Backtracking When It Strays: Mitigating Dual Exposure Biases in LLM Reasoning Distillation
Pith reviewed 2026-05-20 06:19 UTC · model grok-4.3
The pith
MOTAB uses backtracking and teacher intervention on straying student trajectories to fix dual exposure biases in LLM reasoning distillation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MOTAB dynamically monitors the student's on-policy generation against an adaptive safety boundary; when the generation strays and exceeds this threshold, MOTAB backtracks to the last safe state and leverages teacher intervention to correct the course, thereby mitigating both the standard exposure bias of off-policy distillation and the reversed exposure bias of on-policy distillation.
What carries the argument
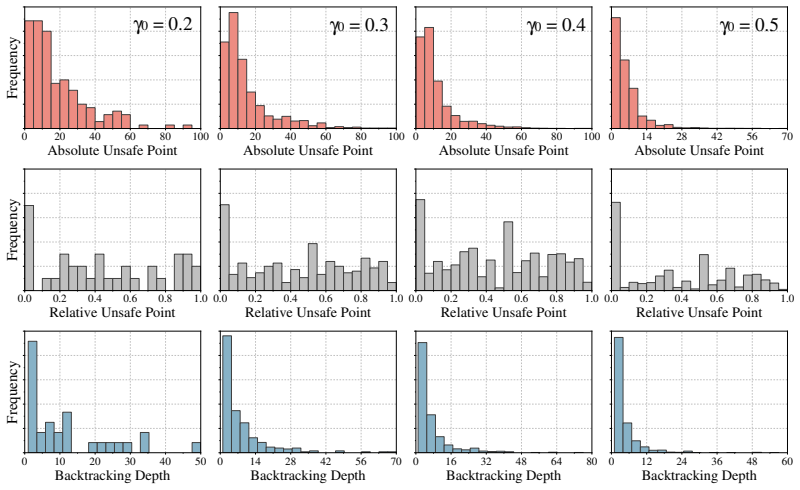
The MOTAB pipeline, which defines an adaptive safety boundary during on-policy student generation and triggers backtracking plus teacher correction when that boundary is crossed.
Load-bearing premise
An adaptive safety boundary can be defined such that backtracking to the last safe state and teacher intervention corrects the course without introducing significant new biases or excessive computational overhead.
What would settle it
Training the same student models with standard on-policy distillation on LIMO-v2 and AceReason and measuring whether the reported three percent average gain disappears.
Figures
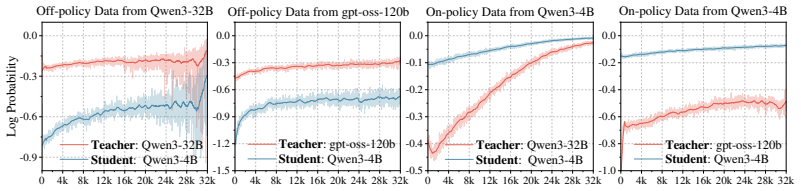






read the original abstract
Large language models (LLMs) have achieved remarkable success in complex reasoning tasks via long chain-of-thought (CoT), yet their immense computational overhead hinders real-world deployment. LLM reasoning distillation addresses this by transferring reasoning capabilities from formidable teacher models to compact student models. However, existing distillation paradigms face a fundamental dilemma. Typical off-policy distillation strictly utilizes teacher-generated golden trajectories, suffering from an exposure bias due to the mismatch between training distributions and student-generated inference contexts, which leads to error cascades in long CoT reasoning. To address this, on-policy distillation allows students to explore their own trajectories, but we demonstrate that it inherently introduces a reciprocal reversed exposure bias: the teacher model also struggles to provide positive guidance when conditioned on student-generated sub-optimal contexts. To resolve this dual exposure biases problem, we propose Monitoring Trajectories and Backtracking when it strays (MOTAB), a new LLM reasoning distillation pipeline. Specifically, MOTAB dynamically monitors the student's on-policy generation against an adaptive safety boundary. When the generation strays and exceeds this threshold, MOTAB backtracks to the last safe state and leverages teacher intervention to correct the course. This approach inherently tolerates minor student errors to mitigate exposure bias, while preventing sub-optimal contexts to circumvent reversed exposure bias. Extensive experiments on the LIMO-v2 and AceReason datasets demonstrate that MOTAB effectively alleviates the dual exposure biases, yielding a roughly 3% average performance improvement in reasoning tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript identifies a dual exposure bias problem in LLM reasoning distillation: off-policy methods suffer from exposure bias due to distribution mismatch between teacher-generated trajectories and student inference, leading to error cascades in long CoT; on-policy methods introduce reversed exposure bias where the teacher struggles to guide from student-generated sub-optimal contexts. To resolve this, the authors propose MOTAB, which dynamically monitors student on-policy generations against an adaptive safety boundary, backtracks to the last safe state when the boundary is exceeded, and applies teacher intervention to correct the trajectory. This is claimed to tolerate minor student errors while preventing sub-optimal contexts. Experiments on the LIMO-v2 and AceReason datasets report a roughly 3% average performance improvement in reasoning tasks.
Significance. If the central mechanism holds under scrutiny, the work would be moderately significant for the field of efficient LLM reasoning. It explicitly articulates the reciprocal nature of the two biases and offers a practical backtracking pipeline that aims to balance exploration with guidance, which could aid deployment of compact student models for complex reasoning. The approach credits the identification of the dual-bias dilemma and the intent to avoid both error cascades and reversed guidance issues. However, without formalization or ablations on the key adaptive component, the contribution remains more conceptual than immediately actionable.
major comments (2)
- [MOTAB Pipeline] The MOTAB pipeline description introduces the 'adaptive safety boundary' as the core mechanism for deciding when to backtrack and intervene, yet provides no equation, threshold computation rule, or update procedure (e.g., whether based on token probability, entropy, or another signal). This is load-bearing for the central claim that the method mitigates both exposure biases without new artifacts or excessive overhead, because the boundary directly controls which trajectories receive correction versus tolerance and thus determines the validity of the reported 3% gain.
- [Experiments] The experimental claim of a roughly 3% average performance improvement on LIMO-v2 and AceReason is stated without reference to specific metrics, baseline models, number of runs, error bars, or statistical tests. This directly affects assessment of whether the backtracking truly balances the dual biases or reflects dataset-specific tuning.
minor comments (1)
- [Abstract] The abstract refers to 'dynamic monitoring against the boundary' and 'last safe state' without clarifying how the safe state is identified or stored, which could be expanded for clarity even if details appear later in the manuscript.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments correctly identify areas where additional formalization and experimental detail will improve the manuscript. We address each major comment below and have revised the paper accordingly.
read point-by-point responses
-
Referee: [MOTAB Pipeline] The MOTAB pipeline description introduces the 'adaptive safety boundary' as the core mechanism for deciding when to backtrack and intervene, yet provides no equation, threshold computation rule, or update procedure (e.g., whether based on token probability, entropy, or another signal). This is load-bearing for the central claim that the method mitigates both exposure biases without new artifacts or excessive overhead, because the boundary directly controls which trajectories receive correction versus tolerance and thus determines the validity of the reported 3% gain.
Authors: We agree that a more explicit formalization of the adaptive safety boundary is necessary for reproducibility and to fully substantiate the central claims. In the revised manuscript we have added a new subsection (3.2) that defines the boundary mathematically as an entropy-based threshold computed from the student's per-token prediction entropy, updated at each step via an exponential moving average whose decay rate is conditioned on trajectory length. The backtracking decision rule is now stated as an inequality involving this boundary and the teacher's conditional log-probability on the prefix. We also include pseudocode and a brief complexity analysis showing that the added overhead remains negligible. These changes directly clarify how the mechanism tolerates minor deviations while preventing sub-optimal contexts. revision: yes
-
Referee: [Experiments] The experimental claim of a roughly 3% average performance improvement on LIMO-v2 and AceReason is stated without reference to specific metrics, baseline models, number of runs, error bars, or statistical tests. This directly affects assessment of whether the backtracking truly balances the dual biases or reflects dataset-specific tuning.
Authors: We concur that the experimental reporting must be expanded for proper evaluation. The revised Experiments section now specifies that the reported figure is the average accuracy across the standard reasoning benchmarks in each dataset, compares MOTAB against off-policy SFT, vanilla on-policy distillation, and two recent backtracking baselines, reports results averaged over five independent runs with standard error bars, and includes paired t-test p-values confirming statistical significance of the gains. These additions demonstrate that the improvement is consistent rather than an artifact of dataset-specific tuning. revision: yes
Circularity Check
No significant circularity; method and gains rest on empirical validation rather than definitional reduction.
full rationale
The paper introduces MOTAB as a novel pipeline that monitors on-policy generation against an adaptive safety boundary and applies backtracking plus teacher intervention. The claimed alleviation of dual exposure biases and the ~3% gain are presented as outcomes of experiments on LIMO-v2 and AceReason. No equations or steps in the abstract or described pipeline reduce a result to its own inputs by construction, nor does any load-bearing premise collapse into a self-citation whose validity is presupposed. The adaptive boundary and tolerance rules are introduced as design choices whose effectiveness is tested externally rather than derived tautologically from the performance metric itself. The derivation chain therefore remains self-contained against the reported benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- adaptive safety boundary threshold
axioms (1)
- domain assumption Teacher model can provide positive guidance on corrected trajectories after backtracking.
invented entities (1)
-
adaptive safety boundary
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MOTAB dynamically monitors the student’s on-policy generation against an adaptive safety boundary... backtracks to the last safe state and leverages teacher intervention
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the ideal distillation dataset should cover the student model’s own sub-optimal on-policy data distribution... while the teacher model must provide supervision within a relatively accurate student-generated context
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
R. Agarwal, N. Vieillard, Y . Zhou, P. Stanczyk, S. R. Garea, M. Geist, and O. Bachem. On- policy distillation of language models: Learning from self-generated mistakes. InInternational Conference on Learning Representations, 2024
work page 2024
- [2]
-
[3]
H. Chen, S. Wu, X. Quan, R. Wang, M. Yan, and J. Zhang. MCC-KD: multi-cot consistent knowledge distillation. InFindings of the Association for Computational Linguistics: EMNLP, pages 6805–6820, 2023
work page 2023
- [4]
-
[5]
X. Chen, S. Zhou, K. Liang, X. Sun, and X. Liu. Skip-thinking: Chunk-wise chain-of-thought distillation enable smaller language models to reason better and faster. InConference on Empirical Methods in Natural Language Processing, pages 12142–12157, 2025
work page 2025
-
[6]
Y . Chen, Z. Yang, Z. Liu, C. Lee, P. Xu, M. Shoeybi, B. Catanzaro, and W. Ping. Acereason- nemotron: Advancing math and code reasoning through reinforcement learning. InAnnual Conference on Neural Information Processing Systems, 2025
work page 2025
- [7]
-
[8]
Y . Fu, H. Huang, K. Jiang, Y . Zhu, and D. Zhao. Revisiting on-policy distillation: Empirical failure modes and simple fixes.CoRR, abs/2603.25562, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Y . Gu, L. Dong, F. Wei, and M. Huang. Minillm: Knowledge distillation of large language models. InInternational Conference on Learning Representations, 2024
work page 2024
-
[10]
E. K. Guha, R. Marten, S. Keh, N. Raoof, G. Smyrnis, H. Bansal, M. Nezhurina, J. Mercat, T. Vu, Z. Sprague, et al. Openthoughts: Data recipes for reasoning models. InFirst Workshop on Foundations of Reasoning in Language Models, 2025. 10
work page 2025
-
[11]
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081): 633–638, 2025
work page 2025
-
[12]
N. Ho, L. Schmid, and S. Yun. Large language models are reasoning teachers. InAnnual Meeting of the Association for Computational Linguistics, pages 14852–14882, 2023
work page 2023
-
[13]
C. Hsieh, C. Li, C. Yeh, H. Nakhost, Y . Fujii, A. Ratner, R. Krishna, C. Lee, and T. Pfister. Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes. InFindings of the Association for Computational Linguistics: ACL, pages 8003–8017, 2023
work page 2023
-
[14]
J. Jung, S. Han, X. Lu, S. Hallinan, D. Acuna, S. Prabhumoye, M. Patwary, M. Shoeybi, B. Catanzaro, and Y . Choi. Prismatic synthesis: Gradient-based data diversification boosts generalization in llm reasoning. InAnnual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[15]
S. Jung, S. Yoon, D. Kim, and H. Lee. Todi: Token-wise distillation via fine-grained divergence control. InConference on Empirical Methods in Natural Language Processing, pages 8078– 8091, 2025
work page 2025
- [16]
-
[17]
J. Ko, S. Kim, T. Chen, and S. Yun. Distillm: Towards streamlined distillation for large language models. InInternational Conference on Machine Learning, pages 24872–24895, 2024
work page 2024
-
[18]
J. Ko, T. Chen, S. Kim, T. Ding, L. Liang, I. Zharkov, and S. Yun. Distillm-2: A contrastive approach boosts the distillation of llms. InInternational Conference on Machine Learning, 2025
work page 2025
- [19]
-
[20]
Z. Lei, Z. Tan, S. Wang, Y . Zhu, Z. Chen, Y . Dong, and J. Li. Learning from diverse reasoning paths with routing and collaboration. InConference on Empirical Methods in Natural Language Processing, pages 2832–2845, 2025
work page 2025
-
[21]
Y . Li, Y . Emad, K. Padthe, J. Lanchantin, W. Yuan, T. Nguyen, J. E. Weston, S.-W. Li, D. Wang, I. Kulikov, et al. Naturalthoughts: Selecting and distilling reasoning traces for general reasoning tasks. InNeurIPS Workshop on Efficient Reasoning, 2025
work page 2025
-
[22]
H. Lightman, V . Kosaraju, Y . Burda, H. Edwards, B. Baker, T. Lee, J. Leike, J. Schulman, I. Sutskever, and K. Cobbe. Let’s verify step by step. InInternational Conference on Learning Representations, 2024
work page 2024
-
[23]
A. Lin, J. Wohlwend, H. Chen, and T. Lei. Autoregressive knowledge distillation through imitation learning. InConference on Empirical Methods in Natural Language Processing, pages 6121–6133, 2020
work page 2020
-
[24]
K. Liu, S. Yan, R. Miao, B. Wang, C. Shen, J. Zhang, and J. Ye. Where did this sentence come from? tracing provenance in LLM reasoning distillation. InInternational Conference on Learning Representations, 2026
work page 2026
-
[25]
R. Lowe, Y . Wu, A. Tamar, J. Harb, P. Abbeel, and I. Mordatch. Multi-agent actor-critic for mixed cooperative-competitive environments. InAnnual Conference on Neural Information Processing Systems, pages 6379–6390, 2017
work page 2017
-
[26]
L. C. Magister, J. Mallinson, J. Adámek, E. Malmi, and A. Severyn. Teaching small language models to reason. InAnnual Meeting of the Association for Computational Linguistics, pages 1773–1781, 2023. 11
work page 2023
-
[27]
N. Muennighoff, Z. Yang, W. Shi, X. L. Li, L. Fei-Fei, H. Hajishirzi, L. Zettlemoyer, P. Liang, E. J. Candès, and T. Hashimoto. s1: Simple test-time scaling. InConference on Empirical Methods in Natural Language Processing, pages 20275–20321, 2025
work page 2025
-
[28]
gpt-oss-120b & gpt-oss-20b Model Card
OpenAI. gpt-oss-120b & gpt-oss-20b model card.CoRR, abs/2508.10925, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
E. Pignatelli, J. Ferret, M. Geist, T. Mesnard, H. van Hasselt, and L. Toni. A survey of temporal credit assignment in deep reinforcement learning.Transactions on Machine Learning Research, 2024, 2024
work page 2024
-
[30]
M. Ranzato, S. Chopra, M. Auli, and W. Zaremba. Sequence level training with recurrent neural networks. InInternational Conference on Learning Representations, 2016
work page 2016
-
[31]
D. Rein, B. L. Hou, A. C. Stickland, J. Petty, R. Y . Pang, J. Dirani, J. Michael, and S. R. Bowman. GPQA: A graduate-level google-proof q&a benchmark.CoRR, abs/2311.12022, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
S. Ross, G. J. Gordon, and D. Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InInternational Conference on Artificial Intelligence and Statistics, pages 627–635, 2011
work page 2011
-
[33]
J. Schulman, P. Moritz, S. Levine, M. I. Jordan, and P. Abbeel. High-dimensional continuous control using generalized advantage estimation. InInternational Conference on Learning Representations, 2016
work page 2016
-
[34]
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, M. Zhang, Y . K. Li, Y . Wu, and D. Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.CoRR, abs/2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
A Survey of On-Policy Distillation for Large Language Models
M. Song and M. Zheng. A survey of on-policy distillation for large language models.CoRR, abs/2604.00626, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
B. Wang, R. Miao, C. Shen, S. Yan, K. Liu, X. Li, X. Yuan, S. Fan, J. Zhang, and J. Ye. On the step length confounding in LLM reasoning data selection.CoRR, abs/2604.06834, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
S. Wang, L. Yu, C. Gao, C. Zheng, S. Liu, R. Lu, K. Dang, X.-H. Chen, J. Yang, Z. Zhang, et al. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning. InAnnual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[38]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. H. Chi, Q. V . Le, and D. Zhou. Chain-of-thought prompting elicits reasoning in large language models. InAnnual Conference on Neural Information Processing Systems, 2022
work page 2022
- [39]
-
[40]
Z. Xi, C. Liao, G. Li, Z. Zhang, W. Chen, B. Wang, S. Jin, Y . Zhou, J. Guan, W. Wu, T. Ji, T. Gui, Q. Zhang, and X. Huang. Agentprm: Process reward models for LLM agents via step-wise promise and progress. InACM Web Conference, pages 4184–4195, 2026
work page 2026
-
[41]
W. Xu, R. Han, Z. Wang, L. T. Le, D. Madeka, L. Li, W. Y . Wang, R. Agarwal, C. Lee, and T. Pfister. Speculative knowledge distillation: Bridging the teacher-student gap through interleaved sampling. InInternational Conference on Learning Representations, 2025
work page 2025
- [42]
-
[43]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, et al. Qwen3 technical report.CoRR, abs/2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Y . Yang, Y . He, J. Liu, and Z. Jin. Making complex reasoning student-friendly: A hybrid LLM-to-SLM distillation framework. InThe 1st Workshop on Scaling Post-training for LLMs, 2026. 12
work page 2026
-
[45]
Y . Ye, Z. Huang, Y . Xiao, E. Chern, S. Xia, and P. Liu. Limo: Less is more for reasoning. In Conference on Language Modeling, 2025
work page 2025
-
[46]
X. Yuan, C. Shen, S. Yan, X. Zhang, L. Xie, W. Wang, R. Guan, Y . Wang, and J. Ye. Instance- adaptive zero-shot chain-of-thought prompting. InAnnual Conference on Neural Information Processing Systems, volume 37, pages 125469–125486, 2024
work page 2024
-
[47]
X. Yuan, C. Shen, S. Yan, K. Liu, X. Zhang, S. Fan, L. Xie, W. Wang, R. Guan, Y . Wang, and J. Ye. Differential fine-tuning large language models towards better diverse reasoning abilities. InInternational Conference on Learning Representations, 2026
work page 2026
- [48]
-
[49]
J. Zhang and K. Cho. Query-efficient imitation learning for end-to-end simulated driving. In AAAI Conference on Artificial Intelligence, pages 2891–2897, 2017
work page 2017
-
[50]
Instruction-Following Evaluation for Large Language Models
J. Zhou, T. Lu, S. Mishra, S. Brahma, S. Basu, Y . Luan, D. Zhou, and L. Hou. Instruction- following evaluation for large language models.CoRR, abs/2311.07911, 2023. 13 A Theoretical Analysis In this section, we provide a formal and mathematical derivation of the dual exposure biases in LLM reasoning distillation, and prove how our proposed MOTABframework...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.