Closing the Gap at CRAC 2026: Two-Stage Adaptation for LLM-Based Multilingual Coreference Resolution
Pith reviewed 2026-05-22 09:50 UTC · model grok-4.3
The pith
A two-stage adapter fine-tuning strategy with headword-based mention formatting lets an LLM top the multilingual coreference resolution shared task.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Our system based on the Gemma-3-27b model, fine-tuned using a two-stage strategy with a multilingual base adapter followed by dataset-specific adapters, represents mention spans by their headword using an XML-inspired format with local reindexing and annotates documents iteratively, achieving an average CoNLL F1 score of 74.32 on the official test set and ranking first in the LLM track.
What carries the argument
Two-stage adapter fine-tuning (multilingual base adapter then dataset-specific adapters) paired with headword-only XML-inspired mention tags and iterative document annotation.
If this is right
- The two-stage adapter approach separates cross-lingual knowledge from language- or dataset-specific patterns, allowing efficient specialization after initial multilingual training.
- Representing only the headword rather than full spans simplifies the prediction target while still capturing coreference links.
- Iterative annotation of documents lets the model maintain consistency across longer coreference chains without exceeding context limits.
Where Pith is reading between the lines
- The same headword-plus-adapter pattern might reduce error rates in other span-prediction tasks such as named-entity recognition or relation extraction when applied to multilingual data.
- If the base adapter is kept fixed, the method could support rapid addition of new languages by training only a small dataset-specific adapter rather than full model updates.
- Testing the system on documents substantially longer than those in the shared-task test set would reveal whether iterative annotation scales without additional context-window techniques.
Load-bearing premise
The headword-based XML-inspired mention representation with local reindexing and iterative document annotation will transfer effectively across languages, document lengths, and annotation guidelines.
What would settle it
A large drop in average CoNLL F1 below 70 when the same system is evaluated on a new language or document collection whose annotation guidelines differ substantially from the training data would falsify the claim that the design choices generalize.
Figures
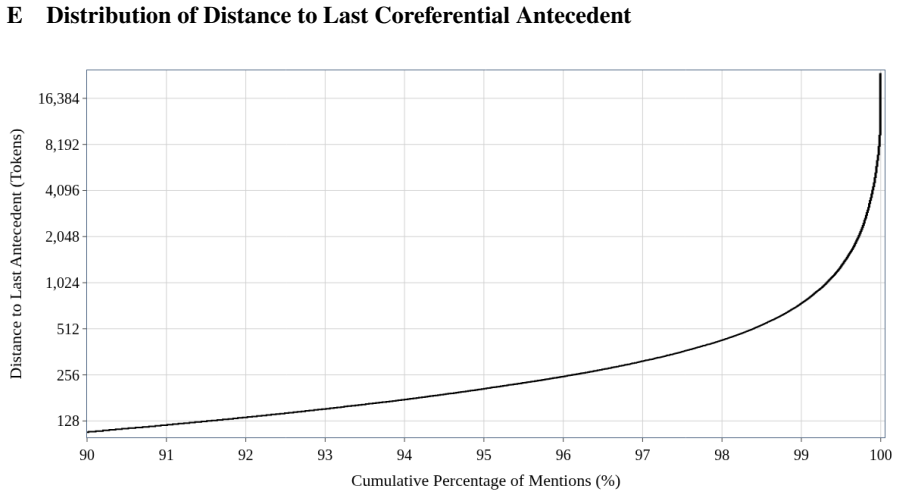
read the original abstract
We present our submission to the LLM track of the 2026 Computational Models of Reference, Anaphora and Coreference (CRAC 2026) shared task. With an average CoNLL F1 score of 74.32 on the official test set, our system ranked first in the LLM track, and third overall. Our system is based on the Gemma-3-27b model, fine-tuned using a two-stage strategy with a multilingual base adapter followed by dataset-specific adapters. We represent mention spans by their headword using an XML-inspired format with local reindexing and annotate documents iteratively. These design choices proved effective across languages, document lengths, and annotation guidelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a submission to the LLM track of the CRAC 2026 shared task on multilingual coreference resolution. The system is based on the Gemma-3-27b model and uses a two-stage adaptation strategy consisting of a multilingual base adapter followed by dataset-specific adapters. Mentions are represented by their headword in an XML-inspired format with local reindexing, and documents are annotated iteratively. The system achieves an average CoNLL F1 of 74.32 on the official test set, ranking first in the LLM track and third overall. The authors state that these design choices proved effective across languages, document lengths, and annotation guidelines.
Significance. If the result holds, the work supplies direct empirical evidence from the official shared-task test set that two-stage adapter fine-tuning on a strong multilingual LLM can reach competitive coreference performance, placing first among LLM submissions. The ranking and single reported F1 score constitute a clear, externally validated outcome. The manuscript would gain from explicitly crediting the CRAC 2026 evaluation protocol for enabling this comparison.
major comments (2)
- [Abstract] Abstract: the assertion that the headword-based XML-inspired representation with local reindexing and iterative annotation 'proved effective across languages, document lengths, and annotation guidelines' is not supported by any ablation or controlled comparison. The manuscript reports only the single end-to-end score; no runs are shown that disable local reindexing, replace iterative annotation with single-pass decoding, or substitute a conventional span representation while keeping the two-stage adapter training fixed.
- [Results] Results section: the attribution of the 74.32 F1 and first-place LLM-track ranking to the combination of two-stage adaptation plus the three representation choices cannot be evaluated because the paper supplies no baseline that uses the same Gemma-3-27b and adapter schedule but omits the XML-inspired format or iterative annotation.
minor comments (2)
- [Method] Method section: the exact tokenization of the XML-inspired format and the mechanics of local reindexing should be illustrated with a short example to support reproducibility.
- [Experiments] Add a table or paragraph listing the languages, document lengths, and annotation guidelines covered by the training data to ground the cross-lingual claim.
Simulated Author's Rebuttal
We thank the referee for the constructive review of our CRAC 2026 LLM-track submission. We agree that the manuscript's claims about the effectiveness of specific design choices require more careful qualification given the absence of ablations. Below we respond point-by-point to the major comments and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that the headword-based XML-inspired representation with local reindexing and iterative annotation 'proved effective across languages, document lengths, and annotation guidelines' is not supported by any ablation or controlled comparison. The manuscript reports only the single end-to-end score; no runs are shown that disable local reindexing, replace iterative annotation with single-pass decoding, or substitute a conventional span representation while keeping the two-stage adapter training fixed.
Authors: We acknowledge that the abstract overstates the evidential basis for these design choices. The manuscript presents only the final system score of 74.32 CoNLL F1 without ablations that isolate the contribution of headword XML representation, local reindexing, or iterative annotation while holding the two-stage adapter schedule constant. In the revised version we will remove the phrase 'proved effective across languages, document lengths, and annotation guidelines' from the abstract and replace it with a more precise statement that these choices were employed in the submitted system that achieved first place in the LLM track. revision: yes
-
Referee: [Results] Results section: the attribution of the 74.32 F1 and first-place LLM-track ranking to the combination of two-stage adaptation plus the three representation choices cannot be evaluated because the paper supplies no baseline that uses the same Gemma-3-27b and adapter schedule but omits the XML-inspired format or iterative annotation.
Authors: We agree that the current results section does not permit readers to isolate the impact of the XML-inspired format or iterative annotation from the two-stage adaptation itself. The reported ranking and F1 score reflect the complete pipeline. We will revise the results section to explicitly state that the 74.32 F1 is the performance of the full system and to avoid any phrasing that attributes specific gains to individual components without supporting controlled experiments. We will also add a short limitations paragraph noting the lack of such ablations. revision: yes
Circularity Check
No circularity: empirical shared-task performance is externally measured
full rationale
The paper reports an end-to-end experimental outcome on the official CRAC 2026 test set: a fine-tuned Gemma-3-27b system with two-stage adapters and headword XML mention representation achieves 74.32 CoNLL F1 and first place in the LLM track. This score is obtained by direct evaluation on held-out data provided by the shared task organizers and does not reduce to any internal equation, fitted parameter renamed as prediction, or self-citation chain. The design choices are described as inputs to the system; the reported metric is an independent external benchmark rather than a quantity derived from those choices by construction. No uniqueness theorems, ansatzes, or renamings of known results appear in the derivation. The result is therefore self-contained as a standard empirical submission.
Axiom & Free-Parameter Ledger
free parameters (1)
- adapter weights
axioms (1)
- domain assumption Headword XML-inspired representation with local reindexing and iterative annotation generalizes effectively across languages and guidelines.
Reference graph
Works this paper leans on
-
[1]
Scaling Laws for Neural Language Models
Jared Kaplan and Sam McCandlish and Tom Henighan and Tom B. Brown and Benjamin Chess and Rewon Child and Scott Gray and Alec Radford and Jeffrey Wu and Dario Amodei , title =. CoRR , volume =. 2020 , url =. 2001.08361 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[2]
Context-Aware Machine Translation with Source Coreference Explanation
Vu, Huy Hien and Kamigaito, Hidetaka and Watanabe, Taro. Context-Aware Machine Translation with Source Coreference Explanation. Transactions of the Association for Computational Linguistics. 2024. doi:10.1162/tacl_a_00677
-
[3]
Radford, Benjamin. Seeing the Forest and the Trees: Detection and Cross-Document Coreference Resolution of Militarized Interstate Disputes. Proceedings of the Workshop on Automated Extraction of Socio-political Events from News 2020. 2020
work page 2020
-
[4]
Tourille, Julien and Ferret, Olivier and N \'e v \'e ol, Aur \'e lie and Tannier, Xavier. Mod \`e le neuronal pour la r \'e solution de la cor \'e f \'e rence dans les dossiers m \'e dicaux \'e lectroniques (Neural approach for coreference resolution in electronic health records ). Actes de la 6e conf \'e rence conjointe Journ \'e es d' \'E tudes sur la P...
work page 2020
-
[5]
Coreference Resolution for the Biomedical Domain: A Survey
Lu, Pengcheng and Poesio, Massimo. Coreference Resolution for the Biomedical Domain: A Survey. Proceedings of the Fourth Workshop on Computational Models of Reference, Anaphora and Coreference. 2021. doi:10.18653/v1/2021.crac-1.2
-
[6]
L egal C ore: A Dataset for Event Coreference Resolution in Legal Documents
Wei, Kangda and Shi, Xi and Tong, Jonathan and Sai Ramana Reddy and Natarajan, Anandhavelu and Jain, Rajiv and Garimella, Aparna and Huang, Ruihong. L egal C ore: A Dataset for Event Coreference Resolution in Legal Documents. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.1284
-
[7]
Coreference-Aware Dialogue Summarization
Liu, Zhengyuan and Shi, Ke and Chen, Nancy. Coreference-Aware Dialogue Summarization. Proceedings of the 22nd Annual Meeting of the Special Interest Group on Discourse and Dialogue. 2021. doi:10.18653/v1/2021.sigdial-1.53
-
[8]
D oc RED : A Large-Scale Document-Level Relation Extraction Dataset
Yao, Yuan and Ye, Deming and Li, Peng and Han, Xu and Lin, Yankai and Liu, Zhenghao and Liu, Zhiyuan and Huang, Lixin and Zhou, Jie and Sun, Maosong. D oc RED : A Large-Scale Document-Level Relation Extraction Dataset. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1074
-
[9]
Modeling the Construction of a Literary Archetype: The Case of the Detective Figure in French Literature , author =. 2025 , address = "Luxembourg", journal =. doi:10.63744/SMbYIWcHZj87 , url =
-
[10]
An Annotated Dataset of Coreference in E nglish Literature
Bamman, David and Lewke, Olivia and Mansoor, Anya. An Annotated Dataset of Coreference in E nglish Literature. Proceedings of the Twelfth Language Resources and Evaluation Conference. 2020
work page 2020
-
[11]
Computational Humanities Research Conference , pages=
Putting Dutchcoref to the Test: Character Detection and Gender Dynamics in Contemporary Dutch Novels , author=. Computational Humanities Research Conference , pages=. 2023 , organization=
work page 2023
-
[12]
Journal of Computational Literary Studies , year =
Mélanie, Frédérique and Barré, Jean and Seminck, Olga and Plancq, Clément and Naguib, Marco and Pastor, Martial and Poibeau, Thierry , title =. Journal of Computational Literary Studies , year =. doi:10.48694/jcls.3924 , url =
-
[13]
Kummerfeld, Jonathan K. and Klein, Dan. Error-Driven Analysis of Challenges in Coreference Resolution. Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. 2013
work page 2013
-
[14]
Lattice @ M ulti GEC -2025: A Spitful Multilingual Language Error Correction System Using LL a MA
Seminck, Olga and Dupont, Yoann and Dehouck, Mathieu and Wang, Qi and Durandard, No \'e and Novikov, Margo. Lattice @ M ulti GEC -2025: A Spitful Multilingual Language Error Correction System Using LL a MA. Proceedings of the 14th Workshop on Natural Language Processing for Computer Assisted Language Learning. 2025
work page 2025
-
[15]
The M ulti GEC -2025 Shared Task on Multilingual Grammatical Error Correction at NLP 4 CALL
Masciolini, Arianna and Caines, Andrew and De Clercq, Orph. The M ulti GEC -2025 Shared Task on Multilingual Grammatical Error Correction at NLP 4 CALL. Proceedings of the 14th Workshop on Natural Language Processing for Computer Assisted Language Learning. 2025
work page 2025
-
[16]
Staruch, Ryszard. UAM - CSI at M ulti GEC -2025: Parameter-efficient LLM Fine-tuning for Multilingual Grammatical Error Correction. Proceedings of the 14th Workshop on Natural Language Processing for Computer Assisted Language Learning. 2025
work page 2025
-
[17]
Cognitive computational models of pronoun resolution , author=. 2018 , school=
work page 2018
-
[18]
Explicitly Modeling Syntax in Language Models with Incremental Parsing and a Dynamic Oracle
Shen, Yikang and Tan, Shawn and Sordoni, Alessandro and Reddy, Siva and Courville, Aaron. Explicitly Modeling Syntax in Language Models with Incremental Parsing and a Dynamic Oracle. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021. doi:10.18653/v1/2021.naa...
- [19]
-
[20]
Publications Manual , year = "1983", publisher =
work page 1983
-
[21]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
- [22]
-
[23]
Dan Gusfield , title =. 1997
work page 1997
-
[24]
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
work page 2015
-
[25]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[26]
Design Challenges and Misconceptions in Named Entity Recognition
Ratinov, Lev and Roth, Dan. Design Challenges and Misconceptions in Named Entity Recognition. Proceedings of the Thirteenth Conference on Computational Natural Language Learning ( C o NLL -2009). 2009
work page 2009
-
[27]
A Controlled Reevaluation of Coreference Resolution Models
Porada, Ian and Zou, Xiyuan and Cheung, Jackie Chi Kit. A Controlled Reevaluation of Coreference Resolution Models. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 2024
work page 2024
-
[28]
Computational Humanites, Debates in Digital Humanities (2020, preprint) , year=
Litbank: Born-literary natural language processing , author=. Computational Humanites, Debates in Digital Humanities (2020, preprint) , year=
work page 2020
- [29]
- [30]
-
[31]
C or P ipe at CRAC 2024: Predicting Zero Mentions from Raw Text
Straka, Milan. C or P ipe at CRAC 2024: Predicting Zero Mentions from Raw Text. Proceedings of the Seventh Workshop on Computational Models of Reference, Anaphora and Coreference. 2024. doi:10.18653/v1/2024.crac-1.9
-
[32]
arXiv preprint arXiv:2209.12516 , year=
End-to-end multilingual coreference resolution with mention head prediction , author=. arXiv preprint arXiv:2209.12516 , year=
-
[33]
Cognitive psychology , volume=
Understanding natural language , author=. Cognitive psychology , volume=. 1972 , publisher=
work page 1972
-
[34]
Anaphora in natural language understanding: a survey , author=. 1981 , publisher=
work page 1981
-
[35]
Proceedings of the 6th conference on Message understanding , pages=
Design of the MUC-6 evaluation , author=. Proceedings of the 6th conference on Message understanding , pages=. 1995 , organization=
work page 1995
-
[36]
A Machine Learning Approach to Coreference Resolution of Noun Phrases
Soon, Wee Meng and Ng, Hwee Tou and Lim, Daniel Chung Yong. A Machine Learning Approach to Coreference Resolution of Noun Phrases. Computational Linguistics. 2001. doi:10.1162/089120101753342653
-
[37]
Conll-2011 shared task: Modeling unrestricted coreference in ontonotes , author=. Proceedings of the fifteenth conference on computational natural language learning: shared task , pages=
work page 2011
-
[38]
Specialized Models and Ranking for Coreference Resolution
Denis, Pascal and Baldridge, Jason. Specialized Models and Ranking for Coreference Resolution. Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing. 2008
work page 2008
-
[39]
Joint conference on EMNLP and CoNLL-shared task , pages=
CoNLL-2012 shared task: Modeling multilingual unrestricted coreference in OntoNotes , author=. Joint conference on EMNLP and CoNLL-shared task , pages=
work page 2012
-
[40]
End-to-end Neural Coreference Resolution
Lee, Kenton and He, Luheng and Lewis, Mike and Zettlemoyer, Luke. End-to-end Neural Coreference Resolution. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. 2017. doi:10.18653/v1/D17-1018
-
[41]
BERT for Coreference Resolution: Baselines and Analysis
Joshi, Mandar and Levy, Omer and Zettlemoyer, Luke and Weld, Daniel. BERT for Coreference Resolution: Baselines and Analysis. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1588
-
[42]
Journal of machine learning research , volume=
Exploring the limits of transfer learning with a unified text-to-text transformer , author=. Journal of machine learning research , volume=
-
[43]
Muzerelle, Judith and Lefeuvre, Ana. ANCOR, premier corpus de fran. TALN'2013, 20e conf
work page 2013
-
[44]
Coreference in Universal Dependencies 1.3 (
Nov. Coreference in Universal Dependencies 1.3 (
-
[45]
Neural Greedy Constituent Parsing with Dynamic Oracles
Coavoux, Maximin and Crabb \'e , Beno \^i t. Neural Greedy Constituent Parsing with Dynamic Oracles. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2016. doi:10.18653/v1/P16-1017
-
[46]
[Lions: 1] and [Tigers: 2] and [Bears: 3] , Oh My! Literary Coreference Annotation with LLM s
Hicke, Rebecca and Mimno, David. [Lions: 1] and [Tigers: 2] and [Bears: 3] , Oh My! Literary Coreference Annotation with LLM s. Proceedings of the 8th Joint SIGHUM Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature (LaTeCH-CLfL 2024). 2024
work page 2024
-
[47]
Evaluating Very Long-Term Conversational Memory of
Maharana, Adyasha and Lee, Dong-Ho and Tulyakov, Sergey and Bansal, Mohit and Barbieri, Francesco and Fang, Yuwei. Evaluating Very Long-Term Conversational Memory of LLM Agents. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.747
-
[48]
Large Language Models for Data Annotation and Synthesis: A Survey
Tan, Zhen and Li, Dawei and Wang, Song and Beigi, Alimohammad and Jiang, Bohan and Bhattacharjee, Amrita and Karami, Mansooreh and Li, Jundong and Cheng, Lu and Liu, Huan. Large Language Models for Data Annotation and Synthesis: A Survey. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emn...
-
[49]
Levy, Mosh and Jacoby, Alon and Goldberg, Yoav. Same Task, More Tokens: the Impact of Input Length on the Reasoning Performance of Large Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.818
-
[50]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
A Theoretical Analysis of the Repetition Problem in Text Generation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=. 2021 , organization=
work page 2021
-
[51]
Proceedings of the 41st International Conference on Machine Learning , pages=
From self-attention to markov models: unveiling the dynamics of generative transformers , author=. Proceedings of the 41st International Conference on Machine Learning , pages=
-
[52]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Liu, Nelson F. and Lin, Kevin and Hewitt, John and Paranjape, Ashwin and Bevilacqua, Michele and Petroni, Fabio and Liang, Percy. Lost in the Middle: How Language Models Use Long Contexts. Transactions of the Association for Computational Linguistics. 2024. doi:10.1162/tacl_a_00638
-
[53]
QLoRA: Efficient Finetuning of Quantized LLMs , url =
Dettmers, Tim and Pagnoni, Artidoro and Holtzman, Ari and Zettlemoyer, Luke , booktitle =. QLoRA: Efficient Finetuning of Quantized LLMs , url =
- [54]
-
[55]
Seq2seq is All You Need for Coreference Resolution
Zhang, Wenzheng and Wiseman, Sam and Stratos, Karl. Seq2seq is All You Need for Coreference Resolution. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.704
-
[56]
Zhu, Lixing and Wang, Jun and He, Yulan. L lm L ink: Dual LLM s for Dynamic Entity Linking on Long Narratives with Collaborative Memorisation and Prompt Optimisation. Proceedings of the 31st International Conference on Computational Linguistics. 2025
work page 2025
-
[57]
Assessing the Capabilities of Large Language Models in Coreference: An Evaluation
Gan, Yujian and Poesio, Massimo and Yu, Juntao. Assessing the Capabilities of Large Language Models in Coreference: An Evaluation. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 2024
work page 2024
-
[58]
Moving on from O nto N otes: Coreference Resolution Model Transfer
Xia, Patrick and Van Durme, Benjamin. Moving on from O nto N otes: Coreference Resolution Model Transfer. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.425
-
[59]
W iki C oref: An E nglish Coreference-annotated Corpus of W ikipedia Articles
Ghaddar, Abbas and Langlais, Phillippe. W iki C oref: An E nglish Coreference-annotated Corpus of W ikipedia Articles. Proceedings of the Tenth International Conference on Language Resources and Evaluation ( LREC `16). 2016
work page 2016
-
[60]
Hovy, Eduard and Marcus, Mitchell and Palmer, Martha and Ramshaw, Lance and Weischedel, Ralph. O nto N otes: The 90 \. Proceedings of the Human Language Technology Conference of the NAACL , Companion Volume: Short Papers. 2006
work page 2006
-
[61]
Towards Coreference for Literary Text: Analyzing Domain-Specific Phenomena
Roesiger, Ina and Schulz, Sarah and Reiter, Nils. Towards Coreference for Literary Text: Analyzing Domain-Specific Phenomena. Proceedings of the Second Joint SIGHUM Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature. 2018
work page 2018
-
[62]
Cohen, K. Bretonnel and Lanfranchi, Arrick and Choi, Miji Joo-young and Bada, Michael and Baumgartner, William A. and Panteleyeva, Natalya and Verspoor, Karin and Palmer, Martha and Hunter, Lawrence E. , title=. BMC Bioinformatics , year=. doi:10.1186/s12859-017-1775-9 , url=
-
[63]
Computational Linguistics in the Netherlands Journal , author=
A Dutch coreference resolution system with an evaluation on literary fiction , volume=. Computational Linguistics in the Netherlands Journal , author=. 2019 , month=
work page 2019
-
[64]
Coreference in Universal Dependencies 1.4 (
Nov. Coreference in Universal Dependencies 1.4 (
-
[65]
C oref UD 1.0: Coreference Meets U niversal D ependencies
Nedoluzhko, Anna and Nov \'a k, Michal and Popel, Martin and Z abokrtsk \'y , Zden e k and Zeldes, Amir and Zeman, Daniel. C oref UD 1.0: Coreference Meets U niversal D ependencies. Proceedings of the Thirteenth Language Resources and Evaluation Conference. 2022
work page 2022
-
[66]
Manning, Joakim Nivre, and Daniel Zeman
de Marneffe, Marie-Catherine and Manning, Christopher D. and Nivre, Joakim and Zeman, Daniel. U niversal D ependencies. Computational Linguistics. 2021. doi:10.1162/coli_a_00402
-
[67]
Findings of the Third Shared Task on Multilingual Coreference Resolution
Nov \'a k, Michal and Dohnalov \'a , Barbora and Konopik, Miloslav and Nedoluzhko, Anna and Popel, Martin and Prazak, Ondrej and Sido, Jakub and Straka, Milan and Z abokrtsk \'y , Zden e k and Zeman, Daniel. Findings of the Third Shared Task on Multilingual Coreference Resolution. Proceedings of the Seventh Workshop on Computational Models of Reference, A...
-
[68]
Nov \'a k, Michal and Konopik, Miloslav and Nedoluzhko, Anna and Popel, Martin and Prazak, Ondrej and Sido, Jakub and Straka, Milan and Z abokrtsk \'y , Zden e k and Zeman, Daniel. Findings of the Fourth Shared Task on Multilingual Coreference Resolution: Can LLM s Dethrone Traditional Approaches?. Proceedings of the Eighth Workshop on Computational Model...
-
[69]
Computational Linguistics in the Netherlands Journal , author=
OpenBoek: A Corpus of Literary Coreference and Entities with an Exploration of Historical Spelling Normalization , volume=. Computational Linguistics in the Netherlands Journal , author=. 2022 , month=
work page 2022
-
[70]
C or P ipe at CRAC 2025: Evaluating Multilingual Encoders for Multilingual Coreference Resolution
Straka, Milan. C or P ipe at CRAC 2025: Evaluating Multilingual Encoders for Multilingual Coreference Resolution. Proceedings of the Eighth Workshop on Computational Models of Reference, Anaphora and Coreference. 2025. doi:10.18653/v1/2025.crac-1.11
-
[71]
GL a R ef@ CRAC 2025: Should we transform coreference resolution into a text generation task?
Seminck, Olga and Bourgois, Antoine and Dupont, Yoann and Dehouck, Mathieu and Delaborde, Marine. GL a R ef@ CRAC 2025: Should we transform coreference resolution into a text generation task?. Proceedings of the Eighth Workshop on Computational Models of Reference, Anaphora and Coreference. 2025. doi:10.18653/v1/2025.crac-1.10
-
[72]
Findings of the Shared Task on Multilingual Coreference Resolution
Z abokrtsk \'y , Zden e k and Konop \'i k, Miloslav and Nedoluzhko, Anna and Nov \'a k, Michal and Ogrodniczuk, Maciej and Popel, Martin and Pra z \'a k, Ond r ej and Sido, Jakub and Zeman, Daniel and Zhu, Yilun. Findings of the Shared Task on Multilingual Coreference Resolution. Proceedings of the CRAC 2022 Shared Task on Multilingual Coreference Resolut...
work page 2022
- [73]
-
[74]
C o NLL -2012 Shared Task: Modeling Multilingual Unrestricted Coreference in O nto N otes
Pradhan, Sameer and Moschitti, Alessandro and Xue, Nianwen and Uryupina, Olga and Zhang, Yuchen. C o NLL -2012 Shared Task: Modeling Multilingual Unrestricted Coreference in O nto N otes. Joint Conference on EMNLP and C o NLL - Shared Task. 2012
work page 2012
-
[75]
Fine-Tuned Llama for Multilingual Text-to-Text Coreference Resolution
Hejman, Jakub and Prazak, Ondrej and Konop \'i k, Miloslav. Fine-Tuned Llama for Multilingual Text-to-Text Coreference Resolution. Proceedings of the Eighth Workshop on Computational Models of Reference, Anaphora and Coreference. 2025. doi:10.18653/v1/2025.crac-1.12
-
[76]
Few-Shot Coreference Resolution with Semantic Difficulty Metrics and In-Context Learning
Phuc, Nguyen Xuan and Thin, Dang Van. Few-Shot Coreference Resolution with Semantic Difficulty Metrics and In-Context Learning. Proceedings of the Eighth Workshop on Computational Models of Reference, Anaphora and Coreference. 2025. doi:10.18653/v1/2025.crac-1.13
-
[77]
End-to-end Multilingual Coreference Resolution with Headword Mention Representation
Prazak, Ondrej and Konop \'i k, Miloslav. End-to-end Multilingual Coreference Resolution with Headword Mention Representation. Proceedings of the Seventh Workshop on Computational Models of Reference, Anaphora and Coreference. 2024. doi:10.18653/v1/2024.crac-1.10
-
[78]
Word-Level Coreference Resolution
Dobrovolskii, Vladimir. Word-Level Coreference Resolution. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.605
-
[79]
Computational Humanities Research , year =
Bourgois, Antoine and Barré, Jean and Seminck, Olga and Poibeau, Thierry , title =. Computational Humanities Research , year =. doi:10.1017/chr.2026.10025 , url =
-
[80]
The Elephant in the Coreference Room: Resolving Coreference in Full-Length F rench Fiction Works
Bourgois, Antoine and Poibeau, Thierry. The Elephant in the Coreference Room: Resolving Coreference in Full-Length F rench Fiction Works. Proceedings of the Eighth Workshop on Computational Models of Reference, Anaphora and Coreference. 2025. doi:10.18653/v1/2025.crac-1.5
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.