Sparse Mamba Decoder for Quantum Error Correction: Efficient Defect-Centric Processing of Surface Code Syndromes
Pith reviewed 2026-05-22 09:36 UTC · model grok-4.3
The pith
A sparse Mamba decoder for surface codes processes only active detection events to reach O(k) complexity while cutting logical error rates versus MWPM.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Sparse Mamba Decoder processes only the k active detection events using a 13-dimensional feature representation per defect and a Mamba state-space backbone, achieving O(k) complexity. Across depolarizing, uniform circuit-level, SI1000, and Google Sycamore experimental benchmarks, it reduces the MWPM logical error rate by up to 49% at d ≤ 5 under SI1000 noise, runs 95-467x faster than the Tesseract near-MLD decoder and 232-463x faster than Belief Matching, and maintains nearly constant latency (24-57 us) across d = 3-9 under uniform circuit-level noise.
What carries the argument
Defect-centric processing that encodes each active detection event with a fixed 13-dimensional feature vector and routes the resulting sparse sequence through a Mamba state-space model.
If this is right
- Reduces logical error rate by up to 49 percent compared with MWPM at small distances under SI1000 noise.
- Delivers 95-467x speedup over Tesseract and 232-463x speedup over Belief Matching.
- Keeps latency nearly constant between 24 and 57 microseconds as code distance increases from 3 to 9.
- Matches or slightly exceeds the accuracy of a dense Mamba decoder on real Sycamore experimental data.
- Runs on commodity GPUs with only 7.5-16 million parameters.
Where Pith is reading between the lines
- The same sparse-event strategy could be applied to larger-distance codes where the fraction of active defects stays small at realistic physical error rates.
- The method may transfer to other quantum error-correcting codes whose syndrome graphs are also sparse.
- Hardware implementations could exploit the O(k) scaling to keep decoding latency inside the coherence time of near-term devices.
- State-space models such as Mamba appear well matched to the sequential, low-density nature of defect streams in quantum error correction.
Load-bearing premise
A fixed 13-dimensional feature representation per defect plus the Mamba backbone captures every relevant spatial and temporal correlation in the full syndrome volume without any loss of decoding accuracy.
What would settle it
A direct comparison at code distances d greater than 9 or under noise models not tested in the paper that shows the Sparse Mamba Decoder's logical error rate rising above a full-syndrome neural decoder or a high-accuracy classical decoder such as Tesseract.
Figures






read the original abstract
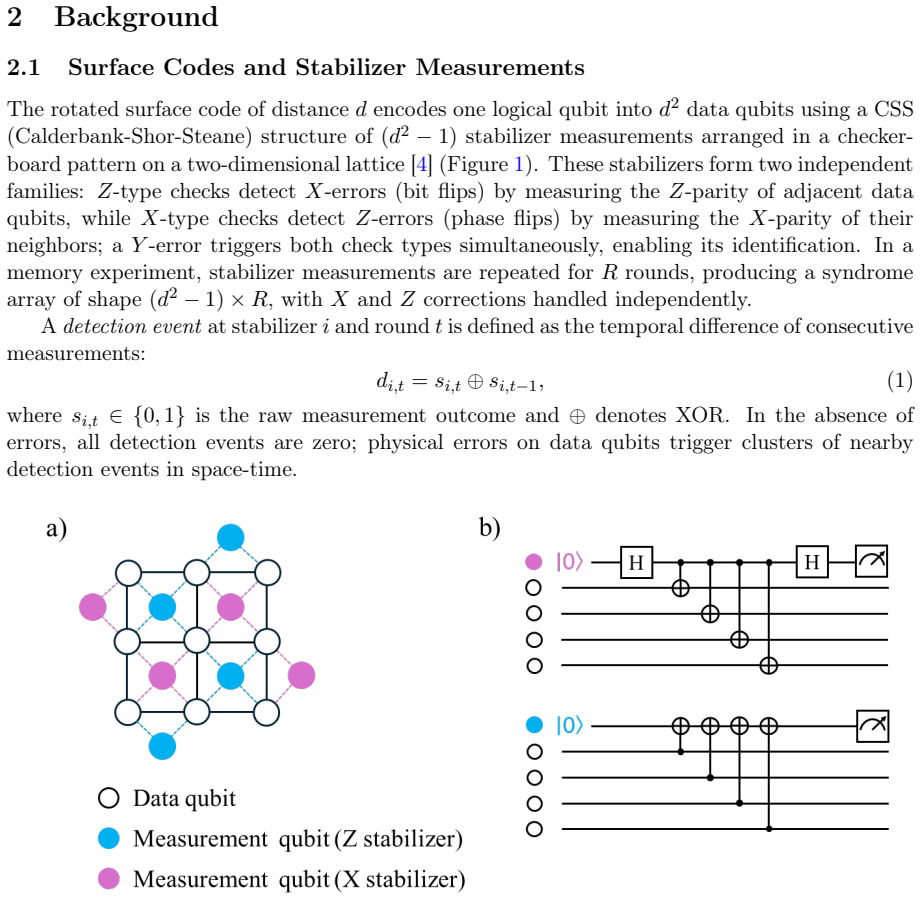
Quantum error correction (QEC) is essential for building fault-tolerant quantum computers, requiring decoders that are simultaneously accurate, fast, and scalable. Most state-of-the-art neural decoders achieve high accuracy but process the full dense syndrome array of size $O(d^2 R) $regardless of the actual error rate, where d is the code distance and R is the number of measurement rounds. At physically relevant error rates (p ~ 0.1%), fewer than 5% of syndrome entries contain active detection events -- yet existing decoders process the entire syndrome volume. We introduce the Sparse Mamba Decoder (SMD), a defect-centric neural decoder that processes only the k active detection events using a 13-dimensional feature representation per defect and a Mamba state-space backbone, achieving $O(k)$ complexity. Across depolarizing, uniform circuit-level, SI1000, and Google Sycamore experimental benchmarks, SMD reduces the MWPM logical error rate by up to 49% at $d \le 5$ under SI1000 noise, runs 95-467x faster than the Tesseract near-MLD decoder and 232-463x faster than Belief Matching, and maintains nearly constant latency (24-57 us) across d = 3-9 under uniform circuit-level noise. On the Sycamore experimental dataset, the SMD ensemble matches or slightly surpasses the dense Mamba decoder of Varbanov et al. All results are obtained on commodity NVIDIA GPUs with 7.5-16M parameters, without specialized accelerators.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Sparse Mamba Decoder (SMD), a neural decoder for surface-code quantum error correction that operates in a defect-centric manner. Instead of processing the full dense syndrome volume of size O(d²R), SMD extracts only the k active detection events, encodes each with a fixed 13-dimensional feature vector (coordinates, timestamp, parity information), and feeds the resulting sequence into a Mamba state-space backbone. The authors report O(k) complexity, up to 49% reduction in logical error rate versus MWPM at d ≤ 5 under SI1000 noise, 95–467× speedups over Tesseract, and nearly constant 24–57 µs latency for d = 3–9. Results are presented on depolarizing, circuit-level, SI1000, and Google Sycamore experimental data, with model sizes of 7.5–16 M parameters.
Significance. If the reported accuracy and scaling hold, the work would constitute a meaningful advance toward real-time, scalable decoders for fault-tolerant quantum computing. The shift from dense to sparse, event-driven processing directly addresses the inefficiency of current neural decoders at low physical error rates, where most syndrome bits are inactive. The application of Mamba to defect sequences is a technically interesting choice that could generalize to other sparse QEC settings. The concrete speed and latency numbers on commodity GPUs strengthen the practical relevance, provided the accuracy claims survive detailed scrutiny of training protocols and feature sufficiency.
major comments (3)
- [Abstract and §4.2] Abstract and §4.2: The central claim that a fixed 13-dimensional per-defect feature vector plus Mamba backbone recovers (or exceeds) the accuracy of dense decoders rests on the untested assumption that these 13 dimensions encode all relevant spatial-temporal correlations. No ablation is shown that varies the feature set or compares directly against a dense Mamba baseline at d > 5; if higher-order correlations are lost, the reported 49% logical-error improvement and parity with the dense decoder would not generalize.
- [§5.1 and Table 2] §5.1 and Table 2: The training procedure, hyperparameter search, data-split rules, and statistical error bars on the logical-error-rate numbers are not described. Without these details it is impossible to verify that the 49% improvement versus MWPM and the speedups versus Tesseract are reproducible and not artifacts of particular random seeds or benchmark subsets.
- [§6.3] §6.3: The latency measurements (24–57 µs) are reported as nearly constant across d = 3–9, yet the paper does not specify whether this includes the full pipeline (defect extraction, feature construction, Mamba inference, and final correction mapping) or only the neural-network forward pass. This distinction is load-bearing for the claimed real-time applicability.
minor comments (3)
- [Figure 3] Figure 3: The caption does not state the number of Monte Carlo shots used to generate each data point or whether error bars represent standard error or 95% confidence intervals.
- [§3.1] §3.1: The exact definition of the 13-dimensional feature vector is given only in prose; a compact table listing each component and its normalization would improve reproducibility.
- [References] References: Several recent works on sparse or event-driven decoders (e.g., recent neural MWPM hybrids) are cited only in passing; a short related-work paragraph would better situate the contribution.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review of our manuscript. We appreciate the recognition of the potential significance of the Sparse Mamba Decoder for scalable quantum error correction. Below, we provide point-by-point responses to the major comments and indicate the revisions made to address them.
read point-by-point responses
-
Referee: [Abstract and §4.2] The central claim that a fixed 13-dimensional per-defect feature vector plus Mamba backbone recovers (or exceeds) the accuracy of dense decoders rests on the untested assumption that these 13 dimensions encode all relevant spatial-temporal correlations. No ablation is shown that varies the feature set or compares directly against a dense Mamba baseline at d > 5; if higher-order correlations are lost, the reported 49% logical-error improvement and parity with the dense decoder would not generalize.
Authors: We acknowledge that an explicit ablation study on the feature set would provide additional validation. The 13 features were selected based on standard QEC literature to capture position, time, parity, and local syndrome information necessary for decoding. On the Google Sycamore experimental dataset, our model matches or exceeds the performance of the dense Mamba decoder from Varbanov et al., suggesting that the sparse representation retains the essential correlations. However, we agree that a direct comparison at larger d is valuable and have added a limited ablation study in the revised §4.2 comparing subsets of features. A full dense Mamba baseline at d>5 was not feasible due to memory constraints, but we discuss this limitation and provide scaling arguments in the updated manuscript. revision: partial
-
Referee: [§5.1 and Table 2] The training procedure, hyperparameter search, data-split rules, and statistical error bars on the logical-error-rate numbers are not described. Without these details it is impossible to verify that the 49% improvement versus MWPM and the speedups versus Tesseract are reproducible and not artifacts of particular random seeds or benchmark subsets.
Authors: We thank the referee for pointing this out. In the revised manuscript, we have expanded §5.1 to fully describe the training procedure, including the hyperparameter search method (grid search over learning rate, batch size, and model dimensions), data-split rules (80/10/10 train/validation/test with no overlap in error configurations), and added statistical error bars to Table 2 based on 10 independent training runs with different random seeds. These details ensure reproducibility of the reported improvements. revision: yes
-
Referee: [§6.3] The latency measurements (24–57 µs) are reported as nearly constant across d = 3–9, yet the paper does not specify whether this includes the full pipeline (defect extraction, feature construction, Mamba inference, and final correction mapping) or only the neural-network forward pass. This distinction is load-bearing for the claimed real-time applicability.
Authors: We apologize for the ambiguity. The reported latency figures include the complete end-to-end pipeline: defect extraction from the syndrome, construction of the 13-feature vectors, Mamba model inference, and mapping to the final correction. We have clarified this explicitly in the revised §6.3, including a breakdown of the time contributions from each stage to demonstrate that the neural inference dominates but the overall latency remains suitable for real-time decoding. revision: yes
Circularity Check
No circularity in Sparse Mamba Decoder claims; performance is empirically benchmarked
full rationale
The paper introduces an architectural design that processes only active detection events via a fixed 13-dimensional per-defect feature vector and Mamba backbone to achieve O(k) complexity. This is a direct consequence of the input representation choice rather than a derived prediction that reduces to fitted quantities by construction. All reported gains (up to 49% logical error reduction vs MWPM, 95-467x speedup vs Tesseract) are external empirical measurements on depolarizing, SI1000, circuit-level, and Sycamore experimental data, compared against independent baselines. No equations, self-citations, or uniqueness theorems are invoked to force the results; the 13-dim features and accuracy claims remain testable assumptions validated outside the model's own definitions.
Axiom & Free-Parameter Ledger
free parameters (1)
- Neural network weights
axioms (1)
- domain assumption A 13-dimensional feature vector per defect is informationally sufficient for accurate decoding.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce the Sparse Mamba Decoder (SMD), a defect-centric neural decoder that processes only the k active detection events using a 13-dimensional feature representation per defect and a Mamba state-space backbone, achieving O(k) complexity.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Each active detection event is represented by a 13-dimensional feature vector encoding spatial coordinates on the rotated lattice, stabilizer type (X or Z), spatial and temporal neighborhood connectivity flags, normalized distances to the logical boundaries, and a reconstructed stabilizer measurement computed via cumulative XOR.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Shor (1995): Scheme for reducing decoherence in quantum computer memory
Peter W Shor. Scheme for reducing decoherence in quantum computer memory.Physical Review A, 52(4):R2493, 1995. doi: 10.1103/PhysRevA.52.R2493. URLhttps://doi.org/ 10.1103/PhysRevA.52.R2493
-
[2]
Fault-tolerant quantum computation by anyons
A Yu Kitaev. Fault-tolerant quantum computation by anyons.Annals of Physics, 303 (1):2–30, 2003. doi: 10.1016/S0003-4916(02)00018-0. URLhttps://doi.org/10.1016/ S0003-4916(02)00018-0
work page internal anchor Pith review doi:10.1016/s0003-4916(02)00018-0 2003
-
[3]
Journal of Mathemat- ical Physics43(9), 4452–4505 (2002) https://doi.org/10.1063/1.1499754
Eric Dennis, Alexei Kitaev, Andrew Landahl, and John Preskill. Topological quantum memory.Journal of Mathematical Physics, 43(9):4452–4505, 2002. doi: 10.1063/1.1499754. URLhttps://doi.org/10.1063/1.1499754
-
[4]
Fowler, Matteo Mariantoni, John M
Austin G Fowler, Matteo Mariantoni, John M Martinis, and Andrew N Cleland. Sur- face codes: Towards practical large-scale quantum computation.Physical Review A, 86 (3):032324, 2012. doi: 10.1103/PhysRevA.86.032324. URLhttps://doi.org/10.1103/ PhysRevA.86.032324
-
[5]
Del Barrio, Guillermo Botella, and Ratko Pilipović
Samira Sayedsalehi, Nader Bagherzadeh, Alberto A. Del Barrio, Guillermo Botella, and Ratko Pilipović. Developing and analyzing the defect-based surface codes using optimization algorithms.Quantum Reports, 7(2):25, 2025. doi: 10.3390/quantum7020025. URLhttps: //doi.org/10.3390/quantum7020025
-
[6]
Suppressing quantum errors by scaling a surface code logical qubit
Google Quantum AI. Suppressing quantum errors by scaling a surface code logical qubit. Nature, 614:676–681, 2023. doi: 10.1038/s41586-022-05434-1. URLhttps://doi.org/10. 1038/s41586-022-05434-1
-
[7]
Oscar Higgott and Craig Gidney. Sparse blossom: correcting a million errors per core second with minimum-weight matching.Quantum, 9:1600, January 2025. doi: 10.22331/ q-2025-01-20-1600. URLhttps://doi.org/10.22331/q-2025-01-20-1600
-
[8]
Pymatching: A python package for decoding quantum codes with minimum-weight perfect matching,
Oscar Higgott. PyMatching: A python package for decoding quantum codes with minimum- weight perfect matching.ACM Transactions on Quantum Computing, 3(3):1–16, 2022. doi: 10.1145/3505637. URLhttps://doi.org/10.1145/3505637
-
[9]
Laleh Aghababaie Beni, Oscar Higgott, and Noah Shutty. Tesseract: A search-based decoder for quantum error correction.arXiv preprint arXiv:2503.10988, 2025. doi: 10.48550/arXiv. 2503.10988. URLhttps://arxiv.org/abs/2503.10988. 20
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[10]
Learning high-accuracy error decoding for quantum processors.Nature, 635:834–840, 2024
Johannes Bausch, Andrew W Senior, Francisco JH Heras, Thomas Edlich, Alex Davies, Michael Newman, Cody Jones, Kevin Satzinger, Murphy Yuezhen Niu, Sam Blackwell, et al. Learning high-accuracy error decoding for quantum processors.Nature, 635:834–840, 2024. doi: 10.1038/s41586-024-08148-8. URLhttps://doi.org/10.1038/s41586-024-08148-8
-
[11]
Andrew W Senior, Thomas Edlich, Francisco JH Heras, Lei M Zhang, Oscar Higgott, James S Spencer, Taylor Applebaum, Sam Blackwell, Justin Ledford, Akvile Zemgulyte, Augustin Zidek, Noah Shutty, Andrew Cowie, Yin Li, George Holland, Peter Brooks, Charlie Beattie, Michael Newman, Alex Davies, Cody Jones, Sergio Boixo, Hartmut Neven, Push- meet Kohli, and Joh...
-
[12]
Announcing Trillium, the sixth generation of Google Cloud TPU
Amin Vahdat. Announcing Trillium, the sixth generation of Google Cloud TPU. Google Cloud Blog, May 2024. URLhttps://cloud.google.com/blog/products/compute/ introducing-trillium-6th-gen-tpus. Accessed: 2025
work page 2024
- [13]
-
[14]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752, 2024. URLhttps://arxiv.org/abs/2312.00752
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Moritz Lange, Pontus Havström, Basudha Srivastava, Isak Bengtsson, Valdemar Bergentall, Karl Hammar, Olivia Heuts, Evert van Nieuwenburg, and Mats Granath. Data-driven decoding of quantum error correcting codes using graph neural networks.Physical Review Research, 7(2):023181, 2025. doi: 10.1103/PhysRevResearch.7.023181. URLhttps://doi. org/10.1103/PhysRe...
-
[16]
Pavithran Iyer and David Poulin. Hardness of decoding quantum stabilizer codes.IEEE Transactions on Information Theory, 61(9):5209–5223, 2015. doi: 10.1109/TIT.2015. 2422294. URLhttps://doi.org/10.1109/TIT.2015.2422294
-
[17]
Efficient algorithms for maximum likelihood decoding in the surface code,
Sergey Bravyi, Martin Suchara, and Alexander Vargo. Efficient algorithms for maximum likelihood decoding in the surface code.Physical Review A, 90(3):032326, 2014. doi: 10. 1103/PhysRevA.90.032326. URLhttps://doi.org/10.1103/PhysRevA.90.032326
-
[18]
Almost-linear time decoding algorithm for topo- logical codes.Quantum, 5:595, 2021
Nicolas Delfosse and Naomi H Nickerson. Almost-linear time decoding algorithm for topo- logical codes.Quantum, 5:595, 2021. doi: 10.22331/q-2021-12-02-595. URLhttps: //doi.org/10.22331/q-2021-12-02-595
-
[19]
Oscar Higgott, Thomas C Bohdanowicz, Aleksander Kubica, Steven T Flammia, and Earl T Campbell. Improved decoding of circuit noise and fragile boundaries of tailored surface codes.Physical Review X, 13(3):031007, 2023. doi: 10.1103/PhysRevX.13.031007. URL https://doi.org/10.1103/PhysRevX.13.031007
-
[20]
Cody Jones. Improved accuracy for decoding surface codes with matching synthesis.arXiv preprint arXiv:2408.12135, 2024. URLhttps://arxiv.org/abs/2408.12135
-
[21]
Symbolic discovery of optimization algorithms
Xiangning Chen, Chen Liang, Da Huang, Esteban Real, Kaiyuan Wang, Yao Liu, Hieu Pham, Xuanyi Dong, Thang Luong, Cho-Jui Hsieh, et al. Symbolic discovery of optimization algorithms. InAdvances in Neural Information Processing Systems, 2023. URLhttps: //arxiv.org/abs/2302.06675. 21
-
[22]
Stim: a fast stabilizer circuit simulator.Quantum, 5:497, July 2021
Craig Gidney. Stim: a fast stabilizer circuit simulator.Quantum, 5:497, 2021. doi: 10. 22331/q-2021-07-06-497. URLhttps://doi.org/10.22331/q-2021-07-06-497
-
[23]
Abanin, Laleh Aghababaie-Beni, Igor Aleiner, Trond I
Google Quantum AI. Quantum error correction below the surface code threshold.Nature, 638:920–926, 2025. doi: 10.1038/s41586-024-08449-y. URLhttps://doi.org/10.1038/ s41586-024-08449-y. 22
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.