A Unified Perturbation Framework for Analyzing Leaderboard Stability and Manipulation
Pith reviewed 2026-05-20 21:22 UTC · model grok-4.3
The pith
Sub-1% targeted changes to pairwise votes can flip the top model and degrade ranking consistency on leaderboards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A unified perturbation framework using influence-based approximations shows that modern Bradley-Terry leaderboards are non-robust: sub-1% targeted Drop, Add, Flip, or player-removal operations suffice to change the top-ranked model, lower Kendall's tau, and shift confidence intervals across Chatbot Arena and six other pairwise datasets, while the same influence scores enable more efficient targeted promotion or demotion than prior manipulation baselines.
What carries the argument
Influence-based approximations that estimate the effect of Drop, Add, and Flip match-level perturbations (and player removal) on Bradley-Terry parameters without full re-optimization after each change.
If this is right
- Leaderboards can be audited for stability by computing normalized robustness scores under the three perturbation types.
- The same influence scores allow an attacker to promote or demote a chosen model with fewer actions than previous baselines.
- Uncertainty reduction for a target model can be achieved with fewer flips than active-sampling methods.
- Global ranking consistency (Kendall's tau) and top-k membership both degrade under the same small perturbations.
- Dataset-level robustness scores provide a practical metric for comparing evaluation platforms.
Where Pith is reading between the lines
- Evaluation protocols that rely on single-leaderboard snapshots may need to incorporate explicit robustness checks or aggregate across multiple perturbation scenarios.
- If influence approximations remain accurate at larger scales, they could be used to design more stable ranking aggregation methods that resist small data changes.
- The framework's efficiency suggests that real-world preference data collection should track not only volume but also sensitivity of the resulting rankings to individual matches.
Load-bearing premise
The influence scores correctly predict the ranking and uncertainty changes that would be observed if the Bradley-Terry model were fully re-fit after each perturbation.
What would settle it
Re-optimize the Bradley-Terry model from scratch after applying the top-k influence-selected perturbations and check whether the observed changes in top model, Kendall's tau, and confidence intervals match the influence predictions within a small tolerance.
Figures



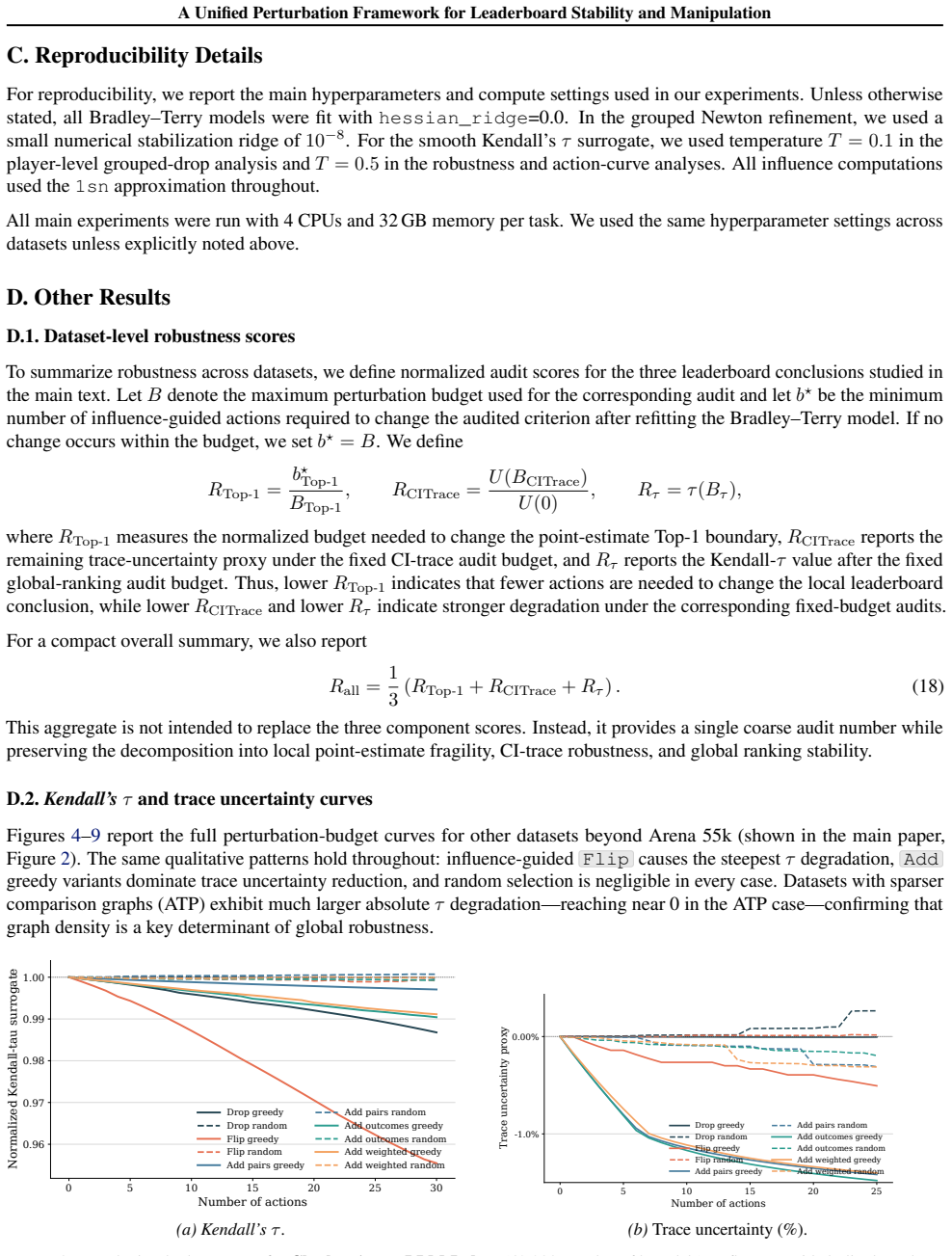








read the original abstract
Evaluation leaderboards such as LMArena play a central role in benchmarking large language models by aggregating pairwise human preferences into model rankings, yet the robustness of these rankings remains poorly understood. We present a unified perturbation framework for analyzing Bradley-Terry leaderboards under structured data modifications using influence-based approximations. Our framework studies three match-level perturbations -- Drop, Add, and Flip -- together with player removal, and evaluates their effects on top-k membership, global ranking consistency via Kendall's tau, and confidence-interval-based uncertainty. Across Chatbot Arena and six additional pairwise-comparison datasets, we show that modern leaderboards are non-robust across all three objectives: sub-1% targeted perturbations can change the top-ranked model, degrade Kendall's tau, and alter confidence intervals. Beyond robustness auditing, we show that the same influence scores enable efficient targeted perturbations, promoting or demoting specific models and reducing target-model uncertainty with fewer actions than previous manipulation and active-sampling baselines. By summarizing these effects with normalized dataset-level robustness scores, our framework provides a practical and helpful tool for auditing leaderboard stability and motivating more robust evaluation protocols.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a unified perturbation framework that applies influence-function approximations to analyze Bradley-Terry leaderboards under three match-level operations (Drop, Add, Flip) plus player removal. It evaluates effects on top-k membership, Kendall's tau, and confidence-interval uncertainty across Chatbot Arena and six additional pairwise-comparison datasets, reporting that sub-1% targeted perturbations suffice to alter the top-ranked model, degrade ranking consistency, and change uncertainty estimates. The same influence scores are further used to construct efficient targeted manipulations that outperform prior baselines in promoting or demoting models and reducing target uncertainty.
Significance. If the first-order approximations are shown to be sufficiently accurate for the reported perturbation sizes, the framework supplies a practical, scalable auditing method for leaderboard robustness and supplies concrete evidence that current pairwise-preference rankings are fragile. The multi-dataset evaluation and the unification of several perturbation types constitute a clear empirical contribution to the study of evaluation stability in machine learning.
major comments (2)
- [Abstract and §3] Abstract and §3 (influence approximation): The central claim that sub-1% perturbations change top-ranked models and degrade Kendall's tau rests on the accuracy of the influence-function linearization around the original BT MLE. No quantitative comparison of the approximated post-perturbation parameters or ranking metrics against exact re-optimization of the Bradley-Terry model is reported; without such validation it is unclear whether higher-order terms or non-convexity produce ranking flips or tau shifts that reverse the reported effects.
- [§4.2 and Table 2] §4.2 and Table 2 (Chatbot Arena results): For the dataset where the smallest perturbation sizes (sub-1%) are claimed to produce ranking changes, the manuscript should report the maximum absolute error between the influence-based predictions and exact re-computed BT parameters over a held-out set of perturbations; if this error is comparable to the observed effect size, the non-robustness conclusions do not follow.
minor comments (2)
- [§5] The definition of the normalized dataset-level robustness score should be stated explicitly with its normalization constants and range.
- [Figures 3-5] Figure captions should indicate whether shaded regions represent standard deviation across random seeds or across perturbation realizations.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We agree that validating the accuracy of the influence-function approximations against exact re-optimization is important to support the central claims. We will incorporate the requested comparisons in the revised manuscript to strengthen the empirical foundation of the framework.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (influence approximation): The central claim that sub-1% perturbations change top-ranked models and degrade Kendall's tau rests on the accuracy of the influence-function linearization around the original BT MLE. No quantitative comparison of the approximated post-perturbation parameters or ranking metrics against exact re-optimization of the Bradley-Terry model is reported; without such validation it is unclear whether higher-order terms or non-convexity produce ranking flips or tau shifts that reverse the reported effects.
Authors: We appreciate the referee highlighting this point. Influence functions are a standard first-order tool for efficient sensitivity analysis in ranking and preference models, enabling scalable auditing without repeated full MLE solves. Nevertheless, we acknowledge that explicit validation against exact re-optimization is needed to confirm that higher-order effects do not reverse the reported ranking changes for the perturbation sizes studied. In the revision we will add a dedicated validation subsection that reports parameter-level and metric-level (top-k, Kendall tau) differences between the influence approximation and exact BT re-fitting on a representative sample of perturbations drawn from each dataset. This will quantify approximation error and directly address whether the observed non-robustness effects persist under exact computation. revision: yes
-
Referee: [§4.2 and Table 2] §4.2 and Table 2 (Chatbot Arena results): For the dataset where the smallest perturbation sizes (sub-1%) are claimed to produce ranking changes, the manuscript should report the maximum absolute error between the influence-based predictions and exact re-computed BT parameters over a held-out set of perturbations; if this error is comparable to the observed effect size, the non-robustness conclusions do not follow.
Authors: We agree that reporting the maximum absolute error for Chatbot Arena is particularly important given the sub-1% perturbation regime. In the revised §4.2 we will add this analysis: we will compute the maximum absolute error between influence-predicted and exactly re-optimized BT parameters over a held-out collection of perturbations, and we will compare this error magnitude to the observed effect sizes on top-rank flips and Kendall-tau degradation. The results will be presented alongside the existing Table 2 so readers can assess whether approximation error could plausibly undermine the non-robustness conclusions. revision: yes
Circularity Check
No significant circularity; framework applies external influence approximations
full rationale
The paper's derivation chain applies established influence-function approximations from the literature to estimate post-perturbation changes in Bradley-Terry parameters, top-k membership, Kendall's tau, and confidence intervals for Drop/Add/Flip operations. These approximations are not derived from or reduced to the paper's own fitted values by construction; they serve as first-order linearizations whose accuracy is an empirical question separate from the logical structure. No self-definitional equations, fitted inputs renamed as predictions, or load-bearing self-citations appear in the central claims. The results are presented as empirical findings across multiple datasets rather than tautological outputs, making the analysis self-contained against external benchmarks for influence methods.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Influence functions provide a first-order approximation to the change in maximum-likelihood estimates under small data perturbations.
- domain assumption The Bradley-Terry model is an appropriate generative model for the observed pairwise human preferences.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
unified influence-based perturbation framework for Bradley–Terry leaderboards under three match-level perturbations—Drop, Add, and Flip
-
IndisputableMonolith/Cost/FunctionalEquation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
influence scores enable efficient targeted perturbations... normalized dataset-level robustness scores
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback , author =. 2022 , journal =. 2204.05862 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Ameli, Siavash and Zhuang, Siyuan and Stoica, Ion and Mahoney, Michael W. , booktitle =. A Statistical Framework for Ranking. 2025 , note =
work page 2025
-
[3]
Azar, Eyar and Feldman, Michael J. and Nadler, Boaz , year =. Robustness of. arXiv preprint arXiv:2512.23069 , eprint =
-
[4]
Advances in Neural Information Processing Systems , volume =
If Influence Functions are the Answer, Then What is the Question? , author =. Advances in Neural Information Processing Systems , volume =
-
[5]
Proceedings of the 37th International Conference on Machine Learning , series =
On Second-Order Group Influence Functions for Black-Box Predictions , author =. Proceedings of the 37th International Conference on Machine Learning , series =. 2020 , publisher =
work page 2020
-
[6]
Generalized Results for the Existence and Consistency of the
Bong, Heejong and Rinaldo, Alessandro , booktitle =. Generalized Results for the Existence and Consistency of the. 2022 , publisher =
work page 2022
-
[7]
Boubdir, Meriem and Kim, Edward and Ermis, Beyza and Hooker, Sara and Fadaee, Marzieh , booktitle =. 2024 , publisher =
work page 2024
-
[8]
Bradley, Ralph Allan and Terry, Milton E. , journal =. Rank Analysis of Incomplete Block Designs:. 1952 , doi =
work page 1952
-
[9]
An Automatic Finite-Sample Robustness Metric: When Can Dropping a Little Data Make a Big Difference? , author =. Econometrica , volume =. 2025 , doi =
work page 2025
-
[10]
Advances in Neural Information Processing Systems , volume =
Prediction-Powered Ranking of Large Language Models , author =. Advances in Neural Information Processing Systems , volume =. 2024 , publisher =
work page 2024
-
[11]
Chiang, Wei-Lin and Zheng, Lianmin and Sheng, Ying and Angelopoulos, Anastasios Nikolas and Li, Tianle and Li, Dacheng and Zhu, Banghua and Zhang, Hao and Jordan, Michael and Gonzalez, Joseph E. and Stoica, Ion , booktitle =. 2024 , publisher =
work page 2024
-
[12]
and Chiang, Wei-Lin , booktitle =
Chou, Christopher and Dunlap, Lisa and Mashita, Koki and Mandal, Krishna and Darrell, Trevor and Stoica, Ion and Gonzalez, Joseph E. and Chiang, Wei-Lin , booktitle =
-
[13]
Learning How Hard to Think: Input-Adaptive Allocation of
Damani, Mehul and Shenfeld, Idan and Peng, Andi and Bobu, Andreea and Andreas, Jacob , booktitle =. Learning How Hard to Think: Input-Adaptive Allocation of
-
[14]
Ranking Unraveled: Recipes for
Daynauth, Roland and Clarke, Christopher and Flautner, Krisztian and Tang, Lingjia and Mars, Jason , booktitle =. Ranking Unraveled: Recipes for. 2025 , publisher =
work page 2025
-
[15]
Fan, Jianqing and Hou, Jikai and Yu, Mengxin , journal =. Uncertainty Quantification of
-
[16]
Fang, Shuxing and Han, Ruijian and Luo, Yuanhang and Xu, Yiming , year =. Recent Advances in the. arXiv preprint arXiv:2601.14727 , eprint =
-
[17]
2025 , howpublished =
work page 2025
-
[18]
Journal of the Royal Statistical Society, Series B (Methodological) , volume =
Distance Based Ranking Models , author =. Journal of the Royal Statistical Society, Series B (Methodological) , volume =
- [19]
-
[20]
Gao, Mingqi and Liu, Yixin and Hu, Xinyu and Wan, Xiaojun and Bragg, Jonathan and Cohan, Arman , booktitle =. Re-evaluating Automatic. 2025 , publisher =
work page 2025
-
[21]
Gao, Chao and Shen, Yandi and Zhang, Anderson Y. , journal =. Uncertainty Quantification in the. 2023 , doi =
work page 2023
-
[22]
Ghorbani, Amirata and Zou, James , booktitle =. 2019 , publisher =
work page 2019
-
[23]
and Broderick, Tamara , booktitle =
Giordano, Ryan and Stephenson, William and Liu, Runjing and Jordan, Michael I. and Broderick, Tamara , booktitle =. A. 2019 , publisher =
work page 2019
-
[24]
Evaluating large language models: A comprehensive survey
Evaluating Large Language Models: A Comprehensive Survey , author =. 2023 , journal =. 2310.19736 , archivePrefix =
-
[25]
The Many Routes to the Ubiquitous
Hamilton, Ian and Tawn, Nick and Firth, David , year =. The Many Routes to the Ubiquitous. arXiv preprint arXiv:2312.13619 , eprint =
-
[26]
Training Data Influence Analysis and Estimation: A Survey , author =. Machine Learning , volume =. 2024 , doi =
work page 2024
-
[27]
The Fourteenth International Conference on Learning Representations , year =
Dropping Just a Handful of Preferences Can Change Top Large Language Model Rankings , author =. The Fourteenth International Conference on Learning Representations , year =
-
[28]
Proceedings of the 42nd International Conference on Machine Learning , series =
Exploring and Mitigating Adversarial Manipulation of Voting-Based Leaderboards , author =. Proceedings of the 42nd International Conference on Machine Learning , series =. 2025 , publisher =
work page 2025
-
[29]
The Behavior of Maximum Likelihood Estimates Under Nonstandard Conditions , author =. Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Statistics , pages =. 1967 , publisher =
work page 1967
- [30]
-
[31]
Journal of Machine Learning Research , volume =
Simple, Robust and Optimal Ranking from Pairwise Comparisons , author =. Journal of Machine Learning Research , volume =
-
[32]
A New Measure of Rank Correlation , author =. Biometrika , volume =. 1938 , doi =
work page 1938
-
[33]
Advances in Neural Information Processing Systems , volume =
On the Accuracy of Influence Functions for Measuring Group Effects , author =. Advances in Neural Information Processing Systems , volume =
-
[34]
Proceedings of the 34th International Conference on Machine Learning , volume =
Understanding Black-Box Predictions via Influence Functions , author =. Proceedings of the 34th International Conference on Machine Learning , volume =. 2017 , publisher =
work page 2017
- [35]
-
[36]
Lee, Harrison and Phatale, Samrat and Mansoor, Hassan and Mesnard, Thomas and Ferret, Johan and Lu, Kellie Ren and Bishop, Colton and Hall, Ethan and Carbune, Victor and Rastogi, Abhinav and Prakash, Sushant , booktitle =. 2024 , publisher =
work page 2024
-
[37]
Confidence and Stability of Global and Pairwise Scores in
Levtsov, Georgii and Ustalov, Dmitry , booktitle =. Confidence and Stability of Global and Pairwise Scores in. 2025 , publisher =
work page 2025
-
[38]
Transactions on Machine Learning Research , year =
Holistic Evaluation of Language Models , author =. Transactions on Machine Learning Research , year =
-
[39]
Liu, Zirui and Li, Jiatong and Zhuang, Yan and Liu, Qi and Shen, Shuanghong and Ouyang, Jie and Cheng, Mingyue and Wang, Shijin , booktitle =. am-. 2025 , publisher =
work page 2025
-
[40]
Arena Human Preference 55K Dataset , author =. 2024 , howpublished =
work page 2024
- [41]
-
[42]
Improving Your Model Ranking on
Min, Rui and Pang, Tianyu and Du, Chao and Liu, Qian and Cheng, Minhao and Lin, Min , booktitle =. Improving Your Model Ranking on. 2025 , publisher =
work page 2025
-
[43]
Operations Research , volume =
Rank Centrality: Ranking from Pairwise Comparisons , author =. Operations Research , volume =. 2017 , doi =
work page 2017
-
[44]
Advances in Neural Information Processing Systems , volume =
Training Language Models to Follow Instructions with Human Feedback , author =. Advances in Neural Information Processing Systems , volume =
-
[45]
Park, Sung Min and Georgiev, Kristian and Ilyas, Andrew and Leclerc, Guillaume and Madry, Aleksander , booktitle =. 2023 , publisher =
work page 2023
-
[46]
Causal Inference in Statistics: An Overview , author =. Statistics Surveys , volume =. 2009 , doi =
work page 2009
-
[47]
The Annals of Statistics , volume =
Logistic Regression Diagnostics , author =. The Annals of Statistics , volume =
-
[48]
Advances in Neural Information Processing Systems , volume =
Estimating Training Data Influence by Tracing Gradient Descent , author =. Advances in Neural Information Processing Systems , volume =
-
[49]
Raina, Vyas and Liusie, Adian and Gales, Mark , booktitle =. Is
-
[50]
Sackmann, Jeff , year =
-
[51]
The Leaderboard Illusion , author =. The Thirty-ninth Annual Conference on Neural Information Processing Systems, Datasets and Benchmarks Track , year =
-
[52]
Exploiting Leaderboards for Large-Scale Distribution of Malicious Models , author =
-
[53]
The Thirteenth International Conference on Learning Representations , year =
Rethinking Reward Modeling in Preference-Based Large Language Model Alignment , author =. The Thirteenth International Conference on Learning Representations , year =
-
[54]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, Hugo and Martin, Louis and Stone, Kevin and Albert, Peter and Almahairi, Amjad and Babaei, Yasmine and Bashlykov, Nikolay and Batra, Soumya and Bhargava, Prajjwal and Bhosale, Shruti and others , year =. arXiv preprint arXiv:2307.09288 , eprint =
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
and Chiang, Wei-Lin and Tang, Kelly and Manolache, Luca , year =
Vichare, Aryan and Angelopoulos, Anastasios N. and Chiang, Wei-Lin and Tang, Kelly and Manolache, Luca , year =
-
[56]
Counterfactual Explanations without Opening the Black Box: Automated Decisions and the
Wachter, Sandra and Mittelstadt, Brent and Russell, Chris , journal =. Counterfactual Explanations without Opening the Black Box: Automated Decisions and the
-
[57]
Confidence Diagram of Nonparametric Ranking for Uncertainty Assessment in Large Language Models Evaluation , author =. 2025 , journal =. 2412.05506 , archivePrefix =
-
[58]
Proceedings of the 30th International Conference on Machine Learning , volume =
Efficient Ranking from Pairwise Comparisons , author =. Proceedings of the 30th International Conference on Machine Learning , volume =. 2013 , publisher =
work page 2013
-
[59]
A Diagnostic Framework for the
Wu, Weichen and Niezink, Nynke and Junker, Brian , journal =. A Diagnostic Framework for the. 2022 , doi =
work page 2022
-
[60]
Uncertainty-Aware Preference Alignment in Reinforcement Learning from Human Feedback , author =
-
[61]
Findings of the Association for Computational Linguistics:
Challenges in Trustworthy Human Evaluation of Chatbots , author =. Findings of the Association for Computational Linguistics:. 2025 , address =
work page 2025
-
[62]
and Zhang, Hao and Gonzalez, Joseph E
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , booktitle =. Judging
-
[63]
Zheng, Xiaosen and Pang, Tianyu and Du, Chao and Liu, Qian and Jiang, Jing and Lin, Min , booktitle =. Cheating Automatic
-
[64]
The Annals of Mathematical Statistics , volume =
Adjustment of an Inverse Matrix Corresponding to a Change in One Element of a Given Matrix , author =. The Annals of Mathematical Statistics , volume =. 1950 , doi =
work page 1950
-
[65]
Prompt-to-Leaderboard: Prompt-Adaptive
Frick, Evan and Chen, Connor and Tennyson, Joseph and Li, Tianle and Chiang, Wei-Lin and Angelopoulos, Anastasios Nikolas and Stoica, Ion , booktitle =. Prompt-to-Leaderboard: Prompt-Adaptive. 2025 , publisher =
work page 2025
-
[66]
Miroyan, Mihran and Wu, Tsung-Han and King, Logan and Li, Tianle and Pan, Jiayi and Hu, Xinyan and Chiang, Wei-Lin and Angelopoulos, Anastasios Nikolas and Darrell, Trevor and Norouzi, Narges and Gonzalez, Joseph E. , booktitle =. 2026 , note =
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.