Runtime-Orchestrated Second-Order Optimization for Scalable LLM Training
Pith reviewed 2026-05-19 18:25 UTC · model grok-4.3
The pith
Asteria enables practical second-order LLM training by managing optimizer state and background tasks at the runtime level.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
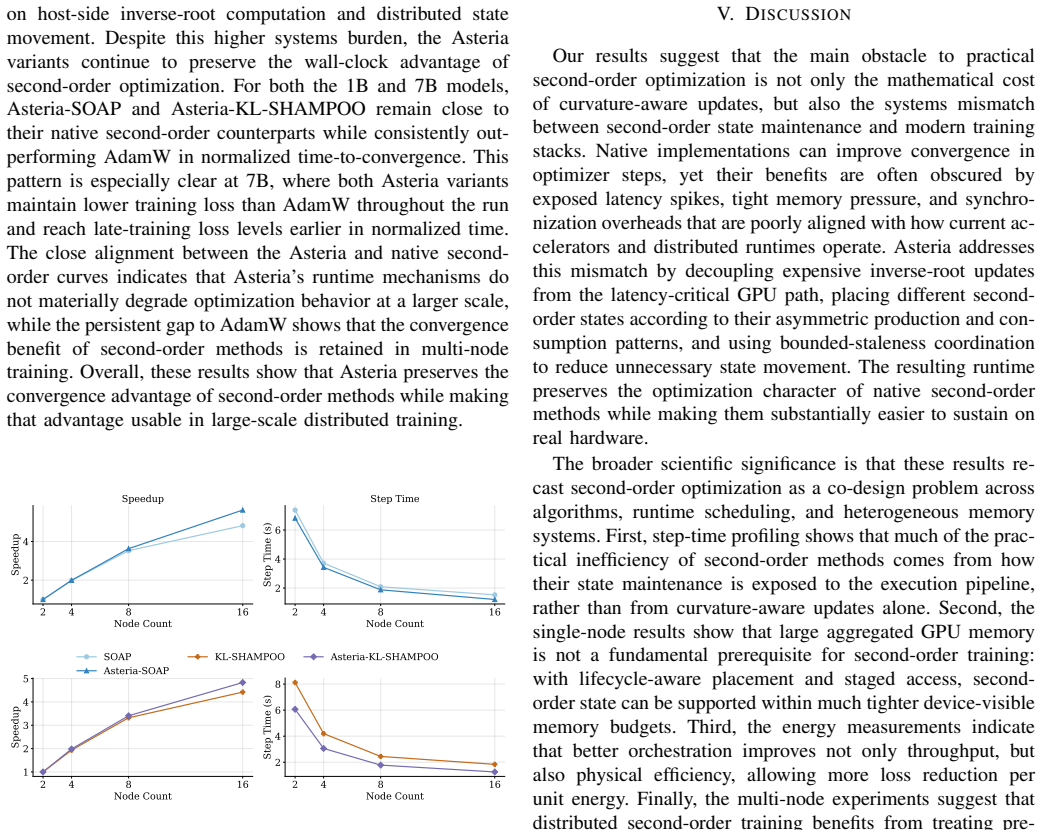
Asteria is a runtime system that separates second-order optimization logic from the GPU training path. It distributes optimizer state dynamically across GPU, CPU, and storage based on pressure, prepares shadow states asynchronously using training hooks, and applies a bounded-staleness protocol for distributed synchronization to preserve effectiveness.
What carries the argument
Asteria, the runtime system that decouples second-order preconditioner maintenance and updates from the critical GPU computation path through dynamic state distribution and asynchronous preparation.
If this is right
- On a single GPU with 128GB unified memory, second-order training works for 1B-parameter models.
- In multi-node setups, visible optimizer overhead drops and recurring latency spikes are reduced for 7B-parameter models.
- Wall-clock convergence accelerates while keeping the optimization benefits of SOAP and KL-Shampoo.
- Second-order methods become practical through runtime management of state, computation, and synchronization instead of simplifying the optimizer.
Where Pith is reading between the lines
- This runtime approach might apply to other compute-heavy optimizers that have large internal states.
- Hardware with more unified memory or faster interconnects could further benefit from similar orchestration techniques.
- Determining the right staleness bounds for different model sizes or network setups remains an open extension.
- Integrating Asteria with mixed-precision or other efficiency techniques could compound the gains in large-scale training.
Load-bearing premise
That the bounded-staleness protocol and asynchronous shadow-state preparation maintain optimizer effectiveness without causing too much latency or harming convergence.
What would settle it
A direct comparison showing that training with Asteria leads to slower convergence or higher final loss compared to first-order methods on identical hardware and data, or that latency spikes remain unchanged in distributed runs.
Figures









read the original abstract
Second-order methods offer an attractive path toward more sample-efficient LLM training, but their practical use is often blocked by the systems cost of maintaining and updating large matrix-based optimizer states. We introduce \textbf{Asteria}, a runtime system designed to remove this bottleneck by separating second-order optimization logic from the critical GPU training path. Rather than keeping all preconditioner state on the accelerator, Asteria dynamically distributes optimizer state across GPU memory, CPU memory, and optional NVMe storage according to architectural constraints and runtime pressure. It further uses training hooks to prepare shadow states in advance, allowing expensive inverse-root computations to proceed asynchronously on the host while GPU computation continues. For distributed training, Asteria employs a bounded-staleness protocol that limits synchronization frequency while preserving optimizer effectiveness through topology-aware coordination. We evaluate Asteria on both memory-constrained and distributed training settings. On a DGX Spark platform with a single GB10 GPU and 128GB unified memory, Asteria supports second-order training for a 1B-parameter language model. On multi-node GH200 systems, it lowers visible optimizer overhead, reduces recurring latency spikes, accelerates convergence in wall-clock time, and maintains the optimization advantages of SOAP and KL-Shampoo in a 7B-parameter language model. Our results suggest that second-order LLM training can be made practical not by simplifying the optimizer alone, but by rethinking how optimizer state, background computation, and distributed synchronization are managed at the runtime level.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Asteria, a runtime system for enabling practical second-order optimization (e.g., SOAP, KL-Shampoo) in LLM training. It decouples optimizer state management from the GPU critical path by dynamically distributing state across GPU/CPU/NVMe memory, prepares shadow states asynchronously via training hooks, and uses a topology-aware bounded-staleness protocol to limit synchronization frequency in distributed settings. Evaluations on a DGX Spark platform claim support for 1B-parameter models under memory constraints, while multi-node GH200 results claim reduced optimizer overhead, fewer latency spikes, faster wall-clock convergence, and retained optimization advantages for 7B models.
Significance. If the central claims hold, the work demonstrates that systems-level runtime orchestration can make second-order methods viable for large-scale training without algorithmic simplification, addressing a key barrier to sample-efficient LLM training. The focus on concrete platforms and the separation of concerns between optimization logic and synchronization are positive engineering contributions.
major comments (2)
- [§4.3] §4.3: The bounded-staleness protocol is described as limiting synchronization frequency via topology-aware coordination while preserving optimizer effectiveness, yet the 7B-model results report only aggregate wall-clock improvements and 'maintained advantages' without per-epoch loss curves, step-wise preconditioner quality metrics, or an ablation against a synchronous baseline. This leaves the claim that staleness does not degrade inverse-root computations or Hessian approximations unverified.
- [Evaluation section] Evaluation section: The abstract and results describe qualitative improvements and maintained optimizer effectiveness on concrete platforms, but provide no quantitative metrics, error bars, or detailed ablation studies. This absence directly affects assessment of whether the runtime mechanisms retain second-order convergence benefits.
minor comments (1)
- [Abstract] Abstract: The phrase 'lowers visible optimizer overhead' would benefit from a precise definition or measurement methodology to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation of Asteria's bounded-staleness protocol and the quantitative rigor of our results. We address each major comment below and outline planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4.3] §4.3: The bounded-staleness protocol is described as limiting synchronization frequency via topology-aware coordination while preserving optimizer effectiveness, yet the 7B-model results report only aggregate wall-clock improvements and 'maintained advantages' without per-epoch loss curves, step-wise preconditioner quality metrics, or an ablation against a synchronous baseline. This leaves the claim that staleness does not degrade inverse-root computations or Hessian approximations unverified.
Authors: We agree that the current 7B-model results emphasize aggregate wall-clock time and overall maintained optimizer advantages without the requested granular metrics. To directly verify that bounded staleness does not degrade inverse-root computations or Hessian approximations, the revised manuscript will include per-epoch loss curves for the 7B experiments. We will also add an ablation comparing the topology-aware bounded-staleness protocol against a synchronous baseline, reporting both convergence behavior and available preconditioner quality indicators. These additions will provide explicit evidence supporting the protocol's effectiveness. revision: yes
-
Referee: [Evaluation section] Evaluation section: The abstract and results describe qualitative improvements and maintained optimizer effectiveness on concrete platforms, but provide no quantitative metrics, error bars, or detailed ablation studies. This absence directly affects assessment of whether the runtime mechanisms retain second-order convergence benefits.
Authors: We acknowledge that the evaluation section would benefit from greater quantitative detail. In the revision we will report specific numerical improvements in optimizer overhead, latency spike reduction, and wall-clock convergence time, accompanied by error bars from repeated runs where available. We will also expand the ablation studies to isolate the impact of dynamic state distribution, asynchronous shadow-state preparation, and bounded-staleness synchronization on retention of second-order convergence benefits. These changes will enable a more precise assessment of the runtime mechanisms. revision: yes
Circularity Check
No circularity: engineering runtime design with no derivation chain
full rationale
The paper describes Asteria as a runtime system that distributes optimizer state across memory tiers, uses training hooks for asynchronous shadow-state preparation, and applies a bounded-staleness protocol for distributed synchronization. No equations, fitted parameters, uniqueness theorems, or ansatzes appear in the provided text. Claims rest on implementation descriptions and reported wall-clock improvements on specific hardware rather than any self-referential reduction of a prediction to its own inputs or load-bearing self-citations. The work is therefore self-contained as a systems contribution.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArrowOfTime.leanarrow_from_z unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Asteria employs a bounded-staleness protocol that limits synchronization frequency while preserving optimizer effectiveness through topology-aware coordination.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Hook-Orchestrated Shadow-State Pipeline... expensive inverse-root computations to proceed asynchronously on the host
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,”
-
[2]
Decoupled Weight Decay Regularization
[Online]. Available: https://doi.org/10.48550/arXiv.1711.05101
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1711.05101
-
[3]
Shampoo: Preconditioned Stochastic Tensor Optimization
V . Gupta, T. Koren, and Y . Singer, “Shampoo: Preconditioned stochastic tensor optimization,” inProceedings of the 35th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, J. Dy and A. Krause, Eds., vol. 80. PMLR, 10–15 Jul 2018, pp. 1842–1850. [Online]. Available: https://doi.org/10.48550 /arXiv.1802.09568
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
SOAP: Improving and Stabilizing Shampoo using Adam
N. Vyas, D. Morwani, R. Zhao, I. Shapira, D. Brandfonbrener, L. Janson, and S. M. Kakade, “SOAP: Improving and stabilizing shampoo using adam for language modeling,” inThe Thirteenth International Conference on Learning Representations, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2409.11321
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2409.11321 2025
-
[5]
Clarifying shampoo: Adapting spectral descent to stochasticity and the parameter trajectory,
R. Eschenhagen, A. Cai, T.-H. Lee, and H.-J. M. Shi, “Clarifying shampoo: Adapting spectral descent to stochasticity and the parameter trajectory,” 2026. [Online]. Available: https://doi.org/10.48550/arXiv.2 602.09314
-
[6]
Understanding and improving shampoo and soap via kullback-leibler minimization,
W. Lin, S. C. Lowe, F. Dangel, R. Eschenhagen, Z. Xu, and R. B. Grosse, “Understanding and improving shampoo and soap via kullback-leibler minimization,” 2026. [Online]. Available: https: //doi.org/10.48550/arXiv.2509.03378
-
[7]
arXiv preprint arXiv:2309.06497 (2023)
H.-J. M. Shi, T.-H. Lee, S. Iwasaki, J. Gallego-Posada, Z. Li, K. Rangadurai, D. Mudigere, and M. Rabbat, “A distributed data- parallel pytorch implementation of the distributed shampoo optimizer for training neural networks at-scale,” 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2309.06497
-
[8]
Asdl: A unified interface for gradient preconditioning in pytorch,
K. Osawa, S. Ishikawa, R. Yokota, S. Li, and T. Hoefler, “Asdl: A unified interface for gradient preconditioning in pytorch,” 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2305.04684
-
[9]
Pytorch fsdp: Experiences on scaling fully sharded data parallel,
Y . Zhao, A. Gu, R. Varma, L. Luo, C.-C. Huang, M. Xu, L. Wright, H. Shojanazeri, M. Ott, S. Shleifer, A. Desmaison, C. Balioglu, P. Damania, B. Nguyen, G. Chauhan, Y . Hao, A. Mathews, and S. Li, “Pytorch fsdp: Experiences on scaling fully sharded data parallel,”
-
[10]
PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel
[Online]. Available: https://doi.org/10.48550/arXiv.2304.11277
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2304.11277
-
[11]
Optimizing neural networks with kronecker-factored approximate curvature,
J. Martens and R. Grosse, “Optimizing neural networks with kronecker-factored approximate curvature,” 2020. [Online]. Available: https://doi.org/10.48550/arXiv.1503.05671
-
[12]
arXiv preprint arXiv:2002.09018 , year =
R. Anil, V . Gupta, T. Koren, K. Regan, and Y . Singer, “Scalable second order optimization for deep learning,” 2021. [Online]. Available: https://doi.org/10.48550/arXiv.2002.09018
-
[13]
arXiv preprint arXiv:2508.13898 (2025)
Y . Lu and W. Armour, “Beyond the mean: Fisher-orthogonal projection for natural gradient descent in large batch training,” 2026. [Online]. Available: https://doi.org/10.48550/arXiv.2508.13898
-
[14]
J. Ren, S. Rajbhandari, R. Y . Aminabadi, O. Ruwase, S. Yang, M. Zhang, D. Li, and Y . He, “Zero-offload: Democratizing billion-scale model training,” 2021. [Online]. Available: https://doi.org/10.48550/a rXiv.2101.06840
work page doi:10.48550/a 2021
-
[15]
Zero- infinity: Breaking the gpu memory wall for extreme scale deep learning,
S. Rajbhandari, O. Ruwase, J. Rasley, S. Smith, and Y . He, “Zero- infinity: Breaking the gpu memory wall for extreme scale deep learning,”
-
[16]
Available: https://doi.org/10.48550/arXiv.2104.07857
[Online]. Available: https://doi.org/10.48550/arXiv.2104.07857
-
[17]
Parallel training of pre-trained models via chunk-based dynamic memory management,
J. Fang, Z. Zhu, S. Li, H. Su, Y . Yu, J. Zhou, and Y . You, “Parallel training of pre-trained models via chunk-based dynamic memory management,”IEEE Transactions on Parallel and Distributed Systems, vol. 34, no. 1, p. 304–315, Jan. 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2108.05818
-
[18]
Adam: A method for stochastic optimization,
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,”
-
[19]
Adam: A Method for Stochastic Optimization
[Online]. Available: https://doi.org/10.48550/arXiv.1412.6980
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1412.6980
-
[20]
Adafactor: Adaptive Learning Rates with Sublinear Memory Cost
N. Shazeer and M. Stern, “Adafactor: Adaptive learning rates with sublinear memory cost,” 2018. [Online]. Available: https: //doi.org/10.48550/arXiv.1804.04235
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1804.04235 2018
-
[21]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
M. Shoeybi, M. Patwary, R. Puri, P. LeGresley, J. Casper, and B. Catanzaro, “Megatron-lm: Training multi-billion parameter language models using model parallelism,” 2020. [Online]. Available: https://doi.org/10.48550/arXiv.1909.08053
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1909.08053 2020
-
[22]
A unified architecture for accelerating distributed DNN training in heterogeneous GPU/CPU clusters,
Y . Jiang, Y . Zhu, C. Lan, B. Yi, Y . Cui, and C. Guo, “A unified architecture for accelerating distributed DNN training in heterogeneous GPU/CPU clusters,” in14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20). USENIX Association, Nov. 2020, pp. 463–479. [Online]. Available: https://dl.acm.org/doi/10.5555/3488766.3488792
-
[23]
Deep optimizer states: Towards scalable training of transformer models using interleaved offloading,
A. Maurya, J. Ye, M. M. Rafique, F. Cappello, and B. Nicolae, “Deep optimizer states: Towards scalable training of transformer models using interleaved offloading,” inProceedings of the 25th International Middleware Conference, ser. Middleware ’24. ACM, Dec. 2024, p. 404–416. [Online]. Available: https://doi.org/10.48550/arXiv.2410.2131 6
-
[24]
Local SGD Converges Fast and Communicates Little
S. U. Stich, “Local sgd converges fast and communicates little,” 2019. [Online]. Available: https://doi.org/10.48550/arXiv.1805.09767
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1805.09767 2019
-
[25]
GossipGraD: Scalable Deep Learning using Gossip Communication based Asynchronous Gradient Descent
J. Daily, A. Vishnu, C. Siegel, T. Warfel, and V . Amatya, “Gossipgrad: Scalable deep learning using gossip communication based asynchronous gradient descent,” 2018. [Online]. Available: https://doi.org/10.48550/arXiv.1803.05880
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1803.05880 2018
-
[26]
T. OLMo, P. Walsh, L. Soldaini, D. Groeneveld, K. Lo, S. Arora, A. Bhagia, Y . Gu, S. Huang, M. Jordan, N. Lambert, D. Schwenk, O. Tafjord, T. Anderson, D. Atkinson, F. Brahman, C. Clark, P. Dasigi, N. Dziri, A. Ettinger, M. Guerquin, D. Heineman, H. Ivison, P. W. Koh, J. Liu, S. Malik, W. Merrill, L. J. V . Miranda, J. Morrison, T. Murray, C. Nam, J. Poz...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.00656 2025
-
[27]
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y . Zhou, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,” 2023. [Online]. Available: https://doi.org/10.48550/arXiv.1910.10683
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1910.10683 2023
-
[28]
RoFormer: Enhanced Transformer with Rotary Position Embedding
J. Su, Y . Lu, S. Pan, A. Murtadha, B. Wen, and Y . Liu, “Roformer: Enhanced transformer with rotary position embedding,” 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2104.09864
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2104.09864 2023
-
[29]
A. Kapenekakis, “spark hwmon,” 2026, accessed 2026-04-08. [Online]. Available: https://github.com/antheas/spark hwmon
work page 2026
-
[30]
Z. Yang, K. Adamek, and W. Armour, “Accurate and convenient energy measurements for gpus: A detailed study of nvidia gpu’s built-in power sensor,” inSC24: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 2024, pp. 1–17. [Online]. Available: https://doi.org/10.1109/SC41406.2024.00028
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/sc41406.2024.00028 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.