Sampling-Based Safe Reinforcement Learning
Pith reviewed 2026-05-20 07:01 UTC · model grok-4.3
The pith
Enforcing constraints jointly over finite dynamics samples approximates worst-case safety in reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SBSRL maintains safety throughout learning by enforcing constraints jointly across a finite set of dynamics samples. This formulation approximates an intractable worst-case optimization over uncertain dynamics and enables practical safety guarantees in continuous domains. Under regularity conditions, high-probability guarantees of safety throughout learning and a finite-time sample complexity bound for recovering a near-optimal policy are derived.
What carries the argument
Joint enforcement of constraints across a finite set of sampled dynamics models that approximates the worst-case optimization over uncertain dynamics.
If this is right
- Safety is preserved with high probability for the entire duration of learning.
- A finite-time bound guarantees recovery of a near-optimal policy after a controlled number of samples.
- Exploration proceeds by constraining epistemic uncertainty without separate reward bonuses.
- The formulation scales to deep-ensemble implementations for high-dimensional continuous control.
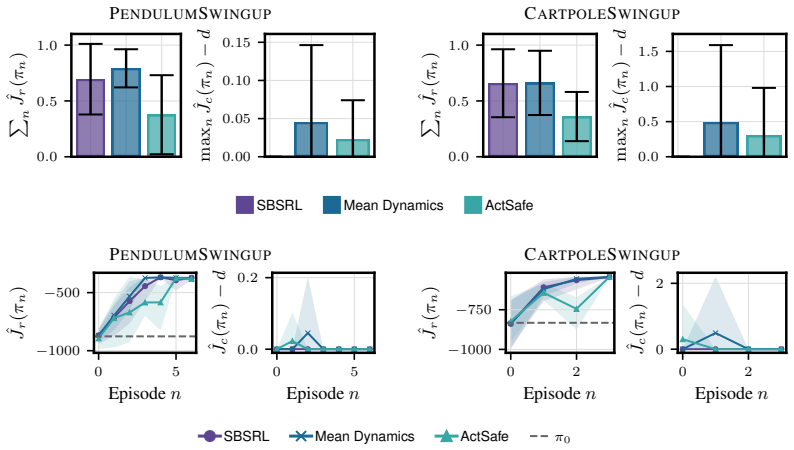
- Empirical results confirm safe operation on both simulated and physical robotic hardware.
Where Pith is reading between the lines
- The sampling approach could reduce the risk of catastrophic failures when RL is applied to real-world systems with costly mistakes.
- Similar joint-constraint ideas might transfer to other model-based planning settings that face model uncertainty.
- Direct measurement of how often sampled models must be drawn to keep violation probability below a target threshold would test practical tightness of the bounds.
Load-bearing premise
High-probability safety guarantees and sample-complexity bounds rely on regularity conditions on the dynamics and uncertainty model.
What would settle it
An experiment that satisfies the regularity conditions yet records a safety violation during learning would disprove the high-probability guarantees.
Figures









read the original abstract
Safe exploration remains a fundamental challenge in reinforcement learning (RL), limiting the deployment of RL agents in the real world. We propose Sampling-Based Safe Reinforcement Learning (SBSRL), a model-based RL algorithm that maintains safety throughout the learning process by enforcing constraints jointly across a finite set of dynamics samples. This formulation approximates an intractable worst-case optimization over uncertain dynamics and enables practical safety guarantees in continuous domains. We further introduce an exploration strategy based on constraining epistemic uncertainty, eliminating the need for explicit exploration bonuses. Under regularity conditions, we derive high-probability guarantees of safety throughout learning and a finite-time sample complexity bound for recovering a near-optimal policy. Empirically, SBSRL achieves safe and efficient exploration both in simulation and in real robotic hardware, and readily extends to practical deep-ensemble implementations that scale to high-dimensional continuous control problems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Sampling-Based Safe Reinforcement Learning (SBSRL), a model-based RL algorithm that maintains safety throughout learning by jointly enforcing constraints over a finite set of sampled dynamics models. This approximates an intractable worst-case optimization over uncertain dynamics, introduces an epistemic-uncertainty-constrained exploration strategy without explicit bonuses, and claims high-probability safety guarantees plus finite-time sample-complexity bounds for near-optimal policy recovery under regularity conditions. Empirical results are reported in simulation and on real robotic hardware, with extensions to deep-ensemble implementations for high-dimensional continuous control.
Significance. If the regularity conditions are mild and the finite-sample approximation closes the gap to the true uncertainty set with the stated high probability, the work would provide a practical bridge between worst-case robust RL and scalable model-based methods. The elimination of explicit exploration bonuses via uncertainty constraints and the hardware validation are strengths that could influence safe exploration research in continuous domains.
major comments (2)
- [Abstract / Theoretical Results] Abstract and theoretical results section: the high-probability safety guarantees and finite-time sample-complexity bounds are stated to hold only under unspecified 'regularity conditions' on the dynamics and uncertainty model. Without an explicit list (e.g., Lipschitz constants, bounded epistemic variance, or compactness of the uncertainty set), it is impossible to verify whether the finite dynamics samples suffice to approximate the worst-case optimization with the claimed probability, particularly for the continuous robotic domains tested.
- [Safety Formulation] The safety formulation is defined directly with respect to the finite set of sampled models chosen by the algorithm. This creates a potential circularity: the derived bounds apply to the sampled set by construction, but no explicit reduction or concentration argument is visible showing that the sampled-set safety implies safety with respect to the true (continuous) uncertainty set outside the regularity conditions.
minor comments (2)
- [Abstract] The abstract reports empirical success but does not mention error bars, number of trials, or statistical significance for the hardware experiments; adding these would strengthen the reproducibility claim.
- [Introduction / Method] Notation for the epistemic uncertainty set and the finite sample size should be introduced earlier and used consistently when stating the approximation to the worst-case optimization.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, clarifying the theoretical assumptions and indicating revisions that will be incorporated to make the regularity conditions and safety reduction explicit.
read point-by-point responses
-
Referee: [Abstract / Theoretical Results] Abstract and theoretical results section: the high-probability safety guarantees and finite-time sample-complexity bounds are stated to hold only under unspecified 'regularity conditions' on the dynamics and uncertainty model. Without an explicit list (e.g., Lipschitz constants, bounded epistemic variance, or compactness of the uncertainty set), it is impossible to verify whether the finite dynamics samples suffice to approximate the worst-case optimization with the claimed probability, particularly for the continuous robotic domains tested.
Authors: We agree that the regularity conditions must be stated explicitly to allow verification of the bounds. Our analysis assumes: (i) Lipschitz continuity of the dynamics with constant L, (ii) uniform bound σ on epistemic variance, and (iii) compactness of the uncertainty set. Under these, finite samples suffice via standard covering-number and concentration arguments. We will revise the abstract and theory section to list these conditions explicitly and add a short discussion of their relevance to the tested robotic domains. revision: yes
-
Referee: [Safety Formulation] The safety formulation is defined directly with respect to the finite set of sampled models chosen by the algorithm. This creates a potential circularity: the derived bounds apply to the sampled set by construction, but no explicit reduction or concentration argument is visible showing that the sampled-set safety implies safety with respect to the true (continuous) uncertainty set outside the regularity conditions.
Authors: Safety is enforced on the sampled models as a tractable proxy. The reduction to the true continuous uncertainty set is obtained via a uniform-convergence argument: under the stated regularity conditions, the worst-case violation over the true set is bounded by the sampled-set violation plus a term that decays with sample count (via Lipschitz continuity and compactness). We will insert an explicit lemma (with proof sketch) in the theory section or appendix to detail this concentration step and the required sample size. revision: yes
Circularity Check
No significant circularity in the claimed derivation
full rationale
The paper defines SBSRL as enforcing joint constraints over a finite set of dynamics samples to approximate worst-case optimization over uncertain dynamics, then derives high-probability safety guarantees and finite-time sample-complexity bounds under regularity conditions on the dynamics and uncertainty model. No step reduces a derived bound or guarantee to an input quantity by construction (e.g., no fitted parameter renamed as prediction, no self-definitional loop where safety w.r.t. samples is equated to true safety without external conditions, and no load-bearing self-citation or smuggled ansatz). The regularity conditions are external assumptions that are intended to close the gap between samples and true dynamics, leaving the central claims with independent theoretical content rather than tautological equivalence to the algorithmic choices.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of dynamics samples
axioms (1)
- domain assumption Regularity conditions on dynamics and epistemic uncertainty
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Under regularity conditions, we derive high-probability guarantees of safety throughout learning and a finite-time sample complexity bound
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
enforcing constraints jointly across a finite set of dynamics samples... approximates an intractable worst-case optimization
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Human-level control through deep reinforcement learning
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei Rusu, Joel Veness, Marc Bellemare, Alex Graves, Martin Riedmiller, Andreas Fidjeland, Georg Ostrovski, Stig Petersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg, and Demis Hassabis. Human-level control through deep reinforcement learning....
work page 2015
-
[2]
Mastering the game of Go without human knowledge.Nature, 2017.(Cited on page 1)
David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, et al. Mastering the game of Go without human knowledge.Nature, 2017.(Cited on page 1)
work page 2017
-
[3]
Jens Kober, J. Bagnell, and Jan Peters. Reinforcement learning in robotics: A survey.The International Journal of Robotics Research, 2013.(Cited on page 1)
work page 2013
-
[4]
Chen Tang, Ben Abbatematteo, Jiaheng Hu, Rohan Chandra, Roberto Martin-Martin, and Peter Stone. Deep reinforcement learning for robotics: A survey of real-world successes.Proceedings of the AAAI Conference on Artificial Intelligence, 2025.(Cited on page 1)
work page 2025
-
[5]
Jonas Degrave, Federico Felici, Jonas Buchli, Michael Neunert, Brendan Tracey, Francesco Carpanese, Timo Ewalds, Roland Hafner, Abbas Abdolmaleki, Diego Casas, Craig Donner, Leslie Fritz, Cristian Galperti, Andrea Huber, James Keeling, Maria Tsimpoukelli, Jackie Kay, Antoine Merle, Jean-Marc Moret, and Martin Riedmiller. Magnetic control of tokamak plasma...
work page 2022
-
[6]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback,...
work page 2022
-
[7]
Concrete problems in ai safety, 2016.(Cited on page 1)
Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman, and Dan Mané. Concrete problems in ai safety, 2016.(Cited on page 1)
work page 2016
-
[8]
Actsafe: Active exploration with safety constraints for reinforcement learning
Yarden As, Bhavya Sukhija, Lenart Treven, Carmelo Sferrazza, Stelian Coros, and Andreas Krause. Actsafe: Active exploration with safety constraints for reinforcement learning. In International Conference on Learning Representations, 2025.(Cited on pages 1, 3, 4, 5, 6, 8, 16, 17, 18, 23, 25, 26, 27, and 28)
work page 2025
-
[9]
Safe exploration via policy priors
Manuel Wendl, Yarden As, Manish Prajapat, Anton Pollak, Stelian Coros, and Andreas Krause. Safe exploration via policy priors. InThe Fourteenth International Conference on Learning Representations, 2026.(Cited on pages 1, 3, 4, 6, 28, and 29)
work page 2026
-
[10]
Kurtland Chua, Roberto Calandra, Rowan McAllister, and Sergey Levine. Deep reinforcement learning in a handful of trials using probabilistic dynamics models.International Conference on Neural Information Processing Systems, 2018.(Cited on pages 2, 25, 27, and 29)
work page 2018
-
[11]
Benchmarking Safe Exploration in Deep Reinforcement Learning
Alex Ray, Joshua Achiam, and Dario Amodei. Benchmarking Safe Exploration in Deep Reinforcement Learning. 2019.(Cited on pages 2, 8, 27, 28, and 29)
work page 2019
-
[12]
Mankowitz, Jerry Li, Cosmin Paduraru, Sven Gowal, and Todd Hester
Gabriel Dulac-Arnold, Nir Levine, Daniel J. Mankowitz, Jerry Li, Cosmin Paduraru, Sven Gowal, and Todd Hester. An empirical investigation of the challenges of real-world reinforce- ment learning, 2021.(Cited on pages 2, 8, 27, 28, and 29)
work page 2021
-
[13]
A comprehensive survey on safe reinforcement learning
Javier García and Fernando Fernández. A comprehensive survey on safe reinforcement learning. Journal of Machine Learning Research, 2015.(Cited on page 2)
work page 2015
-
[14]
Lukas Brunke, Melissa Greeff, Adam W Hall, Zhaocong Yuan, Siqi Zhou, Jacopo Panerati, and Angela P Schoellig. Safe learning in robotics: From learning-based control to safe reinforcement learning.Annual Review of Control, Robotics, and Autonomous Systems, 2022.(Cited on page 2)
work page 2022
-
[15]
Shangding Gu, Long Yang, Yali Du, Guang Chen, Florian Walter, Jun Wang, and Alois Knoll. A review of safe reinforcement learning: Methods, theories and applications.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024.(Cited on page 2) 11
work page 2024
-
[16]
Altman.Constrained Markov Decision Processes
E. Altman.Constrained Markov Decision Processes. Chapman and Hall, 1999.(Cited on pages 2 and 10)
work page 1999
-
[17]
Safe reinforcement learning using advantage-based intervention
Nolan Wagener, Byron Boots, and Ching-An Cheng. Safe reinforcement learning using advantage-based intervention. InInternational Conference on Machine Learning, 2021.(Cited on page 2)
work page 2021
-
[18]
Safe reinforcement learning via confidence-based filters
Sebastian Curi, Armin Lederer, Sandra Hirche, and Andreas Krause. Safe reinforcement learning via confidence-based filters. InConference on Decision and Control. IEEE, 2022.(Cited on page 2)
work page 2022
-
[19]
Safe exploration in reinforcement learning: A generalized formulation and algorithms
Akifumi Wachi, Wataru Hashimoto, Xun Shen, and Kazumune Hashimoto. Safe exploration in reinforcement learning: A generalized formulation and algorithms. InInternational Conference on Neural Information Processing Systems, 2023.(Cited on page 2)
work page 2023
-
[20]
Near-optimal sample complexity bounds for constrained MDPs
Sharan Vaswani, Lin Yang, and Csaba Szepesvari. Near-optimal sample complexity bounds for constrained MDPs. InInternational Conference on Neural Information Processing Systems, 2022.(Cited on page 2)
work page 2022
-
[21]
Zhang, Jiali Duan, Tamer Bacsar, and Mihailo R
Dongsheng Ding, K. Zhang, Jiali Duan, Tamer Bacsar, and Mihailo R. Jovanovi´c. Convergence and sample complexity of natural policy gradient primal-dual methods for constrained mdps. ArXiv, 2022.(Cited on page 2)
work page 2022
-
[22]
Truly no-regret learning in constrained mdps
Adrian Müller, Pragnya Alatur, V olkan Cevher, Giorgia Ramponi, and Niao He. Truly no-regret learning in constrained mdps. InInternational Conference on Machine Learning, 2024.(Cited on page 2)
work page 2024
-
[23]
Constrained policy optimization
Joshua Achiam, David Held, Aviv Tamar, and Pieter Abbeel. Constrained policy optimization. InInternational Conference on Machine Learning, 2017.(Cited on page 2)
work page 2017
-
[24]
Constrained policy opti- mization via bayesian world models
Yarden As, Ilnura Usmanova, Sebastian Curi, and Andreas Krause. Constrained policy opti- mization via bayesian world models. InInternational Conference on Learning Representations, 2022.(Cited on pages 2, 3, 6, and 28)
work page 2022
-
[25]
Saute rl: Almost surely safe reinforcement learning using state augmentation
Aivar Sootla, Alexander I Cowen-Rivers, Taher Jafferjee, Ziyan Wang, David H Mguni, Jun Wang, and Haitham Ammar. Saute rl: Almost surely safe reinforcement learning using state augmentation. InInternational Conference on Machine Learning, 2022.(Cited on page 2)
work page 2022
-
[26]
Safedreamer: Safe reinforcement learning with world models
Weidong Huang, Jiaming Ji, Chunhe Xia, Borong Zhang, and Yaodong Yang. Safedreamer: Safe reinforcement learning with world models. InInternational Conference on Learning Representations, 2024.(Cited on page 2)
work page 2024
-
[27]
Safe Exploration in Markov Decision Processes
Teodor Mihai Moldovan and Pieter Abbeel. Safe exploration in markov decision processes. arXiv preprint arXiv:1205.4810, 2012.(Cited on page 2)
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[28]
Matteo Turchetta, Felix Berkenkamp, and Andreas Krause. Safe exploration in finite markov decision processes with gaussian processes.International Conference on Neural Information Processing Systems, 2016.(Cited on pages 2 and 7)
work page 2016
-
[29]
Akifumi Wachi, Yanan Sui, Yisong Yue, and Masahiro Ono. Safe exploration and optimization of constrained mdps using gaussian processes.AAAI, 2018.(Cited on page 2)
work page 2018
-
[30]
Safe reinforcement learning in constrained markov decision processes
Akifumi Wachi and Yanan Sui. Safe reinforcement learning in constrained markov decision processes. InInternational Conference on Machine Learning, 2020.(Cited on page 2)
work page 2020
-
[31]
Provably efficient safe exploration via primal-dual policy optimization
Dongsheng Ding, Xiaohan Wei, Zhuoran Yang, Zhaoran Wang, and Mihailo Jovanovic. Provably efficient safe exploration via primal-dual policy optimization. InInternational conference on artificial intelligence and statistics, 2021.(Cited on page 2)
work page 2021
-
[32]
Archana Bura, Aria HasanzadeZonuzy, Dileep Kalathil, Srinivas Shakkottai, and Jean-Francois Chamberland. Dope: Doubly optimistic and pessimistic exploration for safe reinforcement learning.International Conference on Neural Information Processing Systems, 2022.(Cited on page 2) 12
work page 2022
-
[33]
Torsten Koller, Felix Berkenkamp, Matteo Turchetta, and Andreas Krause. Learning-based model predictive control for safe exploration.IEEE Conference on Decision and Control, 2018. (Cited on page 2)
work page 2018
-
[34]
Lukas Hewing, Juraj Kabzan, and Melanie N Zeilinger. Cautious model predictive control using gaussian process regression.IEEE Transactions on Control Systems Technology, 2019.(Cited on page 2)
work page 2019
-
[35]
Kim Peter Wabersich and Melanie N Zeilinger. A predictive safety filter for learning-based control of constrained nonlinear dynamical systems.Automatica, 2021.(Cited on page 2)
work page 2021
- [36]
-
[37]
Manish Prajapat, Amon Lahr, Johannes Köhler, Andreas Krause, and Melanie N Zeilinger. Towards safe and tractable gaussian process-based mpc: Efficient sampling within a sequential quadratic programming framework. InIEEE Conference on Decision and Control. IEEE, 2024. (Cited on pages 2, 6, 15, and 16)
work page 2024
-
[38]
Domain randomization for transferring deep neural networks from simulation to the real world
Josh Tobin, Rachel Fong, Alex Ray, Jonas Schneider, Wojciech Zaremba, and Pieter Abbeel. Domain randomization for transferring deep neural networks from simulation to the real world. In2017 IEEE/RSJ international conference on intelligent robots and systems (IROS), 2017. (Cited on page 2)
work page 2017
-
[39]
A simple and efficient sampling-based algorithm for general reachability analysis
Thomas Lew, Lucas Janson, Riccardo Bonalli, and Marco Pavone. A simple and efficient sampling-based algorithm for general reachability analysis. InProceedings of The 4th Annual Learning for Dynamics and Control Conference, 2022.(Cited on page 2)
work page 2022
-
[40]
Grady Williams, Paul Drews, Brian Goldfain, James M. Rehg, and Evangelos A. Theodorou. Aggressive driving with model predictive path integral control. In2016 IEEE International Conference on Robotics and Automation (ICRA), 2016.(Cited on page 2)
work page 2016
-
[41]
G. Calafiore and Marco Campi. The scenario approach to robust control design.Automatic Control, IEEE Transactions on, 2006.(Cited on page 2)
work page 2006
-
[42]
Scenario-based Optimal Control for Gaussian Process State Space Models
Jonas Umlauft, Thomas Beckers, and Sandra Hirche. Scenario-based Optimal Control for Gaussian Process State Space Models. In2018 European Control Conference (ECC), 2018. (Cited on pages 2 and 15)
work page 2018
-
[43]
Lars Lindemann, Yiqi Zhao, Xinyi Yu, George J. Pappas, and Jyotirmoy V . Deshmukh. Formal verification and control with conformal prediction: Practical safety guarantees for autonomous systems.IEEE Control Systems, 2025.(Cited on page 2)
work page 2025
-
[44]
Manish Prajapat, Johannes Köhler, Amon Lahr, Andreas Krause, and Melanie N Zeilinger. Finite-sample-based reachability for safe control with gaussian process dynamics.arXiv preprint arXiv:2505.07594, 2025.(Cited on pages 2, 5, 15, 16, and 17)
-
[45]
Logarithmic online regret bounds for undiscounted reinforcement learning
Peter Auer and Ronald Ortner. Logarithmic online regret bounds for undiscounted reinforcement learning. InInternational Conference on Neural Information Processing Systems, 2006.(Cited on page 3)
work page 2006
-
[46]
Niranjan Srinivas, Andreas Krause, Sham M. Kakade, and Matthias W. Seeger. Information- theoretic regret bounds for gaussian process optimization in the bandit setting.IEEE Transac- tions on Information Theory, 2012.(Cited on pages 3 and 15)
work page 2012
-
[47]
Efficient model-based reinforcement learning through optimistic policy search and planning
Sebastian Curi, Felix Berkenkamp, and Andreas Krause. Efficient model-based reinforcement learning through optimistic policy search and planning. InInternational Conference on Neural Information Processing Systems, 2020.(Cited on pages 3, 4, 21, and 25)
work page 2020
-
[48]
Safe exploration for optimization with gaussian processes
Yanan Sui, Alkis Gotovos, Joel Burdick, and Andreas Krause. Safe exploration for optimization with gaussian processes. InInternational conference on machine learning, 2015.(Cited on page 3) 13
work page 2015
-
[49]
Transductive active learning: Theory and applications
Jonas Hübotter, Bhavya Sukhija, Lenart Treven, Yarden As, and Andreas Krause. Transductive active learning: Theory and applications. InInternational Conference on Neural Information Processing Systems, 2024.(Cited on page 3)
work page 2024
-
[50]
On explore-then-commit strategies
Aurélien Garivier, Tor Lattimore, and Emilie Kaufmann. On explore-then-commit strategies. Advances in Neural Information Processing Systems, 2016.(Cited on page 3)
work page 2016
-
[51]
Sombrl: Scalable and optimistic model-based rl
Bhavya Sukhija, Lenart Treven, Carmelo Sferrazza, Florian Dörfler, Pieter Abbeel, and Andreas Krause. Sombrl: Scalable and optimistic model-based rl. InAdvances in Neural Information Processing Systems (NeurIPS), 2025.(Cited on pages 3, 4, 17, and 18)
work page 2025
-
[52]
Manish Prajapat, Johannes Köhler, Melanie N. Zeilinger, and Andreas Krause. Safe and near-optimal control with online dynamics learning. 2026.(Cited on pages 3 and 7)
work page 2026
-
[53]
John Wiley & Sons, 2014.(Cited on page 3)
Martin L Puterman.Markov decision processes: discrete stochastic dynamic programming. John Wiley & Sons, 2014.(Cited on page 3)
work page 2014
-
[54]
In- formation theoretic regret bounds for online nonlinear control
Sham Kakade, Akshay Krishnamurthy, Kendall Lowrey, Motoya Ohnishi, and Wen Sun. In- formation theoretic regret bounds for online nonlinear control. InInternational Conference on Neural Information Processing Systems, 2020.(Cited on pages 4, 18, and 23)
work page 2020
-
[55]
On kernelized multi-armed bandits
Sayak Ray Chowdhury and Aditya Gopalan. On kernelized multi-armed bandits. InInternational Conference on Machine Learning, 2017.(Cited on page 5)
work page 2017
-
[56]
Aad Van Der Vaart and Harry Van Zanten. Information rates of nonparametric gaussian process methods.Journal of Machine Learning Research, 12(6), 2011.(Cited on page 5)
work page 2011
-
[57]
Felix Berkenkamp, Matteo Turchetta, Angela P. Schoellig, and Andreas Krause. Safe model- based reinforcement learning with stability guarantees. InInternational Conference on Neural Information Processing Systems, 2017.(Cited on page 7)
work page 2017
-
[58]
Yuval Tassa, Yotam Doron, Alistair Muldal, Tom Erez, Yazhe Li, Diego de Las Casas, David Budden, Abbas Abdolmaleki, Josh Merel, Andrew Lefrancq, et al. Deepmind control suite. arXiv preprint arXiv:1801.00690, 2018.(Cited on page 8)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[59]
T. Beckers and S. Hirche. Prediction with approximated gaussian process dynamical models. IEEE Transactions on Automatic Control, 2021.(Cited on page 15)
work page 2021
-
[60]
Cambridge University Press, 2023.(Cited on page 16)
Roman Garnett.Bayesian Optimization. Cambridge University Press, 2023.(Cited on page 16)
work page 2023
-
[61]
Bach Do, Nafeezat A. Ajenifuja, Taiwo A. Adebiyi, and Ruda Zhang. Sampling from gaussian processes: a tutorial and applications in global sensitivity analysis and optimization.Structural and Multidisciplinary Optimization, 2025.(Cited on page 16)
work page 2025
-
[62]
Optimistic active exploration of dynamical systems
Bhavya Sukhija, Lenart Treven, Cansu Sancaktar, Sebastian Blaes, Stelian Coros, and Andreas Krause. Optimistic active exploration of dynamical systems. InInternational Conference on Neural Information Processing Systems, 2023.(Cited on pages 17, 23, and 25)
work page 2023
-
[63]
Nicolò Cesa-Bianchi and Gábor Lugosi.Prediction, Learning, and Games. 2006. doi: 10.1017/CBO9780511546921.(Cited on page 20)
-
[64]
Sample-efficient cross-entropy method for real-time planning
Cristina Pinneri, Shambhuraj Sawant, Sebastian Blaes, Jan Achterhold, Joerg Stueckler, Michal Rolinek, and Georg Martius. Sample-efficient cross-entropy method for real-time planning. In Conference on Robot Learning, 2020.(Cited on page 25)
work page 2020
-
[65]
When to trust your model: model- based policy optimization
Michael Janner, Justin Fu, Marvin Zhang, and Sergey Levine. When to trust your model: model- based policy optimization. InInternational Conference on Neural Information Processing Systems, 2019.(Cited on pages 27 and 29)
work page 2019
-
[66]
Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple and scalable predictive uncertainty estimation using deep ensembles.International Conference on Neural Information Processing Systems, 2017.(Cited on page 27) 14
work page 2017
-
[67]
Decomposition of uncertainty in bayesian deep learning for efficient and risk-sensitive learning
Stefan Depeweg, Jose-Miguel Hernandez-Lobato, Finale Doshi-Velez, and Steffen Udluft. Decomposition of uncertainty in bayesian deep learning for efficient and risk-sensitive learning. InInternational conference on machine learning, 2018.(Cited on page 27)
work page 2018
-
[68]
Jorge Nocedal and Stephen J. Wright.Numerical Optimization. Springer, second edition, 2006. (Cited on page 28)
work page 2006
-
[69]
Jingqi Li, David Fridovich-Keil, Somayeh Sojoudi, and Claire J. Tomlin. Augmented lagrangian method for instantaneously constrained reinforcement learning problems.2021 60th IEEE Conference on Decision and Control (CDC), 2021.(Cited on page 28)
work page 2021
-
[70]
SPiDR: A simple approach for zero-shot safety in sim-to-real transfer
Yarden As, Chengrui Qu, Benjamin Unger, Dongho Kang, Max van der Hart, Laixi Shi, Stelian Coros, Adam Wierman, and Andreas Krause. SPiDR: A simple approach for zero-shot safety in sim-to-real transfer. InInternational Conference on Neural Information Processing Systems, 2025.(Cited on page 28)
work page 2025
-
[71]
Tianhe Yu, Garrett Thomas, Lantao Yu, Stefano Ermon, James Zou, Sergey Levine, Chelsea Finn, and Tengyu Ma. Mopo: Model-based offline policy optimization. InAdvances in Neural Information Processing Systems, 2020.(Cited on page 28) A Discussion We collect here several technical observations that clarify the scope of our assumptions and design choices. We ...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.