Guard: Scalable Straggler Detection and Node Health Management for Large-Scale Training
Pith reviewed 2026-05-20 01:14 UTC · model grok-4.3
The pith
Guard detects fail-slow nodes missed by standard checks, delivering up to 1.7x better FLOPs utilization in large training clusters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Guard is a scalable system that combines lightweight online performance monitoring during training with an offline node-sweep mechanism to detect both acute failures and long-running fail-slow behaviors that traditional diagnostics cannot capture. Deployed on large-scale foundation model pretraining workloads, it improves mean FLOPs utilization by up to 1.7x, reduces run-to-run training step variance from 20% to 1%, increases mean time to failure, and cuts operational and debugging overhead.
What carries the argument
Lightweight online performance monitoring during training combined with an offline node-sweep mechanism for systematic qualification.
If this is right
- Mean FLOPs utilization rises by up to 1.7x on foundation-model pretraining jobs.
- Run-to-run training step time variance drops from 20% to 1%.
- Mean time to failure for long-running jobs increases.
- Operational and debugging overhead falls substantially.
Where Pith is reading between the lines
- Similar dual online-plus-offline monitoring could apply to other distributed systems that run for weeks or months.
- The approach highlights that maintaining performance consistency across nodes may matter more than maximizing peak speed for overall cluster efficiency.
- Systematic pre-qualification of hardware could reduce the frequency of mid-job interventions in future even larger clusters.
Load-bearing premise
That the online monitoring and offline sweep together can reliably identify fail-slow behaviors missed by conventional tests and that correcting them produces the measured gains in utilization and consistency.
What would settle it
A side-by-side comparison of identical training runs on the same cluster, one with Guard's detected problematic nodes left in place without remediation and one with them excluded or fixed, to check whether the utilization and variance improvements still appear.
Figures





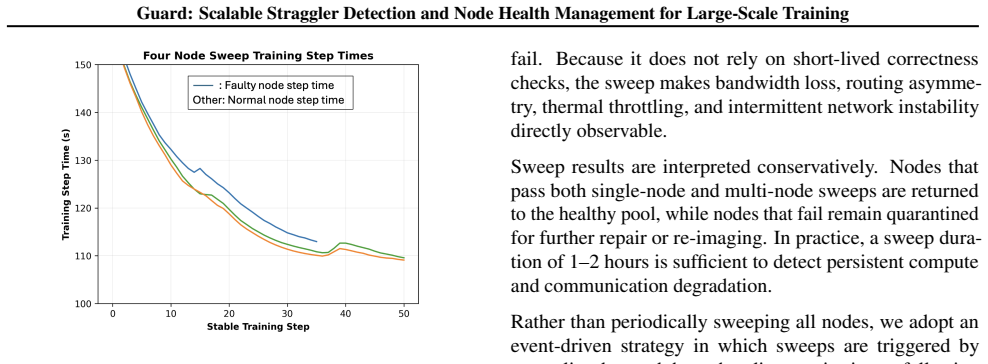



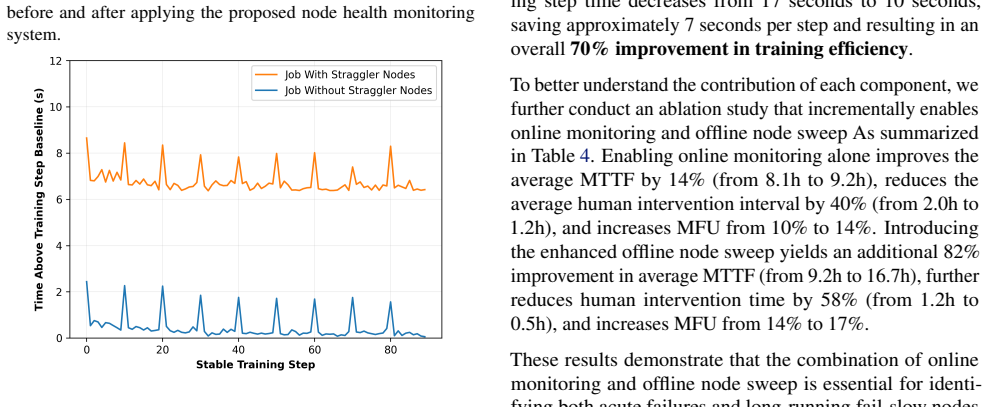
read the original abstract
Training frontier-scale foundation models involves coordinating tens of thousands of GPUs over multi-month runs, where even minor performance degradations can accumulate into substantial efficiency losses. Existing health-check mechanisms, such as NCCL tests or GPU burn-in, primarily focus on functional correctness and often fail to detect fail-slow behaviors that silently degrade system performance. In this paper, we present Guard, a scalable system for detecting stragglers and ensuring node health in large-scale training clusters. Guard combines lightweight online performance monitoring during training with an offline node-sweep mechanism that systematically evaluates and qualifies nodes before they participate in production workloads. This design enables Guard to detect both acute failures and long-running fail-slow behaviors that traditional diagnostics cannot capture. Deployed on large-scale foundation model pretraining workloads, Guard improves mean FLOPs utilization by up to 1.7x, reduces run-to-run training step variance from 20% to 1%, increases mean time to failure (MTTF), and significantly reduces operational and debugging overhead. These results demonstrate that proactive straggler detection and systematic node qualification are critical for maintaining stable and efficient large-scale training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes Guard, a system for detecting stragglers and managing node health in large-scale training clusters. Guard integrates lightweight online performance monitoring during training with an offline node-sweep mechanism to identify acute failures and long-running fail-slow behaviors that traditional diagnostics like NCCL tests cannot capture. Based on deployment in large-scale foundation model pretraining, the paper claims improvements of up to 1.7x in mean FLOPs utilization, reduction of run-to-run training step variance from 20% to 1%, increased mean time to failure, and reduced operational and debugging overhead.
Significance. This work has potential significance for the field of distributed systems and machine learning infrastructure. By addressing fail-slow issues in production environments with tens of thousands of GPUs, it could lead to more efficient use of compute resources in training frontier models. The real-world deployment results provide practical evidence, though the absence of detailed experimental controls limits the ability to fully gauge the novelty and impact.
major comments (2)
- [Abstract] The abstract reports concrete numerical improvements but provides no details on baselines, measurement methodology, statistical significance, or exclusion criteria; the central claims rest on deployment results whose support cannot be fully evaluated from the given text.
- [Evaluation] The presentation of before/after metrics without ablations or quantification of flagged nodes undermines the ability to attribute the 1.7x utilization and variance reductions directly to Guard's detection mechanisms rather than other factors.
minor comments (2)
- The manuscript would benefit from a clearer description of the system architecture, perhaps with a diagram illustrating the online and offline components.
- [Abstract] Consider providing more context on the scale of the training jobs (e.g., number of nodes or GPUs) to help readers appreciate the scalability claims.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review of our manuscript. We appreciate the focus on strengthening the presentation of our deployment results and have addressed each major comment below. Revisions have been made to improve clarity while preserving the integrity of the reported findings from production environments.
read point-by-point responses
-
Referee: [Abstract] The abstract reports concrete numerical improvements but provides no details on baselines, measurement methodology, statistical significance, or exclusion criteria; the central claims rest on deployment results whose support cannot be fully evaluated from the given text.
Authors: We agree that the abstract can be strengthened with additional high-level context. In the revised manuscript, we have updated the abstract to briefly specify the baselines (traditional NCCL tests and GPU burn-in), the measurement approach (lightweight online monitoring combined with offline node sweeps), and the deployment scale (tens of thousands of GPUs over multi-month foundation model pretraining runs). Full details on statistical analysis, variance measurements, and any exclusion criteria for the reported metrics are provided in the Evaluation section; space constraints preclude including them in the abstract itself. revision: yes
-
Referee: [Evaluation] The presentation of before/after metrics without ablations or quantification of flagged nodes undermines the ability to attribute the 1.7x utilization and variance reductions directly to Guard's detection mechanisms rather than other factors.
Authors: We acknowledge the importance of clearer attribution. The original manuscript reports before/after metrics from production deployments in which Guard was enabled while holding other cluster configuration and workload parameters as constant as possible. In the revised version, we have added quantification of nodes flagged by Guard (both acute failures and fail-slow cases) along with their measured impact on step-time variance and FLOPs utilization. We also include a discussion of why exhaustive ablations are operationally difficult in live multi-month training runs and provide supporting evidence from offline node-sweep experiments that isolate Guard's detection components. These changes directly address the attribution concern. revision: partial
Circularity Check
No circularity: engineering system description with externally grounded deployment claims
full rationale
The paper describes a practical system (Guard) for straggler detection and node health management, combining online monitoring and offline sweeps. Its central claims rest on reported deployment outcomes—1.7x FLOPs utilization gains, variance reduction from 20% to 1%, and higher MTTF—rather than any mathematical derivation, equations, fitted parameters, or predictions that reduce to inputs by construction. No self-definitional steps, fitted-input predictions, load-bearing self-citations, uniqueness theorems, or smuggled ansatzes appear in the derivation chain. The results are presented as empirical measurements from production workloads, making the account self-contained against external benchmarks without circular reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Traditional health-check mechanisms such as NCCL tests or GPU burn-in primarily focus on functional correctness and fail to detect fail-slow behaviors.
invented entities (1)
-
Guard system
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Guard combines lightweight online performance monitoring during training with an offline node-sweep mechanism that systematically evaluates and qualifies nodes before they participate in production workloads.
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
reduces run-to-run training step variance from 20% to 1%
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Chowdhery, A. et al. PaLM: Scaling language modeling with pathways.arXiv preprint arXiv:2204.02311,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Dubey, A. et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
Fedus, W., Zoph, B., and Shazeer, N. Switch transform- ers: Scaling to trillion parameter models with simple and efficient sparsity.arXiv preprint arXiv:2101.03961,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Hu, H., Jiang, C., Zhong, Y ., Peng, Y ., Wu, C., Zhu, Y ., Lin, H., and Guo, C. dpro: A generic profiling and optimiza- tion system for expediting distributed dnn training.arXiv preprint arXiv:2205.02473,
-
[6]
Le Scao, T. et al. BLOOM: A 176b-parameter open- access multilingual language model.arXiv preprint arXiv:2211.05100,
work page internal anchor Pith review Pith/arXiv arXiv
- [7]
-
[8]
Liu, A. et al. Deepseek-V3 technical report.arXiv preprint arXiv:2412.19437,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Shazeer, N. et al. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Shoeybi, M., Patwary, M., Puri, R., et al. Megatron-LM: Training multi-billion parameter language models using model parallelism.arXiv preprint arXiv:1909.08053,
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[11]
Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts
Wang1, L., Gao, H., Zhao1, C., Sun, X., and Dai, D. Auxiliary-loss-free load balancing strategy for mixture- of-experts.arXiv preprint arXiv:2408.15664,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Zhou, Y . et al. Towards practical monitoring for large-scale deep learning clusters. InMLSys, 2023
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.