Dynamic Chunking for Diffusion Language Models
Pith reviewed 2026-05-20 19:35 UTC · model grok-4.3
The pith
Dynamic chunking replaces fixed positional blocks in diffusion language models with content-defined semantic clusters, improving benchmark performance up to 1.5B parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
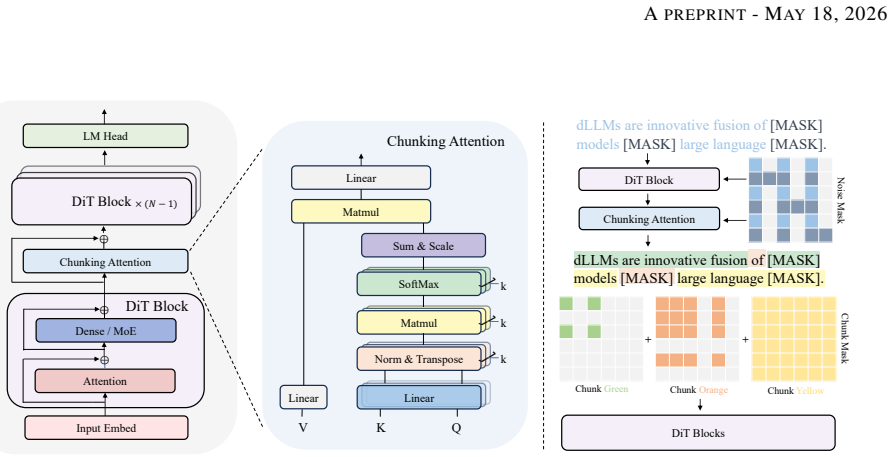
Block discrete diffusion language models factorize a sequence autoregressively over fixed-size positional blocks. DCDM replaces these with content-defined semantic chunks produced by Chunking Attention, a differentiable layer that routes tokens into K clusters parameterized by learnable subspaces. The cluster assignments induce a chunk-causal attention mask under which the discrete diffusion denoiser factorizes the sequence likelihood strictly generalizing the positional-block approach.
What carries the argument
Chunking Attention, a differentiable layer that routes tokens into K clusters via learnable subspaces shaped end-to-end by the diffusion objective to produce a content-based chunk-causal mask.
Load-bearing premise
The Chunking Attention layer, when trained end-to-end with the diffusion objective, will produce cluster assignments that induce a chunk-causal mask meaningfully better than fixed positional blocks.
What would settle it
A direct comparison in which the learned cluster assignments are replaced by random or fixed groupings while keeping all other components identical, and measuring whether the performance advantage disappears.
Figures



read the original abstract
Block discrete diffusion language models factorize a sequence autoregressively over fixed-size positional blocks, decoupling within-block parallel denoising from across-block conditioning. We argue that this rigid partition wastes structure already present in the sequence: blocks defined by position rather than by content separate semantically coherent tokens and group unrelated ones together. We introduce the \textbf{D}ynamic \textbf{C}hunking \textbf{D}iffusion \textbf{M}odel (DCDM), which replaces positional blocks with content-defined semantic chunks. At its core is Chunking Attention, a differentiable layer that routes tokens into $K$ clusters parameterized by learnable subspaces and shaped end-to-end by the diffusion objective. The resulting cluster assignments induce a chunk-causal attention mask under which a discrete diffusion denoiser factorizes the sequence likelihood autoregressively over semantic chunks, strictly generalizing block discrete diffusion. On downstream benchmarks at parameter scales up to 1.5B, DCDM consistently improves over both unstructured and positional-block diffusion baselines, with the advantage stable across scales and visible early in training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Dynamic Chunking Diffusion Model (DCDM), which replaces fixed positional blocks in discrete diffusion language models with content-defined semantic chunks. A Chunking Attention layer routes tokens into K clusters via learnable subspaces, inducing a chunk-causal attention mask that is trained end-to-end with the diffusion objective. The paper claims this strictly generalizes block discrete diffusion and yields consistent empirical gains on downstream benchmarks at scales up to 1.5B parameters over both unstructured and positional-block baselines, with the advantage appearing early in training and remaining stable across scales.
Significance. If the reported gains are robust and attributable to semantically coherent dynamic chunking rather than additional parameters or implementation artifacts, the approach could advance diffusion language models by allowing the denoising factorization to better respect natural data structure. The end-to-end optimization of chunk boundaries without hand-crafted rules is a clean generalization of prior block-based methods and could improve both efficiency and modeling quality at scale.
major comments (2)
- [§4] §4 (Experiments): The central claim of consistent improvements on downstream benchmarks lacks supporting details on training hyperparameters, baseline implementations, number of random seeds or statistical significance tests, and ablations that isolate the Chunking Attention component from the mere addition of extra parameters. This omission makes it impossible to determine whether the gains are reproducible or specifically due to content-defined chunks.
- [§3.2] §3.2 (Chunking Attention): The routing mechanism performs soft assignment to K learnable subspaces followed by a hard chunk-causal mask. The diffusion loss contains no explicit term to penalize subspace collapse or to encourage clusters to capture semantic rather than positional or frequency-based structure. Without quantitative analysis of cluster diversity, assignment entropy, or qualitative inspection of chunk boundaries, it remains possible that the learned masks are close to fixed positional blocks, undermining the explanation for the observed performance advantage.
minor comments (2)
- [§3] The notation for the subspace projection matrices and the soft-to-hard assignment function should be introduced with explicit equations rather than prose descriptions to improve reproducibility.
- [Figure 2] Figure 2 or the corresponding results table would benefit from error bars or standard deviations across runs to support the claim of stable advantages across scales.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We appreciate the referee's positive assessment of the potential impact of dynamic chunking and address each major comment below. We will revise the paper to improve reproducibility and provide supporting analyses as outlined.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): The central claim of consistent improvements on downstream benchmarks lacks supporting details on training hyperparameters, baseline implementations, number of random seeds or statistical significance tests, and ablations that isolate the Chunking Attention component from the mere addition of extra parameters. This omission makes it impossible to determine whether the gains are reproducible or specifically due to content-defined chunks.
Authors: We agree that the current manuscript would benefit from expanded experimental details to support reproducibility and isolate the contribution of Chunking Attention. In the revised version, Section 4 will be updated to include a full table of training hyperparameters (learning rate schedules, batch sizes, diffusion timesteps, and optimizer settings), precise descriptions of baseline implementations ensuring matched parameter counts and training protocols, results from multiple random seeds (at least three) with standard deviations and statistical significance tests (e.g., paired t-tests), and a dedicated ablation comparing DCDM to a parameter-matched fixed-block variant. These additions will demonstrate that performance gains are attributable to content-defined chunks rather than capacity differences or implementation choices. revision: yes
-
Referee: [§3.2] §3.2 (Chunking Attention): The routing mechanism performs soft assignment to K learnable subspaces followed by a hard chunk-causal mask. The diffusion loss contains no explicit term to penalize subspace collapse or to encourage clusters to capture semantic rather than positional or frequency-based structure. Without quantitative analysis of cluster diversity, assignment entropy, or qualitative inspection of chunk boundaries, it remains possible that the learned masks are close to fixed positional blocks, undermining the explanation for the observed performance advantage.
Authors: The referee is correct that the manuscript lacks an explicit regularization term against subspace collapse and does not yet provide quantitative or qualitative analysis of the learned clusters. While the diffusion objective implicitly favors chunk boundaries that improve denoising efficiency, this alone does not fully rule out degenerate solutions. In the revision, we will add to Section 3.2: (i) plots of assignment entropy and cluster-size variance over the course of training, (ii) quantitative comparison of learned masks against fixed positional blocks (e.g., via mask overlap metrics), and (iii) qualitative examples of chunk boundaries on held-out text demonstrating semantic coherence beyond positional or frequency patterns. These analyses will strengthen the claim that the observed gains arise from semantically meaningful dynamic chunking. revision: yes
Circularity Check
No significant circularity; derivation self-contained via end-to-end training of new components
full rationale
The paper defines Chunking Attention as a new differentiable routing layer with K learnable subspaces whose parameters are optimized directly by the discrete diffusion objective to induce content-based chunk-causal masks. This architecture generalizes positional-block diffusion without reducing any claimed prediction or uniqueness result to a prior fit, self-citation chain, or ansatz smuggled from the authors' own work. The central modeling step (soft assignment into subspaces followed by hard mask) is not equivalent by construction to its inputs; the diffusion loss provides an external training signal that can in principle discover semantic structure. No load-bearing self-citation or renaming of known results appears in the provided derivation. The model therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- K (number of clusters)
- learnable subspace parameters
axioms (1)
- domain assumption Cluster assignments produced by Chunking Attention can be used to construct a valid chunk-causal attention mask that strictly generalizes positional blocks.
invented entities (1)
-
Chunking Attention layer
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Chunking Attention... routes tokens into K clusters parameterized by learnable subspaces... induces a chunk-causal attention mask
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DCDM... strictly generalizing block discrete diffusion
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Subham Sekhar Sahoo, and V olodymyr Kuleshov
Marianne Arriola, Aaron Gokaslan, Justin T. Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Subham Sekhar Sahoo, and V olodymyr Kuleshov. Block diffusion: Interpolating between autoregressive and diffusion language models,
-
[3]
URLhttps://arxiv.org/abs/2503.09573
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
and Ho, Jonathan and Tarlow, Daniel and van den Berg, Rianne , year =
Jacob Austin, Daniel D. Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg. Structured denoising diffusion models in discrete state-spaces, 2023. URLhttps://arxiv.org/abs/2107.03006
-
[5]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng X...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Efficient Training of Language Models to Fill in the Middle
Mohammad Bavarian, Heewoo Jun, Nikolas Tezak, John Schulman, Christine McLeavey, Jerry Tworek, and Mark Chen. Efficient training of language models to fill in the middle.arXiv preprint arXiv:2207.14255, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
Piqa: Reasoning about physical commonsense in natural language
Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al. Piqa: Reasoning about physical commonsense in natural language. InProceedings of the AAAI conference on artificial intelligence, volume 34, pages 7432–7439, 2020
work page 2020
-
[8]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Nee- lakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020. 9 APREPRINT- MAY18, 2026
work page 1901
-
[9]
One Billion Word Benchmark for Measuring Progress in Statistical Language Modeling
Ciprian Chelba, Tomas Mikolov, Mike Schuster, Qi Ge, Thorsten Brants, Phillipp Koehn, and Tony Robinson. One billion word benchmark for measuring progress in statistical language modeling. Preprint arXiv:1312.3005, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[10]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv:1803.05457v1, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[11]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
A Discourse-Aware Attention Model for Abstractive Summarization of Long Documents
Arman Cohan, Franck Dernoncourt, Doo Soon Kim, Trung Bui, Seokhwan Kim, Walter Chang, and Nazli Goharian. A discourse-aware attention model for abstractive summarization of long documents. Preprint arXiv:1804.05685, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[13]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022
work page 2022
-
[15]
Aaron Gokaslan and Vanya Cohen. Openwebtext corpus. http://Skylion007.github.io/ OpenWebTextCorpus, 2019
work page 2019
-
[16]
Scaling Diffusion Language Models via Adaptation from Autoregressive Models
Shansan Gong, Shivam Agarwal, Yizhe Zhang, Jiacheng Ye, Lin Zheng, Mukai Li, Chenxin An, Peilin Zhao, Wei Bi, Jiawei Han, et al. Scaling diffusion language models via adaptation from autoregressive models.arXiv preprint arXiv:2410.17891, 2024
work page internal anchor Pith review arXiv 2024
-
[17]
Google DeepMind. Gemini diffusion, 2025. URLhttps://deepmind.google/models/gemini-diffusion/. Accessed: 2026-04-21
work page 2025
-
[18]
Dan Hendrycks, Collin Burns, Steven Basart, Andrew Critch, Jerry Li, Dawn Song, and Jacob Steinhardt. Aligning ai with shared human values.Proceedings of the International Conference on Learning Representations (ICLR), 2021
work page 2021
-
[19]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.Proceedings of the International Conference on Learning Representations (ICLR), 2021
work page 2021
-
[20]
Autoregressive diffusion models.arXiv preprint arXiv:2110.02037, 2021
Emiel Hoogeboom, Alexey A Gritsenko, Jasmijn Bastings, Ben Poole, Rianne van den Berg, and Tim Salimans. Autoregressive diffusion models.arXiv preprint arXiv:2110.02037, 2021
-
[21]
Categorical Reparameterization with Gumbel-Softmax
Eric Jang, Shixiang Gu, and Ben Poole. Categorical reparameterization with gumbel-softmax.arXiv preprint arXiv:1611.01144, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[22]
Yuxuan Jiang, Chenwei Yu, Zhi Lin, and Xiaolan Liu. A mini-batch training strategy for deep subspace clustering networks.arXiv preprint arXiv:2507.19917, 2025
-
[23]
Mercury: Ultra-Fast Language Models Based on Diffusion
Inception Labs, Samar Khanna, Siddhant Kharbanda, Shufan Li, Harshit Varma, Eric Wang, Sawyer Birnbaum, Ziyang Luo, Yanis Miraoui, Akash Palrecha, et al. Mercury: Ultra-fast language models based on diffusion.arXiv preprint arXiv:2506.17298, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step.arXiv preprint arXiv:2305.20050, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Truthfulqa: Measuring how models mimic human falsehoods
Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimic human falsehoods. In Proceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers), pages 3214–3252, 2022
work page 2022
-
[26]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Guanxi Lu, Hao Mark Chen, Yuto Karashima, Zhican Wang, Daichi Fujiki, and Hongxiang Fan. Adablock-dllm: Semantic-aware diffusion llm inference via adaptive block size.arXiv preprint arXiv:2509.26432, 2025
-
[28]
Marcus, Beatrice Santorini, and Mary Ann Marcinkiewicz
Mitchell P. Marcus, Beatrice Santorini, and Mary Ann Marcinkiewicz. Building a large annotated corpus of English: The Penn Treebank.Computational Linguistics, 19(2):313–330, 1993. URL https://aclanthology. org/J93-2004/
work page 1993
-
[29]
Attention-based clustering.arXiv preprint arXiv:2505.13112, 2025
Rodrigo Maulen-Soto, Pierre Marion, and Claire Boyer. Attention-based clustering.arXiv preprint arXiv:2505.13112, 2025. 10 APREPRINT- MAY18, 2026
-
[30]
Pointer sentinel mixture models
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models. In International Conference on Learning Representations, 2017
work page 2017
-
[31]
Large Language Diffusion Models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models.arXiv preprint arXiv:2502.09992, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
The lambada dataset: Word prediction requiring a broad discourse context
D Paperno, G Kruszewski, A Lazaridou, QN Pham, Raffaella Bernardi, S Pezzelle, M Baroni, G Boleda, and R Fernández. The lambada dataset: Word prediction requiring a broad discourse context. In54th Annual Meeting of the Association for Computational Linguistics, ACL 2016-Long Papers, volume 3, pages 1525–1534. Association for Computational Linguistics (ACL), 2016
work page 2016
-
[33]
Subspace clustering for high dimensional data: a review
Lance Parsons, Ehtesham Haque, and Huan Liu. Subspace clustering for high dimensional data: a review. SIGKDD Explor. Newsl., 6(1):90–105, June 2004. ISSN 1931-0145. doi: 10.1145/1007730.1007731. URL https://doi.org/10.1145/1007730.1007731
-
[34]
Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
work page 2019
-
[35]
Simple and effective masked diffusion language models, 2024
Subham Sekhar Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin T Chiu, Alexander Rush, and V olodymyr Kuleshov. Simple and effective masked diffusion language models, 2024. URLhttps: //arxiv.org/abs/2406.07524
-
[36]
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale.Communications of the ACM, 64(9):99–106, 2021
work page 2021
-
[37]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Out- rageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[38]
Jiaxin Shi, Kehang Han, Zhe Wang, Arnaud Doucet, and Michalis Titsias. Simplified and generalized masked diffusion for discrete data.Advances in neural information processing systems, 37:103131–103167, 2024
work page 2024
-
[39]
Andy Shih, Dorsa Sadigh, and Stefano Ermon. Training and inference on any-order autoregressive models the right way.Advances in Neural Information Processing Systems, 35:2762–2775, 2022
work page 2022
-
[40]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
work page 2017
-
[42]
Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts
Lean Wang, Huazuo Gao, Chenggang Zhao, Xu Sun, and Damai Dai. Auxiliary-loss-free load balancing strategy for mixture-of-experts.arXiv preprint arXiv:2408.15664, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding
Chengyue Wu, Hao Zhang, Shuchen Xue, Zhijian Liu, Shizhe Diao, Ligeng Zhu, Ping Luo, Song Han, and Enze Xie. Fast-dllm: Training-free acceleration of diffusion llm by enabling kv cache and parallel decoding.arXiv preprint arXiv:2505.22618, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Deep structure and attention aware subspace clustering
Wenhao Wu, Weiwei Wang, and Shengjiang Kong. Deep structure and attention aware subspace clustering. In Chinese Conference on Pattern Recognition and Computer Vision (PRCV), pages 139–150. Springer, 2023
work page 2023
-
[45]
Dream 7B: Diffusion Large Language Models
Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Dream 7b: Diffusion large language models.arXiv preprint arXiv:2508.15487, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
HellaSwag: Can a Machine Really Finish Your Sentence?
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence?arXiv preprint arXiv:1905.07830, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[47]
Xiang Zhang, Junbo Zhao, and Yann LeCun. Character-level convolutional networks for text classification. 2015. 11 APREPRINT- MAY18, 2026 A Pseudocode Algorithm 1 reproduces the chunking attention layer of Section 4.1 as a single-batch computation. The notation follows the main text: L is the sequence length, d the model dimension, K the number of clusters...
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.