning attacks. 2024 Global Conference on Communications and Infor- mation Technologies (GCCIT), pp. 1–6,
work page 2024
- [22]
-
[23]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Simonyan, K. and Zisserman, A. Very deep convolu- tional networks for large-scale image recognition.arXiv preprint arXiv:1409.1556,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Sun, Q., Xia, H., and Liu, J. Data-faithful feature attribution: Mitigating unobservable confounders via instrumental variables.Advances in Neural Information Processing Systems, 37:44935–44964, 2024a. Sun, W., Liu, H., Kandpal, N., Raffel, C., and Yang, Y . Enhancing training data attribution with representational optimization.arXiv preprint arXiv:2505.18513,
-
[25]
Sun, Y ., Shen, J., and Kwon, Y . 2d-oob: Attributing data con- tribution through joint valuation framework.Advances in Neural Information Processing Systems, 37:46764– 46790, 2024b. Tastan, N., Fares, S., Aremu, T., Horvath, S., and Nan- dakumar, K. Redefining contributions: Shapley-driven federated learning.arXiv preprint arXiv:2406.00569,
-
[26]
Wang, A., Nguyen, E., Yang, R., Bae, J., McIlraith, S. A., and Grosse, R. Better training data attribution via better inverse hessian-vector products.arXiv preprint arXiv:2507.14740, 2025a. Wang, J., Lin, X., Qiao, R., Foo, C.-S., and Low, B. K. H. Helpful or harmful data? fine-tuning-free shapley attri- bution for explaining language model predictions.ar...
-
[27]
T., Mittal, P., Song, D., and Jia, R
Wang, J. T., Mittal, P., Song, D., and Jia, R. Data shapley in one training run.arXiv preprint arXiv:2406.11011, 2024b. Wang, J. T., Yang, T., Zou, J., Kwon, Y ., and Jia, R. Re- thinking data shapley for data selection tasks: Misleads and merits.arXiv preprint arXiv:2405.03875, 2024c. Wang, L., Xu, S., Wang, X., and Zhu, Q. Addressing class imbalance in ...
-
[28]
Wang, S.-Y ., Hertzmann, A., Efros, A., Zhu, J.-Y ., and Zhang, R. Data attribution for text-to-image models by unlearning synthesized images.Advances in Neural In- formation Processing Systems, 37:4235–4266, 2024d. 12 On the Fragility of Data Attribution When Learning Is Distributed Wang, S.-Y ., Hertzmann, A., Efros, A. A., Zhang, R., and Zhu, J.-Y . Fa...
-
[29]
Wang, W., Deng, J., Hu, Y ., Zhang, S., Jiang, X., Zhang, R., Zhao, H., and Ma, J. W. Taming hyperparameter sensitiv- ity in data attribution: Practical selection without costly retraining.arXiv preprint arXiv:2505.24261, 2025c. Wang, X., Hu, P., Deng, J., and Ma, J. W. Adversarial attacks on data attribution.arXiv preprint arXiv:2409.05657, 2024e. Wei, D...
-
[30]
Adversarial label flips attack on support vector machines
Xiao, H., Xiao, H., and Eckert, C. Adversarial label flips attack on support vector machines. InECAI 2012, pp. 870–875. IOS Press,
work page 2012
-
[31]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Xiao, H., Rasul, K., and V ollgraf, R. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms.arXiv preprint arXiv:1708.07747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Associa- tion for Computing Machinery. ISBN 9798400704369. doi: 10.1145/3627673.3679650. URL https://doi. org/10.1145/3627673.3679650. Xu, X., Wang, S., Foo, C.-S., Low, B. K., and Fanti, G. Data distribution valuation.Advances in Neural Information Processing Systems, 37:2407–2448,
-
[33]
Zagoruyko, S. and Komodakis, N. Wide residual networks. arXiv preprint arXiv:1605.07146,
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Zhang, L., Jiao, C., Li, B., and Xiong, C. Fairshare data pric- ing via data valuation for large language models.arXiv preprint arXiv:2502.00198, 2025a. Zhang, L., Wu, H., Zhang, L., Xu, F., Cao, J., Li, F., and Niu, B. Training data attribution: Was your model secretly trained on data created by mine? InProceedings of the 31st ACM SIGKDD Conference on Kn...
-
[35]
Federated Learning with Non-IID Data
Zhao, Y ., Li, M., Lai, L., Suda, N., Civin, D., and Chandra, V . Federated learning with non-iid data.arXiv preprint arXiv:1806.00582,
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Intriguing properties of data attribution on diffusion models.arXiv preprint arXiv:2311.00500,
Zheng, X., Pang, T., Du, C., Jiang, J., and Lin, M. Intriguing properties of data attribution on diffusion models.arXiv preprint arXiv:2311.00500,
-
[37]
Background and Related Work A.1
13 On the Fragility of Data Attribution When Learning Is Distributed A. Background and Related Work A.1. Federated Learning Federated learning (FL) enables collaborative training over decentralized data without sharing raw samples. Classi- cal FL follows the broadcast–local-train–aggregate loop, where a central server coordinates many clients under pri- v...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.