Does Your Wildfire Prediction Model Actually Work, or Just Score Well?
Pith reviewed 2026-05-20 20:40 UTC · model grok-4.3
The pith
Wildfire model performance rankings depend on evaluation rules
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
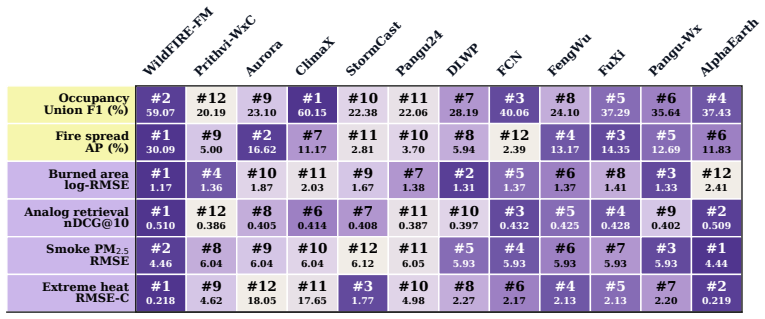
Under a fixed-contract evaluation framework, comparisons between WILDFIRE-FM and ten Earth foundation model baselines across occupancy, spread, retrieval, and regression tasks demonstrate that wildfire transfer conclusions depend strongly on evaluation design and task formulation.
What carries the argument
The fixed-contract evaluation framework, which uses a fixed-output check to isolate matching-rule effects and a fixed-feature check to isolate head-selection effects, ensuring controlled comparisons in sparse wildfire data.
If this is right
- Wildfire foundation model performance must be assessed under matched contracts to yield reliable transfer conclusions.
- Task formulation influences whether a model appears effective for prediction or retrieval.
- The new WILDFIRE-FM provides a domain-specific backbone that can be evaluated fairly using this framework.
- Future benchmarking in wildfire research should adopt similar controlled checks to avoid confounding.
Where Pith is reading between the lines
- Similar evaluation sensitivities likely exist in other domains with sparse rare events, such as earthquake prediction or disease outbreak forecasting.
- Without such frameworks, claims about foundation model superiority in Earth science applications may often be artifacts of evaluation design rather than true improvements.
- Researchers could test the framework on historical wildfire datasets to verify if past model comparisons hold under fixed contracts.
Load-bearing premise
The fixed-output check and fixed-feature check together control for the main confounding factors that affect transfer conclusions in sparse-event settings.
What would settle it
If model rankings and transfer conclusions remain the same across different matching rules and feature selections when using the fixed-contract framework, this would show that evaluation design does not strongly affect conclusions.
Figures





read the original abstract
Wildfire prediction is important for early warning and resource allocation, yet existing Earth foundation models (Earth FMs) are pretrained for general atmospheric and geophysical objectives rather than wildfire forecasting. To address this gap, we introduce WILDFIRE-FM, the first foundation model pretrained specifically for wildfire prediction using weather, active-fire observations, topography, vegetation, and static environmental data. However, introducing a domain-specific backbone alone does not solve the evaluation problem: wildfire events are sparse in space and time, making transfer conclusions highly sensitive to matching rules and evaluation settings. To address this problem, we introduce a fixed-contract evaluation framework with two controlled checks: a fixed-output check for matching-rule effects and a fixed-feature check for head-selection effects. Under matched contracts, we compare WILDFIRE-FM with ten Earth-FM baselines across occupancy, spread, retrieval, and regression tasks. Our results show that wildfire transfer conclusions depend strongly on evaluation design and task formulation. We hope this framework and WILDFIRE-FM provide a foundation for future wildfire-specific Earth-FM research and benchmarking. Our code is available at https://anonymous.4open.science/r/Wildfire-fm-evaluation-contracts-5AE9/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces WILDFIRE-FM, the first foundation model pretrained specifically for wildfire prediction on weather, active-fire observations, topography, vegetation, and static environmental data. It argues that transfer conclusions for such sparse-event tasks are highly sensitive to evaluation design and task formulation, and proposes a fixed-contract framework consisting of a fixed-output check (for matching-rule effects) and a fixed-feature check (for head-selection effects). The paper then compares WILDFIRE-FM against ten Earth-FM baselines across occupancy, spread, retrieval, and regression tasks, concluding that performance rankings and transfer claims vary substantially depending on the chosen contract.
Significance. If the empirical comparisons hold under the proposed controls, the work usefully demonstrates the fragility of standard transfer evaluations in rare-event domains and supplies both a domain-specific backbone and an evaluation protocol that future wildfire and Earth-science ML studies can adopt. The public release of code is a clear strength that supports reproducibility.
major comments (2)
- [§4.2] §4.2 (Fixed-contract framework): the assertion that the fixed-output and fixed-feature checks together 'control for the main confounding factors' is load-bearing for the central claim, yet the manuscript provides no explicit ablation or sensitivity analysis showing that other factors (e.g., temporal split strategies or class imbalance handling) are neutralized; without this, the dependence result risks being partly attributable to uncontrolled variables.
- [Results section, Table 3] Results section, Table 3 (or equivalent cross-task summary): the reported performance gaps between WILDFIRE-FM and the Earth-FM baselines under different contracts are presented without error bars, statistical significance tests, or multiple random seeds; this weakens the claim that conclusions 'depend strongly' on evaluation design, as the magnitude and reliability of the sensitivity cannot be assessed.
minor comments (3)
- [Abstract] Abstract: the headline result is stated qualitatively; adding one concrete numerical example (e.g., 'occupancy AUC drops from 0.82 to 0.61 when switching from fixed-output to standard matching') would make the sensitivity claim more immediate for readers.
- [§3] §3 (Pretraining details): the loss function and masking strategy used for WILDFIRE-FM are described at a high level; specifying the exact objective (e.g., cross-entropy weights for active-fire pixels) would aid replication.
- [Figure 2] Figure 2 (evaluation contract diagram): the arrows and boxes are difficult to follow at print size; adding a small legend or numbered steps would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and for recognizing the value of the fixed-contract framework and the public code release. We address each major comment below and outline the revisions we will make to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Fixed-contract framework): the assertion that the fixed-output and fixed-feature checks together 'control for the main confounding factors' is load-bearing for the central claim, yet the manuscript provides no explicit ablation or sensitivity analysis showing that other factors (e.g., temporal split strategies or class imbalance handling) are neutralized; without this, the dependence result risks being partly attributable to uncontrolled variables.
Authors: We agree that isolating the effects of the evaluation contract requires demonstrating that other design choices do not drive the observed sensitivity. The fixed-output check standardizes the prediction format and matching rules, while the fixed-feature check standardizes the input representation and head architecture; these two controls were chosen because they directly address the most common sources of non-comparable transfer results in sparse-event settings. Nevertheless, the original manuscript does not contain explicit sensitivity analyses for temporal split strategies or class-imbalance handling. In the revised version we will add a dedicated subsection that re-runs the cross-contract comparisons under alternative temporal splits (e.g., year-based vs. random) and under different imbalance-correction regimes, confirming that the ranking reversals across contracts persist. This addition will make the claim that conclusions depend strongly on the contract more robust. revision: yes
-
Referee: [Results section, Table 3] Results section, Table 3 (or equivalent cross-task summary): the reported performance gaps between WILDFIRE-FM and the Earth-FM baselines under different contracts are presented without error bars, statistical significance tests, or multiple random seeds; this weakens the claim that conclusions 'depend strongly' on evaluation design, as the magnitude and reliability of the sensitivity cannot be assessed.
Authors: We accept that the absence of variability estimates and formal statistical tests limits the strength of the sensitivity claim. In the revised manuscript we will re-execute all experiments with at least three independent random seeds, report means and standard deviations as error bars in Table 3 and the associated figures, and include paired statistical significance tests (with appropriate multiple-comparison correction) between contracts. These additions will allow readers to assess both the magnitude and the reliability of the performance differences that arise when the evaluation contract is changed. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper is an empirical comparison study that introduces WILDFIRE-FM and a fixed-contract evaluation framework consisting of fixed-output and fixed-feature checks, then reports results across occupancy, spread, retrieval, and regression tasks. All load-bearing claims rest on direct model comparisons under matched evaluation contracts rather than any derivation, equation, or prediction that reduces to its own inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked to justify core results, and the framework is presented as a methodological contribution whose effects are measured externally against baselines. The work is therefore self-contained against its own empirical benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard machine-learning assumptions about pretraining objectives and transfer learning apply to wildfire data.
invented entities (1)
-
WILDFIRE-FM
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Kaifeng Bi, Lingxi Xie, Hengheng Zhang, Xin Chen, Xiaotao Gu, and Qi Tian. Pangu- weather: A 3d high-resolution model for fast and accurate global weather forecast.Nature, 619(7970):533–538, 2023
work page 2023
-
[2]
Cristian Bodnar et al. Aurora: A foundation model of the atmosphere.arXiv preprint arXiv:2405.13063, 2024
-
[3]
Christopher F Brown, Michal R Kazmierski, Valerie J Pasquarella, William J Rucklidge, Masha Samsikova, Chenhui Zhang, Evan Shelhamer, Estefania Lahera, Olivia Wiles, Simon Ilyushchenko, et al. Alphaearth foundations: An embedding field model for accurate and efficient global mapping from sparse label data.arXiv preprint arXiv:2507.22291, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Kang Chen, Tao Han, Junchao Gong, Lei Bai, Fenghua Ling, Jing-Jia Luo, Xi Chen, Leiming Ma, Tianning Zhang, Rui Su, et al. Fengwu: Pushing the skillful global medium-range weather forecast beyond 10 days lead.arXiv preprint arXiv:2304.02948, 2023
-
[5]
Lei Chen, Xiaohui Zhong, Feng Zhang, Yuan Cheng, Yinghui Xu, Yuan Qi, and Hao Li. Fuxi: A cascade machine learning forecasting system for 15-day global weather forecast.npj climate and atmospheric science, 6(1):190, 2023
work page 2023
-
[6]
Elizabeth E. Ebert. Neighborhood verification: A strategy for rewarding close forecasts.Weather and Forecasting, 24(6):1498–1510, 2009
work page 2009
-
[7]
Alireza Farahmand, E Natasha Stavros, John T Reager, and Ali Behrangi. Introducing spatially distributed fire danger from earth observations (fdeo) using satellite-based data in the contiguous united states.Remote Sensing, 12(8):1252, 2020
work page 2020
-
[8]
Sebastian Gerard, Yu Zhao, and Josephine Sullivan. Wildfirespreadts: A dataset of multi-modal time series for wildfire spread prediction.Advances in Neural Information Processing Systems, 36:74515–74529, 2023
work page 2023
-
[9]
Eric Gilleland, David Ahijevych, Barbara G Brown, and Elizabeth E Ebert. Intercomparison of spatial forecast verification methods.Weather and Forecasting, 24(5):1416–1430, 2009
work page 2009
-
[10]
Johann Georg Goldammer. Early warning systems for the prediction of and appropriate response to wildfires and related environmental hazards. InEarly Warning Systems for Natural Disaster Reduction, 1999
work page 1999
-
[11]
Next day wildfire prediction using deep learning.arXiv preprint arXiv:2206.08930, 2022
Fantine Huot, R Lily Hu, Nita Goyal, Tharun Sankar, Matthias Ihme, and Yi-Fan Chen. Next day wildfire prediction using deep learning.arXiv preprint arXiv:2206.08930, 2022
-
[12]
WILDS: A benchmark of in-the-wild distribution shifts
Pang Wei Koh, Shiori Sagawa, Henrik Marklund, Sang Michael Xie, Marvin Zhang, Akshay Balsubramani, Weihua Hu, Michihiro Yasunaga, Richard Lanas Phillips, Irena Gao, et al. WILDS: A benchmark of in-the-wild distribution shifts. InProceedings of the International Conference on Machine Learning, pages 5637–5664, 2021
work page 2021
-
[13]
Vassiliki Kotroni, Constantinos Cartalis, Silas Michaelides, Julia Stoyanova, Filippos Tymvios, Antonis Bezes, Theodoros Christoudias, Stavros Dafis, Christos Giannakopoulos, Theodore M. Giannaros, et al. Disarm early warning system for wildfires in the eastern mediterranean. Sustainability, 12(16):6670, 2020. 10
work page 2020
-
[14]
GEO- Bench: Toward foundation models for earth monitoring
Alexandre Lacoste, Nils Lehmann, Pau Rodriguez, Evan Sherwin, Hannah Kerner, Björn Lütjens, Jeremy Irvin, David Dao, Hamed Alemohammad, Alexandre Drouin, et al. GEO- Bench: Toward foundation models for earth monitoring. InAdvances in Neural Information Processing Systems, 2023
work page 2023
-
[15]
Learning skillful medium-range global weather forecasting.Science, 382(6677):1416–1421, 2023
Remi Lam, Alvaro Sanchez-Gonzalez, Matthew Willson, Peter Wirnsberger, Meire Fortunato, Ferran Alet, Suman Ravuri, Timo Ewalds, Zach Eaton-Rosen, Weihua Hu, et al. Learning skillful medium-range global weather forecasting.Science, 382(6677):1416–1421, 2023
work page 2023
-
[16]
LANDFIRE 40 Fire Behavior Fuel Models
LANDFIRE. LANDFIRE 40 Fire Behavior Fuel Models. https://landfire.gov/fuel/ fbfm40, 2026. Accessed: 2026-05-05
work page 2026
-
[17]
LANDFIRE. LANDFIRE Forest Canopy Cover. https://landfire.gov/fuel/cc, 2026. Accessed: 2026-05-05
work page 2026
-
[18]
Carsten T. Lüth, Till J. Bungert, Lukas Klein, and Paul F. Jäger. Navigating the pitfalls of active learning evaluation: A systematic framework for meaningful performance assessment. In Advances in Neural Information Processing Systems, 2023
work page 2023
-
[19]
arXiv preprint arXiv:2412.04204 , year =
Valerio Marsocci, Yuru Jia, Georges Le Bellier, David Kerekes, Liang Zeng, Sebastian Hafner, Sebastian Gerard, Eric Brune, Ritu Yadav, Ali Shibli, et al. Pangaea: A global and inclusive benchmark for geospatial foundation models.arXiv preprint arXiv:2412.04204, 2024
-
[20]
McDermott, Haoran Zhang, Lasse Hyldig Hansen, Giovanni Angelotti, and Jack Gallifant
Matthew B. McDermott, Haoran Zhang, Lasse Hyldig Hansen, Giovanni Angelotti, and Jack Gallifant. A closer look at AUROC and AUPRC under class imbalance. InAdvances in Neural Information Processing Systems, 2024
work page 2024
-
[21]
Fire Information for Resource Management System (FIRMS)
NASA Earthdata. Fire Information for Resource Management System (FIRMS). https: //www.earthdata.nasa.gov/data/tools/firms, 2026. Accessed: 2026-05-05
work page 2026
-
[22]
Wildland Fire Interagency Geospatial Services (WFIGS): Current Perimeters
National Interagency Fire Center. Wildland Fire Interagency Geospatial Services (WFIGS): Current Perimeters. https://data-nifc.opendata.arcgis.com/datasets/nifc:: wfigs-current-perimeters/about, 2026. Accessed: 2026-05-05
work page 2026
-
[23]
Tung Nguyen, Johannes Brandstetter, Aditya Kapoor, Jayesh K Gupta, and Aditya Grover. Climax: A foundation model for weather and climate.arXiv preprint arXiv:2301.10343, 2023
-
[24]
Rapid Refresh / High-Resolution Rapid Refresh
NOAA National Centers for Environmental Information. Rapid Refresh / High-Resolution Rapid Refresh. https://www.ncei.noaa.gov/products/weather-climate-models/ rapid-refresh-update, 2026. Accessed: 2026-05-05
work page 2026
-
[25]
High- Resolution Rapid Refresh (HRRR)
NOAA National Centers for Environmental Prediction Environmental Modeling Center. High- Resolution Rapid Refresh (HRRR). https://rapidrefresh.noaa.gov/hrrr/, 2026. Ac- cessed: 2026-05-05
work page 2026
-
[26]
Oak Ridge National Laboratory. LandScan Global 2024. https://landscan.ornl.gov/,
work page 2024
-
[28]
Jaideep Pathak, Yair Cohen, Piyush Garg, Peter Harrington, Noah Brenowitz, Dale Durran, Morteza Mardani, Arash Vahdat, Shaoming Xu, Karthik Kashinath, et al. Kilometer-scale convection-allowing model emulation using generative diffusion modeling.Science Advances, 12(5):eadv0423, 2026
work page 2026
-
[29]
Jaideep Pathak, Shashank Subramanian, Peter Harrington, Sanjeev Raja, Ashesh Chattopadhyay, Morteza Mardani, Thorsten Kurth, David Hall, Zongyi Li, Kamyar Azizzadenesheli, et al. Fourcastnet: A global data-driven high-resolution weather model using adaptive fourier neural operators.arXiv preprint arXiv:2202.11214, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[30]
Paul D Pickell, Nicholas C Coops, Colin J Ferster, Christopher W Bater, Karen D Blouin, Mike D Flannigan, and Jinkai Zhang. An early warning system to forecast the close of the spring burning window from satellite-observed greenness.Scientific Reports, 7(1):14190, 2017
work page 2017
-
[31]
Firecast: Leveraging deep learning to predict wildfire spread
David Radke, Anna Hessler, and David Ellsworth. Firecast: Leveraging deep learning to predict wildfire spread. InProceedings of the 28th International Joint Conference on Artificial Intelligence, pages 4575–4581, 2019. 11
work page 2019
-
[32]
Stephan Rasp, Stephan Hoyer, Alex Merose, Ian Langmore, Peter Battaglia, Tyler Russell, Alvaro Sanchez-Gonzalez, Vivian Yang, Rob Carver, Shreya Agrawal, et al. WeatherBench 2: A benchmark for the next generation of data-driven global weather models.Journal of Advances in Modeling Earth Systems, 16(6):e2023MS004019, 2024
work page 2024
-
[33]
Colorado J Reed, Ritwik Gupta, Shufan Li, Sarah Brockman, Christopher Funk, Brian Clipp, Kurt Keutzer, Stefano Ermon, and Ruslan Salakhutdinov. Scale-mae: A scale-aware masked autoencoder for multiscale geospatial representation learning.arXiv preprint arXiv:2212.14532, 2023
-
[34]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InMedical Image Computing and Computer-Assisted Inter- vention, pages 234–241, 2015
work page 2015
-
[35]
Rylan Schaeffer, Brando Miranda, and Sanmi Koyejo. Are emergent abilities of large language models a mirage? InAdvances in Neural Information Processing Systems, 2023
work page 2023
-
[36]
Prithvi wxc: Foun- dation model for weather and climate,
Johannes Schmude, Sujit Roy, Paulina Trofimova, Karthik Ramesh, Bethany Lusch, Harikumar Kesa, Shraddha Singh, Phil Chen, Zhuohan Liu, Shubhankar Parashar, et al. Prithvi wxc: Foundation model for weather and climate.arXiv preprint arXiv:2409.13598, 2024
-
[37]
Stewart, Caleb Robinson, Isaac A
Adam J. Stewart, Caleb Robinson, Isaac A. Corley, Anthony Ortiz, Juan M. Lavista Ferres, and Arindam Banerjee. Torchgeo: Deep learning with geospatial data. InProceedings of the ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, 2022
work page 2022
-
[38]
Jeremias Traub, Till J. Bungert, Carsten T. Lüth, Michael Baumgartner, Klaus H. Maier-Hein, Lena Maier-Hein, and Paul F. Jäger. Overcoming common flaws in the evaluation of selective classification systems. InAdvances in Neural Information Processing Systems, 2024
work page 2024
-
[39]
Geological Survey and USDA Forest Service
U.S. Geological Survey and USDA Forest Service. Monitoring Trends in Burn Severity (MTBS). https://www.mtbs.gov/, 2025. Accessed: 2026-05-05
work page 2025
-
[40]
Wildfire Risk to Communities: Housing Unit Density Image Service
USDA Forest Service. Wildfire Risk to Communities: Housing Unit Density Image Service. https://catalog.data.gov/dataset/ wildfire-risk-to-communities-housing-unit-density-image-service-fac22 ,
-
[41]
Accessed: 2026-05-05
work page 2026
-
[42]
Jonathan A Weyn, Dale R Durran, and Rich Caruana. Improving data-driven global weather prediction using deep convolutional neural networks on a cubed sphere.Journal of Advances in Modeling Earth Systems, 12(9):e2020MS002109, 2020
work page 2020
-
[43]
Christopher Yeh, Chenlin Meng, Sijing Wang, Anne Driscoll, Erik Rozi, Peng Liu, Jae Yong Lee, Marshall Burke, David B. Lobell, and Stefano Ermon. SustainBench: Benchmarks for monitoring the sustainable development goals with machine learning. InAdvances in Neural Information Processing Systems, 2021. 12 Appendix Contents A Evaluation Contract Specificatio...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.