The Thermodynamic Costs of Simple Linear Regression
Pith reviewed 2026-05-20 06:59 UTC · model grok-4.3
The pith
Floating-point linear regression carries a thermodynamic lower bound on energy that determines the optimal training dataset size for a given prediction accuracy target.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
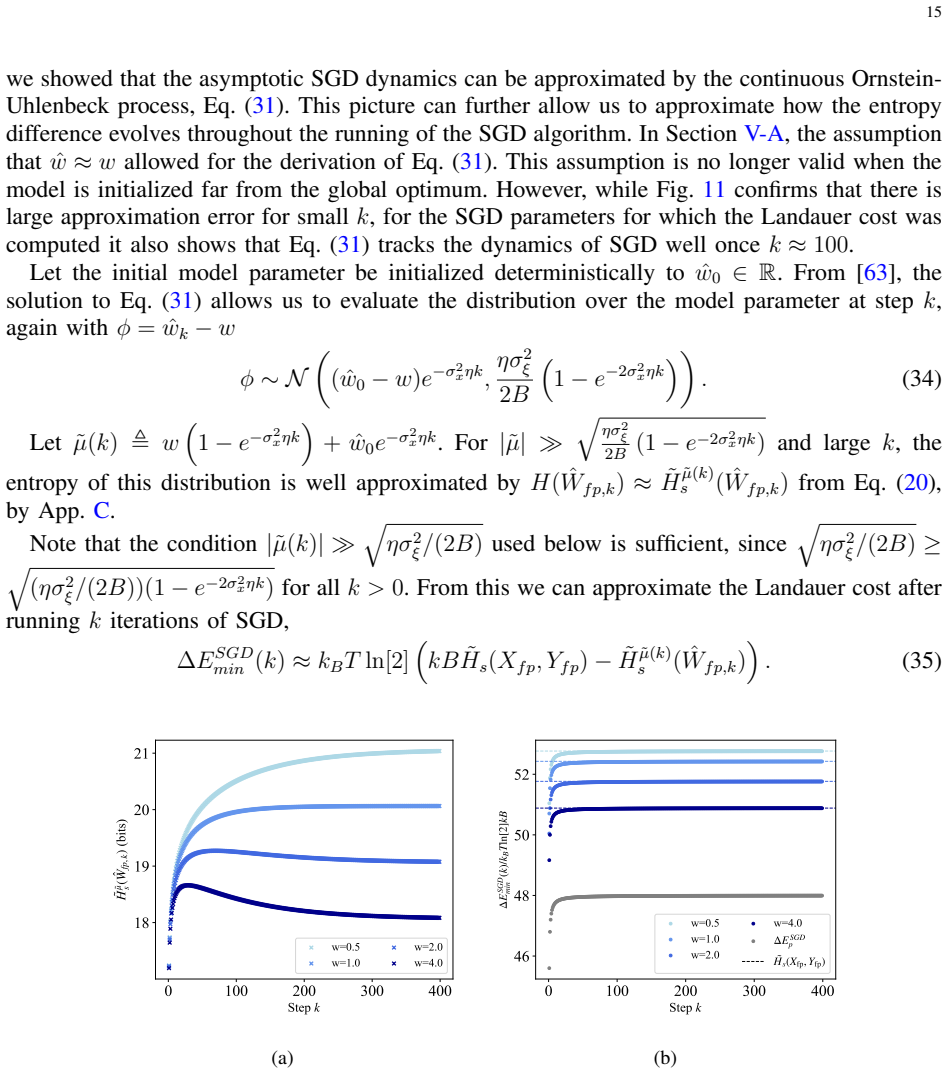
By counting the irreversible bit erasures that occur in the floating-point arithmetic steps of linear regression, the authors derive a concrete lower bound on dissipated energy that increases with both dataset size and numerical precision. When this cost is weighed against the reduction in generalization error that larger datasets provide, an energy-optimal finite dataset size emerges for any required inference accuracy. The same counting approach is applied to stochastic gradient descent, yielding a distinct but related scaling relation.
What carries the argument
Landauer's principle applied to irreversible bit erasures in floating-point arithmetic steps of exact linear regression or stochastic gradient descent
If this is right
- Total energy for a linear model with fixed generalization-error target reaches a minimum at a finite dataset size rather than growing without limit.
- Energy costs of exact regression and SGD versions scale differently with precision and data volume, allowing direct comparison of their thermodynamic efficiency.
- Inference demand that requires lower generalization error shifts the optimal training set size upward in a quantifiable way.
- Mismatch between continuous inputs and discrete algorithm steps produces an additional entropy-production term that can be lower-bounded separately.
Where Pith is reading between the lines
- The same counting method could be extended to other linear models such as logistic regression or to the forward passes of small neural networks.
- Hardware designers could use these bounds to prioritize reductions in floating-point erasure costs when building energy-efficient ML accelerators.
- For very large-scale inference workloads the derived scaling laws predict a crossover beyond which adding more training data becomes energetically wasteful.
Load-bearing premise
Landauer's principle can be applied directly to count the irreversible bit operations in floating-point linear regression and stochastic gradient descent without additional hidden costs from memory access or control flow.
What would settle it
An experiment that measures the actual energy consumed by a processor executing floating-point linear regression on a known dataset and finds dissipation below the calculated Landauer bound for the same number of bit erasures and precision would falsify the bound.
Figures





















read the original abstract
The construction of models from data is a significant contributor to the energetic costs of computation. Because of this, understanding how foundational thermodynamic bounds apply to modeling algorithms will be increasingly important. Here, we study the thermodynamic costs of a basic and fundamental modeling algorithm: simple linear regression. Following Landauer, we approximate the thermodynamic lower bound on irreversibly performing both exact linear regression and linear regression via stochastic gradient descent as implemented on floating-point numbers. From this, we derive energycost aware scaling laws for the optimal dataset size for training a linear regression model given a generalization error dependent demand for inference. Additionally, we discuss a method to lower bound the entropy production from the mismatch cost for algorithms with continuous input variables.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
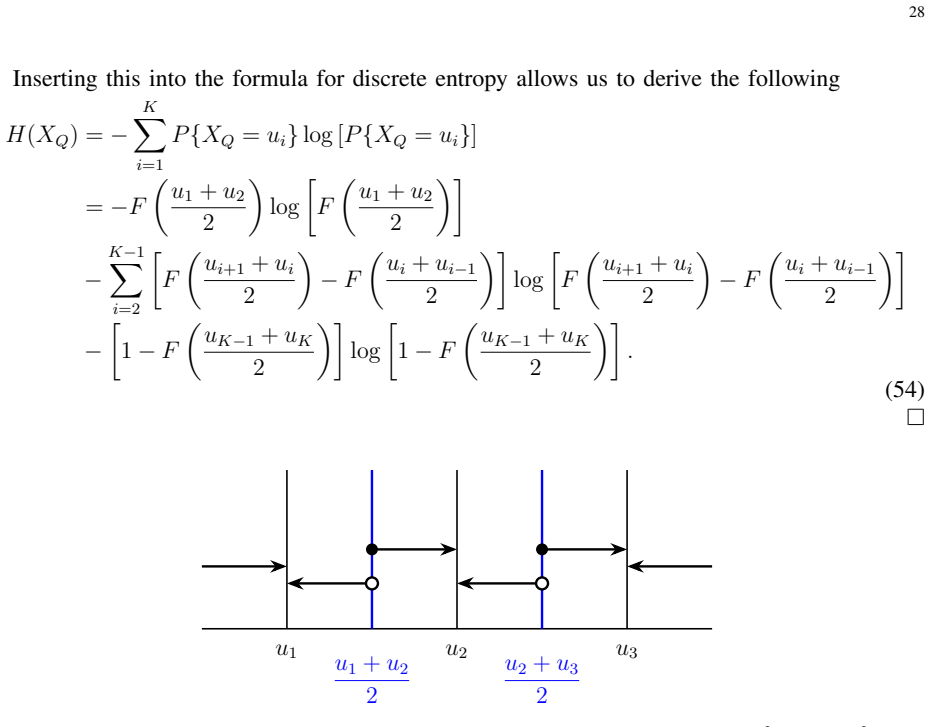
Summary. The manuscript approximates thermodynamic lower bounds on the irreversible energy costs of exact simple linear regression and its implementation via stochastic gradient descent on floating-point arithmetic, by applying Landauer's principle to count bit erasures. From these bounds it derives energy-cost-aware scaling laws for the optimal training dataset size that balance computational dissipation against a generalization-error requirement at inference time. It additionally outlines a method to lower-bound entropy production arising from mismatch costs when input variables are continuous.
Significance. If the bit-operation counting procedure yields a valid and dominant lower bound, the resulting scaling laws would supply a concrete, falsifiable link between thermodynamic principles and practical choices of training-set size in linear models. The mismatch-cost discussion for continuous variables is a useful technical contribution that could extend to other regression or optimization settings. The work is strongest where it remains within the abstract model of irreversible operations; its practical relevance hinges on whether those operations dominate real hardware dissipation.
major comments (2)
- [Thermodynamic bounds and floating-point implementation] The central approximation that counts only irreversible bit operations in floating-point linear regression and SGD (as described in the derivation following the abstract) does not address memory-hierarchy accesses, data movement, or control-flow overhead. These terms are not strictly proportional to bit erasures and can exceed the Landauer floor by orders of magnitude on current hardware; without a quantitative argument that they remain sub-dominant, the claimed lower bound cannot reliably support the derived scaling laws for optimal dataset size.
- [Energy-cost aware scaling laws] The scaling laws for optimal dataset size are obtained by minimizing a total cost that includes both the approximated dissipation and a generalization-error term. If the error metric used to define the inference demand is the same quantity that enters the cost function (as suggested by the abstract phrasing), the optimum may be tautological rather than predictive; an explicit statement of the functional form and any free parameters in the scaling relation is needed to assess this.
minor comments (2)
- [Mismatch cost discussion] Notation for the mismatch-cost lower bound on continuous variables should be introduced with a short example (e.g., a one-dimensional Gaussian input) to clarify how the continuous-to-discrete translation is performed.
- [Introduction] The abstract states that bounds are 'approximated'; a brief paragraph in the introduction or methods section listing the concrete approximations (e.g., neglect of reversible steps, assumption of uniform bit cost) would improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped us clarify the scope and presentation of our results. Below we respond point-by-point to the major comments. We have revised the manuscript to incorporate additional discussion and explicit statements of the scaling relations where appropriate.
read point-by-point responses
-
Referee: [Thermodynamic bounds and floating-point implementation] The central approximation that counts only irreversible bit operations in floating-point linear regression and SGD (as described in the derivation following the abstract) does not address memory-hierarchy accesses, data movement, or control-flow overhead. These terms are not strictly proportional to bit erasures and can exceed the Landauer floor by orders of magnitude on current hardware; without a quantitative argument that they remain sub-dominant, the claimed lower bound cannot reliably support the derived scaling laws for optimal dataset size.
Authors: Our derivation applies Landauer's principle strictly to the irreversible bit erasures that occur during the floating-point arithmetic operations of exact linear regression and SGD. This yields a hardware-independent lower bound on the thermodynamic cost of those specific operations. We agree that memory-hierarchy accesses, data movement, and control flow are not included and can dominate dissipation on existing processors. In the revised manuscript we have added an explicit paragraph in the discussion section stating that the reported bounds and scaling laws concern only the Landauer-limited arithmetic component; they are intended as theoretical minima that any physical implementation must respect, rather than as predictions of total energy use on current hardware. Because a quantitative demonstration of sub-dominance would require device-specific models outside the scope of this theoretical study, we have instead emphasized how the scaling laws can be combined with empirical overhead models in future applied work. revision: partial
-
Referee: [Energy-cost aware scaling laws] The scaling laws for optimal dataset size are obtained by minimizing a total cost that includes both the approximated dissipation and a generalization-error term. If the error metric used to define the inference demand is the same quantity that enters the cost function (as suggested by the abstract phrasing), the optimum may be tautological rather than predictive; an explicit statement of the functional form and any free parameters in the scaling relation is needed to assess this.
Authors: The generalization error appears solely as an external performance requirement at inference time, not as a term inside the training dissipation cost. We minimize the thermodynamic cost of training subject to the constraint that the deployed model must achieve a target generalization error ε. In the revised manuscript we now state the explicit functional form: the optimal training-set size scales as N* ∝ (log(1/ε) + c · precision) / β, where β is the per-sample dissipation coefficient derived from bit erasures and c collects constants from the linear-regression solution. The free parameters are the target error ε, the floating-point precision, and the data variance; these are listed in the new scaling-law subsection. Because the energy cost is incurred only during training while ε is a post-training specification, the resulting optimum is predictive rather than tautological. revision: yes
Circularity Check
No significant circularity; derivation builds from Landauer bounds and statistical scaling without self-referential reduction
full rationale
The paper starts from Landauer's principle applied to bit erasures in exact linear regression and floating-point SGD, counts irreversible operations, and derives energy-aware scaling laws for optimal dataset size under a generalization-error constraint. No equations or steps reduce the final scaling law to a fitted parameter or prior self-citation by construction; the optimal-N expression emerges from combining the thermodynamic cost model with standard bias-variance or generalization bounds rather than tautologically re-expressing the input error metric. The derivation remains self-contained against external thermodynamic and learning-theoretic benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Landauer's principle supplies the minimum energy cost for each irreversible bit erasure or overwrite performed during linear regression and SGD updates on floating-point numbers.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Following Landauer, we approximate the thermodynamic lower bound on irreversibly performing both exact linear regression and linear regression via stochastic gradient descent as implemented on floating-point numbers.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We can gain further insight into the entropy of floating-point numbers... relating the differential entropy of a continuous random variable to the discrete entropy of its counterpart discrete representation.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
2024 United States Data Center Energy Usage Report,
A. Shehabi, A. Newkirk, S. Smith, A. Hubbard, N. Lei, M. Siddiket al., “2024 United States Data Center Energy Usage Report,” Lawrence Berkeley National Laboratory, Berkeley, CA, USA, Tech. Rep. LBNL-2001637, 2024. [Online]. Available: https://escholarship.org/uc/item/32d6m0d1
work page 2024
-
[2]
Power hungry processing: Watts driving the cost of ai deployment?
A. S. Luccioni, Y . Jernite, and E. Strubell, “Power hungry processing: Watts driving the cost of ai deployment?” in Proceedings of the ACM Conference on Fairness, Accountability, and Transparency (FAccT ’24), Rio de Janeiro, Brazil, 2024, pp. 85–99
work page 2024
-
[3]
The growing energy footprint of artificial intelligence,
A. de Vries, “The growing energy footprint of artificial intelligence,”Joule, vol. 7, no. 10, pp. 2191–2194, Oct 2023. 22
work page 2023
-
[4]
A systematic review of green ai,
R. Verdecchia, J. Sallou, and L. Cruz, “A systematic review of green ai,”WIREs Data Mining and Knowledge Discovery, vol. 13, no. 4, p. e1507, 2023
work page 2023
-
[5]
The end of moore’s law: Living without an exponential,
P. Schuster, “The end of moore’s law: Living without an exponential,”Complexity, vol. 21, no. 2, pp. 7–10, 2016
work page 2016
-
[6]
The end of moore’s law: A new beginning for information technology,
T. M. Conteet al., “The end of moore’s law: A new beginning for information technology,” Computing Community Consortium (CCC), Computing Research Association, Tech. Rep., 2017. [Online]. Available: https: //cra.org/ccc/resources/ccc-led-whitepapers/
work page 2017
-
[7]
Moore’s law and the energy requirement of computing versus performance,
L. B. Kish, “Moore’s law and the energy requirement of computing versus performance,”IEE Proceedings – Circuits, Devices and Systems, vol. 151, no. 2, pp. 190–194, Apr 2004
work page 2004
-
[8]
Noninvertible Global Symmet ries in the Standard Model,
N. Zhang, “Moore’s law is dead, long live moore’s law!” arXiv preprint arXiv:2205.05086, 2022. [Online]. Available: https://arxiv.org/abs/2205.05086
-
[9]
Irreversibility and heat generation in the computing process,
R. Landauer, “Irreversibility and heat generation in the computing process,”IBM Journal of Research and Development, vol. 5, no. 3, pp. 183–191, Jul 1961
work page 1961
-
[10]
The thermodynamics of computation—a review,
C. H. Bennett, “The thermodynamics of computation—a review,”International Journal of Theoretical Physics, vol. 21, no. 12, pp. 905–940, Dec 1982
work page 1982
-
[11]
Ultimate physical limits to computation,
S. Lloyd, “Ultimate physical limits to computation,”Nature, vol. 406, no. 6799, pp. 1047–1054, Aug 2000
work page 2000
-
[12]
M. P. Frank, “Physical limits of computing,”Computer, vol. 50, no. 9, pp. 14–23, Sep 2017
work page 2017
-
[13]
The thermodynamics of computation—a review,
C. H. Bennett, “The thermodynamics of computation—a review,”International Journal of Theoretical Physics, vol. 21, no. 12, pp. 905–940, 1982, same asBennett1982
work page 1982
-
[14]
The physical limits of communication and computation,
R. Landauer, “The physical limits of communication and computation,”IEEE Spectrum, vol. 9, no. 5, pp. 23–29, May 1972
work page 1972
-
[15]
Is stochastic thermodynamics the key to understanding the energy costs of computation?
D. H. Wolpert, J. Korbel, C. W. Lynn, F. Tasnim, J. A. Grochow, G. Kardes ¸, J. B. Aimone, V . Balasubramanian, E. D. Giuli, D. Doty, N. Freitas, M. Marsili, T. E. Ouldridge, A. W. Richa, P. Riechers, ´Edgar Rold ´an, B. Rubenstein, Z. Toroczkai, and J. Paradiso, “Is stochastic thermodynamics the key to understanding the energy costs of computation?” Proc...
-
[16]
The stochastic thermodynamics of computation,
D. H. Wolpert, “The stochastic thermodynamics of computation,”Journal of Physics A: Mathematical and Theoretical, vol. 52, no. 19, p. 193001, 2019
work page 2019
-
[17]
Entropy production bounds for systems running computer programs
A. Yadav, F. Caravelli, and D. H. Wolpert, “System-independent lower bounds on entropy production incurred by running a computer program,” arXiv preprint arXiv:2411.16088, 2025. [Online]. Available: https://arxiv.org/abs/2411.16088
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
G. Manzano, G. Kardes ¸, ´E. Rold ´an, and D. H. Wolpert, “Thermodynamics of computations with absolute irreversibility, unidirectional transitions, and stochastic computation times,”Physical Review X, vol. 14, no. 2, p. 021026, 2024
work page 2024
-
[19]
A. Kolchinsky and D. H. Wolpert, “Dependence of integrated, instantaneous, and fluctuating entropy production on the initial state in quantum and classical processes,”Physical Review E, vol. 104, no. 5, p. 054107, Nov 2021
work page 2021
-
[20]
A logical calculus of the ideas immanent in nervous activity,
W. S. McCulloch and W. Pitts, “A logical calculus of the ideas immanent in nervous activity,”Bulletin of Mathematical Biophysics, vol. 5, no. 4, pp. 115–133, Dec 1943
work page 1943
-
[21]
The perceptron: A probabilistic model for information storage and organization in the brain,
F. Rosenblatt, “The perceptron: A probabilistic model for information storage and organization in the brain,”Psychological Review, vol. 65, no. 6, pp. 386–408, Nov 1958
work page 1958
-
[22]
B. Widrow and M. E. Hoff, “Adaptive switching circuits,” in1960 IRE WESCON Convention Record – Part 4. New York: Institute of Radio Engineers, 1960, pp. 96–104
work page 1960
- [23]
-
[24]
S. Goldt and U. Seifert, “Stochastic thermodynamics of learning,”Phys. Rev. Lett., vol. 118, p. 010601, Jan 2017. [Online]. Available: https://link.aps.org/doi/10.1103/PhysRevLett.118.010601
-
[25]
E. D. Demaine, J. Lynch, G. J. Mirano, and N. Tyagi, “Energy-Efficient Algorithms,” inProceedings of the 2016 ACM Conference on Innovations in Theoretical Computer Science, ser. ITCS ’16. New York, NY , USA: Association for Computing Machinery, Jan. 2016, pp. 321–332. [Online]. Available: https://dl.acm.org/doi/10.1145/2840728.2840756
-
[26]
Thermodynamic bounds on energy use in deep neural networks,
A. V . Tkachenko, “Thermodynamic bounds on energy use in deep neural networks,” 2025. [Online]. Available: https://arxiv.org/abs/2503.09980
-
[27]
NVIDIA Blackwell Architecture Technical Overview,
NVIDIA, “NVIDIA Blackwell Architecture Technical Overview,” NVIDIA, Tech. Rep., 2025. [Online]. Available: https://resources.nvidia.com/en-us-blackwell-architecture
work page 2025
-
[28]
I. Advanced Micro Devices, “AMD CDNA 4 Architecture,” AMD, Tech. Rep., Oct. 2025. [Online]. Available: https: //www.amd.com/content/dam/amd/en/documents/instinct-tech-docs/white-papers/amd-cdna-4-architecture-whitepaper.pdf
work page 2025
-
[29]
Data Compression With Low Distortion and Finite Blocklength,
V . Kostina, “Data Compression With Low Distortion and Finite Blocklength,”IEEE Transactions on Information Theory, vol. 63, no. 7, pp. 4268–4285, Jul. 2017. [Online]. Available: https://ieeexplore.ieee.org/abstract/document/7867787
-
[30]
Efloat: Entropy-coded floating point format for compressing vector embedding models,
R. Bordawekar, B. Abali, and M.-H. Chen, “Efloat: Entropy-coded floating point format for compressing vector embedding models,” 2022. [Online]. Available: https://arxiv.org/abs/2102.02705
-
[31]
Y . Hao, Y . Cao, and L. Mou, “NeuZip: Memory-Efficient Training and Inference with Dynamic Compression of Neural Networks,” Oct. 2024, arXiv:2410.20650 [cs]. [Online]. Available: http://arxiv.org/abs/2410.20650
-
[32]
The Entropy of Floating-Point Numbers
S. Daniels, S. H. D’Ambrosia, M. R. DeWeese, and A. Sahai, “The entropy of floating-point numbers,” 2026. [Online]. Available: https://arxiv.org/abs/2605.11546 23
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
Beyond chinchilla-optimal: Ac- counting for inference in language model scaling laws
N. Sardana, J. Portes, S. Doubov, and J. Frankle, “Beyond chinchilla-optimal: Accounting for inference in language model scaling laws,” 2025. [Online]. Available: https://arxiv.org/abs/2401.00448
-
[34]
An efficient reversible algorithm for linear regression,
E. D. Demaine, J. Lynch, and J. Sun, “An efficient reversible algorithm for linear regression,” in2021 International Conference on Rebooting Computing (ICRC), 2021, pp. 103–108
work page 2021
-
[35]
Gradient-based hyperparameter optimization through reversible learning,
D. Maclaurin, D. Duvenaud, and R. P. Adams, “Gradient-based hyperparameter optimization through reversible learning,”
-
[36]
Gradient-based Hyperparameter Optimization through Reversible Learning
[Online]. Available: https://arxiv.org/abs/1502.03492
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Tolman,The Principles of Statistical Mechanics, by Richard C
R. Tolman,The Principles of Statistical Mechanics, by Richard C. Tolman ..., ser. International series of monographs on physics. Oxford University Press, 1942. [Online]. Available: https://books.google.com/books?id=Hbr9yAEACAAJ
work page 1942
-
[38]
J. W. Gibbs,The Collected Works of J. Willard Gibbs. Longmans, Green and Company, 1928, vol. 1
work page 1928
-
[39]
The Physical Basis of the Gibbs-von Neumann entropy
O. J. E. Maroney, “The physical basis of the gibbs-von neumann entropy,” 2008. [Online]. Available: https://arxiv.org/abs/quant-ph/0701127
work page internal anchor Pith review Pith/arXiv arXiv 2008
-
[40]
Generalizing landauer’s principle,
——, “Generalizing landauer’s principle,”Phys. Rev. E, vol. 79, p. 031105, Mar 2009. [Online]. Available: https://link.aps.org/doi/10.1103/PhysRevE.79.031105
-
[41]
H. B. Callen,Thermodynamics and an introduction to thermostatistics. New York, NY: Wiley, 1985. [Online]. Available: https://cds.cern.ch/record/450289
work page 1985
-
[42]
The (absence of a) relationship between thermodynamic and logical reversibility,
O. Maroney, “The (absence of a) relationship between thermodynamic and logical reversibility,”Studies in History and Philosophy of Science Part B: Studies in History and Philosophy of Modern Physics, vol. 36, no. 2, pp. 355–374, 2005. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S1355219805000031
work page 2005
-
[43]
L. D. Landau, E. M. Lifshitz, and L. P. Pitaevskii,Statistical Physics: Part 1, 3rd ed., ser. Course of Theoretical Physics. Oxford: Pergamon Press, 1980, vol. 5
work page 1980
-
[44]
Chandler,Introduction to Modern Statistical Mechanics
D. Chandler,Introduction to Modern Statistical Mechanics. Oxford University Press, 1987
work page 1987
-
[45]
FP8 Quantization: The Power of the Exponent,
A. Kuzmin, M. van Baalen, Y . Ren, M. Nagel, J. Peters, and T. Blankevoort, “FP8 Quantization: The Power of the Exponent,”Advances in Neural Information Processing Systems, vol. 35, pp. 14 651–14 662, Dec. 2022. [Online]. Available: https://proceedings.neurips.cc/paper files/paper/2022/hash/ 5e07476b6bd2497e1fbd11b8f0b2de3c-Abstract-Conference.html
work page 2022
-
[46]
Microscaling data formats for deep learning.arXiv preprint arXiv:2310.10537,
B. D. Rouhani, R. Zhao, A. More, M. Hall, A. Khodamoradi, S. Deng, D. Choudhary, M. Cornea, E. Dellinger, K. Denolf, S. Dusan, V . Elango, M. Golub, A. Heinecke, P. James-Roxby, D. Jani, G. Kolhe, M. Langhammer, A. Li, L. Melnick, M. Mesmakhosroshahi, A. Rodriguez, M. Schulte, R. Shafipour, L. Shao, M. Siu, P. Dubey, P. Micikevicius, M. Naumov, C. Verrill...
-
[47]
B. Darvish Rouhani, R. Zhao, V . Elango, R. Shafipour, M. Hall, M. Mesmakhosroshahi, A. More, L. Melnick, M. Golub, G. Varatkar, L. Shao, G. Kolhe, D. Melts, J. Klar, R. L’Heureux, M. Perry, D. Burger, E. Chung, Z. S. Deng, S. Naghshineh, J. Park, and M. Naumov, “With Shared Microexponents, A Little Shifting Goes a Long Way,” inProceedings of the 50th Ann...
-
[48]
Characterization and Mitigation of Training Instabilities in Microscaling Formats,
H. Su, M. Kwun, S. Gil, S. Kakade, and N. Anand, “Characterization and Mitigation of Training Instabilities in Microscaling Formats,” Jun. 2025. [Online]. Available: https://arxiv.org/abs/2506.20752v1
-
[49]
J. M. Muller,Handbook of floating-point arithmetic / Jean-Michel Muller [and others].Boston: Birkhauser, 2010
work page 2010
-
[50]
What every computer scientist should know about floating-point arithmetic,
D. Goldberg, “What every computer scientist should know about floating-point arithmetic,”ACM Comput. Surv., vol. 23, no. 1, p. 5–48, Mar. 1991. [Online]. Available: https://doi.org/10.1145/103162.103163
-
[51]
T. M. Cover and J. A. Thomas,Elements of Information Theory (Wiley Series in Telecommunications and Signal Processing). USA: Wiley-Interscience, 2006
work page 2006
-
[52]
On the dimension and entropy of probability distributions,
A. R ´enyi, “On the dimension and entropy of probability distributions,”Acta Mathematica Academiae Scientiarum Hungarica, vol. 10, no. 1, pp. 193–215, Mar. 1959. [Online]. Available: https://doi.org/10.1007/BF02063299
-
[53]
Information Theory and Statistical Mechanics,
E. T. Jaynes, “Information Theory and Statistical Mechanics,” inStatistical Physics, ser. Brandeis Summer Institute. New York, NY: W. A. Benjamin Inc., 1962, pp. 181–218
work page 1962
-
[54]
——, “Prior probabilities,”IEEE Transactions on Systems and Cybernetics, no. 3, pp. 227–241, 1968
work page 1968
-
[55]
T. Linder and K. Zeger, “Asymptotic entropy-constrained performance of tessellating and universal randomized lattice quantization,”IEEE Transactions on Information Theory, vol. 40, no. 2, pp. 575–579, Mar. 1994. [Online]. Available: https://ieeexplore.ieee.org/abstract/document/312189
work page 1994
-
[56]
Asymptotically efficient quantizing,
H. Gish and J. Pierce, “Asymptotically efficient quantizing,”IEEE Transactions on Information Theory, vol. 14, no. 5, pp. 676–683, Sep. 1968. [Online]. Available: https://ieeexplore.ieee.org/abstract/document/1054193
-
[57]
R. M. Gray and D. L. Neuhoff, “Quantization,”IEEE Transactions on Information Theory, vol. 44, no. 6, pp. 2325–2383, 1998
work page 1998
-
[58]
Communication in the Presence of Noise,
C. Shannon, “Communication in the Presence of Noise,”Proceedings of the IRE, vol. 37, no. 1, pp. 10–21, Jan. 1949. [Online]. Available: https://ieeexplore.ieee.org/abstract/document/1697831
-
[59]
N. L. Johnson, S. Kotz, and N. Balakrishnan,Continuous univariate distributions, 2nd ed. New York: Wiley, 1994
work page 1994
-
[60]
Stochastic gradient descent as approximate bayesian inference,
S. Mandt, M. D. Hoffman, and D. M. Blei, “Stochastic gradient descent as approximate bayesian inference,”J. Mach. Learn. Res., vol. 18, no. 1, p. 4873–4907, Jan. 2017
work page 2017
-
[61]
A variational analysis of stochastic gradient algorithms,
——, “A variational analysis of stochastic gradient algorithms,” inProceedings of the 33rd International Conference on International Conference on Machine Learning - Volume 48, ser. ICML’16. JMLR.org, 2016, p. 354–363. 24
work page 2016
-
[62]
Three Factors Influencing Minima in SGD
S. Jastrzebski, Z. Kenton, D. Arpit, N. Ballas, A. Fischer, Y . Bengio, and A. J. Storkey, “Three factors influencing minima in sgd,”ArXiv, vol. abs/1711.04623, 2017. [Online]. Available: https://api.semanticscholar.org/CorpusID:7311295
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[63]
Optimization methods for large-scale machine learning,
L. Bottou, F. E. Curtis, and J. Nocedal, “Optimization methods for large-scale machine learning,”SIAM review, vol. 60, no. 2, pp. 223–311, 2018
work page 2018
-
[64]
G. A. Pavliotis,Stochastic processes and applications : diffusion processes, the Fokker-Planck and Langevin equations / Grigorios A. Pavliotis., ser. Texts in applied mathematics, volume 60. New York: Springer, 2014 - 2014
work page 2014
-
[65]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei, “Scaling laws for neural language models,” 2020. [Online]. Available: https://arxiv.org/abs/2001.08361
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[66]
Training Compute-Optimal Large Language Models
J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, D. de Las Casas, L. A. Hendricks, J. Welbl, A. Clark, T. Hennigan, E. Noland, K. Millican, G. van den Driessche, B. Damoc, A. Guy, S. Osindero, K. Simonyan, E. Elsen, J. W. Rae, O. Vinyals, and L. Sifre, “Training compute-optimal large language models,” 2022. [Online]. Available: ...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[67]
Carbon Emissions and Large Neural Network Training
D. Patterson, J. Gonzalez, Q. Le, C. Liang, L.-M. Munguia, D. Rothchild, D. So, M. Texier, and J. Dean, “Carbon emissions and large neural network training,” 2021. [Online]. Available: https://arxiv.org/abs/2104.10350
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[68]
Are emergent abilities of large language models a mirage?
R. Schaeffer, B. Miranda, and S. Koyejo, “Are emergent abilities of large language models a mirage?”Advances in Neural Information Processing Systems, vol. 36, 2023
work page 2023
-
[69]
arXiv preprint arXiv:2403.15796 , year=
Z. Du, A. Zeng, Y . Dong, and J. Tang, “Understanding Emergent Abilities of Language Models from the Loss Perspective,” Jan. 2025, arXiv:2403.15796 [cs]. [Online]. Available: http://arxiv.org/abs/2403.15796
-
[70]
Optimal finite-time processes in stochastic thermodynamics,
T. Schmiedl and U. Seifert, “Optimal finite-time processes in stochastic thermodynamics,”Phys. Rev. Lett., vol. 98, p. 108301, Mar 2007. [Online]. Available: https://link.aps.org/doi/10.1103/PhysRevLett.98.108301
-
[71]
Thermodynamic metrics and optimal paths,
D. A. Sivak and G. E. Crooks, “Thermodynamic metrics and optimal paths,”Phys. Rev. Lett., vol. 108, p. 190602, May
-
[72]
Available: https://link.aps.org/doi/10.1103/PhysRevLett.108.190602
[Online]. Available: https://link.aps.org/doi/10.1103/PhysRevLett.108.190602
-
[73]
N. Freitas, J.-C. Delvenne, and M. Esposito, “Stochastic thermodynamics of nonlinear electronic circuits: A realistic framework for computing aroundkt,”Phys. Rev. X, vol. 11, p. 031064, Sep 2021. [Online]. Available: https://link.aps.org/doi/10.1103/PhysRevX.11.031064
-
[74]
Dependence of dissipation on the initial distribution over states,
A. Kolchinsky and D. H. Wolpert, “Dependence of dissipation on the initial distribution over states,”Journal of Statistical Mechanics: Theory and Experiment, vol. 2017, 2016. [Online]. Available: https://api.semanticscholar.org/CorpusID: 17899737
work page 2017
-
[75]
Thermodynamics of computing with circuits,
D. H. Wolpert and A. Kolchinsky, “Thermodynamics of computing with circuits,”New Journal of Physics, vol. 22, no. 6, p. 063047, jun 2020. [Online]. Available: https://doi.org/10.1088/1367-2630/ab82b8
-
[76]
BFloat16: The secret to high performance on Cloud TPUs — Google Cloud Blog — cloud.google.com,
“BFloat16: The secret to high performance on Cloud TPUs — Google Cloud Blog — cloud.google.com,” https://cloud. google.com/blog/products/ai-machine-learning/bfloat16-the-secret-to-high-performance-on-cloud-tpus, [Accessed 01-12- 2025]
work page 2025
-
[77]
A. Gholami, S. Kim, Z. Dong, Z. Yao, M. W. Mahoney, and K. Keutzer, “A survey of quantization methods for efficient neural network inference,” 2021. [Online]. Available: https://arxiv.org/abs/2103.13630
-
[78]
Deep Learning with Limited Numerical Precision
S. Gupta, A. Agrawal, K. Gopalakrishnan, and P. Narayanan, “Deep learning with limited numerical precision,” 2015. [Online]. Available: https://arxiv.org/abs/1502.02551
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[79]
Quantizing deep convolutional networks for efficient inference: A whitepaper
R. Krishnamoorthi, “Quantizing deep convolutional networks for efficient inference: A whitepaper,” 2018. [Online]. Available: https://arxiv.org/abs/1806.08342
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[80]
Efqat: An efficient framework for quantization-aware training,
S. Ashkboos, B. Verhoef, T. Hoefler, E. Eleftheriou, and M. Dazzi, “Efqat: An efficient framework for quantization-aware training,”CoRR, vol. abs/2411.11038, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2411.11038
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.