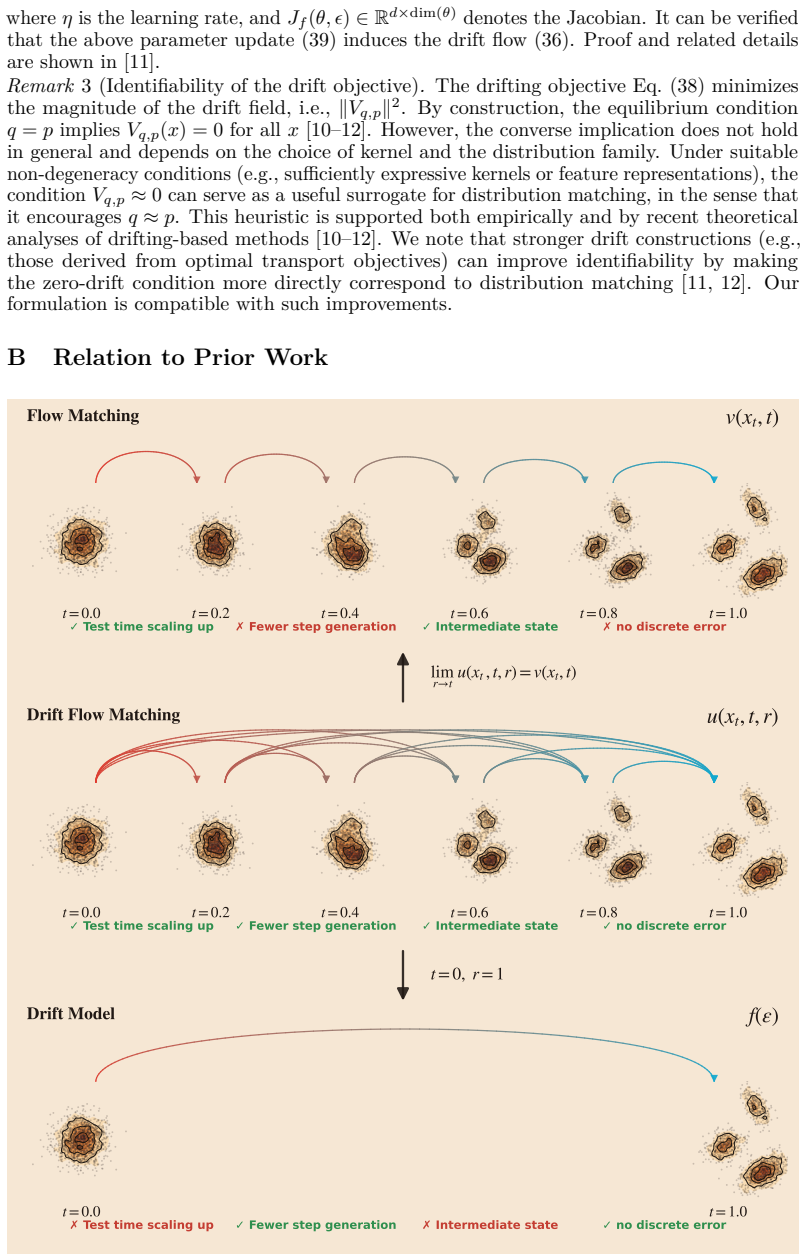
Drift Flow Matching
Pith reviewed 2026-05-20 14:27 UTC · model grok-4.3
The pith
Drift Flow Matching bridges one-step drift models with multi-step flow matching for adaptive generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DFM is a framework that connects drifting generative modeling with flow-based iterative generation. It preserves the efficiency of direct transport maps while enabling generation to be refined through multiple inference steps when desired. This bridges the gap between one-step Drift Models and multi-step Flow Matching methods.
What carries the argument
The Drift Flow Matching (DFM) framework, which integrates direct transport maps from drift models with flow-based iterative processes to allow variable numbers of inference steps.
If this is right
- Generation quality can be improved by increasing the number of inference steps without changing the model.
- Models retain the speed of one-step generation when only a single step is used.
- The framework adapts sampling computation to different quality-efficiency requirements across tasks.
- Extensive experiments show effectiveness on various datasets and tasks.
Where Pith is reading between the lines
- DFM could be extended to other generative paradigms like diffusion models for hybrid efficiency.
- Practitioners might use DFM to dynamically allocate compute based on user-specified quality needs in production systems.
- This approach suggests new ways to design models that optimize for both fast and high-quality sampling paths.
Load-bearing premise
A practical connection can be built between drifting generative modeling and flow-based iterative generation without losing the core efficiency or quality benefits of either approach.
What would settle it
If one-step DFM generation is slower or lower quality than standard drift models, or if adding more steps does not improve quality beyond the one-step baseline.
Figures






read the original abstract
Iterative generative models such as Flow Matching and Diffusion models have demonstrated strong test-time scaling behavior, where additional inference computation can improve generation quality. In contrast, Drift Models offer efficient one-step generation, but their direct generation paradigm limits such flexibility. In this work, we propose Drift Flow Matching (DFM), a framework that connects drifting generative modeling with flow-based iterative generation. DFM preserves the efficiency of direct transport maps while enabling generation to be refined through multiple inference steps when desired. This bridges the gap between one-step Drift Models and multi-step Flow Matching methods, and provides a novel generative paradigm that can adapt sampling computation to different quality--efficiency requirements. Extensive experiments across different tasks and datasets demonstrate the effectiveness and generality of the proposed framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Drift Flow Matching (DFM), a framework connecting drifting generative modeling with flow-based iterative generation. It claims that DFM preserves the efficiency of direct transport maps from Drift Models while enabling optional multi-step refinement for improved generation quality, thereby bridging one-step and multi-step paradigms and allowing adaptive computation based on quality-efficiency needs. Effectiveness and generality are asserted via extensive experiments across tasks and datasets.
Significance. If the central construction holds, the work could supply a practical generative paradigm that flexibly trades inference steps for quality without sacrificing the core speed of one-step models, addressing a relevant gap between efficient direct transport and test-time scalable iterative methods.
major comments (1)
- Abstract: the claim that DFM supports both exact one-step transport (preserving Drift Model efficiency) and consistent multi-step flow-matching trajectories rests on an implicit parameterization of the drift term. No equation, algorithm, or reparameterization is supplied showing how the velocity field is defined to permit exact one-step integration when desired while remaining consistent with the probability-flow ODE for multiple steps; if any auxiliary network or conditioning must still be evaluated in one-step mode, or if the learned drift deviates from the original transport map, the efficiency-preservation claim fails.
minor comments (1)
- The abstract asserts 'extensive experiments across different tasks and datasets' but supplies no concrete list of tasks, datasets, metrics, baselines, or controls, making it impossible to evaluate the generality and effectiveness claims from the provided text.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback on our manuscript. We address the single major comment below in detail.
read point-by-point responses
-
Referee: Abstract: the claim that DFM supports both exact one-step transport (preserving Drift Model efficiency) and consistent multi-step flow-matching trajectories rests on an implicit parameterization of the drift term. No equation, algorithm, or reparameterization is supplied showing how the velocity field is defined to permit exact one-step integration when desired while remaining consistent with the probability-flow ODE for multiple steps; if any auxiliary network or conditioning must still be evaluated in one-step mode, or if the learned drift deviates from the original transport map, the efficiency-preservation claim fails.
Authors: We thank the referee for this observation. The manuscript does supply the explicit reparameterization in Section 3.2 (Equations 5–7 and Algorithm 1): the velocity field is defined as v_θ(x_t, t) = drift_θ(x_0) · (1 − t) + flow-matching correction term, where the drift_θ component is trained to recover the original Drift Model transport map exactly when integrated in a single step. Consequently, one-step sampling requires only a single forward pass through the same network with no auxiliary conditioning or extra modules; multi-step sampling simply integrates the identical velocity field along the probability-flow ODE. The learned drift therefore does not deviate from the transport map—it is the map, augmented with a consistency term that vanishes at the one-step limit. To improve readability we will add one clarifying sentence to the abstract in the revision. revision: yes
Circularity Check
No significant circularity in the DFM proposal
full rationale
The manuscript proposes Drift Flow Matching as a new framework that connects drifting generative modeling with flow-based iterative generation. The abstract and available text frame this as a methodological bridge that preserves one-step efficiency while allowing optional multi-step refinement. No equations, derivations, or load-bearing steps are shown that reduce by construction to fitted inputs, self-citations, or renamed known results. The central claims rest on the existence of a parameterization enabling both regimes, presented as an independent contribution rather than a re-derivation of prior results from the same authors or data. This qualifies as a self-contained proposal with no detectable circular reduction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Vq,p(x) = V+_p(x) - V-_q(x) ... k(x,y) = exp(-C(x,y)/τ) with C(x,y) = ½∥x-y∥² ... LDFM(θ) := ½ E[∥X̂r - sg(X̂r + Vqθt,r,pr(X̂r))∥²]
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. InThe Eleventh International Confer- ence on Learning Representations, 2023. URLhttps://openreview.net/forum?id= PqvMRDCJT9t
work page 2023
-
[2]
Building normalizing flows with stochastic interpolants
Michael Samuel Albergo and Eric Vanden-Eijnden. Building normalizing flows with stochastic interpolants. InThe Eleventh International Conference on Learning Repre- sentations, 2023. URLhttps://openreview.net/forum?id=li7qeBbCR1t
work page 2023
-
[3]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, and Robin Rombach. Scaling rectified flow transformers for high-resolution image synthesis. InForty-first International Conference on Machine Learning, 2024. URLhttps:/...
work page 2024
-
[4]
Stochastic Interpolants: A Unifying Framework for Flows and Diffusions
Michael S Albergo, Nicholas M Boffi, and Eric Vanden-Eijnden. Stochastic inter- polants: A unifying framework for flows and diffusions, 2023.URL https://arxiv. org/abs/2303.08797, 3, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Diffusion self-distillation for zero-shot customized image generation
Shengqu Cai, Eric Ryan Chan, Yunzhi Zhang, Leonidas Guibas, Jiajun Wu, and Gordon Wetzstein. Diffusion self-distillation for zero-shot customized image generation. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 18434– 18443, 2025
work page 2025
-
[6]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. InInternational Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=PxTIG12RRHS
work page 2021
-
[8]
The Principles of Diffusion Models
Chieh-Hsin Lai, Yang Song, Dongjun Kim, Yuki Mitsufuji, and Stefano Ermon. The principles of diffusion models, 2025. URLhttps://arxiv.org/abs/2510.21890
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Learning straight flows: Variational flow matching for efficient generation, 2026
Chenrui Ma, Xi Xiao, Tianyang Wang, Xiao Wang, and Yanning Shen. Learning straight flows: Variational flow matching for efficient generation, 2026. URLhttps: //arxiv.org/abs/2511.17583
-
[10]
Generative Modeling via Drifting
Mingyang Deng, He Li, Tianhong Li, Yilun Du, and Kaiming He. Generative modeling via drifting.arXiv preprint arXiv:2602.04770, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Sinkhorn-Drifting Generative Models.arXiv preprint arXiv:2603.12366, 2026a
Ping He, Om Khangaonkar, Hamed Pirsiavash, Yikun Bai, and Soheil Kolouri. Sinkhorn- drifting generative models.arXiv preprint arXiv:2603.12366, 2026
-
[12]
A Unified View of Score-Based and Drifting Models
Chieh-Hsin Lai, Bac Nguyen, Naoki Murata, Yuhta Takida, Toshimitsu Uesaka, Yuki Mitsufuji, Stefano Ermon, and Molei Tao. A unified view of drifting and score-based models.arXiv preprint arXiv:2603.07514, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Scaling inference time compute for diffusion models
Nanye Ma, Shangyuan Tong, Haolin Jia, Hexiang Hu, Yu-Chuan Su, Mingda Zhang, Xuan Yang, Yandong Li, Tommi Jaakkola, Xuhui Jia, et al. Scaling inference time compute for diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 2523–2534, 2025
work page 2025
-
[14]
A general framework for inference-time scaling and steering of diffusion models
Raghav Singhal, Zachary Horvitz, Ryan Teehan, Mengye Ren, Zhou Yu, Kathleen McKeown, and Rajesh Ranganath. A general framework for inference-time scaling and steering of diffusion models.arXiv preprint arXiv:2501.06848, 2025
-
[15]
Shufan Li, Konstantinos Kallidromitis, Akash Gokul, Arsh Koneru, Yusuke Kato, Kazuki Kozuka, and Aditya Grover. Reflect-dit: Inference-time scaling for text-to- image diffusion transformers via in-context reflection. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15657–15668, 2025. 10
work page 2025
-
[16]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and qiang liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InThe Eleventh International Confer- ence on Learning Representations, 2023. URLhttps://openreview.net/forum?id= XVjTT1nw5z
work page 2023
-
[17]
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. In Proceedings of the 40th International Conference on Machine Learning, pages 32211– 32252, 2023
work page 2023
-
[18]
Con- sistency models made easy
Zhengyang Geng, Ashwini Pokle, Weijian Luo, Justin Lin, and J Zico Kolter. Con- sistency models made easy. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=xQVxo9dSID
work page 2025
-
[19]
Consistency trajectory models: Learning probability flow ODE trajectory of diffusion
Dongjun Kim, Chieh-Hsin Lai, Wei-Hsiang Liao, Naoki Murata, Yuhta Takida, Toshimitsu Uesaka, Yutong He, Yuki Mitsufuji, and Stefano Ermon. Consistency trajectory models: Learning probability flow ODE trajectory of diffusion. InThe Twelfth International Conference on Learning Representations, 2024. URL https: //openreview.net/forum?id=ymjI8feDTD
work page 2024
-
[20]
Simplifying, stabilizing and scaling continuous-time consis- tency models
Cheng Lu and Yang Song. Simplifying, stabilizing and scaling continuous-time consis- tency models. InThe Thirteenth International Conference on Learning Representations,
-
[21]
URLhttps://openreview.net/forum?id=LyJi5ugyJx
-
[22]
Improved techniques for training consistency models
Yang Song and Prafulla Dhariwal. Improved techniques for training consistency models. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=WNzy9bRDvG
work page 2024
-
[23]
One step diffusion via shortcut models
Kevin Frans, Danijar Hafner, Sergey Levine, and Pieter Abbeel. One step diffusion via shortcut models. InThe Thirteenth International Conference on Learning Representa- tions, 2025. URLhttps://openreview.net/forum?id=OlzB6LnXcS
work page 2025
-
[24]
Mean Flows for One-step Generative Modeling
Zhengyang Geng, Mingyang Deng, Xingjian Bai, J Zico Kolter, and Kaiming He. Mean flows for one-step generative modeling.arXiv preprint arXiv:2505.13447, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [25]
-
[26]
Zheyuan Hu, Chieh-Hsin Lai, Yuki Mitsufuji, and Stefano Ermon. Cmt: Mid-training for efficient learning of consistency, mean flow, and flow map models.arXiv preprint arXiv:2509.24526, 2025
-
[27]
Improved Mean Flows: On the Challenges of Fastforward Generative Models
Zhengyang Geng, Yiyang Lu, Zongze Wu, Eli Shechtman, J Zico Kolter, and Kaiming He. Improved mean flows: On the challenges of fastforward generative models.arXiv preprint arXiv:2512.02012, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
One-step Latent-free Image Generation with Pixel Mean Flows
Yiyang Lu, Susie Lu, Qiao Sun, Hanhong Zhao, Zhicheng Jiang, Xianbang Wang, Tianhong Li, Zhengyang Geng, and Kaiming He. One-step latent-free image generation with pixel mean flows.arXiv preprint arXiv:2601.22158, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Transition flow matching.arXiv preprint arXiv:2603.15689, 2026
Chenrui Ma. Transition flow matching.arXiv preprint arXiv:2603.15689, 2026
-
[30]
Align your flow: Scaling continuous-time flow map distillation.arXiv preprint arXiv:2506.14603, 2025
Amirmojtaba Sabour, Sanja Fidler, and Karsten Kreis. Align your flow: Scaling continuous-time flow map distillation.arXiv preprint arXiv:2506.14603, 2025
-
[31]
Large Scale Diffusion Distillation via Score-Regularized Continuous-Time Consistency
Kaiwen Zheng, Yuji Wang, Qianli Ma, Huayu Chen, Jintao Zhang, Yogesh Balaji, Jianfei Chen, Ming-Yu Liu, Jun Zhu, and Qinsheng Zhang. Large scale diffusion distillation via score-regularized continuous-time consistency.arXiv preprint arXiv:2510.08431, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Tunyu Zhang, Xinxi Zhang, Ligong Han, Haizhou Shi, Xiaoxiao He, Zhuowei Li, Hao Wang, Kai Xu, Akash Srivastava, Vladimir Pavlovic, et al. T3d: Few-step diffusion language models via trajectory self-distillation with direct discriminative optimization. arXiv preprint arXiv:2602.12262, 2026. 11
-
[33]
Fu-Yun Wang, Ling Yang, Zhaoyang Huang, Mengdi Wang, and Hongsheng Li. Rectified diffusion: Straightness is not your need in rectified flow.arXiv preprint arXiv:2410.07303, 2024
-
[34]
Towards hierarchical rectified flow
Yichi Zhang, Yici Yan, Alex Schwing, and Zhizhen Zhao. Towards hierarchical rectified flow. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=6F6qwdycgJ
work page 2025
-
[35]
Improving the training of rectified flows
Sangyun Lee, Zinan Lin, and Giulia Fanti. Improving the training of rectified flows. Advances in neural information processing systems, 37:63082–63109, 2024
work page 2024
-
[36]
One-step diffusion distillation via deep equilibrium models
Zhengyang Geng, Ashwini Pokle, and J Zico Kolter. One-step diffusion distillation via deep equilibrium models. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URLhttps://openreview.net/forum?id=b6XvK2de99
work page 2023
-
[37]
Progressive distillation for fast sampling of diffusion models
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models. InInternational Conference on Learning Representations, 2022. URLhttps: //openreview.net/forum?id=TIdIXIpzhoI
work page 2022
-
[38]
Mp1: Meanflow tames policy learning in 1-step for robotic manipulation
Juyi Sheng, Ziyi Wang, Peiming Li, and Mengyuan Liu. Mp1: Meanflow tames policy learning in 1-step for robotic manipulation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 18532–18539, 2026
work page 2026
-
[39]
One- step generative policies with q-learning: A reformulation of meanflow
Zeyuan Wang, Da Li, Yulin Chen, Ye Shi, Liang Bai, Tianyuan Yu, and Yanwei Fu. One- step generative policies with q-learning: A reformulation of meanflow. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 26751–26759, 2026
work page 2026
-
[40]
MeanAudio: Fast and faithful text-to-audio generation with mean flows,
Xiquan Li, Junxi Liu, Yuzhe Liang, Zhikang Niu, Wenxi Chen, and Xie Chen. Meanau- dio: Fast and faithful text-to-audio generation with mean flows.arXiv preprint arXiv:2508.06098, 2025
-
[41]
Constrained diffusion for protein design with hard structural constraints
Jacob K Christopher, Austin Seamann, Jingyi Cui, Sagar Khare, and Ferdinando Fioretto. Constrained diffusion for protein design with hard structural constraints. arXiv preprint arXiv:2510.14989, 2025
-
[42]
Yaron Lipman, Marton Havasi, Peter Holderrieth, Neta Shaul, Matt Le, Brian Karrer, Ricky T. Q. Chen, David Lopez-Paz, Heli Ben-Hamu, and Itai Gat. Flow matching guide and code, 2024. URLhttps://arxiv.org/abs/2412.06264
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Stochastic interpolants with data-dependent couplings
Michael Samuel Albergo, Mark Goldstein, Nicholas Matthew Boffi, Rajesh Ranganath, and Eric Vanden-Eijnden. Stochastic interpolants with data-dependent couplings. In International Conference on Machine Learning, pages 921–937. PMLR, 2024
work page 2024
-
[44]
VCT: Training consistency models with variational noise coupling
Gianluigi Silvestri, Luca Ambrogioni, Chieh-Hsin Lai, Yuhta Takida, and Yuki Mitsufuji. VCT: Training consistency models with variational noise coupling. InForty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/ forum?id=CMoX0BEsDs
work page 2025
-
[45]
Multisample flow matching: Straightening flows with minibatch couplings
Aram-Alexandre Pooladian, Heli Ben-Hamu, Carles Domingo-Enrich, Brandon Amos, Yaron Lipman, and Ricky TQ Chen. Multisample flow matching: Straightening flows with minibatch couplings. InInternational Conference on Machine Learning, pages 28100–28127. PMLR, 2023
work page 2023
-
[46]
Hierarchical rectified flow matching with mini-batch couplings.arXiv preprint arXiv:2507.13350, 2025
Yichi Zhang, Yici Yan, Alex Schwing, and Zhizhen Zhao. Hierarchical rectified flow matching with mini-batch couplings.arXiv preprint arXiv:2507.13350, 2025
-
[47]
Stochastic gradient descent tricks
Léon Bottou. Stochastic gradient descent tricks. InNeural networks: tricks of the trade: second edition, pages 421–436. Springer, 2012
work page 2012
-
[48]
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models.Advances in neural information processing systems, 35:26565–26577, 2022. 12
work page 2022
-
[49]
Learning representations by back-propagating errors.nature, 323(6088):533–536, 1986
David E Rumelhart, Geoffrey E Hinton, and Ronald J Williams. Learning representations by back-propagating errors.nature, 323(6088):533–536, 1986
work page 1986
-
[50]
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, Kyle Lacey, Alex Goodwin, Yannik Marek, and Robin Rombach. Scaling rectified flow transformers for high-resolution image synthesis, 2024. URLhttps://arxiv.org/abs/2403.03206
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers
Nanye Ma, Mark Goldstein, Michael S Albergo, Nicholas M Boffi, Eric Vanden-Eijnden, and Saining Xie. Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers. InEuropean Conference on Computer Vision, pages 23–40. Springer, 2024
work page 2024
-
[52]
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
Sihyun Yu, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie. Representation alignment for generation: Training diffusion transformers is easier than you think.arXiv preprint arXiv:2410.06940, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
Jingfeng Yao, Bin Yang, and Xinggang Wang. Reconstruction vs. generation: Taming optimization dilemma in latent diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 15703–15712, 2025
work page 2025
-
[54]
Diffusion Transformers with Representation Autoencoders
Boyang Zheng, Nanye Ma, Shengbang Tong, and Saining Xie. Diffusion transformers with representation autoencoders.arXiv preprint arXiv:2510.11690, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Shanchuan Lin, Ceyuan Yang, Zhijie Lin, Hao Chen, and Haoqi Fan. Adversarial flow models.arXiv preprint arXiv:2511.22475, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Linqi Zhou, Stefano Ermon, and Jiaming Song. Inductive moment matching. In Forty-second International Conference on Machine Learning, 2025. URLhttps:// openreview.net/forum?id=pwNSUo7yUb
work page 2025
-
[57]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
Leland McInnes, John Healy, and James Melville. Umap: Uniform manifold approx- imation and projection for dimension reduction.arXiv preprint arXiv:1802.03426, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[58]
Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 2002
work page 2002
-
[59]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[60]
Karl Pearson. Liii. on lines and planes of closest fit to systems of points in space.The London, Edinburgh, and Dublin philosophical magazine and journal of science, 2(11): 559–572, 1901
work page 1901
-
[61]
Analysis of a complex of statistical variables into principal components
Harold Hotelling. Analysis of a complex of statistical variables into principal components. Journal of educational psychology, 24(6):417, 1933
work page 1933
-
[62]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4401–4410, 2019
work page 2019
-
[63]
Adversarial latent autoencoders
Stanislav Pidhorskyi, Donald A Adjeroh, and Gianfranco Doretto. Adversarial latent autoencoders. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14104–14113, 2020
work page 2020
-
[64]
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
work page 2017
-
[65]
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks.Advances in neural information processing systems, 25, 2012. 13
work page 2012
-
[66]
High-Resolution Image Synthesis with Latent Diffusion Models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models, 2022. URLhttps:// arxiv.org/abs/2112.10752
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[67]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000–16009, 2022
work page 2022
-
[68]
Improved techniques for training gans.Advances in neural information processing systems, 29, 2016
Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans.Advances in neural information processing systems, 29, 2016
work page 2016
-
[69]
What Matters in Learning from Offline Human Demonstrations for Robot Manipulation
Ajay Mandlekar, Danfei Xu, Josiah Wong, Soroush Nasiriany, Chen Wang, Rohun Kulkarni, Li Fei-Fei, Silvio Savarese, Yuke Zhu, and Roberto Martín-Martín. What matters in learning from offline human demonstrations for robot manipulation.arXiv preprint arXiv:2108.03298, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[70]
Pete Florence, Corey Lynch, Andy Zeng, Oscar A Ramirez, Ayzaan Wahid, Laura Downs, Adrian Wong, Johnny Lee, Igor Mordatch, and Jonathan Tompson. Implicit behavioral cloning. InConference on robot learning, pages 158–168. PMLR, 2022
work page 2022
-
[71]
Nur Muhammad Shafiullah, Zichen Cui, Ariuntuya Arty Altanzaya, and Lerrel Pinto. Behavior transformers: Cloningk modes with one stone.Advances in neural information processing systems, 35:22955–22968, 2022
work page 2022
-
[72]
Abhishek Gupta, Vikash Kumar, Corey Lynch, Sergey Levine, and Karol Hausman. Relay policy learning: Solving long-horizon tasks via imitation and reinforcement learning.arXiv preprint arXiv:1910.11956, 2019
-
[73]
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
work page 2025
-
[74]
Stochastic interpolants via conditional dependent coupling.arXiv preprint arXiv:2509.23122, 2025
Chenrui Ma, Xi Xiao, Tianyang Wang, Xiao Wang, and Yanning Shen. Stochastic interpolants via conditional dependent coupling.arXiv preprint arXiv:2509.23122, 2025
-
[75]
CAD-VAE: Leveraging correlation-aware latents for comprehensive fair disentanglement
Chenrui Ma, Xi Xiao, Tianyang Wang, Xiao Wang, and Yanning Shen. CAD-VAE: Leveraging correlation-aware latents for comprehensive fair disentanglement. InThe Fortieth AAAI Conference on Artificial Intelligence, 2025
work page 2025
-
[76]
Chenrui Ma, Xi Xiao, Tianyang Wang, and Yanning Shen. Beyond editing pairs: Fine- grained instructional image editing via multi-scale learnable regions.arXiv preprint arXiv:2505.19352, 2025. 14 Appendix Contents A Preliminary 15 A.1 Flow Matching . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15 A.2 Drift Method . . . . . . . . . . ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.