PCASim: Promptable Closed-loop Adversarial Simulation for Urban Traffic Environment
Pith reviewed 2026-05-20 19:10 UTC · model grok-4.3
The pith
A framework uses large language models to generate promptable safety-critical urban traffic scenarios and pairs them with reinforcement learning to train vehicle behaviors for closed-loop testing of autonomous driving systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
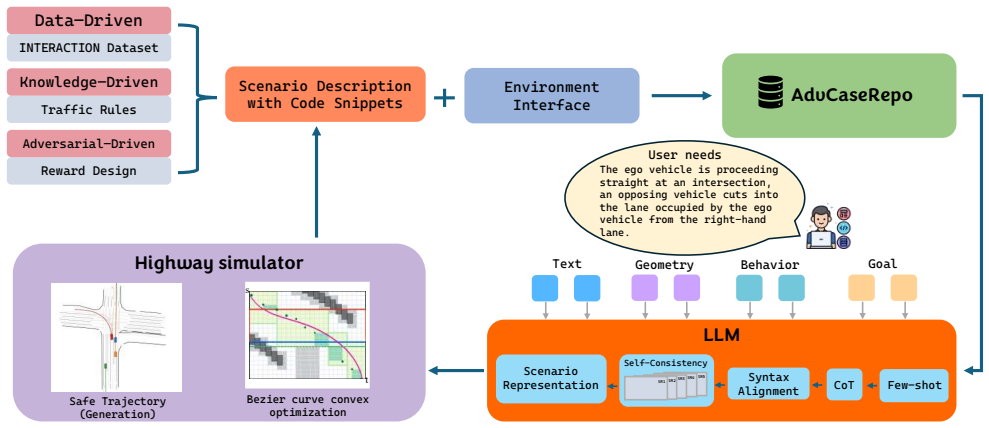
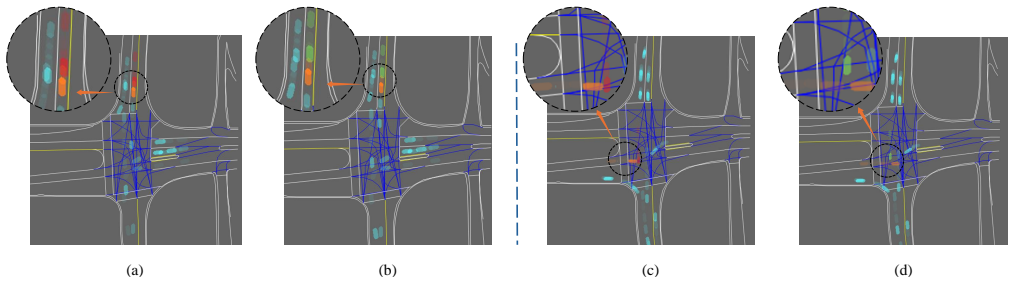
The authors propose PCASim, which constructs an adversarial behavior knowledge repository from an open-source dataset using rule-based filtering and retrieval modules. It employs a large language model to generate user-customized safety-critical traffic scenarios by merging knowledge-driven, data-driven, and adversarial-driven methods. Reinforcement learning is used to train different vehicle types' behaviors, enriching scenario diversity while preserving realism. Experiments show the framework improves domain-specific language generation accuracy by 12%, scenario transformation success rate by 8%, and obstacle-avoidance capability by 30%.
What carries the argument
The promptable closed-loop adversarial simulation that combines LLM-based scenario generation with RL-trained vehicle behaviors to enable mutual enhancement in urban traffic testing.
If this is right
- If the framework works, testing of autonomous vehicles can incorporate user-specified prompts to create targeted safety-critical scenarios.
- The closed-loop setup allows scenario generators and safety agents to improve each other over iterations.
- Urban traffic simulations can achieve higher diversity without losing contact with real data patterns.
- Obstacle avoidance in trained agents improves substantially through this enriched environment.
- Domain-specific language for describing scenarios becomes more accurate with the integrated approach.
Where Pith is reading between the lines
- This could allow simulation platforms to adapt scenarios on the fly based on new edge cases discovered during testing.
- Connecting this to real vehicle logs might further reduce the sim-to-real gap in safety evaluations.
- Extending the RL training to include multi-agent interactions could model more complex traffic flows.
Load-bearing premise
The assumption that combining LLM-generated scenarios with RL-trained behaviors produces realistic and safety-critical situations without introducing unrealistic artifacts not found in actual urban traffic.
What would settle it
A direct comparison of the generated scenarios against a large set of real-world urban traffic recordings to measure if the frequency and types of safety-critical events match real distributions, or if RL behaviors create implausible vehicle interactions.
Figures






read the original abstract
Real-world autonomous driving, particularly in urban environments with numerous corner cases, requires rigorous testing to ensure product safety and robustness. However, few studies have explored integrating adversarial scenario generation with the training of safety agents in closed-loop testing, enabling efficient co-evolution and mutual enhancement of both. To address this challenge, an adversarial behavior knowledge repository is constructed by applying rule-based filtering to an open-source dataset, combined with knowledge retrieval modules tailored for simulation environments. A large language model (LLM) is employed to integrate knowledge-, data-, and adversarial-driven approaches, generating safety-critical traffic scenarios customized to user needs. Additionally, while evaluating the generated scenarios, we employ reinforcement learning models to train the behaviors of different types of vehicles, thereby enriching scenario diversity beyond existing datasets while preserving realism. Experimental results demonstrate that the proposed framework improves the accuracy of domain-specific language generation by 12\%. Moreover, the success rate of newly generated scenario transformations increases by 8\%, while obstacle-avoidance capability is enhanced by 30\%. For the complete manuscript, please refer to: https://zhenhaooo.github.io/PCASim.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PCASim, a framework integrating rule-based filtering of open-source datasets, knowledge retrieval, LLM-driven generation of user-customized safety-critical traffic scenarios, and RL-trained vehicle behaviors for closed-loop adversarial simulation in urban environments. It claims this enables co-evolution of scenario generation and safety agent training, with experimental results showing a 12% improvement in domain-specific language generation accuracy, an 8% increase in newly generated scenario transformation success rate, and a 30% enhancement in obstacle-avoidance capability.
Significance. If the central claims hold after addressing validation gaps, the work could advance autonomous driving testing by providing a promptable, closed-loop approach that combines LLM flexibility with RL-enriched behaviors, potentially improving robustness to corner cases beyond static datasets. The emphasis on mutual enhancement between generation and training is a notable direction, though its impact depends on demonstrated fidelity to real traffic distributions.
major comments (2)
- [Abstract and Experimental Results] Abstract and Experimental Results section: The headline gains (12% DSL accuracy, 8% scenario success, 30% obstacle-avoidance) are stated as percentage improvements without any reported baselines, statistical tests, dataset sizes, number of trials, or error bars. This directly affects interpretability of whether the closed-loop RL augmentation drives genuine gains or artifacts.
- [RL Integration and Scenario Evaluation] Section on RL-augmented scenario generation (near the description of vehicle behavior training): The assertion that RL-trained behaviors 'enrich scenario diversity beyond existing datasets while preserving realism' lacks any supporting quantitative evidence, such as distributional comparisons (e.g., velocity histograms or time-to-collision statistics) against real urban datasets, expert fidelity ratings, or an ablation isolating RL's effect on scenario validity. This is load-bearing for the obstacle-avoidance claim, as non-physical behaviors could inflate the reported 30% improvement.
minor comments (2)
- [Abstract] The abstract ends with a project-page URL rather than a standard reference or DOI; this should be removed or replaced with a proper citation format for the manuscript.
- [Framework Overview] Notation for the adversarial behavior knowledge repository and knowledge retrieval modules is introduced without a clear diagram or pseudocode, making the pipeline flow harder to follow on first reading.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of experimental reporting and validation that we will address to improve clarity and rigor. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract and Experimental Results] Abstract and Experimental Results section: The headline gains (12% DSL accuracy, 8% scenario success, 30% obstacle-avoidance) are stated as percentage improvements without any reported baselines, statistical tests, dataset sizes, number of trials, or error bars. This directly affects interpretability of whether the closed-loop RL augmentation drives genuine gains or artifacts.
Authors: We agree that the abstract and experimental results would benefit from additional details to support interpretability. The reported improvements are relative to internal baselines (non-LLM and non-RL variants of the framework), but these were not explicitly described in the initial submission. In the revised manuscript, we will expand the experimental section to specify the exact baselines, dataset sizes (e.g., number of scenarios sampled from the open-source urban dataset), number of trials (minimum 50 independent runs per condition), error bars or standard deviations, and statistical tests (e.g., t-tests for significance). This will clarify the contribution of the closed-loop RL component. revision: yes
-
Referee: [RL Integration and Scenario Evaluation] Section on RL-augmented scenario generation (near the description of vehicle behavior training): The assertion that RL-trained behaviors 'enrich scenario diversity beyond existing datasets while preserving realism' lacks any supporting quantitative evidence, such as distributional comparisons (e.g., velocity histograms or time-to-collision statistics) against real urban datasets, expert fidelity ratings, or an ablation isolating RL's effect on scenario validity. This is load-bearing for the obstacle-avoidance claim, as non-physical behaviors could inflate the reported 30% improvement.
Authors: We acknowledge that the current text relies on the downstream performance metrics to imply the value of RL augmentation without direct quantitative validation of diversity and realism. This is a valid concern for the obstacle-avoidance results. We will add an ablation study and supporting analyses in the revised version, including velocity and time-to-collision distribution comparisons against the source real-world urban dataset, plus metrics quantifying scenario diversity (e.g., entropy or coverage of edge cases). This will isolate the RL contribution and better ground the 30% improvement. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes an empirical framework combining rule-based filtering, LLM-based scenario generation, and RL-trained vehicle behaviors for closed-loop adversarial simulation. All central claims consist of measured performance deltas (12% DSL accuracy, 8% transformation success, 30% obstacle avoidance) obtained from experiments. No equations, fitted parameters, self-definitional constructs, or load-bearing self-citations appear in the abstract or description; the results are presented as direct experimental outcomes rather than quantities derived from the paper's own inputs by construction. The derivation chain is therefore self-contained and does not reduce to tautology.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Rule-based filtering of open-source datasets yields a representative adversarial behavior knowledge repository suitable for simulation environments.
- domain assumption Reinforcement learning training of vehicle behaviors enriches scenario diversity while preserving realism.
Reference graph
Works this paper leans on
-
[1]
Waymo, “Waymo’s incidents: As of the end of 2024, the national highway traffic safety administration (nhtsa) had received 835 reports documenting 696 incidents involving waymo vehicles,” 2024, accessed: 2025-04-14. [Online]. Available: https://en.wikipedia.org/wiki/Waymo
work page 2024
-
[2]
Tesla, “As of 2024, there have been 51 reported fatalities involving tesla’s autopilot function, with 44 verified by nhtsa or expert testimony.” 2024, accessed: 2025-04-14. [Online]. Available: https://en.wikipedia.org/wiki/Tesla_Autopilot
work page 2024
-
[3]
Performance limit evaluation strategy for automated driving systems,
F. Gao, J. Mu, X. Han, Y . Yang, and J. Zhou, “Performance limit evaluation strategy for automated driving systems,”Automotive Innovation, vol. 5, no. 1, pp. 79–90, 2022
work page 2022
-
[4]
Risk and complexity assessment of autonomous vehicle testing scenarios,
Z. Wei, H. Zhou, and R. Zhou, “Risk and complexity assessment of autonomous vehicle testing scenarios,”Applied Sciences, vol. 14, no. 21, p. 9866, 2024
work page 2024
-
[5]
A survey on datasets for the decision making of autonomous vehicles,
Y . Wang, Z. Han, Y . Xing, S. Xu, and J. Wang, “A survey on datasets for the decision making of autonomous vehicles,”IEEE Intelligent Transportation Systems Magazine, vol. 16, no. 2, pp. 23–40, 2024
work page 2024
-
[6]
A survey on safety-critical driving scenario generation—a methodological perspec- tive,
W. Ding, C. Xu, M. Arief, H. Lin, B. Li, and D. Zhao, “A survey on safety-critical driving scenario generation—a methodological perspec- tive,”IEEE Transactions on Intelligent Transportation Systems, vol. 24, no. 7, pp. 6971–6988, 2023
work page 2023
-
[7]
Generative modeling of adversarial lane-change scenario,
C. Zhang, Z. Wang, J. Wang, K. Su, Q. Lv, B. Jiang, K. Hao, and W. Wang, “Generative modeling of adversarial lane-change scenario,” arXiv preprint arXiv:2503.12055, 2025
-
[8]
Y .-H. Yin, X. Lü, R. Jiang, B. Jia, and Z. Gao, “Kinetic analysis and numerical tests of an adaptive car-following model for real-time traffic in its,”Physica A: Statistical Mechanics and its Applications, vol. 635, p. 129494, 2024
work page 2024
-
[9]
Advsim: Generating safety-critical scenarios for self- driving vehicles,
J. Wang, A. Pun, J. Tu, S. Manivasagam, A. Sadat, S. Casas, M. Ren, and R. Urtasun, “Advsim: Generating safety-critical scenarios for self- driving vehicles,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 9909–9918
work page 2021
-
[10]
Trafficgen: Learning to generate diverse and realistic traffic scenarios,
L. Feng, Q. Li, Z. Peng, S. Tan, and B. Zhou, “Trafficgen: Learning to generate diverse and realistic traffic scenarios,” in2023 IEEE international conference on robotics and automation (ICRA). IEEE, 2023, pp. 3567–3575
work page 2023
-
[11]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azharet al., “Llama: Open and efficient foundation language models,”arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
W. Zhan, L. Sun, D. Wang, H. Shi, A. Clausse, M. Naumann, J. Kummerle, H. Konigshof, C. Stiller, A. de La Fortelleet al., “Interaction dataset: An international, adversarial and cooperative motion dataset in interactive driving scenarios with semantic maps,” arXiv preprint arXiv:1910.03088, 2019
-
[13]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Biet al., “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,”arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruanet al., “Deepseek-v3 technical report,”arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Weiet al., “Qwen2. 5 technical report,”arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Language conditioned traffic generation,
S. Tan, B. Ivanovic, X. Weng, M. Pavone, and P. Kraehenbuehl, “Language conditioned traffic generation,” in7th Annual Conference on Robot Learning, 2023
work page 2023
-
[17]
J. M. Scanlon, K. D. Kusano, T. Daniel, C. Alderson, A. Ogle, and T. Victor, “Waymo simulated driving behavior in reconstructed fatal crashes within an autonomous vehicle operating domain,”Accident Analysis & Prevention, vol. 163, p. 106454, 2021
work page 2021
-
[18]
Surfelgan: Synthesizing realistic sensor data for autonomous driving,
Z. Yang, Y . Chai, D. Anguelov, Y . Zhou, P. Sun, D. Erhan, S. Rafferty, and H. Kretzschmar, “Surfelgan: Synthesizing realistic sensor data for autonomous driving,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 11 118–11 127
work page 2020
-
[19]
Z. Wei, H. Huang, G. Zhang, R. Zhou, X. Luo, S. Li, and H. Zhou, “Interactive critical scenario generation for autonomous vehicles testing based on in-depth crash data using reinforcement learning,”IEEE Transactions on Intelligent Vehicles, 2024
work page 2024
-
[20]
Adaptive stress testing of airborne collision avoidance systems,
R. Lee, M. J. Kochenderfer, O. J. Mengshoel, G. P. Brat, and M. P. Owen, “Adaptive stress testing of airborne collision avoidance systems,” in2015 IEEE/AIAA 34th Digital Avionics Systems Conference (DASC). IEEE, 2015, pp. 6C2–1
work page 2015
-
[21]
Generating adversarial driving scenarios in high-fidelity simulators,
Y . Abeysirigoonawardena, F. Shkurti, and G. Dudek, “Generating adversarial driving scenarios in high-fidelity simulators,” in2019 International Conference on Robotics and Automation (ICRA), 2019, pp. 8271–8277
work page 2019
-
[22]
Structured domain randomization: Bridging the reality gap by context-aware synthetic data,
A. Prakash, S. Boochoon, M. Brophy, D. Acuna, E. Cameracci, G. State, O. Shapira, and S. Birchfield, “Structured domain randomization: Bridging the reality gap by context-aware synthetic data,” in2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019, pp. 7249–7255
work page 2019
-
[23]
Adversarial safety-critical scenario generation using naturalistic human driving priors,
K. Hao, W. Cui, Y . Luo, L. Xie, Y . Bai, J. Yang, S. Yan, Y . Pan, and Z. Yang, “Adversarial safety-critical scenario generation using naturalistic human driving priors,”IEEE Transactions on Intelligent Vehicles, 2023
work page 2023
-
[24]
King: Generating safety-critical driving scenarios for robust imitation via kinematics gradients,
N. Hanselmann, K. Renz, K. Chitta, A. Bhattacharyya, and A. Geiger, “King: Generating safety-critical driving scenarios for robust imitation via kinematics gradients,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 335–352
work page 2022
-
[25]
Y . Mei, T. Nie, J. Sun, and Y . Tian, “Llm-attacker: Enhancing closed- loop adversarial scenario generation for autonomous driving with large language models,”arXiv preprint arXiv:2501.15850, 2025
-
[26]
Frea: Feasibility-guided generation of safety-critical scenarios with reason- able adversariality,
K. Chen, Y . Lei, H. Cheng, H. Wu, W. Sun, and S. Zheng, “Frea: Feasibility-guided generation of safety-critical scenarios with reason- able adversariality,”arXiv preprint arXiv:2406.02983, 2024
-
[27]
Ontology based scene creation for the development of automated vehicles,
G. Bagschik, T. Menzel, and M. Maurer, “Ontology based scene creation for the development of automated vehicles,” in2018 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2018, pp. 1813–1820
work page 2018
-
[28]
Summit: A simulator for urban driving in massive mixed traffic,
P. Cai, Y . Lee, Y . Luo, and D. Hsu, “Summit: A simulator for urban driving in massive mixed traffic,” in2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020, pp. 4023–4029
work page 2020
-
[29]
Scenario factory: Creating safety-critical traffic scenarios for automated vehicles,
M. Klischat, E. I. Liu, F. Holtke, and M. Althoff, “Scenario factory: Creating safety-critical traffic scenarios for automated vehicles,” in 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC). IEEE, 2020, pp. 1–7
work page 2020
-
[30]
Target: Automated scenario generation from traffic rules for testing autonomous vehicles,
Y . Deng, J. Yao, Z. Tu, X. Zheng, M. Zhang, and T. Zhang, “Target: Automated scenario generation from traffic rules for testing autonomous vehicles,”arXiv preprint arXiv:2305.06018, 2023
-
[31]
Available: https://arxiv.org/abs/2406.10857
H. Tian, X. Han, G. Wu, Y . Zhou, S. Li, J. Wei, D. Ye, W. Wang, and T. Zhang, “An llm-enhanced multi-objective evolutionary search for autonomous driving test scenario generation,”arXiv preprint arXiv:2406.10857, 2024
-
[32]
Optimizing autonomous driving for safety: A human-centric approach with llm-enhanced rlhf,
Y . Sun, N. Salami Pargoo, P. Jin, and J. Ortiz, “Optimizing autonomous driving for safety: A human-centric approach with llm-enhanced rlhf,” inCompanion of the 2024 on ACM International Joint Conference on Pervasive and Ubiquitous Computing, 2024, pp. 76–80
work page 2024
-
[33]
Chatscene: Knowledge-enabled safety- critical scenario generation for autonomous vehicles,
J. Zhang, C. Xu, and B. Li, “Chatscene: Knowledge-enabled safety- critical scenario generation for autonomous vehicles,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 15 459–15 469
work page 2024
-
[34]
Text2Scenario: Text-driven scenario generation for autonomous driving test
X. Cai, X. Bai, Z. Cui, D. Xie, D. Fu, H. Yu, and Y . Ren, “Text2scenario: Text-driven scenario generation for autonomous driving test,”arXiv preprint arXiv:2503.02911, 2025
-
[35]
Promptable closed-loop traffic simulation,
S. Tan, B. Ivanovic, Y . Chen, B. Li, X. Weng, Y . Cao, P. Krähenbühl, and M. Pavone, “Promptable closed-loop traffic simulation,”arXiv preprint arXiv:2409.05863, 2024
-
[36]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
N. Reimers and I. Gurevych, “Sentence-bert: Sentence embeddings using siamese bert-networks,”arXiv preprint arXiv:1908.10084, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1908
-
[37]
Billion-scale similarity search with gpus,
J. Johnson, M. Douze, and H. Jégou, “Billion-scale similarity search with gpus,”IEEE Transactions on Big Data, vol. 7, no. 3, pp. 535–547, 2019
work page 2019
-
[38]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
X. Wang, J. Wei, D. Schuurmans, Q. Le, E. Chi, S. Narang, A. Chowd- hery, and D. Zhou, “Self-consistency improves chain of thought reasoning in language models,”arXiv preprint arXiv:2203.11171, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[39]
The primacy bias in deep reinforcement learning,
E. Nikishin, M. Schwarzer, P. D’Oro, P.-L. Bacon, and A. Courville, “The primacy bias in deep reinforcement learning,” inInternational conference on machine learning. PMLR, 2022, pp. 16 828–16 847
work page 2022
-
[40]
Cat: Closed-loop adversarial training for safe end-to-end driving,
L. Zhang, Z. Peng, Q. Li, and B. Zhou, “Cat: Closed-loop adversarial training for safe end-to-end driving,” in7th Annual Conference on Robot Learning, 2023
work page 2023
-
[41]
X. Cai, Z. Cui, X. Bai, R. Ke, Z. Ma, H. Yu, and Y . Ren, “Vcat: Vulnerability-aware and curiosity-driven adversarial training for enhanc- ing autonomous vehicle robustness,”arXiv preprint arXiv:2304.02391, 2024
-
[42]
OpenAI, “Gpt-5 technical overview,” https://openai.com, 2025
work page 2025
-
[43]
Anthropic, “Claude 4 model family,” https://www.anthropic.com, 2025
work page 2025
-
[44]
CARLA: An open urban driving simulator,
A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V . Koltun, “CARLA: An open urban driving simulator,” inProceedings of the 1st Annual Conference on Robot Learning, 2017, pp. 1–16. APPENDIX A. Initialize Corpus and Generate DSL To better illustrate the overall logical flow from prompt construction to scenario representation generation, the corre- spond...
work page 2017
-
[45]
ego vehicle going straight with background vehi- cle turning left,
How to Deal with the Initial Open-source Dataset - Interaction:The initial data source utilized in this work is theINTERACTIONdataset, which provides real-world trajectories of vehicles and pedestrians at urban intersections. To effectively extract structured driving scenarios from this raw data, a comprehensive preprocessing and feature extraction pipeli...
-
[46]
Integrate knowledge-, data- and adversarial-driven information into a complete natural description:To bridge the gap between raw structured data and downstream DSL generation, we integrate information derived from data-driven, knowledge-driven and adversarial-driven sources into a unified natural language description. The integration process is designed a...
-
[47]
Construct the corpus:After generating structured natural language descriptions, we proceed to construct a structured corpus to support downstream DSL generation. This corpus encapsulates not only polished textual descrip- tions but also modular DSL representations segmented into geometry, spawn and behavior components. The construction process is organize...
-
[48]
DSL Scenario Generation According To User’s Need: To enable flexible scenario generation tailored to diverse user needs, we design a Retrieval-Augmented Generation (RAG) pipeline combined with self-consistency voting mechanisms. Given an arbitrary natural language scenario description as input, the system retrieves relevant corpus entries, formats a conte...
-
[49]
Semantic consistency must be strictly maintained—no changes to the original intent are allowed
Polish the Natural Language Scenario Description: Transform the following raw natural language driving scenario description into a clear, natural and simulation-oriented English narrative in paragraph form. Semantic consistency must be strictly maintained—no changes to the original intent are allowed
-
[50]
Structure Requirements: • geometry.snippetshould define the first-level scene, including the ego vehicle’s location and movement direction. It is not necessary to specify the full road network structure; instead, provide a template that references reading from an .osm map. Additionally, clearly specify the source dataset on which this scenario is based an...
-
[51]
Ensure that the semantic content of all three DSL modules matches the polished natural language description. Each element in the DSL must have a clear one-to-one semantic correspondence to the narrative description
-
[52]
Each section must begin with import or reference statements based on the existing base classes of our project highway-env. Avoid introducing excessive custom classes to ensure structural consistency and maintainability. For example: from NGSIM_env import utils from NGSIM_env.envs.common.abstract import AbstractEnv from NGSIM_env.road.road import Road, Roa...
-
[53]
Get Repository:To bridge the gap between DSL generation and executable code, we construct a comprehensive adversarial scenario repository that serves as both a semantic retrieval base and a dynamic code generation backbone. Unlike static corpora, this repository is designed as an extend- able and executable resource collection, integrating domain- specifi...
-
[54]
When creating scenario representations, please prioritize choosing from existing elements
Hierarchical Scenario Repository Guidance:The Hierarchical Scenario Repository provides a dictionary of scenario components corresponding to each subcomponent. When creating scenario representations, please prioritize choosing from existing elements. If no appropriate element is found, you may create a new one. 2)Few-Shot Examples: •LLM Input 1: {{Input e...
-
[55]
Main Conversion Task:Based on the above description and examples, convert the following testing scenario text into the corresponding scenario representation: {{Input Scenario}} 4)Chain of Thought and Syntax Alignment: •Think step by step to reason about appropriate mappings from text descriptions to scenario components. •Syntax alignment checking: a) Ensu...
-
[56]
Retriever Context (Optional): [Scene i] {description} [Scenic Geometry] {geometry} [Scenic Spawn] {spawn} [Scenic Behavior]{behavior} Response: DSL for User’s Need: #------geometry.snippet------# { ... (generated geometry snippet) ... } #------spawn.snippet------# { ... (generated spawn snippet) ... } #------behavior.snippet------# { ... (generated behavi...
-
[57]
DSL-to-Python Code Generation:With the repository prepared, we proceed to detail the process of translating DSL representations into executable simulation codes. The overall workflow for DSL-to-Python code generation, including retrieval, prompt construction, and iterative debugging, is illustrated in Figure 8. The code generation pipeline employs a RAG m...
-
[58]
Construct prompt string with the following sections: a. DSL code block b. Hints and instructions c. RAG knowledge for code reference
-
[59]
Ensure prompt emphasizes: - Logic preservation - Full simulator object structure - Required Python imports and main execution block
-
[60]
Call the LLM with constructed prompt
-
[61]
Return the generated response 。。。。。。 Code: #------geometry.snippet------# ...... ....... #------spawn.snippet------# ...... ....... #------behavior.snippet------# ...... ....... Fig. 8. Workflow of DSL-to-Python code generation: retrieval of relevant code fragments, prompt assembly, LLM-based code generation, and iterative syntax validation. b) Syntax Val...
work page 2048
-
[62]
Scenario Context:Optionally append top- k similar code snippets retrieved from the FAISS-based repository as additional context to guide generation. 2)Instructions for Code Generation: •Preserve all logic encoded in the DSL behaviors without truncation. •Convert regions and vehicle setups into Python objects using the simulator’s modules. •Define all scen...
-
[63]
4)DSL Embedding: •Include the full DSL content within the prompt, properly formatted as a code block
Syntax Error Correction (Optional):If previous generation attempts failed due to syntax errors, prepend the extracted error message as a corrective hint to guide the next generation. 4)DSL Embedding: •Include the full DSL content within the prompt, properly formatted as a code block. Prompt Sections Structure: [Instructions for DSL Conversion] [RAG Contex...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.