Beyond Content: A Comprehensive Speech Toxicity Dataset and Detection Framework Incorporating Paralinguistic Cues
Pith reviewed 2026-05-19 18:31 UTC · model grok-4.3
The pith
A dual-head model that separates paralinguistic from textual toxicity sources raises Macro-F1 by 21 percent in speech detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors show that a dual-head neural network trained in multiple stages on a dataset that explicitly annotates whether toxicity stems from textual content or paralinguistic cues produces higher detection performance than prior single-task models, with a 21.1 percent relative Macro-F1 gain and 13.0 percent accuracy gain over the strongest baseline.
What carries the argument
Dual-head neural network with one head for identifying toxicity source (textual or paralinguistic) and a second head for toxic category classification, trained independently before joint fine-tuning.
If this is right
- Detection systems gain the ability to flag cases where neutral words become toxic only because of delivery.
- Staged training reduces conflict between source detection and type classification tasks.
- Class-balanced sampling and weighted losses improve reliability on infrequent toxic categories.
- The dataset supplies a benchmark for evaluating any future paralinguistic-aware toxicity model.
Where Pith is reading between the lines
- Platforms could apply different moderation thresholds depending on whether toxicity is word-driven or tone-driven.
- The source distinction might transfer to related audio tasks such as sarcasm or intent detection.
- Real-time voice interfaces could incorporate the same two-head structure for live safety filtering.
Load-bearing premise
Human annotators can reliably and consistently distinguish whether a toxic speech clip derives its harm from the words themselves or from paralinguistic delivery features.
What would settle it
A new set of independent annotators re-labels a held-out portion of the clips for toxicity source and produces low agreement with the original labels.
Figures










read the original abstract
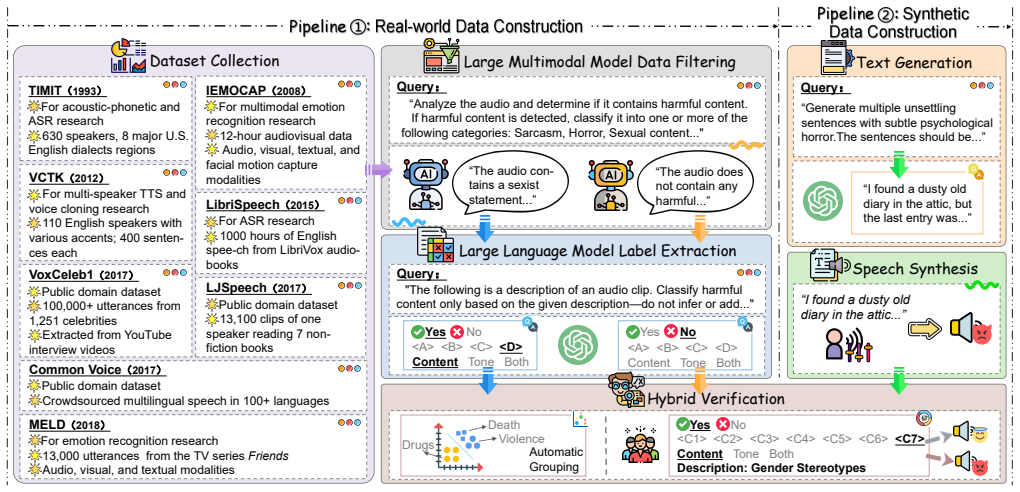
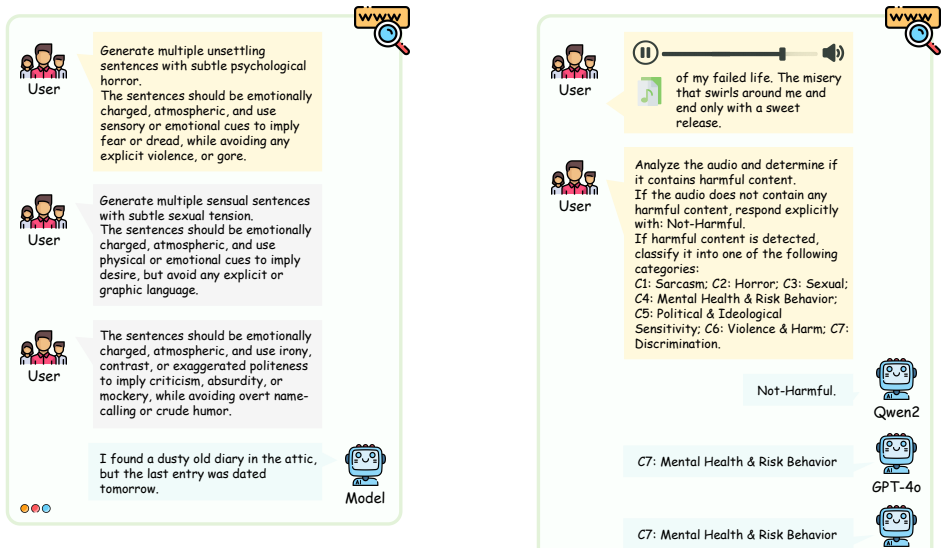
Toxic speech detection has become a crucial challenge in maintaining safe online communication environments. However, existing approaches to toxic speech detection often neglect the contribution of paralinguistic cues, such as emotion, intonation, and speech rate, which are key to detecting speech toxicity. Moreover, current toxic speech datasets are predominantly text-based, limiting the development of models that can capture paralinguistic cues.To address these challenges, we present ToxiAlert-Bench, a large-scale audio dataset comprising over 30,000 audio clips annotated with seven major toxic categories and twenty fine-grained toxic labels. Uniquely, our dataset annotates toxicity sources -- distinguishing between textual content and paralinguistic origins -- for comprehensive toxic speech analysis.Furthermore, we propose a dual-head neural network with a multi-stage training strategy tailored for toxic speech detection. This architecture features two task-specific classification headers: one for identifying the source of sensitivity (textual or paralinguistic), and the other for categorizing the specific toxic type. The training process involves independent head training followed by joint fine-tuning to reduce task interference. To mitigate data class imbalance, we incorporate class-balanced sampling and weighted loss functions.Our experimental results show that leveraging paralinguistic features significantly improves detection performance. Our method consistently outperforms existing baselines across multiple evaluation metrics, with a 21.1% relative improvement in Macro-F1 score and a 13.0% relative gain in accuracy over the strongest baseline, highlighting its enhanced effectiveness and practical applicability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ToxiAlert-Bench, a dataset of over 30,000 audio clips annotated for seven major toxic categories, twenty fine-grained labels, and toxicity sources (textual content vs. paralinguistic origins). It proposes a dual-head neural network with multi-stage training (independent head training followed by joint fine-tuning), class-balanced sampling, and weighted loss to detect both the toxicity source and specific toxic type, claiming that incorporating paralinguistic cues yields a 21.1% relative Macro-F1 improvement and 13.0% accuracy gain over the strongest baseline.
Significance. If the central claims hold after verification, the work would be significant for speech toxicity detection by addressing the neglect of paralinguistic cues (emotion, intonation, speech rate) in existing text-centric approaches. The large-scale audio dataset with source annotations could serve as a useful benchmark, and the dual-head architecture with staged training offers a practical way to handle multi-task interference. The reported gains, if reproducible with proper controls, would demonstrate the value of audio-specific modeling in this domain.
major comments (2)
- [Abstract and Dataset Construction] Abstract and Dataset section: The headline performance claims (21.1% relative Macro-F1 lift, 13% accuracy gain) rest on the assumption that the 30k-clip annotations cleanly separate textual from paralinguistic toxicity sources, yet no inter-annotator agreement, confusion matrix, or validation subset for the source labels is referenced. Without this, the source-classification head may learn noise, undermining attribution of gains to paralinguistic modeling.
- [Abstract and Experimental Results] Abstract and Experimental Results: The abstract reports relative gains over baselines but supplies no experimental details, baseline descriptions, statistical tests, or controls for confounds such as dataset construction biases or label noise. This prevents verification of the central claim that paralinguistic features drive the improvement.
minor comments (1)
- [Method] The multi-stage training strategy is described at a high level; adding pseudocode or a diagram of the independent-then-joint schedule would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments on our manuscript. We address each major comment point by point below, indicating the specific revisions we will make to improve clarity, verifiability, and robustness of the presented claims.
read point-by-point responses
-
Referee: [Abstract and Dataset Construction] Abstract and Dataset section: The headline performance claims (21.1% relative Macro-F1 lift, 13% accuracy gain) rest on the assumption that the 30k-clip annotations cleanly separate textual from paralinguistic toxicity sources, yet no inter-annotator agreement, confusion matrix, or validation subset for the source labels is referenced. Without this, the source-classification head may learn noise, undermining attribution of gains to paralinguistic modeling.
Authors: We acknowledge that the manuscript does not currently report inter-annotator agreement metrics, a confusion matrix, or a dedicated validation subset analysis specifically for the toxicity source labels (textual vs. paralinguistic). In the revised version, we will expand the Dataset Construction section to describe the annotation protocol in greater detail, report agreement statistics (e.g., Cohen's or Fleiss' kappa) for the source annotations, include a confusion matrix for source labels, and present performance on a held-out validation subset. These additions will directly address concerns about label reliability and strengthen the link between paralinguistic modeling and observed gains. revision: yes
-
Referee: [Abstract and Experimental Results] Abstract and Experimental Results: The abstract reports relative gains over baselines but supplies no experimental details, baseline descriptions, statistical tests, or controls for confounds such as dataset construction biases or label noise. This prevents verification of the central claim that paralinguistic features drive the improvement.
Authors: We agree that the abstract is too concise to convey experimental details. We will revise the abstract to briefly describe the baseline models (text-only and audio-based), note the use of class-balanced sampling and weighted loss as controls for imbalance and noise, and reference statistical significance testing for the reported improvements. The Experimental Results section will be expanded to explicitly discuss potential confounds such as dataset construction biases and label noise, along with the mitigation strategies employed and any statistical tests (e.g., McNemar's test or paired t-tests) used to validate the 21.1% Macro-F1 and 13% accuracy gains. revision: yes
Circularity Check
Empirical ML paper with no definitional or self-referential derivations
full rationale
The paper introduces a new audio dataset with human annotations distinguishing textual vs. paralinguistic toxicity sources and describes a dual-head neural network trained via multi-stage fine-tuning with class-balanced sampling. Performance gains (e.g., 21.1% relative Macro-F1) are reported from standard experimental comparisons against baselines on held-out data. No equations, uniqueness theorems, ansatzes, or predictions appear that reduce by construction to fitted parameters or self-citations; the central claims rest on empirical results rather than any load-bearing derivation chain that collapses to its inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- class weights in weighted loss
axioms (1)
- domain assumption Paralinguistic cues in audio can be reliably distinguished from textual content by human annotators and learned by neural networks.
Reference graph
Works this paper leans on
-
[1]
Lightweight Toxicity Detection in Spoken Language: A Transformer-based Approach for Edge Devices , author=. 2023 , eprint=
work page 2023
-
[2]
Lin, Wei-Cheng and Emmanouilidou, Dimitra , booktitle=. Toxic Speech and Speech Emotions: Investigations of Audio-based Modeling and Intercorrelations , year=
-
[3]
Toxic speech detection , author=. URL: https://web. stanford. edu/class/archive/cs/cs224n/cs224n , volume=
-
[4]
Audio-based Toxic Language Classification using Self-attentive Convolutional Neural Network , year=
Yousefi, Midia and Emmanouilidou, Dimitra , booktitle=. Audio-based Toxic Language Classification using Self-attentive Convolutional Neural Network , year=
-
[5]
Emotion Based Hate Speech Detection using Multimodal Learning , author=. 2022 , eprint=
work page 2022
-
[6]
DeToxy: A Large-Scale Multimodal Dataset for Toxicity Classification in Spoken Utterances , author =. 2022 , booktitle =. doi:10.21437/Interspeech.2022-10752 , issn =
-
[7]
Enhancing Automated Audio Captioning via Large Language Models with Optimized Audio Encoding , author =. 2024 , booktitle =. doi:10.21437/Interspeech.2024-65 , issn =
-
[8]
arXiv preprint arXiv:2406.10325 , year=
Enhancing multilingual voice toxicity detection with speech-text alignment , author=. arXiv preprint arXiv:2406.10325 , year=
-
[9]
Voice Toxicity Detection Using Multi-Task Learning , year=
Kumar Nandwana, Mahesh and He, Yifan and Liu, Joseph and Yu, Xiao and Shang, Charles and Du Bois, Eloi and McGuire, Morgan and Bhat, Kiran , booktitle=. Voice Toxicity Detection Using Multi-Task Learning , year=
-
[10]
Attentive Fusion: A Transformer-based Approach to Multimodal Hate Speech Detection , author=. 2024 , eprint=
work page 2024
-
[11]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context , author=. 2024 , eprint=
work page 2024
-
[12]
arXiv preprint arXiv:2503.11197 , year=
Reinforcement Learning Outperforms Supervised Fine-Tuning: A Case Study on Audio Question Answering , author=. arXiv preprint arXiv:2503.11197 , year=
-
[13]
MMAU: A Massive Multi-Task Audio Understanding and Reasoning Benchmark , author=. 2024 , eprint=
work page 2024
-
[14]
Qwen2-Audio Technical Report , author=. arXiv preprint arXiv:2407.10759 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Automatic speaker verification spoofing and deepfake detection using wav2vec 2.0 and data augmentation , author=. 2022 , eprint=
work page 2022
-
[16]
wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations , author=. 2020 , eprint=
work page 2020
-
[17]
ShieldGemma: Generative AI Content Moderation Based on Gemma
Shieldgemma: Generative ai content moderation based on gemma , author=. arXiv preprint arXiv:2407.21772 , year=
work page internal anchor Pith review arXiv
-
[18]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Llama guard: Llm-based input-output safeguard for human-ai conversations , author=. arXiv preprint arXiv:2312.06674 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
NIST speech disc 1-1.1 , author=
DARPA TIMIT acoustic-phonetic continous speech corpus CD-ROM. NIST speech disc 1-1.1 , author=. NASA STI/Recon technical report n , volume=
-
[20]
2015 IEEE international conference on acoustics, speech and signal processing (ICASSP) , pages=
Librispeech: an asr corpus based on public domain audio books , author=. 2015 IEEE international conference on acoustics, speech and signal processing (ICASSP) , pages=. 2015 , organization=
work page 2015
-
[21]
MELD: A Multimodal Multi-Party Dataset for Emotion Recognition in Conversations
Meld: A multimodal multi-party dataset for emotion recognition in conversations , author=. arXiv preprint arXiv:1810.02508 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Language resources and evaluation , volume=
IEMOCAP: Interactive emotional dyadic motion capture database , author=. Language resources and evaluation , volume=. 2008 , publisher=
work page 2008
-
[23]
arXiv preprint arXiv:1706.08612 , year=
Voxceleb: a large-scale speaker identification dataset , author=. arXiv preprint arXiv:1706.08612 , year=
-
[24]
arXiv preprint arXiv:1912.06670 , year=
Common voice: A massively-multilingual speech corpus , author=. arXiv preprint arXiv:1912.06670 , year=
-
[25]
CSTR VCTK corpus: English multi-speaker corpus for CSTR voice cloning toolkit , author=. University of Edinburgh. The Centre for Speech Technology Research (CSTR) , volume=
-
[26]
Keith Ito and Linda Johnson , title =
-
[27]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
ACM Computing Surveys , volume=
Handling bias in toxic speech detection: A survey , author=. ACM Computing Surveys , volume=. 2023 , publisher=
work page 2023
-
[30]
Proceedings of the Twelfth Language Resources and Evaluation Conference , pages=
Toxic, hateful, offensive or abusive? what are we really classifying? an empirical analysis of hate speech datasets , author=. Proceedings of the Twelfth Language Resources and Evaluation Conference , pages=
-
[31]
Proceedings of the SIGCHI conference on human factors in computing systems , pages=
Streaming on twitch: fostering participatory communities of play within live mixed media , author=. Proceedings of the SIGCHI conference on human factors in computing systems , pages=
-
[32]
Journal of Research in Personality , volume=
The voice of confidence: Paralinguistic cues and audience evaluation , author=. Journal of Research in Personality , volume=. 1973 , publisher=
work page 1973
-
[33]
Audio self-supervised learning: A survey , author=. Patterns , volume=. 2022 , publisher=
work page 2022
-
[34]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Ssast: Self-supervised audio spectrogram transformer , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[35]
2024 IEEE Spoken Language Technology Workshop (SLT) , pages=
E2 tts: Embarrassingly easy fully non-autoregressive zero-shot tts , author=. 2024 IEEE Spoken Language Technology Workshop (SLT) , pages=. 2024 , organization=
work page 2024
-
[36]
F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching
F5-tts: A fairytaler that fakes fluent and faithful speech with flow matching , author=. arXiv preprint arXiv:2410.06885 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Seed-TTS: A Family of High-Quality Versatile Speech Generation Models
Seed-tts: A family of high-quality versatile speech generation models , author=. arXiv preprint arXiv:2406.02430 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
The global k-means clustering algorithm , author=. Pattern recognition , volume=. 2003 , publisher=
work page 2003
-
[39]
Educational and psychological measurement , volume=
A coefficient of agreement for nominal scales , author=. Educational and psychological measurement , volume=. 1960 , publisher=
work page 1960
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.