Stochastic Penalty-Barrier Methods for Constrained Machine Learning
Pith reviewed 2026-05-20 12:16 UTC · model grok-4.3
The pith
Stochastic Penalty-Barrier Method extends classical penalty techniques to non-convex stochastic optimization in deep learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
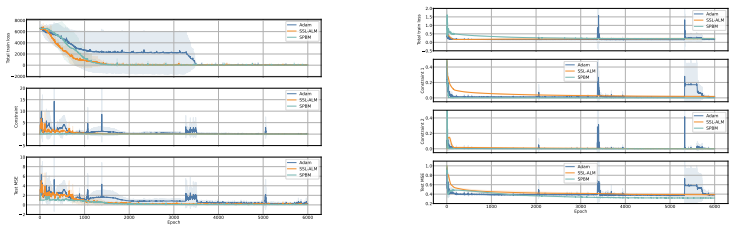
We propose the Stochastic Penalty-Barrier Method (SPBM), which extends classical penalty and barrier methods to this setting via exponential dual averaging, a stabilized penalty schedule, and the Moreau envelope to handle non-smoothness. Experiments across multiple settings show that SPBM matches or outperforms existing constrained optimization baselines while incurring only linear runtime overhead compared to unconstrained Adam for up to 10,000 constraints.
What carries the argument
Exponential dual averaging paired with a stabilized penalty schedule and the Moreau envelope, which together approximate the constrained problem inside a stochastic first-order loop.
If this is right
- Fairness constraints can be enforced during training of large models without replacing the underlying optimizer.
- Physics-informed losses and symbolic rules become practical to add to existing neural-network pipelines.
- The approach scales to thousands of simultaneous constraints while preserving the per-iteration cost of standard stochastic gradient methods.
- Domain knowledge expressed as inequality or equality constraints can be incorporated directly into statistical learning without custom projection steps.
Where Pith is reading between the lines
- SPBM could be paired with other first-order methods such as momentum or adaptive variants beyond the tested Adam baseline.
- The linear overhead pattern suggests the method may remain practical when the number of constraints reaches tens or hundreds of thousands in very large models.
- Similar penalty-barrier constructions might transfer to constrained reinforcement learning or online decision problems that share the same non-convex stochastic character.
- Theoretical analysis of convergence rates under the paper's assumptions would be a natural next step to quantify the observed empirical stability.
Load-bearing premise
The specific mix of exponential dual averaging, stabilized penalty schedule, and Moreau envelope yields stable convergence in non-convex non-smooth stochastic regimes without introducing new instabilities.
What would settle it
A controlled experiment on a standard constrained deep-learning benchmark that shows SPBM diverging, violating constraints more than baselines, or incurring super-linear overhead would falsify the central performance claim.
Figures





read the original abstract
Constrained machine learning enables fairness-aware training, physics-informed neural networks, and integration of symbolic domain knowledge into statistical models. Despite its practical importance, no general method exists for the non-convex, non-smooth, stochastic setting that arises naturally in deep learning. We propose the Stochastic Penalty-Barrier Method (SPBM), which extends classical penalty and barrier methods to this setting via exponential dual averaging, a stabilized penalty schedule, and the Moreau envelope to handle non-smoothness. Experiments across multiple settings show that SPBM matches or outperforms existing constrained optimization baselines while incurring only linear runtime overhead compared to unconstrained Adam for up to 10,000 constraints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Stochastic Penalty-Barrier Method (SPBM) for constrained optimization in the non-convex, non-smooth, stochastic regime of deep learning. It extends classical penalty and barrier methods through exponential dual averaging for dual updates, a stabilized penalty schedule, and the Moreau envelope to accommodate non-smooth constraints. The central claim, supported by experiments across multiple settings, is that SPBM matches or outperforms existing constrained optimization baselines while incurring only linear runtime overhead relative to unconstrained Adam, even for up to 10,000 constraints.
Significance. If the experimental results and stability claims hold under scrutiny, the work would address an important practical gap in constrained machine learning, enabling applications such as fairness-aware training and physics-informed neural networks at scale. The linear-overhead property relative to Adam would be a notable strength for adoption in large-scale stochastic settings, provided the method's components are shown to interact reliably without hidden instabilities.
major comments (2)
- [Experimental Evaluation] Experimental claims (abstract and results section): the assertion that SPBM matches or outperforms baselines with linear overhead provides no details on the specific baselines, datasets, number of independent runs, statistical significance tests, or practical handling of non-smoothness. This information is load-bearing for verifying the superiority and scalability claims.
- [Method Description] Method and analysis (sections describing exponential dual averaging and penalty schedule): the stability of the combined dynamics under stochastic gradients in the non-convex regime is not established. Exponential dual averaging performs multiplicative updates that can amplify gradient noise; no bounds, convergence diagnostics, or ablation results demonstrate that the stabilized schedule and Moreau envelope keep dual variables and constraint violations bounded for the batch sizes and constraint counts used in the experiments.
minor comments (2)
- Notation for the Moreau envelope and penalty schedule parameters should be introduced with explicit definitions and default values to aid reproducibility.
- [Abstract] The abstract refers to 'multiple settings' without enumeration; the full experimental section should list them explicitly with constraint counts and problem types.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. The comments highlight important areas for improving clarity and rigor. We address each major comment below and will incorporate revisions to strengthen the experimental reporting and provide additional empirical diagnostics on stability.
read point-by-point responses
-
Referee: [Experimental Evaluation] Experimental claims (abstract and results section): the assertion that SPBM matches or outperforms baselines with linear overhead provides no details on the specific baselines, datasets, number of independent runs, statistical significance tests, or practical handling of non-smoothness. This information is load-bearing for verifying the superiority and scalability claims.
Authors: We agree that additional details are required for full reproducibility and verification. In the revised manuscript we will expand the experimental setup subsection to explicitly list the baselines (including Lagrangian relaxation, projected stochastic gradient methods, and other penalty-based approaches referenced in the related work), the specific datasets and tasks for each experiment, the number of independent runs (five runs with distinct random seeds, reporting mean and standard deviation), and the statistical comparisons performed. We will also add a dedicated paragraph on the practical implementation of non-smooth constraints via the Moreau envelope, including the choice of smoothing radius and its effect on gradient computation. Runtime measurements confirming linear overhead will be presented in a new table. revision: yes
-
Referee: [Method Description] Method and analysis (sections describing exponential dual averaging and penalty schedule): the stability of the combined dynamics under stochastic gradients in the non-convex regime is not established. Exponential dual averaging performs multiplicative updates that can amplify gradient noise; no bounds, convergence diagnostics, or ablation results demonstrate that the stabilized schedule and Moreau envelope keep dual variables and constraint violations bounded for the batch sizes and constraint counts used in the experiments.
Authors: We recognize that a complete theoretical stability analysis for the non-convex stochastic setting is not provided and would be difficult to obtain given the current state of the literature. However, the design choices (stabilized penalty schedule that gradually increases the penalty coefficient and the Moreau envelope for local smoothing) are intended to mitigate noise amplification. In the revision we will add empirical diagnostics: time-series plots of dual-variable norms and maximum constraint violation across training for the highest constraint counts (10,000) and the batch sizes used. We will also include ablation results on the penalty schedule parameters to demonstrate that violations remain bounded in practice. These additions will be placed in a new subsection on empirical stability. revision: partial
Circularity Check
No circularity: derivation relies on independent algorithmic extensions and empirical validation
full rationale
The paper presents SPBM as a direct extension of classical penalty-barrier methods by introducing exponential dual averaging, a stabilized penalty schedule, and the Moreau envelope to address non-convex, non-smooth, stochastic regimes. No equations reduce claimed performance metrics, convergence behavior, or constraint satisfaction to quantities fitted from the reported experiments, nor does any load-bearing step rest on self-citations whose content is itself defined by the present work. Experimental comparisons to baselines are external to the derivation and do not create a self-referential loop. The central claims therefore remain independent of the inputs they are evaluated against.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions on bounded variance and smoothness for stochastic non-convex optimization hold sufficiently for the method to converge
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SPBM extends classical penalty and barrier methods ... via exponential dual averaging, a stabilized penalty schedule, and the Moreau envelope
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Position: Adopt Constraints Over Penalties in Deep Learning, July 2025.Cited on page 1
Juan Ramirez, Meraj Hashemizadeh, and Simon Lacoste-Julien. Position: Adopt Constraints Over Penalties in Deep Learning, July 2025.Cited on page 1
work page 2025
-
[2]
Zhu Li, Adrián Pérez-Suay, Gustau Camps-Valls, and Dino Sejdinovic. Kernel dependence reg- ularizers and Gaussian processes with applications to algorithmic fairness.Pattern Recognition, 132:108922, December 2022. ISSN 0031-3203. doi: 10.1016/j.patcog.2022.108922.Cited on page 1
-
[3]
fairret: a framework for differentiable fairness regularization terms
Maarten Buyl, Marybeth Defrance, and Tijl De Bie. fairret: a framework for differentiable fairness regularization terms. InInternational Conference on Learning Representations, 2024. Cited on page 1
work page 2024
-
[4]
Andrii Kliachkin, Jana Lepšová, Gilles Bareilles, and Jakub Marecek. Benchmarking stochastic approximation algorithms for fairness-constrained training of deep neural networks. InThe Fourteenth International Conference on Learning Representations, 2026. URL https:// openreview.net/forum?id=JxmjzC6syB.Cited on pages 1, 5, and 25
work page 2026
-
[5]
Lu Lu, Raphael Pestourie, Wenjie Yao, Zhicheng Wang, Francesc Verdugo, and Steven G Johnson. Physics-informed neural networks with hard constraints for inverse design.SIAM Journal on Scientific Computing, 43(6):B1105–B1132, 2021.Cited on page 1
work page 2021
-
[6]
Aditi Krishnapriyan, Amir Gholami, Shandian Zhe, Robert Kirby, and Michael W Mahoney. Characterizing possible failure modes in physics-informed neural networks.Advances in neural information processing systems, 34:26548–26560, 2021.Cited on page 1
work page 2021
-
[7]
Sifan Wang, Shyam Sankaran, and Paris Perdikaris. Respecting causality for training physics- informed neural networks.Computer Methods in Applied Mechanics and Engineering, 421: 116813, 2024.Cited on page 1
work page 2024
-
[8]
Hwijae Son, Sung Woong Cho, and Hyung Ju Hwang. Enhanced physics-informed neural networks with augmented lagrangian relaxation method (al-pinns).Neurocomputing, 548: 126424, 2023.Cited on pages 1, 6, 7, and 15
work page 2023
-
[9]
Yongcun Song, Xiaoming Yuan, and Hangrui Yue. The admm-pinns algorithmic framework for nonsmooth pde-constrained optimization: a deep learning approach.SIAM Journal on Scientific Computing, 46(6):C659–C687, 2024.Cited on page 1
work page 2024
-
[10]
Frank E Curtis, Xin Jiang, and Qi Wang. A single-loop stochastic feasible interior-point algorithm for nonlinear inequality-constrained optimization: F. curtis et al.Mathematical Programming, pages 1–38, 2026.Cited on pages 1 and 3
work page 2026
-
[11]
Yuchen Fang, Jihun Kim, Sen Na, James Demmel, and Javad Lavaei. A trust-region interior- point stochastic sequential quadratic programming method.arXiv preprint arXiv:2603.10230, 2026.Cited on pages 1 and 3
-
[12]
Frank E Curtis, Vyacheslav Kungurtsev, Daniel P Robinson, and Qi Wang. A stochastic- gradient-based interior-point algorithm for solving smooth bound-constrained optimization problems.SIAM Journal on Optimization, 35(2):1030–1059, 2025.Cited on pages 1 and 3
work page 2025
-
[13]
Ion Necoara and Angelia Nedi´c. Minibatch stochastic subgradient-based projection algorithms for feasibility problems with convex inequalities.Computational Optimization and Applications, 80(1):121–152, 2021.Cited on pages 1 and 2
work page 2021
-
[14]
Ion Necoara and Nitesh Kumar Singh. Stochastic subgradient for composite convex optimization with functional constraints.Journal of Machine Learning Research, 23(265):1–35, 2022.Cited on pages 1 and 2. 10
work page 2022
-
[15]
Nitesh Kumar Singh, Ion Necoara, and Vyacheslav Kungurtsev. Mini-batch stochastic subgra- dient for functional constrained optimization.Optimization, 73(7):2159–2185, 2024.Cited on pages 1 and 2
work page 2024
-
[16]
Nitesh Kumar Singh and Ion Necoara. Stochastic halfspace approximation method for convex optimization with nonsmooth functional constraints.IEEE Transactions on Automatic Control, 2024.Cited on pages 1 and 2
work page 2024
-
[17]
Digvijay Boob, Qi Deng, and Guanghui Lan. Stochastic first-order methods for convex and nonconvex functional constrained optimization.Mathematical Programming, 197(1):215–279, 2023.Cited on pages 1 and 2
work page 2023
-
[18]
Yankun Huang and Qihang Lin. Oracle complexity of single-loop switching subgradient methods for non-smooth weakly convex functional constrained optimization. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neu- ral Information Processing Systems, volume 36, pages 61327–61340. Curran Associates, Inc., 2023. URL h...
work page 2023
-
[19]
Ruichuan Huang, Jiawei Zhang, and Ahmet Alacaoglu. Stochastic smoothed primal-dual algorithms for nonconvex optimization with linear inequality constraints. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors,Proceedings of the 42nd International Conference on Machine Learn...
work page 2025
-
[20]
Aharon Ben-Tal and Michael Zibulevsky. Penalty/barrier multiplier methods for convex pro- gramming problems.SIAM Journal on Optimization, 7(2):347–366, 1997.Cited on pages 2, 3, and 4
work page 1997
-
[21]
Neal Parikh, Stephen Boyd, et al. Proximal algorithms.Foundations and trends® in Optimiza- tion, 1(3):127–239, 2014.Cited on pages 2 and 4
work page 2014
-
[22]
Convex analysis.Princeton Mathematical Series, 28, 1970.Cited on page 2
R Rockafellar. Convex analysis.Princeton Mathematical Series, 28, 1970.Cited on page 2
work page 1970
-
[23]
Learning multiple layers of features from tiny images.(2009), 2009.Cited on pages 2 and 6
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images.(2009), 2009.Cited on pages 2 and 6
work page 2009
-
[24]
Frances Ding, Moritz Hardt, John Miller, and Ludwig Schmidt. Retiring adult: New datasets for fair machine learning.Advances in Neural Information Processing Systems, 34, 2021.Cited on pages 2, 5, and 25
work page 2021
-
[25]
12 2001.Cited on pages 2, 5, and 25
Paul Van der Laan.The 2001 Census in the Netherlands: Integration of Registers and Surveys, pages 39–52. 12 2001.Cited on pages 2, 5, and 25
work page 2001
-
[26]
Albert S. Berahas, Frank E. Curtis, Michael J. O’Neill, and Daniel P. Robinson. A stochastic sequential quadratic optimization algorithm for nonlinear equality constrained optimization with rank-deficient jacobians, 2023. URL https://arxiv.org/abs/2106.13015.Cited on page 3
-
[27]
Frank E. Curtis, Michael J. O’Neill, and Daniel P. Robinson. Worst-case complexity of an sqp method for nonlinear equality constrained stochastic optimization.Mathematical Programming, 205(1):431–483, May 2024. ISSN 1436-4646. doi: 10.1007/s10107-023-01981-1. URL https://doi.org/10.1007/s10107-023-01981-1.Cited on page 3
-
[28]
Yuchen Fang, Sen Na, Michael W. Mahoney, and Mladen Kolar. Fully stochastic trust-region sequential quadratic programming for equality-constrained optimization problems.SIAM Journal on Optimization, 34(2):2007–2037, 2024. doi: 10.1137/22M1537862. URL https: //doi.org/10.1137/22M1537862.Cited on page 3. 11
-
[29]
Sen Na, Mihai Anitescu, and Mladen Kolar. An adaptive stochastic sequential quadratic programming with differentiable exact augmented lagrangians.Mathematical Programming, 199(1):721–791, May 2023. doi: 10.1007/s10107-022-01846-z. URL https://doi.org/10. 1007/s10107-022-01846-z.Cited on page 3
-
[30]
Francisco Facchinei and Vyacheslav Kungurtsev. Stochastic approximation for expectation objective and expectation inequality-constrained nonconvex optimization, 2023. URL https: //arxiv.org/abs/2307.02943.Cited on pages 3 and 5
-
[31]
Runchao Ma, Qihang Lin, and Tianbao Yang. Quadratically regularized subgradient methods for weakly convex optimization with weakly convex constraints. InInternational Conference on Machine Learning, pages 6554–6564. PMLR, 2020.Cited on page 3
work page 2020
-
[32]
Frank E. Curtis, Daniel P. Robinson, and Baoyu Zhou. Sequential quadratic optimization for stochastic optimization with deterministic nonlinear inequality and equality constraints. SIAM Journal on Optimization, 34(4):3592–3622, 2024. doi: 10.1137/23M1556149. URL https://doi.org/10.1137/23M1556149.Cited on page 3
-
[33]
Qiankun Shi, Xiao Wang, and Hao Wang. A momentum-based linearized augmented lagrangian method for nonconvex constrained stochastic optimization.Optimization Online, 2022. URL https://optimization-online.org/?p=19870.Cited on page 3
work page 2022
-
[34]
Sen Na, Mihai Anitescu, and Mladen Kolar. Inequality constrained stochastic nonlinear optimization via active-set sequential quadratic programming, 2023. URL https://arxiv. org/abs/2109.11502.Cited on page 3
-
[35]
Figen Oztoprak, Richard Byrd, and Jorge Nocedal. Constrained optimization in the presence of noise.SIAM Journal on Optimization, 33(3):2118–2136, 2023. doi: 10.1137/21M1450999. URLhttps://doi.org/10.1137/21M1450999.Cited on page 3
-
[36]
Raghu Bollapragada, Cem Karamanli, Brendan Keith, Boyan Lazarov, Socratis Petrides, and Jingyi Wang. An adaptive sampling augmented lagrangian method for stochastic optimization with deterministic constraints.Computers and Mathematics with Applications, 149:239–258,
-
[37]
doi: https://doi.org/10.1016/j.camwa.2023.09.014
ISSN 0898-1221. doi: https://doi.org/10.1016/j.camwa.2023.09.014. URL https: //www.sciencedirect.com/science/article/pii/S0898122123003991.Cited on page 3
-
[38]
Cooper: A Library for Constrained Optimization in Deep Learning, April 2025.Cited on page 3
Jose Gallego-Posada, Juan Ramirez, Meraj Hashemizadeh, and Simon Lacoste-Julien. Cooper: A Library for Constrained Optimization in Deep Learning, April 2025.Cited on page 3
work page 2025
-
[39]
Andrii Kliachkin, Jana Lepšová, Gilles Bareilles, and Jakub Mareˇcek. humancompatible.train: Implementing optimization algorithms for stochastically-constrained stochastic optimization problems.NeurIPS Workshop on Constrained Optimization; arXiv preprint arXiv:2509.21254, 2025.Cited on pages 3 and 15
-
[40]
A general method for solving extremal problems
Boris T Polyak. A general method for solving extremal problems. InSoviet Mathematics Doklady, volume 8, pages 593–597, 1967.Cited on page 3
work page 1967
-
[41]
Michal Koˇcvara and Michael Stingl. Pennon: A code for convex nonlinear and semidefinite programming.Optimization methods and software, 18(3):317–333, 2003.Cited on page 3
work page 2003
-
[42]
Pennon: a generalized augmented lagrangian method for semidefinite programming
Michal Koˇcvara and Michael Stingl. Pennon: a generalized augmented lagrangian method for semidefinite programming. InHigh performance algorithms and software for nonlinear optimization, pages 303–321. Springer, 2003.Cited on page 3
work page 2003
-
[43]
Pennon: Software for linear and nonlinear matrix inequali- ties
Michal Koˇcvara and Michael Stingl. Pennon: Software for linear and nonlinear matrix inequali- ties. InHandbook on semidefinite, conic and polynomial optimization, pages 755–791. Springer, 2012.Cited on page 3
work page 2012
-
[44]
Alberto De Marchi and Andreas Themelis. A penalty barrier framework for nonconvex con- strained optimization.Journal of Nonsmooth Analysis and Optimization, 5(Original research articles), 2025.Cited on page 3
work page 2025
-
[45]
R Tyrrell Rockafellar. Augmented lagrangians and applications of the proximal point algorithm in convex programming.Mathematics of operations research, 1(2):97–116, 1976.Cited on page 3. 12
work page 1976
-
[46]
R Tyrrell Rockafellar. Augmented lagrange multiplier functions and duality in nonconvex programming.SIAM Journal on Control, 12(2):268–285, 1974. Not cited
work page 1974
-
[47]
R Tyrell Rockafellar. The multiplier method of hestenes and powell applied to convex pro- gramming.Journal of Optimization Theory and applications, 12(6):555–562, 1973. Not cited
work page 1973
-
[48]
R Tyrrell Rockafellar. A dual approach to solving nonlinear programming problems by uncon- strained optimization.Mathematical programming, 5(1):354–373, 1973. Not cited
work page 1973
-
[49]
A method for nonlinear constraints in minimization problems.Optimization, pages 283–298, 1969
Michael JD Powell. A method for nonlinear constraints in minimization problems.Optimization, pages 283–298, 1969. Not cited
work page 1969
-
[50]
Multiplier and gradient methods.Journal of optimization theory and applications, 4(5):303–320, 1969
Magnus R Hestenes. Multiplier and gradient methods.Journal of optimization theory and applications, 4(5):303–320, 1969. Not cited
work page 1969
-
[51]
Weiwei Kong, Jefferson G Melo, and Renato DC Monteiro. Complexity of a quadratic penalty accelerated inexact proximal point method for solving linearly constrained nonconvex composite programs.SIAM Journal on Optimization, 29(4):2566–2593, 2019. Not cited
work page 2019
-
[52]
Weiwei Kong, Jefferson G Melo, and Renato DC Monteiro. Iteration complexity of a proximal augmented lagrangian method for solving nonconvex composite optimization problems with nonlinear convex constraints.Mathematics of Operations Research, 48(2):1066–1094, 2023. Not cited
work page 2023
-
[53]
Wenqiang Pu, Kaizhao Sun, and Jiawei Zhang. Smoothed proximal lagrangian method for nonlinear constrained programs.arXiv preprint arXiv:2408.15047, 2024. Not cited
-
[54]
Qihang Lin, Runchao Ma, and Yangyang Xu. Complexity of an inexact proximal-point penalty method for constrained smooth non-convex optimization.Computational optimization and applications, 82(1):175–224, 2022. Not cited
work page 2022
-
[55]
Jiawei Zhang and Zhi-Quan Luo. A proximal alternating direction method of multiplier for linearly constrained nonconvex minimization.SIAM Journal on Optimization, 30(3):2272–2302, 2020.Cited on page 4
work page 2020
-
[56]
Jiawei Zhang, Wenqiang Pu, and Zhi-Quan Luo. On the iteration complexity of smoothed proximal alm for nonconvex optimization problem with convex constraints.arXiv preprint arXiv:2207.06304, 2022.Cited on page 3
-
[57]
Amir Beck.First-Order Methods in Optimization. SIAM, Philadelphia, PA, 2017. doi: 10.1137/1.9781611974997.Cited on page 4
-
[58]
Adam: A Method for Stochastic Optimization
Diederik P Kingma. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014.Cited on page 5
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[59]
Maziar Raissi, Paris Perdikaris, and George Em Karniadakis. Physics informed deep learn- ing (part i): Data-driven solutions of nonlinear partial differential equations.arXiv preprint arXiv:1711.10561, 2017.Cited on pages 5 and 8
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[60]
fairret: a framework for differentiable fairness regularization terms, 2024
Maarten Buyl, MaryBeth Defrance, and Tijl De Bie. fairret: a framework for differentiable fairness regularization terms, 2024. URL https://arxiv.org/abs/2310.17256.Cited on page 6
-
[61]
Sifan Wang, Xinling Yu, and Paris Perdikaris. When and why pinns fail to train: A neural tangent kernel perspective.Journal of Computational Physics, 449:110768, 2022.Cited on pages 6 and 7
work page 2022
-
[62]
Sifan Wang, Yujun Teng, and Paris Perdikaris. Understanding and mitigating gradient flow pathologies in physics-informed neural networks.SIAM Journal on Scientific Computing, 43 (5):A3055–A3081, 2021.Cited on pages 6 and 7. 13
work page 2021
-
[63]
Levi D. McClenny and Ulisses M. Braga-Neto. Self-adaptive physics-informed neural networks. Journal of Computational Physics, 474:111722, February 2023. ISSN 0021-9991. doi: 10. 1016/j.jcp.2022.111722. URL http://dx.doi.org/10.1016/j.jcp.2022.111722.Cited on page 14
-
[64]
Solving PDEs as constrained optimization
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.Cited on pages 14 and 25. A Motivating example In this section, we give details on the motivating example (Figure 1). We demonstrate the motivation for usi...
work page 2016
-
[65]
[4] is used under the Apache 2.0 License
and Kliachkin et al. [4] is used under the Apache 2.0 License. The Dutch demographic dataset [25] is copyright 2001 Centraal Bureau voor de Statistiek (Statistics Netherlands) and the Minnesota Population Center. Guidelines: • The answer [N/A] means that the paper does not use existing assets. • The authors should cite the original paper that produced the...
work page 2001
-
[66]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.