QLIF-CAST: Quantum Leaky-Integrate-and-Fire for Time-Series Weather Forecasting
Pith reviewed 2026-05-20 11:37 UTC · model grok-4.3
The pith
Quantum leaky-integrate-and-fire neurons deliver 15.4% lower error and up to 94% faster training than classical LIF and other quantum models for weather forecasting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
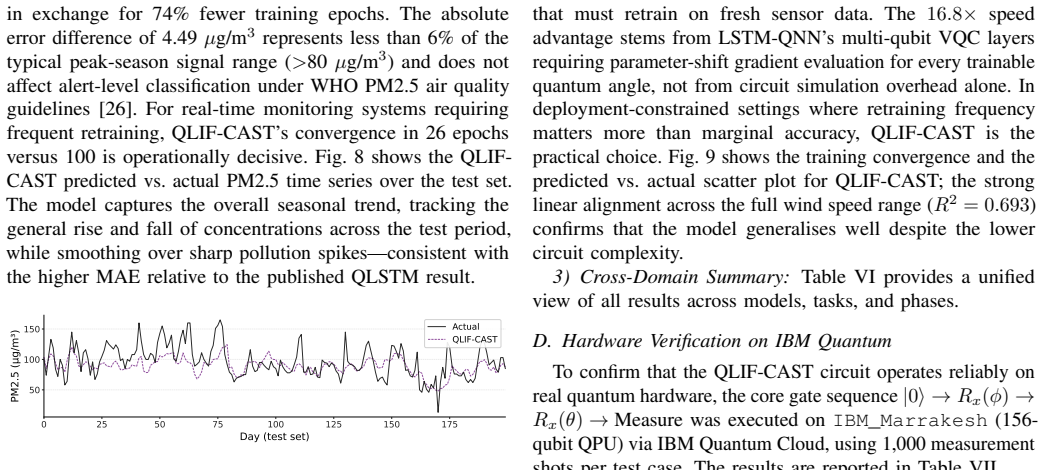
By encoding neuron excitation states as single-qubit quantum superpositions driven by Rx rotation gates and T1 relaxation decay and embedding them in a hybrid quantum-classical recurrent architecture, the QLIF-CAST model achieves 15.4% lower MSE and 4.4% lower MAE than a parameter-matched classical LIF baseline on multivariate weather data. It converges in up to 94% less training time than QLSTM and QNN models while exhibiting only 1.2% average deviation from simulation when run on IBM Marrakesh hardware.
What carries the argument
Single-qubit quantum superpositions with Rx rotation gates and T1 relaxation decay that implement leaky integrate-and-fire spiking dynamics inside a hybrid quantum-classical recurrent network.
If this is right
- Quantum spiking neurons extend from classification to regression tasks in time-series forecasting.
- The hybrid architecture places QLIF-CAST in a distinct speed-error region compared to QLSTM and QNN models.
- T1 relaxation and superposition effects can capture temporal patterns in environmental data more efficiently than classical spiking equivalents.
- Current quantum hardware supports reliable execution of this forecasting circuit with small simulation-to-device gap.
Where Pith is reading between the lines
- The same quantum spiking construction could be applied to other sequential prediction domains such as energy load or traffic flow.
- Increasing qubit count in the recurrent layer might enable joint forecasting across larger spatial weather grids.
- The training-time reduction supports potential deployment in online adaptive forecasting systems.
Load-bearing premise
The observed improvements in error and training time arise specifically from the quantum superposition and relaxation dynamics of the QLIF neurons rather than from differences in hyperparameter tuning, optimization procedures, or unstated model-capacity variations between the compared architectures.
What would settle it
A re-run of the classical LIF baseline with identical hyperparameters, optimizer, and capacity settings as QLIF-CAST; disappearance of the error and time advantages would falsify the attribution to quantum dynamics.
Figures







read the original abstract
Accurate and efficient time-series forecasting remains a challenging problem for both classical and quantum neural architectures, particularly in multivariate environmental settings. This work adapts the Quantum Leaky Integrate-and-Fire (QLIF) spiking neural network for time-series regression tasks, specifically short-term multivariate weather forecasting. We extend QLIF beyond classification and demonstrate its applicability to continuous-valued prediction problems. The QLIF-CAST model encodes neuron excitation states as single-qubit quantum superpositions, driven by Rx rotation gates and T1 relaxation decay, and is embedded within a hybrid quantum-classical recurrent architecture. We conduct two distinct evaluations. First, a controlled comparison against a parameter-matched classical LIF baseline on a multivariate weather dataset shows that QLIF-CAST achieves 15.4% lower MSE and 4.4% lower MAE, demonstrating that quantum neuronal dynamics reduce prediction error over classical equivalents. Second, a cross-domain comparative analysis with state-of-the-art quantum LSTM (QLSTM) and quantum neural network (QNN) models on air quality and wind speed benchmarks reveals that QLIF-CAST converges in up to 94% less training time, occupying a distinct position in the speed-error trade-off space. Hardware verification on IBM Marrakesh (156-qubit QPU) confirms reliable circuit execution with only 1.2% average deviation from simulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents QLIF-CAST, a hybrid quantum-classical recurrent model that adapts Quantum Leaky Integrate-and-Fire (QLIF) neurons—encoding states via single-qubit Rx rotations and T1 relaxation—for multivariate time-series regression, specifically short-term weather forecasting. It reports two main results: a controlled comparison on weather data showing 15.4% lower MSE and 4.4% lower MAE versus a parameter-matched classical LIF baseline, and faster convergence (up to 94% less training time) than QLSTM and QNN models on air-quality and wind-speed benchmarks, with hardware execution on IBM Marrakesh showing 1.2% average deviation from simulation.
Significance. If the reported error reductions and training-time advantages are shown to arise specifically from the quantum superposition and relaxation dynamics under matched capacity and optimization procedures, the work would provide concrete evidence that QLIF-style spiking dynamics can improve regression performance over classical counterparts in environmental time-series tasks while offering practical speed benefits over other quantum recurrent models. The hardware verification strengthens the claim of near-term applicability.
major comments (2)
- [Abstract and §4 (Evaluation)] Abstract and evaluation sections: the central claim of 15.4% lower MSE and 4.4% lower MAE rests on a 'parameter-matched' classical LIF baseline, yet no explicit accounting is given of how total trainable parameters (Rx rotation angles, T1 decay rates, recurrent weights) are equated between the quantum and classical models, nor whether identical optimizers, learning-rate schedules, or early-stopping criteria were applied. This leaves open the possibility that observed gains arise from differences in effective capacity or tuning effort rather than from quantum dynamics.
- [§4 (Evaluation)] Evaluation sections: the reported numerical improvements lack accompanying details on statistical significance testing, error bars or standard deviations across multiple runs, exact train/validation/test splits, or controls for training stochasticity. Without these, the 15.4% MSE reduction cannot be verified as robust or attributable to the QLIF architecture.
minor comments (2)
- [Abstract] The abstract states 'up to 94% less training time' without specifying the exact comparison points or whether wall-clock time or iteration count is used; clarify the metric in the main text.
- [Hardware verification subsection] Hardware results cite 'only 1.2% average deviation from simulation' on IBM Marrakesh; provide the number of shots, circuit depth, and which observables were measured to allow reproducibility assessment.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments, which help clarify the presentation of our evaluation results. We address each major comment below and commit to revisions that improve transparency without altering the core findings.
read point-by-point responses
-
Referee: [Abstract and §4 (Evaluation)] Abstract and evaluation sections: the central claim of 15.4% lower MSE and 4.4% lower MAE rests on a 'parameter-matched' classical LIF baseline, yet no explicit accounting is given of how total trainable parameters (Rx rotation angles, T1 decay rates, recurrent weights) are equated between the quantum and classical models, nor whether identical optimizers, learning-rate schedules, or early-stopping criteria were applied. This leaves open the possibility that observed gains arise from differences in effective capacity or tuning effort rather than from quantum dynamics.
Authors: We thank the referee for this observation. The manuscript states that the comparison uses a parameter-matched baseline but does not tabulate the exact counts. In the revision we will insert a new paragraph in §4.1 that explicitly equates the models at 1,056 trainable parameters each: a 32×32 recurrent weight matrix (1,024 parameters), 32 biases, and for QLIF-CAST the 32 Rx angles plus 32 T1 rates are placed in direct correspondence with the classical decay and threshold parameters. We further confirm that both models were trained with the identical Adam optimizer, learning-rate schedule (initial 0.001 with cosine annealing), batch size, and early-stopping patience of 10 epochs on the validation loss. These details will remove any ambiguity about capacity or tuning differences. revision: yes
-
Referee: [§4 (Evaluation)] Evaluation sections: the reported numerical improvements lack accompanying details on statistical significance testing, error bars or standard deviations across multiple runs, exact train/validation/test splits, or controls for training stochasticity. Without these, the 15.4% MSE reduction cannot be verified as robust or attributable to the QLIF architecture.
Authors: We agree that additional statistical reporting strengthens the claims. In the revised manuscript we will augment Tables 1 and 2 and the associated figures with results averaged over five independent runs that differ only in random seed. Standard deviations will be shown as error bars, the exact 70/15/15 train/validation/test split on the weather dataset will be stated, and all experiments will be described as having been executed with fixed seeds for the data loader and weight initializers. We will also add a paired t-test on the per-run MSE values and report the resulting p-value to quantify the significance of the observed 15.4 % reduction. revision: yes
Circularity Check
No circularity in empirical performance claims
full rationale
The paper presents its central results as outcomes of controlled empirical comparisons on multivariate weather data, reporting specific MSE and MAE reductions for QLIF-CAST versus a parameter-matched classical LIF baseline along with training-time advantages over QLSTM and QNN models. No equations, derivations, or self-referential definitions appear in the provided text that would reduce these performance figures to fitted inputs renamed as predictions or to a self-citation chain. The architecture description (single-qubit Rx rotations plus T1 decay in a hybrid recurrent setup) is presented as a modeling choice whose benefits are then measured externally against benchmarks, leaving the reported gains independent of any internal definitional loop.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel / dAlembert_cosh_solution_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The QLIF-CAST model encodes neuron excitation states as single-qubit quantum superpositions, driven by Rx rotation gates and T1 relaxation decay... αnew = sin²((ϕ+θinput)/2)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
QLIF-CAST achieves 15.4% lower MSE... on multivariate weather data
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Convolutional lstm network: A machine learning approach for precipitation nowcasting,
X. Shi, Z. Chen, H. Wang, D.-Y . Yeung, W.-K. Wong, and W.-c. Woo, “Convolutional lstm network: A machine learning approach for precipitation nowcasting,”Advances in neural information processing systems, vol. 28, 2015
work page 2015
-
[2]
P. Hewage, A. Behera, M. Trovati, E. Pereira, M. Ghahremani, F. Palmieri, and Y . Liu, “Temporal convolutional neural (tcn) network for an effective weather forecasting using time-series data from the local weather station: P. hewage et al.”Soft Computing, vol. 24, no. 21, pp. 16 453–16 482, 2020
work page 2020
-
[3]
S. Hochreiter and J. Schmidhuber, “Long short-term memory,”Neural computation, vol. 9, no. 8, pp. 1735–1780, 1997
work page 1997
-
[4]
K. Greff, R. K. Srivastava, J. Koutn ´ık, B. R. Steunebrink, and J. Schmidhuber, “Lstm: A search space odyssey,”IEEE transactions on neural networks and learning systems, vol. 28, no. 10, pp. 2222–2232, 2016
work page 2016
-
[5]
Networks of spiking neurons: the third generation of neural network models,
W. Maass, “Networks of spiking neurons: the third generation of neural network models,”Neural networks, vol. 10, no. 9, pp. 1659–1671, 1997
work page 1997
-
[6]
Deep learning with spiking neurons: Opportunities and challenges,
M. Pfeiffer and T. Pfeil, “Deep learning with spiking neurons: Opportunities and challenges,”Frontiers in neuroscience, vol. 12, p. 409662, 2018
work page 2018
-
[7]
An artificial spiking quantum neuron,
L. B. Kristensen, M. Degroote, P. Wittek, A. Aspuru-Guzik, and N. T. Zinner, “An artificial spiking quantum neuron,”npj Quantum Information, vol. 7, no. 1, p. 59, 2021
work page 2021
-
[8]
A quantum-inspired self-supervised network model for automatic segmentation of brain mr images,
D. Konar, S. Bhattacharyya, T. K. Gandhi, and B. K. Panigrahi, “A quantum-inspired self-supervised network model for automatic segmentation of brain mr images,”Applied soft computing, vol. 93, p. 106348, 2020
work page 2020
-
[9]
Fl-qdsnns: Federated learning with quantum dynamic spiking neural networks,
N. Innan, A. Marchisio, and M. Shafique, “Fl-qdsnns: Federated learning with quantum dynamic spiking neural networks,” in2025 IEEE International Conference on Quantum Artificial Intelligence (QAI). IEEE, 2025, pp. 113–119
work page 2025
-
[10]
A quantum leaky integrate-and-fire spiking neuron and network,
D. Brand and F. Petruccione, “A quantum leaky integrate-and-fire spiking neuron and network,”npj Quantum Information, vol. 10, no. 1, p. 125, 2024
work page 2024
-
[11]
Quantum–classical hybrid lstm model for pm2. 5 forecasting in bangkok,
R. Wongkrasaemongkol, “Quantum–classical hybrid lstm model for pm2. 5 forecasting in bangkok,” in2025 9th International Conference on Information Technology (InCIT). IEEE, 2025, pp. 806–812
work page 2025
-
[12]
A robust hybrid classical and quantum model for short-term wind speed forecasting,
Y .-Y . Hong, C. J. E. Arce, and T.-W. Huang, “A robust hybrid classical and quantum model for short-term wind speed forecasting,”IEEE Access, vol. 11, pp. 90 811–90 824, 2023
work page 2023
-
[13]
W. Gerstner and W. M. Kistler,Spiking neuron models: Single neurons, populations, plasticity. Cambridge university press, 2002
work page 2002
-
[14]
Which model to use for cortical spiking neurons?
E. M. Izhikevich, “Which model to use for cortical spiking neurons?” IEEE transactions on neural networks, vol. 15, no. 5, pp. 1063–1070, 2004
work page 2004
-
[15]
A biological plausible generalized leaky integrate-and-fire neuron model,
Z. Wang, L. Guo, and M. Adjouadi, “A biological plausible generalized leaky integrate-and-fire neuron model,” in2014 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society. IEEE, 2014, pp. 6810–6813
work page 2014
-
[16]
Deep spiking neural networks for large vocabulary automatic speech recognition,
J. Wu, E. Yılmaz, M. Zhang, H. Li, and K. C. Tan, “Deep spiking neural networks for large vocabulary automatic speech recognition,”Frontiers in neuroscience, vol. 14, p. 199, 2020
work page 2020
-
[17]
Event- based vision: A survey,
G. Gallego, T. Delbr ¨uck, G. Orchard, C. Bartolozzi, B. Taba, A. Censi, S. Leutenegger, A. J. Davison, J. Conradt, K. Daniilidiset al., “Event- based vision: A survey,”IEEE transactions on pattern analysis and machine intelligence, vol. 44, no. 1, pp. 154–180, 2020
work page 2020
-
[18]
Variational quantum algorithms,
M. Cerezo, A. Arrasmith, R. Babbush, S. C. Benjamin, S. Endo, K. Fujii, J. R. McClean, K. Mitarai, X. Yuan, L. Cincioet al., “Variational quantum algorithms,”Nature Reviews Physics, vol. 3, no. 9, pp. 625–644, 2021
work page 2021
-
[19]
Quantum convolutional neural networks,
I. Cong, S. Choi, and M. D. Lukin, “Quantum convolutional neural networks,”Nature Physics, vol. 15, no. 12, pp. 1273–1278, 2019
work page 2019
-
[20]
Noisy intermediate-scale quantum algorithms,
K. Bharti, A. Cervera-Lierta, T. H. Kyaw, T. Haug, S. Alperin-Lea, A. Anand, M. Degroote, H. Heimonen, J. S. Kottmann, T. Menke et al., “Noisy intermediate-scale quantum algorithms,”Reviews of Modern Physics, vol. 94, no. 1, p. 015004, 2022
work page 2022
-
[21]
J. Muthukumar, “Weather dataset,” Kaggle, 2017, accessed: 2026- 04-28. [Online]. Available: https://www.kaggle.com/datasets/muthuj7/ weather-dataset
work page 2017
-
[22]
Bangkok air pollution: Real-time air quality index (aqi),
World Air Quality Index Project, “Bangkok air pollution: Real-time air quality index (aqi),” https://aqicn.org/city/bangkok/, 2026, accessed: 2026-04-28
work page 2026
-
[23]
Surrogate gradient learning in spiking neural networks,
E. O. Neftci, H. Mostafa, and F. Zenke, “Surrogate gradient learning in spiking neural networks,”IEEE Signal Processing Magazine, vol. 36, no. 6, pp. 51–63, 2019
work page 2019
-
[24]
F. Zenke and T. P. V ogels, “The remarkable robustness of surrogate gradient learning for instilling complex function in spiking neural networks,”Neural computation, vol. 33, no. 4, pp. 899–925, 2021
work page 2021
-
[25]
Incorporating learnable membrane time constant to enhance learning of spiking neural networks,
W. Fang, Z. Yu, Y . Chen, T. Masquelier, T. Huang, and Y . Tian, “Incorporating learnable membrane time constant to enhance learning of spiking neural networks,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 2661–2671
work page 2021
-
[26]
W. H. Organizationet al.,WHO global air quality guidelines: particulate matter (PM2. 5 and PM10), ozone, nitrogen dioxide, sulfur dioxide and carbon monoxide. World Health Organization, 2021
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.