When Actions Disappear: Adversarial Action Removal in Self-Play Reinforcement Learning
Pith reviewed 2026-05-20 23:37 UTC · model grok-4.3
The pith
An attacker that removes legal actions from a self-play RL agent's options inflicts more damage than random removals or perturbations, with no recovery from extended training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
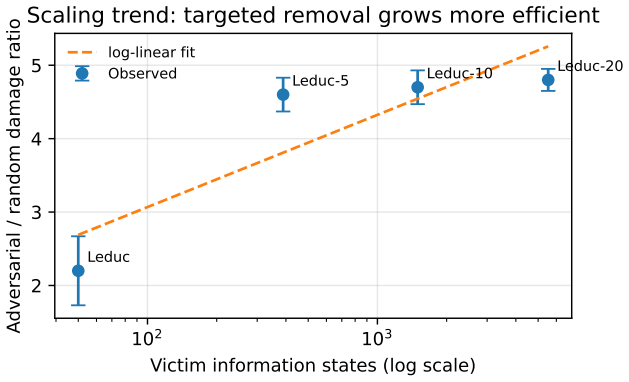
Learned adversarial action masking damages self-play RL victims substantially more than random masking and learned perturbation baselines. The attack works on Q-learning, PPO, NFSP, neural NFSP, and DQN; it transfers across agents; self-play amplifies it; and victims show no recovery even after extended masked training. The adversary targets high-value decision points, as captured by reach-weighted contingent action capacity (CAC_w) and its value-weighted refinement (CAC_v).
What carries the argument
Reach-weighted contingent action capacity (CAC_w) and value-weighted CAC_v, which measure how the adversary focuses removals on high-value decision points by weighting available actions with state reach and value.
If this is right
- The attack persists across Q-learning, PPO, NFSP, neural NFSP, and DQN victims.
- The attack transfers from one trained agent to another.
- Self-play training increases the damage caused by action removal.
- Extended training while actions remain masked produces no performance recovery.
- Action availability forms a robustness surface separate from observation or action perturbations.
Where Pith is reading between the lines
- Real-world RL systems may need safeguards at the action interface to block external restrictions on available moves.
- The same pattern could appear in other multi-agent settings where one participant can limit another's choices.
- Training policies on randomly varying action sets might build resilience to this form of interference.
- Whether the vulnerability appears in continuous-action or high-dimensional control tasks remains open for direct test.
Load-bearing premise
The attacker can remove chosen legal actions from the victim's set in real time without the victim noticing the restriction or adapting its policy to neutralize the loss.
What would settle it
Victims recovering their original performance after prolonged training under continued learned masking, or learned masking performing no better than random masking, would show the central claim does not hold.
Figures

read the original abstract
We study adversarial action masking in self-play reinforcement learning: an attacker selectively removes legal actions from a victim's action set. Unlike observation or action perturbations, removal eliminates decision options before the agent acts. Across poker games scaling from 6 to 5,531 information states and two non-poker domains, learned masking causes substantially more damage than random masking and learned perturbation baselines. The attack persists across Q-learning, PPO, NFSP, neural NFSP, and DQN victims; transfers across agents; is amplified by self-play; and shows no recovery under extended masked training. Mechanistically, the adversary targets high-value decision points, captured by reach-weighted contingent action capacity (CAC$_w$) and a value-weighted refinement CAC$_v$. These results identify action availability as a distinct robustness surface in self-play RL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies adversarial action masking in self-play reinforcement learning, where an attacker selectively removes legal actions from the victim's action set in real time. It claims that learned masking causes substantially more damage than random masking and learned perturbation baselines across poker games scaling from 6 to 5,531 information states and two non-poker domains. The attack persists across Q-learning, PPO, NFSP, neural NFSP, and DQN victims; transfers across agents; is amplified by self-play; and shows no recovery under extended masked training. Mechanistically, the adversary targets high-value decision points, captured by reach-weighted contingent action capacity (CAC_w) and a value-weighted refinement CAC_v. These results identify action availability as a distinct robustness surface in self-play RL.
Significance. If the results hold, the work identifies action availability as a new robustness surface in self-play RL distinct from observation or action perturbations. The broad empirical evaluation across multiple algorithms (Q-learning, PPO, NFSP, DQN), game scales up to 5,531 states, and domains is a clear strength and provides consistent evidence for the headline claims. Credit is given for the cross-algorithm persistence and transfer results, which go beyond single-environment demonstrations common in the field.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experimental Results): The central claim that the attack 'shows no recovery under extended masked training' is load-bearing for the conclusion that action removal is a distinct, non-mitigable robustness surface. The manuscript does not report the number of additional training steps relative to the original self-play horizon, nor whether the victim is permitted to fully re-optimize its Q-values or policy gradients over the reduced legal action set. Without these details, insufficient retraining duration remains a plausible alternative explanation for the observed lack of recovery.
- [§5] §5 (Mechanistic Analysis): CAC_w and CAC_v are introduced as mechanistic explanations for why the adversary targets high-value points. However, both quantities are defined in terms of quantities measured after the attack has been optimized (reach and value under the learned mask). This creates a circularity risk: the metrics explain the attack only because they are constructed from its outputs. An independently motivated, pre-attack capacity measure would be needed to support the mechanistic interpretation.
minor comments (2)
- [Table 1 and Figure 3] Table 1 and Figure 3: Ensure all damage metrics include standard errors or confidence intervals and the number of independent runs; current presentation makes it difficult to assess whether differences between learned masking and baselines are statistically reliable.
- [Notation] Notation: The precise mathematical definitions of CAC_w and CAC_v should appear in the main text (not only the appendix) with explicit summation indices over information states and actions.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the breadth of our empirical evaluation across algorithms, scales, and domains. We address each major comment below with clarifications and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experimental Results): The central claim that the attack 'shows no recovery under extended masked training' is load-bearing for the conclusion that action removal is a distinct, non-mitigable robustness surface. The manuscript does not report the number of additional training steps relative to the original self-play horizon, nor whether the victim is permitted to fully re-optimize its Q-values or policy gradients over the reduced legal action set. Without these details, insufficient retraining duration remains a plausible alternative explanation for the observed lack of recovery.
Authors: We agree that explicit details on retraining duration and re-optimization are necessary to support the claim. The experiments extended masked training for a duration comparable to or exceeding the original self-play horizon, during which victim agents were permitted to fully re-optimize their Q-values or policy gradients over the reduced legal action sets. No meaningful recovery occurred. We will revise §4 to report the exact relative number of additional steps and confirm the re-optimization protocol, and we will update the abstract to reference this clarification. revision: yes
-
Referee: [§5] §5 (Mechanistic Analysis): CAC_w and CAC_v are introduced as mechanistic explanations for why the adversary targets high-value points. However, both quantities are defined in terms of quantities measured after the attack has been optimized (reach and value under the learned mask). This creates a circularity risk: the metrics explain the attack only because they are constructed from its outputs. An independently motivated, pre-attack capacity measure would be needed to support the mechanistic interpretation.
Authors: We acknowledge the risk of circularity in relying on post-attack reach and value. While CAC_w and CAC_v are motivated by the information structure of decision points, we agree that an independently computed pre-attack measure would provide stronger support. We will introduce and report a pre-attack capacity metric based solely on the victim's original policy distribution and game-tree reach, demonstrating its correlation with the adversary's targeting choices. This will be added to §5 to eliminate the circularity concern. revision: yes
Circularity Check
No significant circularity; results are empirical measurements from controlled experiments
full rationale
The paper reports experimental outcomes from training RL agents (Q-learning, PPO, NFSP, DQN) under learned vs. random action masking and perturbation baselines across multiple domains. The central claims concern relative damage, transfer, amplification by self-play, and lack of recovery under extended training; these are direct measurements from policy performance under the attack, not quantities derived by algebraic reduction from the attack definition itself. CAC_w and CAC_v are introduced as post-hoc descriptive metrics that quantify reach and value at decision points targeted by the observed attack behavior. Because the metrics are computed from the same trajectories used to evaluate the attack, they function as explanatory summaries rather than load-bearing premises that force the experimental results. No self-citation chain, fitted-parameter-as-prediction, or self-definitional loop is required to obtain the headline performance deltas. The derivation chain is therefore self-contained against external benchmarks (the victim policies and environment simulators).
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Reinforcement learning proceeds in Markov decision processes where agents select from a legal action set at each information state.
invented entities (2)
-
CAC_w (reach-weighted contingent action capacity)
no independent evidence
-
CAC_v (value-weighted refinement of CAC)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Proposition 1 (DEA Convergence). Under CAC_w = 0 ... the victim's policy converges to the unique forced action at every information set
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CAC_w(M) = ∑ ρ(h)·1[|M(h)|>1]
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , year=
Adversarial policies: Attacking deep reinforcement learning , author=. International Conference on Learning Representations , year=
-
[2]
Adversarial Attacks on Neural Network Policies
Adversarial attacks on neural network policies , author=. arXiv preprint arXiv:1702.02284 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
International FLAIRS Conference , year=
A closer look at invalid action masking in policy gradient algorithms , author=. International FLAIRS Conference , year=
-
[4]
International Conference on Machine Learning , pages=
Open-ended learning in symmetric zero-sum games , author=. International Conference on Machine Learning , pages=
-
[5]
Lanctot, Marc and Lockhart, Edward and Lespiau, Jean-Baptiste and Zambaldi, Vinicius and others , journal=
-
[6]
Advances in Neural Information Processing Systems , volume=
A unified game-theoretic approach to multiagent reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
A general reinforcement learning algorithm that masters chess, shogi, and
Silver, David and Hubert, Thomas and Schrittwieser, Julian and others , journal=. A general reinforcement learning algorithm that masters chess, shogi, and
-
[8]
International Conference on Machine Learning , year=
Adaptive reward-poisoning attacks against reinforcement learning , author=. International Conference on Machine Learning , year=
-
[9]
International Conference on Autonomous Agents and Multiagent Systems , year=
Learning with opponent-learning awareness , author=. International Conference on Autonomous Agents and Multiagent Systems , year=
- [10]
- [11]
-
[12]
International Conference on Learning Representations , year=
Deep reinforcement learning from self-play in imperfect-information games , author=. International Conference on Learning Representations , year=
-
[13]
International Conference on Machine Learning , pages=
Robust adversarial reinforcement learning , author=. International Conference on Machine Learning , pages=
-
[14]
International Conference on Machine Learning , pages=
Action robust reinforcement learning and applications in continuous control , author=. International Conference on Machine Learning , pages=
-
[15]
Who is the strongest enemy? Towards optimal and efficient evasion attacks in deep
Sun, Yanchao and Zheng, Ruijie and Liang, Yongyuan and Huang, Furong , journal=. Who is the strongest enemy? Towards optimal and efficient evasion attacks in deep
-
[16]
International Conference on Machine Learning , year=
Robustness to out-of-distribution inputs via task-aware generative uncertainty , author=. International Conference on Machine Learning , year=
-
[17]
International Conference on Learning Representations , year=
Robust reinforcement learning on state observations with learned optimal adversary , author=. International Conference on Learning Representations , year=
-
[18]
Mathematics of Operations Research , volume=
Robust dynamic programming , author=. Mathematics of Operations Research , volume=
- [19]
-
[20]
Advances in Neural Information Processing Systems , volume=
Regret minimization in games with incomplete information , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
International Conference on Machine Learning , pages=
Deep counterfactual regret minimization , author=. International Conference on Machine Learning , pages=
-
[22]
Journal of Artificial Intelligence Research , volume=
Decision-theoretic planning: Structural assumptions and computational leverage , author=. Journal of Artificial Intelligence Research , volume=
-
[23]
IEEE Security and Privacy Workshops , pages=
On the robustness of cooperative multi-agent reinforcement learning , author=. IEEE Security and Privacy Workshops , pages=
-
[24]
arXiv preprint arXiv:2205.09362 , year=
Sparse adversarial attack in multi-agent reinforcement learning , author=. arXiv preprint arXiv:2205.09362 , year=
-
[25]
Niu, Men and Fan, Xinxin and Jing, Quanliang and Luo, Shaoye and Lu, Yunfeng , journal=
-
[26]
Samvelyan, Mikayel and Rashid, Tabish and de Witt, Christian Schroeder and Farquhar, Gregory and Nardelli, Nantas and Rudner, Tim G. J. and Hung, Chia-Man and Torr, Philip H. S. and Foerster, Jakob and Whiteson, Shimon , booktitle=. The
-
[27]
International Conference on Learning Representations , year=
Game-theoretic robust reinforcement learning handles temporally-coupled perturbations , author=. International Conference on Learning Representations , year=
-
[28]
arXiv preprint arXiv:2508.08800 , year=
Learning robust multi-agent policies via selective adversarial fault induction , author=. arXiv preprint arXiv:2508.08800 , year=
-
[29]
Diagnosis and fault-tolerant control , author=
-
[30]
IEEE Congress on Evolutionary Computation , pages=
Empowerment: A universal agent-centric measure of control , author=. IEEE Congress on Evolutionary Computation , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.