Characterizing Learning in Deep Neural Networks using Tractable Algorithmic Complexity Analysis
Pith reviewed 2026-05-20 20:19 UTC · model grok-4.3
The pith
Training reduces the algorithmic complexity of deep neural network weights in a measurable way.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
QuBD quantizes network weights to a finite alphabet and aggregates per-bit-plane CTM estimates to produce a strictly tighter upper bound on true KCS complexity than any binarization method. When applied to trained networks it shows that the estimated complexity decreases as training proceeds, scales directly with data budget, rises again during overfitting, follows the same delayed-generalization pattern seen in grokking, and correlates with held-out accuracy, while the bulk of the algorithmic information sits in the most significant bit-planes.
What carries the argument
QuBD, the Quantized Block Decomposition method: quantize weights to a finite alphabet then sum CTM estimates across bit-planes to approximate KCS complexity for non-binary objects.
If this is right
- Complexity of the weights falls steadily while the network is still improving on unseen data.
- Larger training sets produce correspondingly larger complexity reductions.
- Once overfitting starts, measured complexity begins to climb again.
- The same complexity curve reproduces the delayed jump in test accuracy known as grokking.
- Lower complexity values line up with better generalization performance.
- Nearly all the algorithmic content is carried by the highest-significance bit-planes.
Where Pith is reading between the lines
- Training runs could be monitored with QuBD to trigger early stopping before overfitting raises complexity.
- The bit-plane concentration result suggests a simple rule for choosing post-training quantization depth.
- The same estimator might be applied to other high-dimensional objects such as learned embeddings or activation maps.
- Refining the quantization grid could shrink the remaining gap to true KCS complexity without losing the scaling advantages.
Load-bearing premise
Quantizing continuous weights to a finite alphabet keeps the structural features that determine their true Kolmogorov complexity.
What would settle it
A controlled run in which a network is trained to clear generalization and QuBD complexity is observed to stay flat or rise instead of falling.
Figures







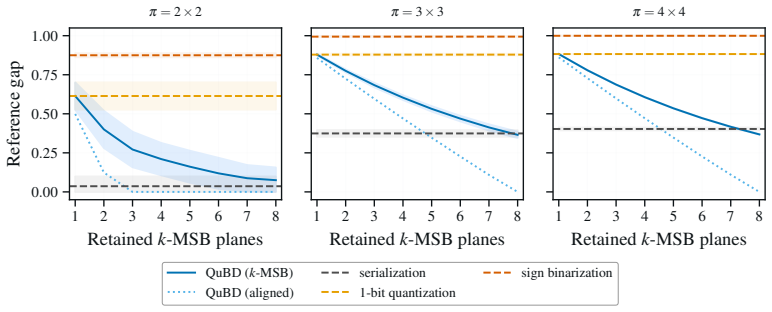



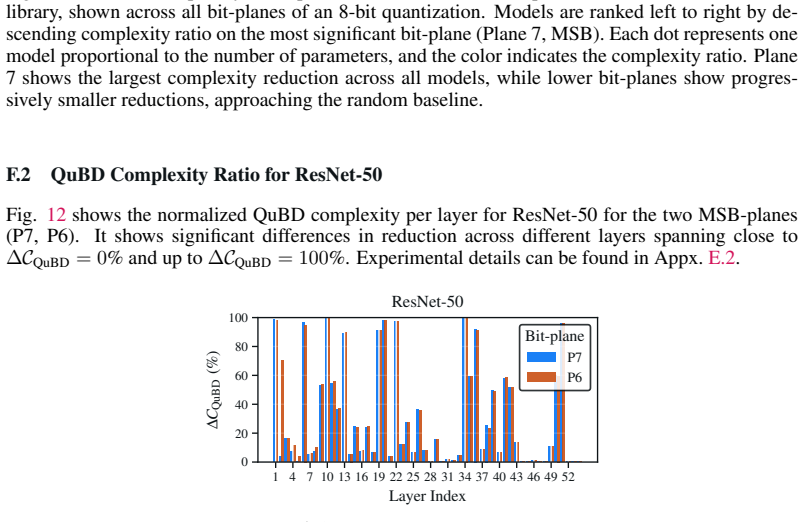
read the original abstract
Training large-scale deep neural networks (DNNs) is resource-intensive, making model compression a practical necessity. The widely accepted ''learning as compression'' hypothesis posits that training induces structure in network weights, which enables compression. Measuring this structure through Kolmogorov-Chaitin-Solomonoff (KCS) complexity is appealing, but existing estimators based on the Coding Theorem Method (CTM) and the Block Decomposition Method (BDM) are limited to small binary objects and do not scale to modern DNNs. We introduce the Quantized Block Decomposition method (QuBD), which extends algorithmic complexity estimation to any $k$-ary object. QuBD first quantizes the network weights to a finite alphabet, then estimates the KCS complexity by aggregating per bit-plane CTM estimates. We show theoretically that QuBD yields a strictly tighter estimation gap with respect to true KCS complexity than binarization-based methods. Using QuBD, we study how the algorithmic complexity of neural network weights evolves during training, showing that it decreases as models learn, scales with data budget, increases during overfitting, follows the delayed generalization observed during grokking, and correlates with generalization performance. We further show that algorithmic information resides predominantly in the most significant bit-planes, which can serve as a practical diagnostic for determining appropriate post-training quantization levels. This work offers novel insights into learning mechanisms in DNNs by providing the first scalable, tractable estimates of KCS complexity for large, non-binary objects such as DNN weights.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Quantized Block Decomposition (QuBD) method, which extends CTM/BDM-based KCS complexity estimation to non-binary objects by first quantizing DNN weights to a finite k-ary alphabet and then aggregating per-bit-plane CTM estimates. It claims a strictly tighter upper bound on the estimation gap relative to true KCS complexity than binarization baselines. Empirically, QuBD is used to show that weight complexity decreases during training, scales with data budget, rises during overfitting, tracks the delayed generalization phase in grokking, and correlates with generalization error; additionally, most algorithmic information resides in the most significant bit-planes, with implications for post-training quantization.
Significance. If the central claims hold, the work supplies the first scalable, non-binary KCS estimator applicable to modern DNNs and supplies concrete empirical support for the learning-as-compression hypothesis, including links to grokking and generalization. The theoretical gap improvement and the bit-plane dominance observation are potentially useful for both theory and practice; however, the absence of full proofs and detailed experimental protocols in the current version limits immediate impact.
major comments (2)
- [§3] §3 (theoretical gap derivation): The claim of a strictly tighter estimation gap for QuBD versus binarization is derived by aggregating CTM over k-ary bit-planes after quantization. This bound holds only under the assumption that the chosen quantization mapping (implicitly uniform or magnitude-based) does not systematically alter the shortest program length for the weight tensor. Because real-valued weights map many-to-one into bins, small perturbations inside a bin can change compressibility without changing network behavior; the manuscript does not provide a formal argument that the gap improvement survives such perturbations.
- [Empirical sections on grokking and overfitting] Empirical sections on grokking and overfitting (e.g., the experiments tracking complexity during delayed generalization): The reported increases in complexity during overfitting and the alignment with grokking lack explicit controls for the quantization alphabet size k and threshold selection. If these hyperparameters are chosen after observing the complexity curves, the claimed correlations with generalization and data budget could be artifacts of the discretization rather than reflections of true KCS changes.
minor comments (2)
- [Abstract and Introduction] The abstract and introduction would benefit from an explicit statement of the quantization rule (uniform, magnitude-based, or learned) and the precise value of k used in the main experiments.
- [Figures on bit-plane analysis] Figure captions for the bit-plane dominance plots should include the exact bit depth and the definition of 'most significant bit-planes' to allow direct replication.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below, providing the strongest honest defense of the manuscript while acknowledging where clarifications or additions are warranted. We have outlined specific revisions to strengthen the theoretical discussion and empirical robustness.
read point-by-point responses
-
Referee: [§3] §3 (theoretical gap derivation): The claim of a strictly tighter estimation gap for QuBD versus binarization is derived by aggregating CTM over k-ary bit-planes after quantization. This bound holds only under the assumption that the chosen quantization mapping (implicitly uniform or magnitude-based) does not systematically alter the shortest program length for the weight tensor. Because real-valued weights map many-to-one into bins, small perturbations inside a bin can change compressibility without changing network behavior; the manuscript does not provide a formal argument that the gap improvement survives such perturbations.
Authors: We thank the referee for this precise observation on the scope of the bound in §3. The theoretical result establishes a strictly tighter upper bound on the gap between the QuBD estimate and the true KCS complexity of the quantized tensor, relative to binarization, because the k-ary representation retains more structural information per bit-plane. We agree that the manuscript does not supply an explicit formal argument showing that this gap improvement is invariant to arbitrary intra-bin perturbations of the original real-valued weights. In the revision we will add a clarifying paragraph in §3 stating that the bound is derived for the fixed quantized object (the relevant quantity for tracking learning dynamics) and that the quantization mapping is chosen to preserve functional equivalence of the network. We will also note that CTM-based estimates exhibit stability under small local changes within the same alphabet, supporting that the observed trends are not artifacts of the discretization step. This addresses the concern directly without overstating the result. revision: partial
-
Referee: [Empirical sections on grokking and overfitting] Empirical sections on grokking and overfitting (e.g., the experiments tracking complexity during delayed generalization): The reported increases in complexity during overfitting and the alignment with grokking lack explicit controls for the quantization alphabet size k and threshold selection. If these hyperparameters are chosen after observing the complexity curves, the claimed correlations with generalization and data budget could be artifacts of the discretization rather than reflections of true KCS changes.
Authors: We concur that explicit sensitivity controls for k and quantization thresholds are necessary to rule out discretization artifacts. In the original work, k=4 was selected after preliminary runs showed that complexity estimates stabilized beyond this value while computational cost remained tractable; thresholds followed a uniform scheme derived from the empirical weight range. To directly address the referee’s concern, we have performed additional experiments sweeping k from 2 to 8 and comparing uniform versus magnitude-based thresholds. The reported trends—monotonic complexity decrease during training, rise during overfitting, and alignment with the delayed-generalization phase of grokking—remain qualitatively unchanged across these settings, and the correlation with generalization error is preserved. We will add a dedicated robustness subsection (or appendix) describing the hyperparameter selection protocol and presenting the sensitivity results. This revision eliminates any ambiguity regarding post-hoc tuning and reinforces that the empirical findings reflect genuine algorithmic-complexity dynamics. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines QuBD explicitly as quantization of real-valued weights to a k-ary alphabet followed by per-bit-plane CTM aggregation, then proves a strictly tighter gap bound relative to binarization from that construction. The central empirical claims (complexity decrease during learning, scaling with data, increase on overfitting, tracking of grokking, correlation with generalization, and MSB dominance) are direct applications of this estimator to trained networks and are compared against external binarization baselines rather than being fitted parameters or self-defined quantities. No load-bearing self-citations, imported uniqueness theorems, or ansatzes from prior author work appear in the provided text; the method is presented as an extension of independent CTM/BDM literature and remains self-contained against those benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- quantization alphabet size or bit depth
axioms (1)
- standard math CTM provides a usable approximation to Kolmogorov complexity for small discrete objects
Reference graph
Works this paper leans on
-
[1]
Jacob, Benoit and Kligys, Skirmantas and Chen, Bo and Zhu, Menglong and Tang, Matthew and Howard, Andrew and Adam, Hartwig and Kalenichenko, Dmitry , booktitle =
-
[2]
Hochreiter, Sepp and Schmidhuber, J\"
- [3]
-
[4]
Paszke, Adam and Gross, Sam and Massa, Francisco and Lerer, Adam and Bradbury, James and Chanan, Gregory and Killeen, Trevor and Lin, Zeming and Gimelshein, Natalia and Antiga, Luca and others , journal=
-
[5]
Algorithmic Simplification of Neural Networks with Mosaic-of-Motifs
Pedram Bakhtiarifard and Tong Chen and Jonathan Wenshøj and Erik B Dam and Raghavendra Selvan , year=. 2602.14896 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Seldin, Yevgeny , journal=
-
[7]
URL https://www.pnas.org/doi/abs/10.1073/pnas.1903070116
Belkin, Mikhail and Hsu, Daniel and Ma, Siyuan and Mandal, Soumik , year=. Proceedings of the National Academy of Sciences , publisher=. doi:10.1073/pnas.1903070116 , number=
-
[8]
Chaitin, Gregory , year=
-
[9]
Neyshabur, Behnam and Bhojanapalli, Srinadh and McAllester, David and Srebro, Nathan , booktitle =. 2017 , url =
work page 2017
- [10]
-
[11]
Cover, Thomas M , year=
- [12]
-
[13]
Delahaye, Jean-Paul and Zenil, Hector , journal=. 2012 , publisher=
work page 2012
- [14]
-
[15]
Kraft, Leon Gordon , year=
- [16]
- [17]
-
[18]
MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer
Sachin Mehta and Mohammad Rastegari , year=. 2110.02178 , archivePrefix=
work page internal anchor Pith review arXiv
-
[19]
Stronger generalization bounds for deep nets via a compression approach
Sanjeev Arora and Rong Ge and Behnam Neyshabur and Yi Zhang , year=. 1802.05296 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Micah Goldblum and Marc Anton Finzi and Keefer Rowan and Andrew Gordon Wilson , booktitle =. 2024 , url=
work page 2024
-
[21]
Two-Dimensional Kolmogorov Complexity and Validation of the Coding Theorem Method by Compressibility
Hector Zenil and Fernando Soler-Toscano and Jean-Paul Delahaye and Nicolas Gauvrit , year=. 1212.6745 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Li, Guoyu and Ye, Shengyu and Chen, Chunyun and Wang, Yang and Yang, Fan and Cao, Ting and Liu, Cheng and Aly, Mohamed M Sabry and Yang, Mao , booktitle =. 2025 , organization=
work page 2025
-
[23]
Gong, Yunchao and Liu, Liu and Yang, Ming and Bourdev, Lubomir , journal=
-
[24]
Ross Wightman , title =. GitHub repository , doi =. 2019 , publisher =
work page 2019
-
[25]
Chaitin, Gregory J. , title =. 1975 , issue_date =. doi:10.1145/321892.321894 , journal =
-
[26]
Shannon, C. E. , journal=. 1948 , volume=
work page 1948
-
[27]
R. Milo and S. Shen-Orr and S. Itzkovitz and N. Kashtan and D. Chklovskii and U. Alon , title =. Science , volume =. 2002 , doi =. https://www.science.org/doi/pdf/10.1126/science.298.5594.824 , abstract =
-
[28]
Benson, Austin R. and Gleich, David F. and Leskovec, Jure , year=. Science , publisher=. doi:10.1126/science.aad9029 , number=
-
[29]
Nowlan, Steven J. and Hinton, Geoffrey E. , title =. Neural Computation , volume =. 1992 , month =. doi:10.1162/neco.1992.4.4.473 , url =
-
[30]
Junru Wu and Yue Wang and Zhenyu Wu and Zhangyang Wang and Ashok Veeraraghavan and Yingyan Lin , year=. 1806.09228 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Michael Burrows and D J Wheeler D I G I T A L and Robert W. Taylor and David J. Wheeler and David Wheeler , year=
- [32]
- [33]
- [34]
- [35]
-
[36]
J. Rissanen , keywords =. Automatica , volume =. 1978 , issn =. doi:https://doi.org/10.1016/0005-1098(78)90005-5 , url =
-
[37]
A tutorial introduction to the minimum description length principle
Peter Grunwald , year=. math/0406077 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
PLOS ONE , publisher =. 2014 , month =. doi:10.1371/journal.pone.0096223 , author =
-
[39]
Xu, Aolin and Raginsky, Maxim , journal=
-
[40]
Emergence of Invariance and Disentanglement in Deep Representations
Alessandro Achille and Stefano Soatto , year=. 1706.01350 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Chaudhari, Pratik and Choromanska, Anna and Soatto, Stefano and LeCun, Yann and Baldassi, Carlo and Borgs, Christian and Chayes, Jennifer and Sagun, Levent and Zecchina, Riccardo , journal=. 2019 , publisher=
work page 2019
-
[42]
Dinh, Laurent and Pascanu, Razvan and Bengio, Samy and Bengio, Yoshua , booktitle =. 2017 , publisher =
work page 2017
-
[43]
Xiao, Han and Rasul, Kashif and Vollgraf, Roland , journal=
-
[44]
Krizhevsky, Alex and Hinton, Geoffrey and others , year=
-
[45]
Jia Deng and Wei Dong and Richard Socher and Li-Jia Li and Kai Li and Li Fei-Fei , title =
-
[46]
Yiding Jiang and Behnam Neyshabur and Hossein Mobahi and Dilip Krishnan and Samy Bengio , year=. 1912.02178 , archivePrefix=
- [47]
-
[48]
Communications of the ACM , doi =
Zhang, Chiyuan and Bengio, Samy and Hardt, Moritz and Recht, Benjamin and Vinyals, Oriol , year =. Communications of the ACM , doi =
-
[49]
Bartlett, Peter L and Mendelson, Shahar , journal=
-
[50]
Vapnik, V. N. , title =. Trans. Neur. Netw. , month = sep, pages =. 1999 , issue_date =. doi:10.1109/72.788640 , abstract =
-
[51]
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
Mingxing Tan and Quoc V. Le , year=. 1905.11946 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[52]
Smith and Oren Etzioni , year=
Roy Schwartz and Jesse Dodge and Noah A. Smith and Oren Etzioni , year=. 1907.10597 , archivePrefix=
-
[53]
Carbon Emissions and Large Neural Network Training
David Patterson and Joseph Gonzalez and Quoc Le and Chen Liang and Lluis-Miquel Munguia and Daniel Rothchild and David So and Maud Texier and Jeff Dean , year=. 2104.10350 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
Efficient Neural Architecture Search via Parameter Sharing
Hieu Pham and Melody Y. Guan and Barret Zoph and Quoc V. Le and Jeff Dean , year=. 1802.03268 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
A White Paper on Neural Network Quantization
Markus Nagel and Marios Fournarakis and Rana Ali Amjad and Yelysei Bondarenko and Mart van Baalen and Tijmen Blankevoort , year=. 2106.08295 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[56]
Shwartz-Ziv, Ravid and Tishby, Naftali , journal=
-
[57]
Song Han and Huizi Mao and William J. Dally , year=. 1510.00149 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
- [58]
-
[59]
Kingma, Diederik P and Ba, Jimmy , booktitle =
-
[60]
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford and Jong Wook Kim and Chris Hallacy and Aditya Ramesh and Gabriel Goh and Sandhini Agarwal and Girish Sastry and Amanda Askell and Pamela Mishkin and Jack Clark and Gretchen Krueger and Ilya Sutskever , year=. 2103.00020 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[61]
Grandmaster level in StarCraft II using multi-agent reinforcement learning
Vinyals, Oriol and Babuschkin, Igor and Czarnecki, Wojciech M and Mathieu, Micha \"e l and Dudzik, Andrew and Chung, Junyoung and Choi, David H and Powell, Richard and Ewalds, Timo and Georgiev, Petko and Oh, Junhyuk and Horgan, Dan and Kroiss, Manuel and Danihelka, Ivo and Huang, Aja and Sifre, Laurent and Cai, Trevor and Agapiou, John P and Jaderberg, M...
-
[62]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy and Lucas Beyer and Alexander Kolesnikov and Dirk Weissenborn and Xiaohua Zhai and Thomas Unterthiner and Mostafa Dehghani and Matthias Minderer and Georg Heigold and Sylvain Gelly and Jakob Uszkoreit and Neil Houlsby , year=. 2010.11929 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[63]
Rosenfeld and Amir Rosenfeld and Yonatan Belinkov and Nir Shavit , year=
Jonathan S. Rosenfeld and Amir Rosenfeld and Yonatan Belinkov and Nir Shavit , year=. 1909.12673 , archivePrefix=
-
[64]
Deep Learning Scaling is Predictable, Empirically
Joel Hestness and Sharan Narang and Newsha Ardalani and Gregory Diamos and Heewoo Jun and Hassan Kianinejad and Md. Mostofa Ali Patwary and Yang Yang and Yanqi Zhou , year=. 1712.00409 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[65]
Scaling Laws for Neural Language Models
Jared Kaplan and Sam McCandlish and Tom Henighan and Tom B. Brown and Benjamin Chess and Rewon Child and Scott Gray and Alec Radford and Jeffrey Wu and Dario Amodei , year=. 2001.08361 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[66]
Yifei Liu and Jicheng Wen and Yang Wang and Shengyu Ye and Li Lyna Zhang and Ting Cao and Cheng Li and Mao Yang , year=. 2409.17066 , archivePrefix=
-
[67]
Mohammad Sadegh Norouzzadeh and Shahbaz Rezaei , year=
-
[68]
arXiv preprint arXiv:2505.20646v3 , year=
Sakabe, Eduardo Y and Abrah. arXiv preprint arXiv:2505.20646v3 , year=
-
[69]
Shaw, Peter and Cohan, James and Eisenstein, Jacob and Toutanova, Kristina , journal=
-
[70]
Wilson, Andrew Gordon , journal=
- [71]
-
[72]
2025 , organization =
work page 2025
-
[73]
and Toetzke, Malte and Kontoleon, Andreas and Díaz Anadón, Laura and Minx, Jan C
Probst, Benedict S. and Toetzke, Malte and Kontoleon, Andreas and Díaz Anadón, Laura and Minx, Jan C. and Haya, Barbara K. and Schneider, Lambert and Trotter, Philipp A. and West, Thales A. P. and Gill-Wiehl, Annelise and Hoffmann, Volker H. , year =. Nature Communications , publisher =. doi:10.1038/s41467-024-53645-z , number =
-
[74]
Ilyas Moutawwakil and Régis Pierrard , title =. 2023 , publisher =
work page 2023
-
[75]
Jumper, John and Evans, Richard and Pritzel, Alexander and Green, Tim and Figurnov, Michael and Ronneberger, Olaf and Tunyasuvunakool, Kathryn and Bates, Russ and Žídek, Augustin and Potapenko, Anna and Bridgland, Alex and Meyer, Clemens and Kohl, Simon and Ballard, Andrew and Cowie, Andrew and Romera-Paredes, Bernardino and Nikolov, Stanislav and Jain, R...
-
[76]
Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin , year=. 1706.03762 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[77]
You Only Look Once: Unified, Real-Time Object Detection
Joseph Redmon and Santosh Divvala and Ross Girshick and Ali Farhadi , year=. 1506.02640 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
- [78]
-
[79]
Tom B. Brown and Benjamin Mann and Nick Ryder and Melanie Subbiah and Jared Kaplan and Prafulla Dhariwal and Arvind Neelakantan and Pranav Shyam and Girish Sastry and Amanda Askell and Sandhini Agarwal and Ariel Herbert
-
[80]
Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.