Targeted Downstream-Agnostic Attack
Pith reviewed 2026-05-20 05:37 UTC · model grok-4.3
The pith
Pre-trained encoders can be attacked in a targeted manner without knowledge of the downstream task by matching features to a chosen threat image.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
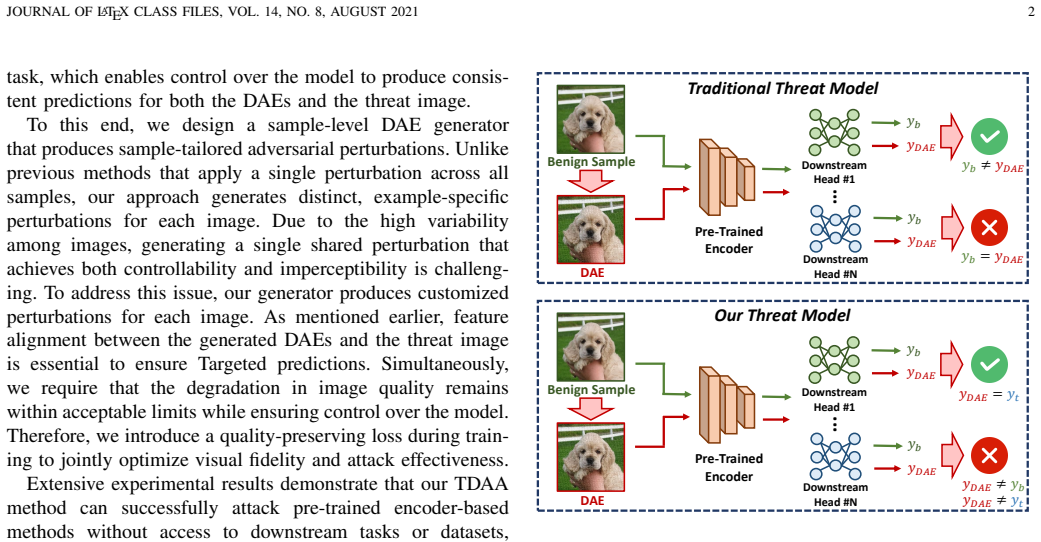
By compelling the victim encoder to output identical features for the downstream-agnostic adversarial examples and a pre-selected threat image, the method achieves targeted attacks that are independent of the unknown downstream task. Unlike prior methods that use a single perturbation for all samples, this example-specific generation ensures high success rates and maintains invisibility of the perturbations. Through this feature-level anchoring, the attack reveals significant vulnerabilities in widely used pre-trained encoders from self-supervised learning.
What carries the argument
The threat image, used as a feature-level anchor that forces the encoder to produce matching outputs for adversarial examples and the target image, thereby creating a task-agnostic connection.
Load-bearing premise
Forcing the encoder to output the same features for an adversarial input and the threat image will make any unknown downstream task behave as though the input was the threat image.
What would settle it
Run the attack on a known downstream task such as image classification, then check if the downstream model's predictions on the adversarial examples match the predictions it would make on the threat image; mismatch would falsify the targeted effect.
Figures







read the original abstract
Recently, pre-trained encoders have gained widespread use due to their strong capability in representation extraction. However, they are vulnerable to downstream-agnostic attacks (DAAs). Existing DAA methods operate under a permissive threat model, where an attack is successful if the generated downstream-agnostic adversarial examples (DAEs) change the original prediction, without requiring a specific target. In this paper, we propose a Targeted DAA (TDAA) method under a stricter threat model requiring the attack to be both targeted and downstream-agnostic. Since the downstream task is unknown and encoders do not directly produce predictions, achieving a targeted attack is particularly challenging. To address this, we introduce a novel component termed the 'threat image', pre-selected by the attacker as the target. Specifically, a generator is designed to produce example-specific adversarial perturbations that compel the victim encoder to output identical features for both the DAEs and the threat image. Unlike previous DAA methods that generate a single shared perturbation for all samples, which often fails due to image diversity, our method adopts an example-specific paradigm. This generates tailored perturbations for each image to ensure a high attack success rate and invisibility. By leveraging the threat image as a feature-level anchor, our method builds a task-agnostic bridge to reveal the vulnerabilities of the victim encoder. Extensive experiments on 10 self-supervised methods across 3 benchmark datasets demonstrate the effectiveness of our approach and reveal the pronounced vulnerability of pre-trained encoders. The code will be made publicly available after the review period.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Targeted Downstream-Agnostic Attack (TDAA) on pre-trained encoders. It introduces a pre-selected 'threat image' as an attacker-chosen target and designs a generator that produces example-specific adversarial perturbations forcing the victim encoder to output identical features for each downstream-agnostic adversarial example (DAE) and the threat image. This is presented as creating a task-agnostic bridge for targeted attacks under a stricter threat model than prior DAAs. Experiments on 10 self-supervised methods across 3 benchmark datasets are claimed to demonstrate effectiveness and high vulnerability of encoders.
Significance. If the feature-matching construction reliably transfers to produce the intended targeted behavior on arbitrary unknown downstream tasks, the work would highlight a concrete security risk in self-supervised representation learning and transfer pipelines. The shift to example-specific perturbations (versus shared perturbations in prior DAAs) is a practical improvement that could be of interest to the adversarial robustness community.
major comments (2)
- [Abstract / Method (threat-image construction)] The core claim (abstract and method section) that forcing identical encoder features between DAE and threat image 'builds a task-agnostic bridge' for targeted attacks rests on the unstated assumption that any downstream head or fine-tuned classifier will map those identical features to the same output the threat image would receive. This equivalence fails if the downstream task applies non-linear heads, task-specific normalization, or further fine-tuning that is not a deterministic function of the encoder features alone.
- [Experiments] Table or experimental results section: the manuscript reports success across 10 SSL methods and 3 datasets, yet the provided abstract and summary contain no quantitative attack success rates, standard deviations, ablation studies on the generator, or explicit verification that the targeted label (derived from the threat image) is achieved on concrete downstream classifiers. Without these numbers it is impossible to assess whether the feature-matching objective actually delivers targeted transfer or merely produces feature similarity.
minor comments (2)
- [Method] Notation for the generator and threat-image objective should be introduced with explicit equations rather than prose description only, to allow readers to verify the optimization target.
- [Abstract] The abstract states that 'the code will be made publicly available after the review period'; adding a footnote with the intended repository URL or license would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which has identified important points for clarification and strengthening. We respond to each major comment below and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract / Method (threat-image construction)] The core claim (abstract and method section) that forcing identical encoder features between DAE and threat image 'builds a task-agnostic bridge' for targeted attacks rests on the unstated assumption that any downstream head or fine-tuned classifier will map those identical features to the same output the threat image would receive. This equivalence fails if the downstream task applies non-linear heads, task-specific normalization, or further fine-tuning that is not a deterministic function of the encoder features alone.
Authors: We appreciate this observation and agree that the equivalence between identical encoder features and identical downstream outputs is not guaranteed for arbitrary non-linear heads or extensive fine-tuning. Our threat model focuses on influencing the encoder features directly as a task-agnostic anchor, which is effective when downstream tasks use the features in a relatively direct manner (e.g., linear probes or frozen encoders). In the revised manuscript we will explicitly articulate this assumption in the method section, qualify the 'task-agnostic bridge' claim accordingly, and add a limitations discussion. We will also include new experiments evaluating transfer to fine-tuned downstream classifiers to provide empirical support. revision: yes
-
Referee: [Experiments] Table or experimental results section: the manuscript reports success across 10 SSL methods and 3 datasets, yet the provided abstract and summary contain no quantitative attack success rates, standard deviations, ablation studies on the generator, or explicit verification that the targeted label (derived from the threat image) is achieved on concrete downstream classifiers. Without these numbers it is impossible to assess whether the feature-matching objective actually delivers targeted transfer or merely produces feature similarity.
Authors: We agree that prominent quantitative results and explicit downstream verification are needed for a complete assessment. The full manuscript contains tables reporting attack success rates across the 10 SSL methods and 3 datasets; however, to improve accessibility we will update the abstract with representative quantitative figures (including means and standard deviations). We will further expand the experiments section with dedicated ablation studies on the generator and a new verification subsection that reports targeted label success rates on concrete downstream classifiers, thereby distinguishing feature-level matching from end-to-end targeted transfer. revision: yes
Circularity Check
No significant circularity in derivation or claims
full rationale
The paper proposes a new TDAA method that explicitly defines an attack objective around a pre-selected threat image to force identical encoder features on adversarial examples. This construction is presented as a design choice to achieve task-agnostic targeted attacks, with effectiveness shown through empirical experiments on 10 self-supervised methods and 3 benchmark datasets. No load-bearing step reduces the claimed success or bridge-building result to a fitted parameter, self-citation chain, or definitional equivalence by the paper's own equations or prior work. The central claim remains self-contained against external benchmarks rather than tautological.
Axiom & Free-Parameter Ledger
invented entities (1)
-
threat image
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark,et al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning, pp. 8748–8763, PmLR, 2021
work page 2021
-
[2]
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Lo,et al., “Segment anything,” inProceedings of the IEEE/CVF international conference on computer vision, pp. 4015–4026, 2023
work page 2023
-
[3]
Language mod- els are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell,et al., “Language mod- els are few-shot learners,”Advances in neural information processing systems, vol. 33, pp. 1877–1901, 2020
work page 1901
-
[4]
Univer- sal adversarial perturbations,
S.-M. Moosavi-Dezfooli, A. Fawzi, O. Fawzi, and P. Frossard, “Univer- sal adversarial perturbations,” inProceedings of the IEEE conference on computer vision and pattern recognition, pp. 1765–1773, 2017
work page 2017
-
[5]
Downstream-agnostic adversarial examples,
Z. Zhou, S. Hu, R. Zhao, Q. Wang, L. Y . Zhang, J. Hou, and H. Jin, “Downstream-agnostic adversarial examples,” inProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 4345– 4355, 2023
work page 2023
-
[6]
Pre-trained adversarial perturbations,
Y . Ban and Y . Dong, “Pre-trained adversarial perturbations,”Advances in Neural Information Processing Systems, vol. 35, pp. 1196–1209, 2022
work page 2022
-
[7]
A self- supervised approach for adversarial robustness,
M. Naseer, S. Khan, M. Hayat, F. S. Khan, and F. Porikli, “A self- supervised approach for adversarial robustness,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 262–271, 2020
work page 2020
-
[8]
Universal adversarial attack via enhanced projected gradient descent,
Y . Deng and L. J. Karam, “Universal adversarial attack via enhanced projected gradient descent,” in2020 IEEE International Conference on Image Processing (ICIP), pp. 1241–1245, IEEE, 2020
work page 2020
-
[9]
Self-supervised models are continual learners,
E. Fini, V . G. T. Da Costa, X. Alameda-Pineda, E. Ricci, K. Alahari, and J. Mairal, “Self-supervised models are continual learners,” inPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 9621–9630, 2022
work page 2022
-
[10]
Ex- ploring the equivalence of siamese self-supervised learning via a unified gradient framework,
C. Tao, H. Wang, X. Zhu, J. Dong, S. Song, G. Huang, and J. Dai, “Ex- ploring the equivalence of siamese self-supervised learning via a unified gradient framework,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 14431–14440, 2022
work page 2022
-
[11]
Improved Baselines with Momentum Contrastive Learning
X. Chen, H. Fan, R. Girshick, and K. He, “Improved baselines with mo- mentum contrastive learning,”arXiv preprint arXiv:2003.04297, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[12]
An empirical study of training self- supervised vision transformers,
X. Chen, S. Xie, and K. He, “An empirical study of training self- supervised vision transformers,” inProceedings of the IEEE/CVF in- ternational conference on computer vision, pp. 9640–9649, 2021
work page 2021
-
[13]
A simple framework for contrastive learning of visual representations,
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” inInternational conference on machine learning, pp. 1597–1607, PmLR, 2020
work page 2020
-
[14]
Bootstrap your own latent-a new approach to self-supervised learning,
J.-B. Grill, F. Strub, F. Altch ´e, C. Tallec, P. Richemond, E. Buchatskaya, C. Doersch, B. Avila Pires, Z. Guo, M. Gheshlaghi Azar,et al., “Bootstrap your own latent-a new approach to self-supervised learning,” Advances in neural information processing systems, vol. 33, pp. 21271– 21284, 2020
work page 2020
-
[15]
Exploring simple siamese representation learning,
X. Chen and K. He, “Exploring simple siamese representation learning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 15750–15758, 2021
work page 2021
-
[17]
Unsupervised learning of visual features by contrasting cluster assign- ments,
M. Caron, I. Misra, J. Mairal, P. Goyal, P. Bojanowski, and A. Joulin, “Unsupervised learning of visual features by contrasting cluster assign- ments,”Advances in neural information processing systems, vol. 33, pp. 9912–9924, 2020
work page 2020
-
[18]
Barlow twins: Self-supervised learning via redundancy reduction,
J. Zbontar, L. Jing, I. Misra, Y . LeCun, and S. Deny, “Barlow twins: Self-supervised learning via redundancy reduction,” inInternational conference on machine learning, pp. 12310–12320, PMLR, 2021
work page 2021
-
[19]
Whitening for self-supervised representation learning,
A. Ermolov, A. Siarohin, E. Sangineto, and N. Sebe, “Whitening for self-supervised representation learning,” inInternational conference on machine learning, pp. 3015–3024, PMLR, 2021
work page 2021
-
[20]
D. Lee and E. Aune, “Vibcreg: Variance-invariance-better-covariance regularization for self-supervised learning on time series,”arXiv preprint arXiv:2109.00783, vol. 2, no. 5, 2021
-
[21]
Towards transferable targeted adversarial examples,
Z. Wang, H. Yang, Y . Feng, P. Sun, H. Guo, Z. Zhang, and K. Ren, “Towards transferable targeted adversarial examples,” inProceedings of JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 10 the IEEE/CVF conference on computer vision and pattern recognition, pp. 20534–20543, 2023
work page 2021
-
[22]
Improving transferable targeted attacks with feature tuning mixup,
K. Liang, X. Dai, Y . Li, D. Wang, and B. Xiao, “Improving transferable targeted attacks with feature tuning mixup,” inProceedings of the Computer Vision and Pattern Recognition Conference, pp. 25802–25811, 2025
work page 2025
-
[23]
Z. Liu and M. Larson, “Adversarial item promotion: Vulnerabilities at the core of top-n recommenders that use images to address cold start,” inProceedings of the Web Conference 2021, pp. 3590–3602, 2021
work page 2021
-
[24]
Hardening interpretable deep learning systems: Investigat- ing adversarial threats and defenses,
E. Abdukhamidov, M. Abuhamad, S. S. Woo, E. Chan-Tin, and T. Abuhmed, “Hardening interpretable deep learning systems: Investigat- ing adversarial threats and defenses,”IEEE Transactions on Dependable and Secure Computing, vol. 21, no. 4, pp. 3963–3976, 2023
work page 2023
-
[25]
Can we mitigate backdoor attack using adversarial detection methods?,
K. Jin, T. Zhang, C. Shen, Y . Chen, M. Fan, C. Lin, and T. Liu, “Can we mitigate backdoor attack using adversarial detection methods?,”IEEE Transactions on Dependable and Secure Computing, vol. 20, no. 4, pp. 2867–2881, 2022
work page 2022
-
[26]
Towards transferable targeted 3d adversarial attack in the physical world,
Y . Huang, Y . Dong, S. Ruan, X. Yang, H. Su, and X. Wei, “Towards transferable targeted 3d adversarial attack in the physical world,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 24512–24522, 2024
work page 2024
-
[27]
Clip-guided generative networks for transferable targeted adversarial attacks,
H. Fang, J. Kong, B. Chen, T. Dai, H. Wu, and S.-T. Xia, “Clip-guided generative networks for transferable targeted adversarial attacks,” in European Conference on Computer Vision, pp. 1–19, Springer, 2024
work page 2024
-
[28]
Learning multiple layers of features from tiny images,
A. Krizhevsky, G. Hinton,et al., “Learning multiple layers of features from tiny images,” 2009
work page 2009
-
[29]
An analysis of single-layer networks in unsupervised feature learning,
A. Coates, A. Ng, and H. Lee, “An analysis of single-layer networks in unsupervised feature learning,” inProceedings of the fourteenth international conference on artificial intelligence and statistics, pp. 215– 223, JMLR Workshop and Conference Proceedings, 2011
work page 2011
-
[30]
C. Alessio, “Animals-10.” https://www.kaggle.com/alessiocorrado99/ animals10, August 2020. Kaggle dataset
work page 2020
-
[31]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778, 2016
work page 2016
-
[32]
With a little help from my friends: Nearest-neighbor contrastive learning of visual representations,
D. Dwibedi, Y . Aytar, J. Tompson, P. Sermanet, and A. Zisserman, “With a little help from my friends: Nearest-neighbor contrastive learning of visual representations,” inProceedings of the IEEE/CVF international conference on computer vision, pp. 9588–9597, 2021
work page 2021
-
[33]
Ressl: Relational self-supervised learning with weak augmentation,
M. Zheng, S. You, F. Wang, C. Qian, C. Zhang, X. Wang, and C. Xu, “Ressl: Relational self-supervised learning with weak augmentation,” Advances in Neural Information Processing Systems, vol. 34, pp. 2543– 2555, 2021
work page 2021
-
[34]
Supervised contrastive learn- ing,
P. Khosla, P. Teterwak, C. Wang, A. Sarna, Y . Tian, P. Isola, A. Maschinot, C. Liu, and D. Krishnan, “Supervised contrastive learn- ing,”Advances in neural information processing systems, vol. 33, pp. 18661–18673, 2020
work page 2020
-
[35]
Adam: A Method for Stochastic Optimization
D. P. Kingma, “Adam: A method for stochastic optimization,”arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[36]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly,et al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[37]
Representation Learning with Contrastive Predictive Coding
A. v. d. Oord, Y . Li, and O. Vinyals, “Representation learning with contrastive predictive coding,”arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.