Agentic Trading: When LLM Agents Meet Financial Markets
Pith reviewed 2026-05-20 05:59 UTC · model grok-4.3
The pith
Studies on LLM trading agents use evaluation protocols so inconsistent that direct comparison and reproduction are nearly impossible.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Within the primary subset of 19 studies, only 2/19 report extractable time-consistent split protocols, 1/19 reports an explicit transaction-cost model, 1/19 documents universe or survivorship handling, 11/19 report execution timing or semantics, 15/19 are coded as R0, and no study reaches R3 reproducibility. Architectural experimentation is expanding rapidly, while comparable evaluation protocols, execution semantics, and reproducible artifacts remain the field's immediate bottlenecks.
What carries the argument
The protocol-coded snapshot and reproducibility audit applied to the 77 studies, using Architecture-Capability-Adaptation as a working analytical lens.
If this is right
- Without time-consistent splits, performance numbers across different agent designs cannot be compared fairly.
- Absence of explicit transaction-cost models means reported returns do not reflect realistic net performance.
- Lack of documented universe or survivorship handling introduces hidden selection bias into every result.
- The proposed reporting checklist would allow future studies to reach higher reproducibility tiers.
Where Pith is reading between the lines
- Standardized split and cost protocols would turn the current set of incomparable experiments into a cumulative body of evidence.
- Adoption of the audit framework could serve as a template for evaluating agentic systems in other high-stakes domains such as portfolio allocation or risk management.
Load-bearing premise
The screening and coding protocol applied to the 77 studies accurately and without selection bias captures the evaluation practices of the broader literature on LLM trading agents.
What would settle it
A re-screening and re-coding of the same or updated literature that finds substantially more than 2/19 studies with extractable time-consistent splits or at least one study reaching R3 reproducibility.
Figures













read the original abstract
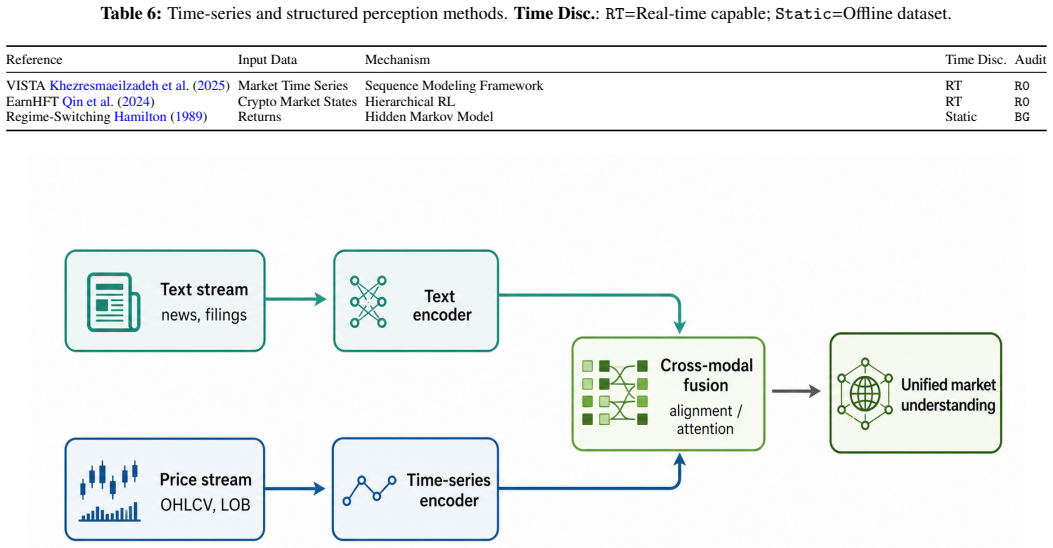
A growing body of work explores how Large Language Models (LLMs) can be embedded in trading systems as agents that perceive market information, retrieve context, reason about decisions, emit tradable actions, and adapt under market feedback. This paper reframes LLM-based trading agents as expert-system decision pipelines and presents an audit-oriented evidence map of 77 included studies in a protocol-coded snapshot screened through 2026-03-09. A primary empirical subset (n=19) satisfies the minimum boundary of Action Output plus Closed-Loop Evaluation; the remaining 58 included studies are retained as background and design context. The central empirical finding is protocol incomparability: within the primary subset, only 2/19 studies report extractable time-consistent split protocols, 1/19 reports an explicit transaction-cost model, 1/19 documents universe or survivorship handling, 11/19 report execution timing or semantics, 15/19 are coded as R0, and no study reaches R3 reproducibility. We therefore use Architecture-Capability-Adaptation as a working analytical lens rather than a validated taxonomy, and we foreground the evidence ledger, reproducibility audit, and reporting checklist as the main contributions. The resulting survey shows that architectural experimentation is expanding rapidly, while comparable evaluation protocols, execution semantics, and reproducible artifacts remain the field's immediate bottlenecks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript audits 77 studies on LLM agents in trading systems, screened through 2026-03-09. It isolates a primary subset of 19 studies meeting the criteria of Action Output plus Closed-Loop Evaluation and reports protocol incomparability: only 2/19 provide extractable time-consistent split protocols, 1/19 an explicit transaction-cost model, 1/19 documents universe/survivorship handling, 11/19 report execution timing/semantics, 15/19 are R0, and none reach R3 reproducibility. The paper positions Architecture-Capability-Adaptation as an analytical lens and contributes an evidence ledger, reproducibility audit, and reporting checklist.
Significance. If the screening and coding hold, the audit usefully documents evaluation gaps in an emerging area where architectural work is expanding quickly. The reproducibility audit and checklist offer concrete tools that could raise standards for comparability and artifact sharing, which are currently the field's main bottlenecks.
major comments (2)
- [Methods / Screening Protocol] Methods (screening and coding protocol): The exact operational definition of 'Action Output plus Closed-Loop Evaluation' used to select the n=19 primary subset from 77 studies, together with the full coding rubric for time-consistent splits, transaction-cost models, universe handling, and R-level reproducibility, must be supplied (including any inter-rater checks). These details are load-bearing for the headline fractions (2/19, 1/19, 0/19 for R3) that support the central claim of protocol incomparability.
- [Results / Primary Subset Analysis] Results (primary-subset counts): The term 'extractable' in the statement that only 2/19 studies report extractable time-consistent split protocols requires an explicit definition and at least one worked example from the coded studies. Without it, the 2/19 figure cannot be independently verified and the incomparability conclusion rests on an opaque threshold.
minor comments (2)
- [Abstract] Abstract: the screening date '2026-03-09' appears to be in the future; confirm whether this is a typographical error or a planned cutoff.
- [Figure 1] Figure 1 (publication timeline): add axis labels and a legend distinguishing the primary subset from the background studies for immediate readability.
Simulated Author's Rebuttal
We are grateful to the referee for their thorough review and valuable suggestions. We respond to each major comment in turn and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Methods / Screening Protocol] Methods (screening and coding protocol): The exact operational definition of 'Action Output plus Closed-Loop Evaluation' used to select the n=19 primary subset from 77 studies, together with the full coding rubric for time-consistent splits, transaction-cost models, universe handling, and R-level reproducibility, must be supplied (including any inter-rater checks). These details are load-bearing for the headline fractions (2/19, 1/19, 0/19 for R3) that support the central claim of protocol incomparability.
Authors: We agree that these methodological details are essential for allowing readers to verify our audit process and conclusions. In the revised manuscript, we will expand the Methods section to provide the precise operational definition of 'Action Output plus Closed-Loop Evaluation', which we used to filter the primary subset of 19 studies from the 77 included ones. We will also include the complete coding rubric as an appendix, detailing the criteria applied for assessing time-consistent splits, transaction-cost models, universe and survivorship handling, execution timing, and the R-level reproducibility scale. For inter-rater reliability, the coding was performed primarily by the first author with review by co-authors for ambiguous cases, and we will document this process explicitly in the revision. These changes will make the headline statistics fully traceable. revision: yes
-
Referee: [Results / Primary Subset Analysis] Results (primary-subset counts): The term 'extractable' in the statement that only 2/19 studies report extractable time-consistent split protocols requires an explicit definition and at least one worked example from the coded studies. Without it, the 2/19 figure cannot be independently verified and the incomparability conclusion rests on an opaque threshold.
Authors: We concur that an explicit definition of 'extractable' is necessary to support independent verification. We define 'extractable time-consistent split protocols' as reporting practices that include enough specific information—such as exact date ranges, period lengths, or references to code that implements the split—to enable a reader to recreate the same temporal division without introducing lookahead bias or ambiguity. In the revised manuscript, we will add this definition to the Results section. Additionally, we will provide a worked example from one of the two studies that met this standard, illustrating how their reported split protocol satisfies the criteria. This will clarify the basis for the 2/19 count and reinforce the protocol incomparability finding. revision: yes
Circularity Check
Observational audit of external literature with no self-referential derivation
full rationale
The paper conducts a protocol-coded audit of 77 external studies on LLM trading agents, identifying a primary subset of 19 and reporting direct counts on their evaluation practices (e.g., 2/19 with time-consistent splits). No equations, parameter fits, predictions, or self-citations are invoked to derive these counts; findings are presented as empirical observations from screened literature. The methodology relies on external benchmarks (published papers) rather than reducing to the paper's own inputs by construction. This matches the default case of a self-contained observational study against external data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A protocol-coded snapshot screened through a fixed date can reliably classify studies into primary empirical and background categories without material selection bias.
Reference graph
Works this paper leans on
-
[1]
Stride: A systematic framework for selecting ai modalities – agentic ai, ai assistants, or llm calls. arXiv preprint arXiv:2512.02228 URL: https://arxiv.org/ab s/2512.02228, doi:10.48550/arXiv.2512.02228. Atkinson, R.C., Shiffrin, R.M., 1968. Human memory: A proposed system and its control processes, in: Spence, K.W., Spence, J.T. (Eds.), The Psychology o...
-
[2]
Pseudo-mathematics and financial charlatanism: The effects of backtest overfitting. SSRN Electronic Journal URL: https://papers.ssrn.com/sol3/papers.cfm?abstra ct_id=2326253, doi:10.2139/ssrn.2326253. Baker, S.R., Bloom, N., Davis, S.J., 2016. Measuring economic policy uncertainty. The Quarterly Journal of Economics 131, 1593–1636. URL: https://doi.org/10...
-
[3]
URL: https://doi.org/10.1093/qje/qjv027 , doi:10.1093/qje/qjv027. Byun, W., 2023. Practical application of deep reinforcement learning to optimal trade execution. FinTech 2, 414–429. URL: https://www.mdpi.com/2674- 1032/2/3/23 , doi:10.3390/fintech2030023. Caner, M., Fan, Q., 2024. Portfolio analysis in high dimensions with tracking error and weight const...
-
[5]
Cook, T., Osuagwu, R., Tsatiashvili, L., Vrynsia, V ., Ghosal, K., Masoud, M., Mattivi, R., 2025
URL: https://doi.org/10.1086/261412 , doi:10.1086/261412. Cook, T., Osuagwu, R., Tsatiashvili, L., Vrynsia, V ., Ghosal, K., Masoud, M., Mattivi, R., 2025. Retrieval augmented generation (rag) for fintech: Agentic design and evaluation. arXiv preprint arXiv:2510.25518 URL: https://arxiv.or g/abs/2510.25518, doi:10.48550/arXiv.2510.25518. Coriat, B., Benha...
-
[6]
nl2spec: Interactively translating unstructured natural language to temporal logics with large language models, in: Computer Aided Verification (CA V 2023), pp. 383–
work page 2023
-
[7]
Davis, M.H.A., Norman, A.R., 1990
URL: https://arxiv.org/abs/2303.04864 , doi:10.1007/978-3-031-37703-7_18. Davis, M.H.A., Norman, A.R., 1990. Portfolio selection with transaction costs. Mathematics of Operations Research 15, 676–713. URL: https://doi.org/10.1287/moor.15.4. 676, doi:10.1287/moor.15.4.676. Deng, K., 2025. Autoquant: An auditable expert-system frame- work for execution-cons...
-
[9]
Bandit Based Monte- Carlo Planning,
URL: https://doi.org/10.1007/11871842_29 , doi:10.1007/11871842_29. Kou, Z., Yu, H., Luo, J., Peng, J., Li, X., Liu, C., Dai, J., Chen, L., Han, S., Guo, Y ., 2025. Automate strategy finding with llm in quant investment, in: Findings of the Association for Computational Linguistics: EMNLP 2025, Suzhou, China. URL: https://aclanthology.org/2025.findings-e ...
-
[10]
Cognitive Alpha Mining via LLM-Driven Code-Based Evolution
URL: https://www.mdpi.com/2079-9292/11/2 2/3701, doi:10.3390/electronics11223701. 53 Liu, F., Yi, H., Luo, S., Wang, Y ., Yang, Y ., Li, X., Hu, Z., Feng, J., Liu, Q., 2025. Cognitive alpha mining via llm-driven code-based evolution. arXiv preprint arXiv:2511.18850 URL: https://arxiv.org/html/2511.18850v1. Liu, N.F., Lin, K., Hewitt, J., Paranjape, A., Be...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.3390/electronics11223701 2079
-
[11]
Fintoolbench: Evaluating llm agents for real-world financial tool use. arXiv preprint arXiv:2603.08262v1 URL: https://arxiv.org/pdf/2603.08262v1. Lundberg, S.M., Lee, S.I., 2017. A unified approach to interpreting model predictions, in: Advances in Neural Information Processing Systems (NeurIPS). URL: https: //arxiv.org/abs/1705.07874. Luo, H., Zhang, Y ....
work page doi:10.48550/a 2017
-
[12]
arXiv preprint arXiv:2602.20493v1 URL: https://arxiv.or g/pdf/2602.20493v1
Awcp: A workspace delegation protocol for deep- engagement collaboration across remote agents. arXiv preprint arXiv:2602.20493v1 URL: https://arxiv.or g/pdf/2602.20493v1. Nitarach, N., Sirichotedumrong, W., Pitchayarthorn, P., Taveek- itworachai, P., Manakul, P., Pipatanakul, K., 2025. Fin- cot: Grounding chain-of-thought in expert financial reason- ing, ...
-
[13]
Papadakis, C., Filandrianos, G., Dimitriou, A., Lymperaiou, M., Thomas, K., Stamou, G., 2025
URL: https://ieeexplore.ieee.org/document /5288526, doi:10.1109/TKDE.2009.191. Papadakis, C., Filandrianos, G., Dimitriou, A., Lymperaiou, M., Thomas, K., Stamou, G., 2025. Stocksim: A dual-mode order- level simulator for evaluating multi-agent llms in financial markets. URL: https://arxiv.org/abs/2507.09255 , doi:10.48550/arXiv.2507.09255,arXiv:2507.0925...
-
[14]
Finevo: From isolated backtests to ecological market games for multi-agent financial strategy evolution. arXiv preprint arXiv:2602.00948 URL: https://arxiv.org/ab s/2602.00948, doi:10.48550/arXiv.2602.00948. Zouaoui, H., Naas, M.N., 2025. Portfolio optimization based on mpt-lstm neural networks: A case study of cryptocurrency markets. Finance, Accounting ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.