Cognitive Alpha Mining via LLM-Driven Code-Based Evolution
Pith reviewed 2026-05-17 06:40 UTC · model grok-4.3
The pith
LLM agents evolve code representations of financial prediction formulas to discover alphas that generalize better across markets than prior methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CogAlpha treats LLMs as adaptive cognitive agents that iteratively refine code-based alpha candidates via multi-stage prompts and financial feedback, enabling broader structured exploration of the alpha space and yielding formulas with superior predictive accuracy, robustness, and generalization compared to existing neural, genetic, or LLM-based baselines.
What carries the argument
The Cognitive Alpha Mining Framework (CogAlpha), which represents alphas as code and drives their evolution through LLM-based reasoning, mutation, recombination, and multi-stage financial feedback prompts.
If this is right
- Alphas produced will be directly executable and economically interpretable because they are expressed as code rather than opaque weights or redundant formulas.
- The effective search space expands because LLM reasoning supports both logical consistency and creative recombination beyond what fixed genetic operators or neural architectures allow.
- Performance gains in accuracy and robustness should appear across different stock markets when the evolutionary loop incorporates real financial metrics as feedback.
- The method supports automated, explainable alpha discovery that can be iterated without manual feature engineering.
Where Pith is reading between the lines
- Similar LLM-driven code evolution could be tested on non-financial time-series prediction tasks that also suffer from low signal-to-noise ratios.
- Combining the framework with real-time market data streams might allow continuous alpha adaptation rather than batch discovery.
- The code representation opens the possibility of hybrid systems that mix LLM-generated alphas with human-designed constraints for regulatory compliance.
Load-bearing premise
The multi-stage LLM prompts and financial feedback will generate alphas that capture genuine market signals rather than overfitting to the specific training periods or prompt patterns in the experiments.
What would settle it
Re-running the alpha discovery on the same training windows and then measuring whether the resulting formulas lose all performance advantage on held-out data from entirely new time periods or a fourth market not used in the original tests.
Figures


read the original abstract
Discovering effective predictive signals, or "alphas," from financial data with high dimensionality and extremely low signal-to-noise ratio remains a difficult open problem. Despite progress in deep learning, genetic programming, and, more recently, large language model (LLM)-based factor generation, existing approaches still explore only a narrow region of the vast alpha search space. Neural models tend to produce opaque and fragile patterns, while symbolic or formula-based methods often yield redundant or economically ungrounded expressions that generalize poorly. Although different in form, these paradigms share a key limitation: none can conduct broad, structured, and human-like exploration that balances logical consistency with creative leaps. To address this gap, we introduce the Cognitive Alpha Mining Framework (CogAlpha), which combines code-level alpha representation with LLM-driven reasoning and evolutionary search. Treating LLMs as adaptive cognitive agents, our framework iteratively refines, mutates, and recombines alpha candidates through multi-stage prompts and financial feedback. This synergistic design enables deeper thinking, richer structural diversity, and economically interpretable alpha discovery, while greatly expanding the effective search space. Experiments on 5 stock datasets from 3 stock markets demonstrate that CogAlpha consistently discovers alphas with superior predictive accuracy, robustness, and generalization over existing methods. Our results highlight the promise of aligning evolutionary optimization with LLM-based reasoning for automated and explainable alpha discovery.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Cognitive Alpha Mining Framework (CogAlpha), which treats LLMs as adaptive cognitive agents to iteratively refine, mutate, and recombine code-based alpha candidates via multi-stage prompts and financial feedback loops. This is positioned as expanding the search space beyond neural or traditional symbolic methods while improving interpretability. Experiments on 5 stock datasets from 3 markets are reported to show consistent superiority in predictive accuracy, robustness, and generalization over baselines.
Significance. If the generalization results hold under rigorous temporal controls, the work offers a concrete advance in automated alpha discovery by aligning LLM reasoning with evolutionary optimization. The code-level representation and feedback-driven iteration provide a structured way to balance logical consistency with creative exploration, which could influence both quantitative finance and LLM-agent research. The empirical outperformance on multiple markets is a positive signal, though its durability depends on the experimental controls.
major comments (2)
- [§5] §5 (Experiments): The central generalization claim requires explicit documentation of temporal train/test splits and confirmation that the evolutionary loop had no access to future data or test-set information. Stock returns are non-stationary; without these details (including any regime-shift handling or walk-forward validation), the reported robustness and out-of-sample superiority cannot be fully evaluated.
- [§4] §4 (Framework): The multi-stage prompt and financial-feedback design is load-bearing for the claimed expansion of search space, yet no ablation isolating the contribution of LLM reasoning stages versus simple mutation/recombination is presented. This leaves open whether the performance gains stem from the cognitive-agent framing or from broader search enabled by code representation alone.
minor comments (3)
- Notation for alpha expressions in tables could be clarified with explicit variable definitions to aid reproducibility.
- Figure captions should state the exact evaluation metric (e.g., IC, rank IC) and whether results are averaged over seeds.
- A few citations to classic factor literature (e.g., Fama-French) appear missing in the related-work section.
Simulated Author's Rebuttal
We thank the referee for their constructive and insightful comments, which help clarify key aspects of our work on the Cognitive Alpha Mining Framework (CogAlpha). We address each major comment point by point below, providing the strongest honest defense of the manuscript while committing to revisions that strengthen the presentation of our experimental controls and framework contributions.
read point-by-point responses
-
Referee: [§5] §5 (Experiments): The central generalization claim requires explicit documentation of temporal train/test splits and confirmation that the evolutionary loop had no access to future data or test-set information. Stock returns are non-stationary; without these details (including any regime-shift handling or walk-forward validation), the reported robustness and out-of-sample superiority cannot be fully evaluated.
Authors: We agree that explicit documentation of temporal train/test splits and safeguards against future data leakage is essential for rigorously evaluating generalization claims in non-stationary financial time series. The original manuscript described the five datasets, markets, and high-level evaluation protocol in §5, including out-of-sample testing, but we acknowledge that finer-grained details on split dates, access restrictions, and validation procedures would strengthen the robustness claims. In the revised version, we will add a dedicated paragraph (or subsection) in §5 that: (i) specifies the exact temporal splits for each dataset (e.g., training up to a cutoff date with subsequent test periods and no overlap), (ii) explicitly confirms that the evolutionary search, LLM prompts, and financial feedback operated solely on in-sample training data with no access to test-set information or future returns, and (iii) discusses any regime-shift handling or walk-forward elements used. These additions will allow readers to fully assess the reported out-of-sample superiority without altering the core results. revision: yes
-
Referee: [§4] §4 (Framework): The multi-stage prompt and financial-feedback design is load-bearing for the claimed expansion of search space, yet no ablation isolating the contribution of LLM reasoning stages versus simple mutation/recombination is presented. This leaves open whether the performance gains stem from the cognitive-agent framing or from broader search enabled by code representation alone.
Authors: We recognize the value of isolating the contribution of the multi-stage LLM reasoning and financial-feedback components versus simpler code-level mutation and recombination. While the code representation itself expands the search space beyond traditional symbolic or neural methods, the multi-stage prompts are specifically engineered to enable iterative, domain-informed reasoning, logical consistency checks, and creative yet grounded recombination that random mutations alone would not produce. To directly address this concern, we will incorporate an ablation study in the revised manuscript. This will compare the full CogAlpha framework against a stripped-down variant relying only on basic code mutation/recombination without the cognitive multi-stage prompts or financial feedback loops. The ablation results will be added to §5 (or a new subsection), quantifying the incremental benefit attributable to the LLM-driven cognitive stages and thereby clarifying the source of the observed performance gains. revision: yes
Circularity Check
No circularity: empirical experimental validation of LLM-driven framework
full rationale
The paper introduces CogAlpha as an empirical framework combining LLM reasoning with code-based evolutionary search for alpha discovery, then validates it via experiments on five stock datasets across three markets. No derivation chain, equations, or first-principles claims appear that reduce by construction to fitted inputs, self-definitions, or self-citation load-bearing premises. Performance claims rest on direct experimental comparisons rather than renaming known results or smuggling ansatzes; the method is self-contained as a practical search procedure whose outputs are assessed externally against baselines.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce the Cognitive Alpha Mining Framework (CogAlpha), which combines code-level alpha representation with LLM-driven reasoning and evolutionary search... Experiments on 5 stock datasets... superior predictive accuracy, robustness, and generalization
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Thinking Evolution implements a genetic-style optimization process in natural language space, where candidate alpha codes undergo mutation and crossover operations expressed through textual prompts
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Agentic Trading: When LLM Agents Meet Financial Markets
A protocol-coded audit of 77 LLM trading agent studies shows that only 2 of 19 primary empirical papers report time-consistent data splits and none reach high reproducibility standards.
Reference graph
Works this paper leans on
-
[1]
Robert F Engle. Autoregressive conditional heteroscedasticity with estimates of the variance of united kingdom inflation.Econometrica: Journal of the econometric society, pages 987–1007, 1982
work page 1982
-
[2]
Jian Guo, Saizhuo Wang, Lionel M Ni, and Heung-Yeung Shum. Quant 4.0: engineering quan- titative investment with automated, explainable, and knowledge-driven artificial intelligence. Frontiers of Information Technology & Electronic Engineering, 25(11):1421–1445, 2024
work page 2024
-
[3]
The cross-section of expected stock returns.the Journal of Finance, 47(2):427–465, 1992
Eugene F Fama and Kenneth R French. The cross-section of expected stock returns.the Journal of Finance, 47(2):427–465, 1992
work page 1992
-
[4]
and the cross-section of expected returns
Campbell R Harvey, Yan Liu, and Heqing Zhu. . . . and the cross-section of expected returns. The Review of Financial Studies, 29(1):5–68, 2016
work page 2016
-
[5]
Kewei Hou, Chen Xue, and Lu Zhang. Replicating anomalies. Technical report, National Bureau of Economic Research, 2017
work page 2017
-
[6]
Yitong Duan, Lei Wang, Qizhong Zhang, and Jian Li. Factorvae: A probabilistic dynamic factor model based on variational autoencoder for predicting cross-sectional stock returns. In Proceedings of the AAAI conference on artificial intelligence, volume 36, pages 4468–4476, 2022
work page 2022
-
[7]
Wentao Xu, Weiqing Liu, Lewen Wang, Yingce Xia, Jiang Bian, Jian Yin, and Tie-Yan Liu. Hist: A graph-based framework for stock trend forecasting via mining concept-oriented shared information.arXiv preprint arXiv:2110.13716, 2021
-
[8]
Rest: Relational event-driven stock trend forecasting
Wentao Xu, Weiqing Liu, Chang Xu, Jiang Bian, Jian Yin, and Tie-Yan Liu. Rest: Relational event-driven stock trend forecasting. InProceedings of the web conference 2021, pages 1–10, 2021. 10
work page 2021
-
[9]
Tianping Zhang, Yuanqi Li, Yifei Jin, and Jian Li. Autoalpha: an efficient hierarchical evolutionary algorithm for mining alpha factors in quantitative investment.arXiv preprint arXiv:2002.08245, 2020
-
[10]
Openfe: Automated feature generation with expert-level performance
Tianping Zhang, Zheyu Aqa Zhang, Zhiyuan Fan, Haoyan Luo, Fengyuan Liu, Qian Liu, Wei Cao, and Li Jian. Openfe: Automated feature generation with expert-level performance. In International Conference on Machine Learning, pages 41880–41901. PMLR, 2023
work page 2023
-
[11]
Alphae- volve: A learning framework to discover novel alphas in quantitative investment
Can Cui, Wei Wang, Meihui Zhang, Gang Chen, Zhaojing Luo, and Beng Chin Ooi. Alphae- volve: A learning framework to discover novel alphas in quantitative investment. InProceedings of the 2021 International conference on management of data, pages 2208–2216, 2021
work page 2021
-
[12]
Stock alpha mining based on genetic algorithm
Xiaoming Lin, Ye Chen, Ziyu Li, and Kang He. Stock alpha mining based on genetic algorithm. Technical Report, Huatai Securities Research Center, 2019
work page 2019
-
[13]
Rahul Ramesh Patil. Ai-infused algorithmic trading: Genetic algorithms and machine learning in high-frequency trading.International Journal For Multidisciplinary Research, 5(5), 2023
work page 2023
-
[14]
Age-fitness pareto optimization
Michael D Schmidt and Hod Lipson. Age-fitness pareto optimization. InProceedings of the 12th annual conference on Genetic and evolutionary computation, pages 543–544, 2010
work page 2010
-
[15]
Genetic algorithm based quantitative factors construction
Zhaofan Su, Jianwu Lin, and Chengshan Zhang. Genetic algorithm based quantitative factors construction. In2022 IEEE 20th International Conference on Industrial Informatics (INDIN), pages 650–655. IEEE, 2022
work page 2022
-
[16]
Finrl: Deep reinforce- ment learning framework to automate trading in quantitative finance
Xiao-Yang Liu, Hongyang Yang, Jiechao Gao, and Christina Dan Wang. Finrl: Deep reinforce- ment learning framework to automate trading in quantitative finance. InProceedings of the second ACM international conference on AI in finance, pages 1–9, 2021
work page 2021
-
[17]
Generating synergistic formulaic alpha collections via reinforcement learning
Shuo Yu, Hongyan Xue, Xiang Ao, Feiyang Pan, Jia He, Dandan Tu, and Qing He. Generating synergistic formulaic alpha collections via reinforcement learning. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 5476–5486, 2023
work page 2023
-
[18]
Alphaforge: A framework to mine and dynamically combine formulaic alpha factors
Hao Shi, Weili Song, Xinting Zhang, Jiahe Shi, Cuicui Luo, Xiang Ao, Hamid Arian, and Luis Angel Seco. Alphaforge: A framework to mine and dynamically combine formulaic alpha factors. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 12524–12532, 2025
work page 2025
-
[19]
R&d- agent-quant: A multi-agent framework for data-centric factors and model joint optimization
Yuante Li, Xu Yang, Xiao Yang, Minrui Xu, Xisen Wang, Weiqing Liu, and Jiang Bian. R&d- agent-quant: A multi-agent framework for data-centric factors and model joint optimization. arXiv preprint arXiv:2505.15155, 2025
-
[20]
Yu Shi, Yitong Duan, and Jian Li. Navigating the alpha jungle: An llm-powered mcts framework for formulaic factor mining.arXiv preprint arXiv:2505.11122, 2025
-
[21]
Ziyi Tang, Zechuan Chen, Jiarui Yang, Jiayao Mai, Yongsen Zheng, Keze Wang, Jinrui Chen, and Liang Lin. Alphaagent: Llm-driven alpha mining with regularized exploration to counteract alpha decay.arXiv preprint arXiv:2502.16789, 2025
-
[22]
Automate strategy finding with llm in quant investment.arXiv preprint arXiv:2409.06289, 2024
Zhizhuo Kou, Holam Yu, Junyu Luo, Jingshu Peng, Xujia Li, Chengzhong Liu, Juntao Dai, Lei Chen, Sirui Han, and Yike Guo. Automate strategy finding with llm in quant investment.arXiv preprint arXiv:2409.06289, 2024
-
[23]
Evolving deeper llm thinking.arXiv preprint arXiv:2501.09891, 2025
Kuang-Huei Lee, Ian Fischer, Yueh-Hua Wu, Dave Marwood, Shumeet Baluja, Dale Schu- urmans, and Xinyun Chen. Evolving deeper llm thinking.arXiv preprint arXiv:2501.09891, 2025
-
[24]
Wizardlm: Empowering large pre-trained language models to follow complex instructions
Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, Qing- wei Lin, and Daxin Jiang. Wizardlm: Empowering large pre-trained language models to follow complex instructions. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[25]
Connecting large language models with evolutionary algorithms yields powerful prompt optimizers
Qingyan Guo, Rui Wang, Junliang Guo, Bei Li, Kaitao Song, Xu Tan, Guoqing Liu, Jiang Bian, and Yujiu Yang. Connecting large language models with evolutionary algorithms yields powerful prompt optimizers. InThe Twelfth International Conference on Learning Representations, 2024. 11
work page 2024
-
[26]
Mathematical discoveries from program search with large language models
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M Pawan Kumar, Emilien Dupont, Francisco JR Ruiz, Jordan S Ellenberg, Pengming Wang, Omar Fawzi, et al. Mathematical discoveries from program search with large language models. Nature, 625(7995):468–475, 2024
work page 2024
-
[27]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Alexander Novikov, Ngân V˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco JR Ruiz, Abbas Mehrabian, et al. Alphaevolve: A coding agent for scientific and algorithmic discovery.arXiv preprint arXiv:2506.13131, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Le Xiao and Xiaolin Chen. Enhancing llm with evolutionary fine tuning for news summary generation.arXiv preprint arXiv:2307.02839, 2023
-
[29]
Llm-aided evolutionary algorithms for haiku generation
Vedant Dhaval Jobanputra, Basam Thilaknath Reddy, Sri Ganesh Bhojanapalli, Krishna Aditya SV S, Bagavathi Chandrasekara, and Ritwik Murali. Llm-aided evolutionary algorithms for haiku generation. InProceedings of the Genetic and Evolutionary Computation Conference Companion, pages 2584–2587, 2025
work page 2025
-
[30]
Enhancing large language models-based code generation by leveraging genetic improvement
Giovanni Pinna, Damiano Ravalico, Luigi Rovito, Luca Manzoni, and Andrea De Lorenzo. Enhancing large language models-based code generation by leveraging genetic improvement. InEuropean Conference on Genetic Programming (Part of EvoStar), pages 108–124. Springer, 2024
work page 2024
-
[31]
Evolving code with a large language model.Genetic Programming and Evolvable Machines, 25(2):21, 2024
Erik Hemberg, Stephen Moskal, and Una-May O’Reilly. Evolving code with a large language model.Genetic Programming and Evolvable Machines, 25(2):21, 2024
work page 2024
-
[32]
gpt-oss-120b & gpt-oss-20b Model Card
OpenAI. GPT-OSS-120B & GPT-OSS-20B model card.arXiv preprint arXiv:2508.10925, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. Lightgbm: A highly efficient gradient boosting decision tree.Advances in neural information processing systems, 30, 2017
work page 2017
-
[34]
Random forests.Machine learning, 45(1):5–32, 2001
Leo Breiman. Random forests.Machine learning, 45(1):5–32, 2001
work page 2001
-
[35]
Xgboost: A scalable tree boosting system
Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system. InProceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, pages 785–794, 2016
work page 2016
-
[36]
Liudmila Prokhorenkova, Gleb Gusev, Aleksandr V orobev, Anna Veronika Dorogush, and Andrey Gulin. Catboost: unbiased boosting with categorical features.Advances in neural information processing systems, 31, 2018
work page 2018
-
[37]
Yoav Freund and Robert E Schapire. A decision-theoretic generalization of on-line learning and an application to boosting.Journal of computer and system sciences, 55(1):119–139, 1997
work page 1997
-
[38]
Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
Kyunghyun Cho, Bart Van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using rnn encoder- decoder for statistical machine translation.arXiv preprint arXiv:1406.1078, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[39]
Long short-term memory.Neural computation, 9(8):1735–1780, 1997
Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory.Neural computation, 9(8):1735–1780, 1997
work page 1997
-
[40]
Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 2002
work page 2002
-
[41]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
work page 2017
-
[42]
Microsoft. Alpha 158 from microsoft qlib. https://github.com/microsoft/qlib/blob/ 85cc74846b5af2e3e6d18666a2f6e399396980b9/qlib/contrib/data/loader.py# L61, 2025. Accessed: 2025-05-12. 12
work page 2025
-
[43]
Microsoft. Alpha 360 from microsoft qlib. https://github.com/microsoft/qlib/blob/ 85cc74846b5af2e3e6d18666a2f6e399396980b9/qlib/contrib/data/loader.py#L4,
-
[44]
Accessed: 2025-05-12
work page 2025
-
[45]
Introducing GPT-4.1 in the api
OpenAI. Introducing GPT-4.1 in the api. https://openai.com/index/gpt-4-1/, April
-
[46]
Accessed: 2025-11-11
work page 2025
-
[47]
OpenAI. Introducing deep research. https://openai.com/index/ introducing-deep-research/, August 2025. Accessed: 2025-09-24
work page 2025
-
[48]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Albert S Kyle. Continuous auctions and insider trading.Econometrica: Journal of the Econometric Society, pages 1315–1335, 1985
work page 1985
-
[50]
Yakov Amihud. Illiquidity and stock returns: cross-section and time-series effects.Journal of financial markets, 5(1):31–56, 2002
work page 2002
-
[51]
np":import numpy as np(numpy version: 2.2.6) •
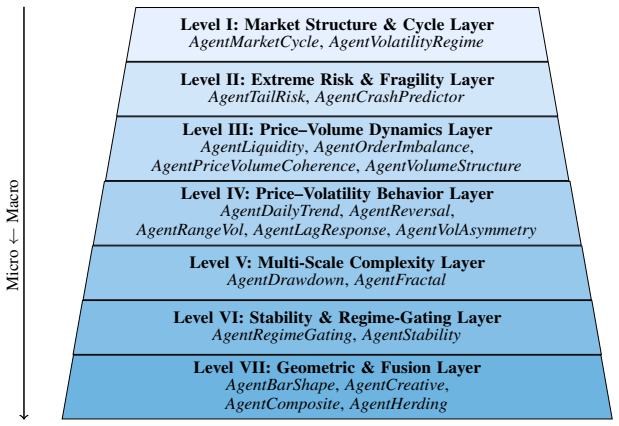
Xiao Yang, Weiqing Liu, Dong Zhou, Jiang Bian, and Tie-Yan Liu. Qlib: An ai-oriented quantitative investment platform.arXiv preprint arXiv:2009.11189, 2020. A Approach A.1 Seven-Level Agent Hierarchy Table 3: Seven-Level Agent Hierarchy of COGALPHAand their corresponding conceptual focuses. Level Layer Name Description I Market Structure & Cycle Layer Exp...
-
[52]
Does the factor have anyfuture information leakage?
-
[53]
Is the factor calculationcorrect and internally consistent?
-
[54]
Is the factor logiceconomically interpretable(even if exploratory or novel)?
-
[55]
Does the factor avoid obviouserrors(such as invalid operations, unprotected division by zero, undefined results)?
-
[56]
Is the factorefficiently implemented(avoids unnecessary loops, leverages vector- ized operations, and is suitable for large-scale backtesting)?
-
[57]
Does the factor strictlyavoid any nested loops or potentially infinite loops? • Nested loops areforbiddenat any depth: –forinsidefor –whileinsidewhile –forinsidewhile –whileinsidefor • The use ofwhile Trueor any loop that can run indefinitely isprohibited. — ### Factor under review: «function» {code} «/function» The input DataFrame has a MultiIndex of (da...
-
[58]
It is economically and financially interpretable
-
[59]
It is logically sound according to financial principles
-
[60]
np":import numpy as np(numpy version: 2.2.6) •
It addresses the specific feedback provided below. — ### Original function: «previous function» {old_code} «/previous function» — ### Hard Complexity Constraints (must-follow) Remember:Simple factors are often the most powerful and stable. • Single theme, minimal path: each factor must represent one clear idea. • Hard cap: never exceed 5 logical steps in ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.